




DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Imagine you’re planning a road trip and ask your digital assistant, What’s the fastest route to the mountains right now? Without real-time information, it suggests a highway based on outdated traffic patterns, leaving you stuck in a detour. But with live traffic updates, it would have detected the closure and guided you through a quicker scenic route. This highlights a core limitation of large language models (LLMs): their reliance on static, pre-trained knowledge often leads to outdated or incomplete answers.Retrieval-augmented generation (RAG) addresses this by combining LLMs with external knowledge sources like databases or search engines. Rather than relying only on stored knowledge, RAG retrieves relevant information and incorporates it into the model’s response. This is useful for answering questions about recent events or specialized topics. However, traditional RAG systems are far from perfect. They often retrieve irrelevant information, miss crucial details, or waste resources on unnecessary lookups.DeepRAG, introduced in the paper DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, solves these issues with a more adaptive approach. Instead of treating retrieval as a single step, it breaks complex questions into smaller subqueries and decides at each stage whether to rely on internal knowledge or fetch external data. Techniques like binary tree search, which explores different answer paths, and imitation learning, where the model is trained using expert examples, help DeepRAG retrieve only what is necessary. This step-by-step approach reduces wasted searches and improves answer accuracy.In this article, we’ll explore how DeepRAG works, unpack its key components, and show how vector databases like Milvus and Zilliz Cloud can further enhance its retrieval capabilities.
The Shortcomings of Static Knowledge and Naive Retrieval
While large language models (LLMs) excel at generating coherent responses, they fall short when queries demand current, specific, or deeply contextual knowledge. This is because their knowledge is based on static datasets collected during training, which limits their ability to answer questions that require real-time or specialized information. Once training is complete, their knowledge is frozen, making them unreliable for queries that demand timeliness, specificity, or dynamic context.
Timeliness: For topics like current events or live updates, LLMs provide outdated information. When asked, “Who won the World Cup this year?”, the model may answer based on past tournaments rather than the most recent results.
Specificity: LLMs often fail in niche domains like medicine, law, or technical standards, where up-to-date or highly specialized knowledge is critical. For example, a query about the latest FDA-approved treatments for Alzheimer’s disease may produce outdated recommendations.
Dynamic Context: Rapidly evolving information, such as stock prices, social media trends, or weather conditions, is beyond their reach. Without external updates, the model guesses rather than provides informed responses.
Retrieval-augmented generation (RAG) extends the capabilities of LLMs by pulling in external information from databases, search engines, or APIs before generating responses. However, traditional RAG systems introduce their own set of problems:
- Over-Retrieval: When RAG retrieves too many irrelevant documents, it floods the model with noise, making responses less accurate. For example, if asked, “What caused the 2023 Hawaii wildfires?”, a traditional RAG system might retrieve a range of articles about wildfire prevention or historical fires rather than the specific cause.
- Under-Retrieval: Poorly framed or overly broad queries can result in missing key details. Searching only for “Hawaii wildfire causes” might exclude official investigative reports that attribute the cause to downed power lines.
- Computational Waste: Retrieving and processing large volumes of unnecessary information increases response times and costs without improving the quality of the answer.
The root of these issues is that traditional RAG systems treat every query the same, retrieving external information indiscriminately without evaluating whether it is necessary. This lack of adaptability results in inefficiencies for simple questions and incomplete responses for complex ones. Simple queries, such as “What is photosynthesis?”, do not require external retrieval because the answer is already within the model’s internal knowledge. In contrast, complex or multi-step questions, like “Compare the efficacy of mRNA vaccines across different age groups”, demand external information and may involve breaking the query into sub questions to retrieve the most relevant data.
This rigid approach highlights the need for a more adaptive system that can balance internal knowledge with external retrieval, tailoring its strategy based on the complexity and requirements of each query.
How DeepRAG Adapts Retrieval Step-by-Step
DeepRAG addresses the limitations of traditional RAG systems by introducing an adaptive process that mirrors how we as humans approach complex questions. Instead of retrieving information all at once or for every query, DeepRAG breaks down questions into smaller, more manageable subqueries and decides at each step whether external information is necessary. This adaptive process reduces unnecessary searches and improves accuracy.
The key to DeepRAG’s approach lies in how it structures and navigates the retrieval process. Rather than treating a query as a single block, it follows a retrieval narrative, a logical sequence where each subquery builds on previous steps to gradually form a complete answer. At every stage, DeepRAG makes atomic decisions to determine whether to rely on internal knowledge or to fetch external data, allowing it to stay efficient and focused on what’s truly needed to answer the question.
Take a look at the following illustration that shows how DeepRAG mirrors human thinking.
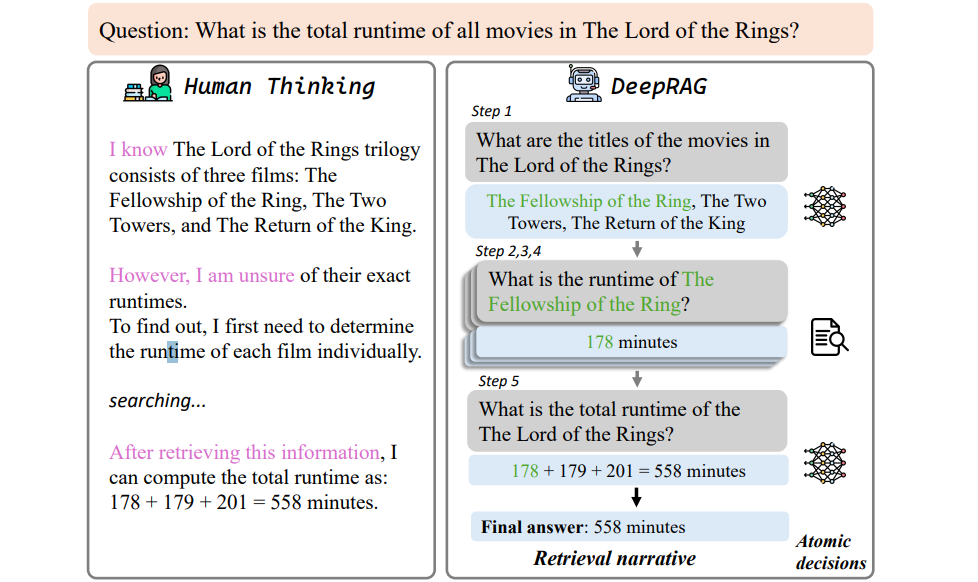
Figure 1: Illustration of how DeepRAG mirrors human thinking
By structuring the reasoning process through a well-defined retrieval narrative and making precise atomic decisions at each step, DeepRAG ensures that it only retrieves when needed and relies on internal knowledge when appropriate. This balanced approach leads to more efficient and accurate answers while reducing the computational cost associated with excessive or irrelevant retrieval. This adaptive framework not only improves response quality but also optimizes resource usage, making DeepRAG a more practical and scalable solution for complex information retrieval tasks.
The Core Components Behind DeepRAG’s Adaptive Retrieval
DeepRAG’s adaptive retrieval process relies on a structured approach that breaks down complex questions, makes informed decisions about when to retrieve external information, and refines its reasoning strategies through training. This process is built on four interconnected components; Markov Decision Process (MDP) modeling, binary tree search, imitation learning, and a chain of calibration, all of which work together to balance efficiency and accuracy in answering questions.
Markov Decision Process (MDP) Overview
At the heart of DeepRAG’s decision-making process is the Markov Decision Process (MDP) framework, which helps the system systematically map out the steps needed to answer a question. The MDP consists of four components:
States (S): Represent the current progress in answering a question. A state includes the original question along with any subqueries and their corresponding answers generated so far.
Actions (A): At each state, the model makes two decisions to guide its actions. The termination decision determines whether the model should stop and provide a final answer or continue by generating subqueries. The atomic decision decides whether the model should use its internal knowledge or retrieve external information to address the next subquery.
Transitions (P): Define how the system moves from one state to another based on the chosen actions.
Rewards (R): A scoring system that rewards the model for finding the correct answer while penalizing unnecessary or excessive retrievals.
For example, suppose the system is asked “What is the total runtime of all movies in The Lord of the Rings?”. The initial state s_0 contains only the question. The model’s first action might be to generate a subquery like “What are the titles of the movies in The Lord of the Rings?”. It then decides whether to use internal knowledge or retrieve external data. Once it has the list of movies, the system transitions to a new state s_1, now containing the movie titles. Next, it generates subqueries such as “What is the runtime of The Fellowship of the Ring?” and continues making similar decisions until it collects all necessary information. Finally, it sums the runtimes and provides the total, reaching a terminal state.
Binary Tree Search Strategy
To manage this decision-making process effectively, DeepRAG uses a binary tree search. This strategy allows the system to explore multiple reasoning paths by treating each decision as a node in a tree. For every subquery, DeepRAG generates two branches:
One branch represents using parametric knowledge (internal knowledge).
The other represents retrieving external documents.
As the system explores the tree, it constructs a retrieval narrative, which is a sequence of subqueries and answers leading to the final response. The binary tree search helps the model evaluate different reasoning paths, deciding when retrieval is necessary and when internal knowledge suffices.
This approach allows DeepRAG to break down complex queries into smaller, manageable subqueries and make adaptive decisions at each step. By navigating the binary tree, the model can balance the trade-off between relying on pre-trained knowledge and retrieving external data, ultimately improving the accuracy and efficiency of the responses. The structured nature of the binary tree search ensures that DeepRAG not only retrieves information when it is essential but also avoids unnecessary retrievals, optimizing computational resources while maintaining answer quality.
Imitation Learning
While binary tree search helps DeepRAG explore reasoning paths, it still needs to learn which paths are the most efficient. This is where imitation learning plays a role. Imitation learning teaches DeepRAG by showing examples of optimal reasoning paths, those that result in correct answers while minimizing retrievals by following the following algorithm.
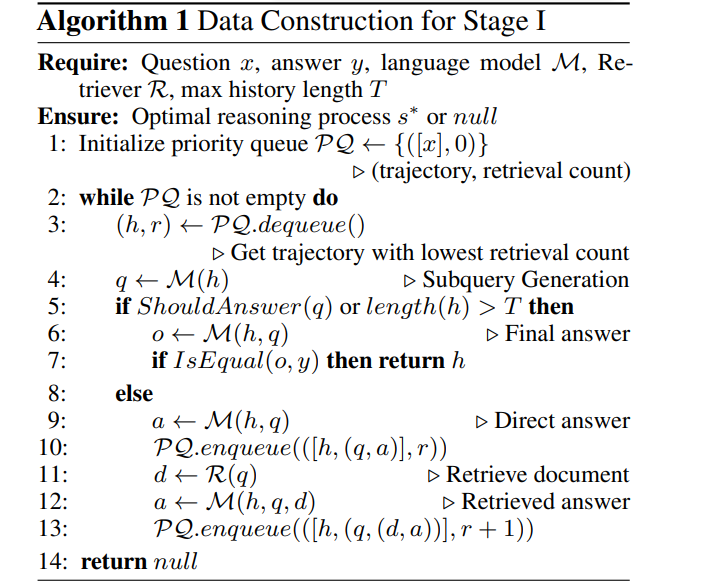
Figure: Algorithm DeepRAG uses to construct optimal reasoning paths.
The above figure outlines how DeepRAG constructs optimal reasoning paths using imitation learning. The system employs a priority queue to explore reasoning trajectories, favoring paths with fewer retrievals. Here’s how the algorithm works:
Initialization: It starts by placing the original question into a priority queue with a retrieval count of zero.
Path Exploration: The algorithm dequeues the path with the fewest retrievals and generates the next subquery.
Decision Making: At each step, the model decides whether to stop and provide a final answer (termination decision) or continue generating subqueries.
Answer Generation: If the model chooses to answer directly, it adds this path back into the queue. If it decides to retrieve documents, it adds the new path with an incremented retrieval count.
Termination: The process continues until the algorithm identifies a reasoning path that reaches the correct answer with the least amount of retrieval.
Chain of Calibration
Even after imitation learning, DeepRAG may struggle with knowing when to retrieve external information versus relying on internal knowledge. To refine its decision-making process, DeepRAG uses a chain of calibration, which fine-tunes the model’s retrieval behavior based on preference pairs, examples that indicate the preferred action (retrieval or internal knowledge) for each subquery.The chain of calibration adjusts the model’s decision-making using the following loss function:
L = - log σ [ β log ( πθ(yw | si, qi) / πref(yw | si, qi) ) - β log ( πθ(yl | si, qi) / πref(yl | si, qi) ) ]
Here is how the formula works:
σ is the logistic function, normalizing the model's outputs.
β is a hyperparameter controlling the penalty for deviating from the preferred decision path.
πθ(yw | si, qi) represents the probability of answering subquery qi in state si using parametric knowledge.
πθ(yl | si, qi) represents the probability of answering the subquery based on retrieved documents.
πref is the reference model used as a baseline for comparison.
This loss function encourages the model to favor the most efficient reasoning path, deciding whether to use internal knowledge or retrieve external data, based on the optimal examples provided during imitation learning. If the model retrieves information unnecessarily or fails to retrieve when needed, the chain of calibration corrects these tendencies, helping the system achieve a balance between efficiency and accuracy.
The following figure illustrates how DeepRAG integrates binary tree search, imitation learning, and chain of calibration to construct efficient reasoning paths. It shows the step-by-step process of query decomposition, decision-making, and model calibration that enables DeepRAG to balance internal knowledge and external retrieval.
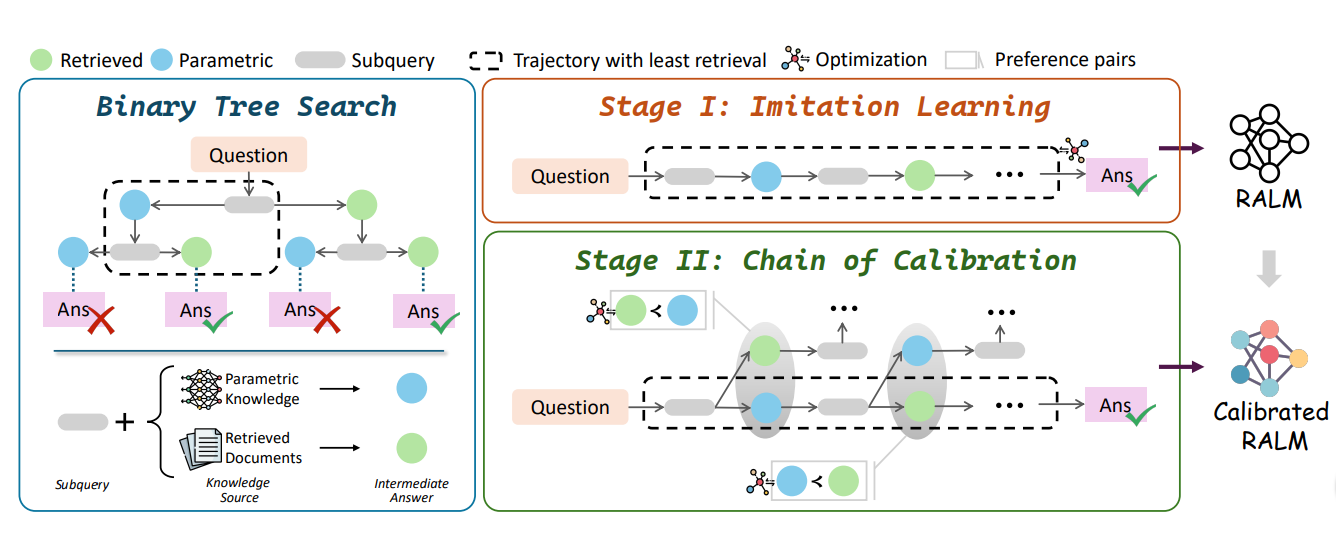
Figure: _An overview of DeepRAG framework comprises three steps_Through the integration of MDP modeling, binary tree search, imitation learning, and the chain of calibration, DeepRAG achieves an adaptive retrieval process capable of handling complex, multi-step questions.
DeepRAG’s Performance on Benchmarks
After refining its retrieval strategy and adaptive reasoning process, DeepRAG demonstrates strong performance across multiple open-domain question-answering (QA) benchmarks. These benchmarks evaluate DeepRAG’s ability to decompose complex queries, make efficient retrieval decisions, and accurately generate answers, even in dynamic or multi-hop scenarios. DeepRAG has been evaluated on five diverse datasets: HotpotQA and 2WikiMultihopQA for multi-hop factual QA, CAG for time-sensitive queries, and PopQA and WebQuestions for open-domain QA tasks. Each dataset presents unique challenges, such as multi-step reasoning, temporal shifts in data, or handling out-of-distribution queries.
On HotpotQA, DeepRAG achieves an F1 score of 51.54, outperforming methods like UAR (34.2) and FLARE (32.0). In 2WikiMultihopQA, which requires complex multi-hop reasoning, DeepRAG scores 53.25 in F1, surpassing baseline models that often struggle with multi-step queries. For time-sensitive tasks like CAG, DeepRAG reaches an Exact Match (EM) score of 59.8, outperforming traditional RAG systems. In open-domain QA datasets such as PopQA and WebQuestions, DeepRAG achieves EM scores of 43.2 and 38.8, respectively, maintaining high accuracy while reducing unnecessary retrievals. These results highlight DeepRAG’s ability to balance retrieval efficiency and answer accuracy, outperforming traditional RAG systems and dense retrievers by effectively deciding when to retrieve external information and when to rely on its internal knowledge.
Integrating DeepRAG with Vector Databases for Enhanced Retrieval
One of DeepRAG’s strengths is its ability to decide when to retrieve external information and when to rely on internal knowledge. However, the quality and efficiency of retrieval also depend on the system it uses to store and search data. This is where vector databases like Milvus and Zilliz Cloud enhance DeepRAG’s performance, offering scalable and efficient solutions for handling large volumes of unstructured data.
Vector databases store data as high-dimensional vectors, allowing for fast and accurate similarity searches. In DeepRAG’s workflow, when the system generates a subquery that requires external information, it can query a vector database like Milvus to find the most relevant documents based on semantic similarity. This approach improves both the speed and relevance of the retrieved data, directly impacting the quality of DeepRAG’s answers.
Milvus is an open-source vector database optimized for high-performance similarity searches, capable of handling billion-scale vector data. Zilliz Cloud, built on top of Milvus, offers a managed cloud-based solution that simplifies scaling and maintenance. These databases provide the infrastructure DeepRAG needs to perform efficient retrievals, especially for large-scale applications.
Example: Customer Support Automation Consider a customer support system integrated with DeepRAG and Milvus to handle complex customer queries. A user submits the question: “How can I transfer my account to another user and ensure my billing information is updated?” This question involves multiple steps and requires information from different sections of a company’s documentation.
Step 1 – Subquery Generation: DeepRAG begins by breaking down the complex query into smaller, manageable subqueries. In this case, it identifies two distinct subquestions: “How to transfer an account to another user?” and “How to update billing information?”. This decomposition allows DeepRAG to focus on answering each part of the user’s request individually, improving both retrieval efficiency and the quality of the final response.
Step 2 – Retrieval with Milvus: Once the subqueries are generated, DeepRAG uses Milvus to search for relevant documents. Each subquery is converted into a vector and matched against the documents stored in Milvus, which are also indexed as vectors. For the first subquery, the system retrieves a document titled “Transferring Account Ownership”, detailing the steps needed to transfer an account. For the second subquery, it finds a document called “Updating Your Billing Details”, which outlines how users can change their payment information. Milvus’s semantic search ensures that only the most relevant documents are retrieved, minimizing unnecessary data.
Step 3 – Answer Assembly: After retrieving the documents, DeepRAG processes the information to extract the most useful details. It reads through the content of the retrieved articles and summarizes the essential steps. For the account transfer subquery, DeepRAG generates a response like: “To transfer your account, go to Settings > Account Management and select ‘Transfer Ownership.’ Enter the new user’s details and confirm the change.” For the billing update, it produces: “To update billing information, visit Billing Settings and click on ‘Edit Payment Method.’ Make the necessary changes and save.” This step ensures that users receive clear, concise instructions tailored to their specific questions.
Step 4 – Final Answer: Finally, DeepRAG combines the individual answers into a coherent response, directly addressing the user’s multi-part query. The system merges the guidance from both subqueries into a seamless reply, providing the user with all the information they need without making them read through multiple documents. This integration of subanswers results in a complete and helpful response that resolves the user's issue efficiently.
In this example, the integration of DeepRAG with Milvus enables the system to handle complex queries efficiently. DeepRAG’s step-by-step reasoning, combined with Milvus’s fast and accurate retrieval, ensures the user gets a precise and complete answer without sifting through irrelevant documents.
This approach highlights how vector databases like Milvus and Zilliz Cloud can enhance DeepRAG’s retrieval process, making it well-suited for real-world applications where efficient and accurate information retrieval is critical.
Future Directions for DeepRAG
While DeepRAG has made significant progress in retrieval-augmented generation, there are areas where future research could further enhance its capabilities:
Multimodal Retrieval Integration: Expanding DeepRAG to handle multimodal data such as images, audio, and videos would greatly broaden its applicability. This enhancement would enable the system to process and retrieve information from diverse sources, allowing it to answer more complex queries that require knowledge beyond text. For example, in a medical setting, DeepRAG could retrieve both textual reports and relevant medical images to provide a more comprehensive response.
Context-Aware Retrieval Decisions: Improving DeepRAG’s ability to make more context-sensitive retrieval decisions is a crucial next step. Currently, the system relies on its MDP-based framework to decide when to retrieve external data, but future iterations could incorporate more nuanced understanding of query intent and context. This would help the model better assess when retrieval is necessary and tailor its approach to complex or ambiguous queries, improving both efficiency and accuracy.
Real-Time and Dynamic Data Retrieval:Enhancing DeepRAG’s ability to access and process real-time data sources would make it more effective for time-sensitive applications. Integrating live data streams, such as news feeds or stock market updates, would allow DeepRAG to handle queries that require up-to-date information. This capability would be especially valuable in domains like finance, news aggregation, or emergency response, where access to the most current data is critical.
Conclusion
DeepRAG advances retrieval-augmented generation by combining adaptive query decomposition with efficient retrieval strategies, leading to more accurate answers while minimizing unnecessary searches. Its strong performance across benchmarks highlights its ability to handle complex, multi-step queries with improved reasoning and retrieval efficiency. While the core model operates independently, integrating DeepRAG with vector databases like Milvus and Zilliz Cloud can further enhance its retrieval capabilities in large-scale applications. With future improvements in multimodal retrieval, context-aware decisions, and real-time data access, DeepRAG is well-positioned to become a versatile and powerful solution for a wide range of complex information retrieval tasks.
Further Resources
Papers:
[2502.01142] DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
[2404.19456] A Survey of Imitation Learning Methods, Environments and Metrics
Robust Markov Decision Processes: A Place Where AI and Formal Methods Meet
Articles:
Keep Reading

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.