




От слов к векторам: Понимание Word2Vec в обработке естественного языка (NLP)
От слов к векторам: Понимание Word2Vec в обработке естественного языка (NLP)
Что такое Word2Vec?
Word2Vec - это модель машинного обучения, которая преобразует слова в числовые векторные представления, чтобы отразить их значения на основе контекста, в котором они встречаются. Разработанная Томасом Миколовым и его командой в Google, она использует большие текстовые массивы данных для понимания взаимосвязей между словами, чтобы представить семантическое и синтаксическое сходство. В отличие от традиционных подходов, таких как одноточечное кодирование, Word2Vec создает плотные, содержательные вкрапления, где похожие слова располагаются ближе в непрерывном векторном пространстве. Word2Vec широко используется в приложениях обработки естественного языка, таких как анализ настроения и рекомендательные системы.
Зачем нам нужен Word2Vec?
Понимание связей и значений слов является основной задачей в Обработке естественного языка (NLP). Традиционные методы, такие как одноточечное кодирование, представляют слова как разреженные, высокоразмерные векторы, где каждое слово не зависит от других. Такой подход не позволяет уловить семантические или синтаксические связи между словами. Например, при одноточечном кодировании векторы для слов "король" и "королева" будут казаться совершенно несвязанными, хотя их значения тесно связаны.
Кроме того, такие разреженные представления неэффективны с вычислительной точки зрения, особенно для больших словарей, и плохо обобщаются на незнакомые слова или контексты. Это ограничение мешает машинам по-настоящему понимать язык, препятствуя прогрессу в таких задачах, как машинный перевод, анализ настроений и ранжирование поиска.
Word2Vec решает эти проблемы, создавая компактные и плотные [вкрапления слов] (https://zilliz.com/ai-faq/what-is-word-embedding), которые отражают отношения между словами на основе того, как они встречаются в тексте. Улавливая как значение слов, так и их контекст, Word2Vec изменил способы машинной интерпретации и обработки человеческого языка, сделав их более эффективными и содержательными.
Как работает Word2Vec?
В основе Word2Vec лежат вкрапления слов, которые представляют собой низкоразмерные [плотные векторы] (https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning), отражающие семантические и синтаксические свойства слов. Word2Vec работает, анализируя большие объемы текста, чтобы узнать отношения между словами. По своей сути это неглубокая нейронная сеть, которая генерирует векторные представления для слов, отражающие их семантические и синтаксические значения. Модель выявляет закономерности в том, как слова встречаются в предложениях, и использует эту информацию для расположения связанных слов ближе друг к другу в непрерывном векторном пространстве.
Основная концепция заключается в том, что похожие векторы представляют слова с похожими значениями или контекстами употребления. Например, слова "король" и "королева" будут иметь близкие векторы с различиями, которые кодируют специфические семантические различия, такие как пол.
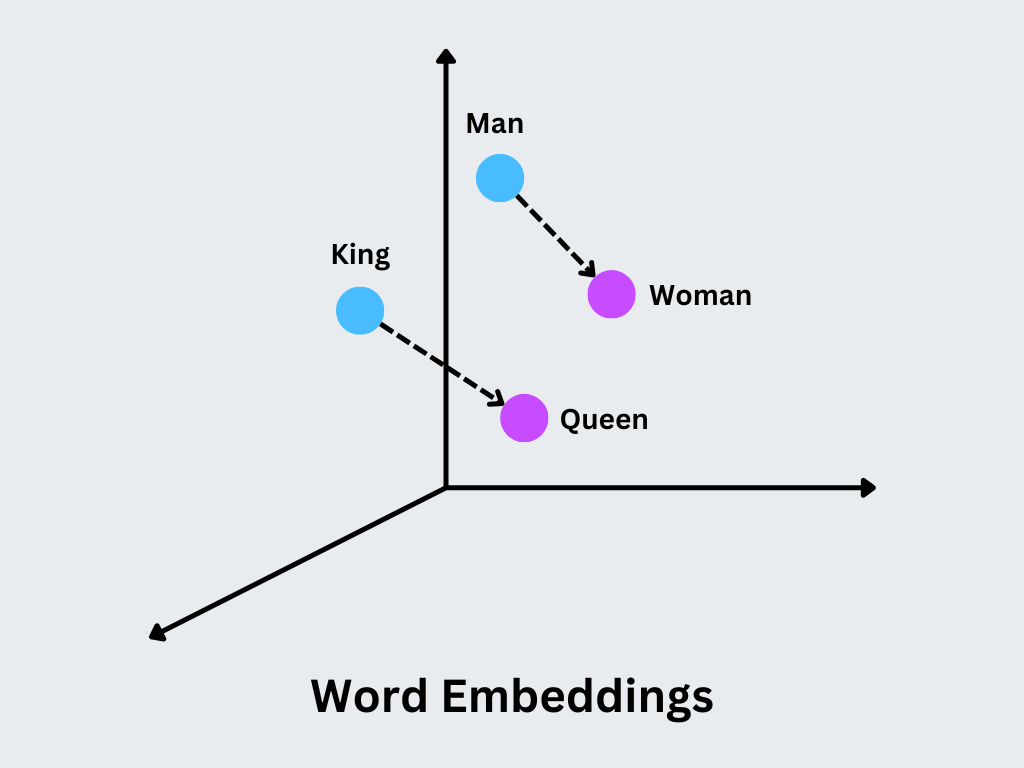 Рисунок Word Embeddings.png
Рисунок Word Embeddings.png
** Рисунок:** Вкрапления слов
Word2Vec предлагает два подхода к генерации вкраплений, в зависимости от того, как обрабатывается контекст:
Continuous Bag of Words (CBOW)
Непрерывный [мешок слов] (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#Bag-of-Words-Models) фокусируется на предсказании целевого слова на основе окружающих его слов. Например, в предложении "Яблоки сладкие и сочные" CBOW использует контекстные слова ("яблоки", "есть", "и" и "сочный") для предсказания целевого слова, например "сладкий".
CBOW эффективен с вычислительной точки зрения, поскольку он усредняет контекстные слова для предсказания цели. Однако он лучше работает с часто встречающимися словами и может испытывать трудности с редкими терминами.
Пример использования: CBOW обычно используется в таких приложениях, как автозаполнение и проверка орфографии, где требуется предсказать пропущенное или следующее слово.
Модель пропущенных грамм
Модель Skip-Gram меняет процесс предсказания на противоположный. Вместо того чтобы предсказывать целевое слово по его контексту, она предсказывает контекстные слова на основе целевого слова. Например, если целевое слово - "сладкий", Skip-Gram предсказывает контекстные слова "яблоки", "есть", "и" и "сочный".
Skip-Gram лучше справляется с редкими словами и особенно эффективен для улавливания более тонких взаимосвязей при работе с большими наборами данных.
Пример использования: Skip-Gram ценен в таких задачах, как создание рекомендательных систем или кластеризация схожих терминов в специализированных областях.
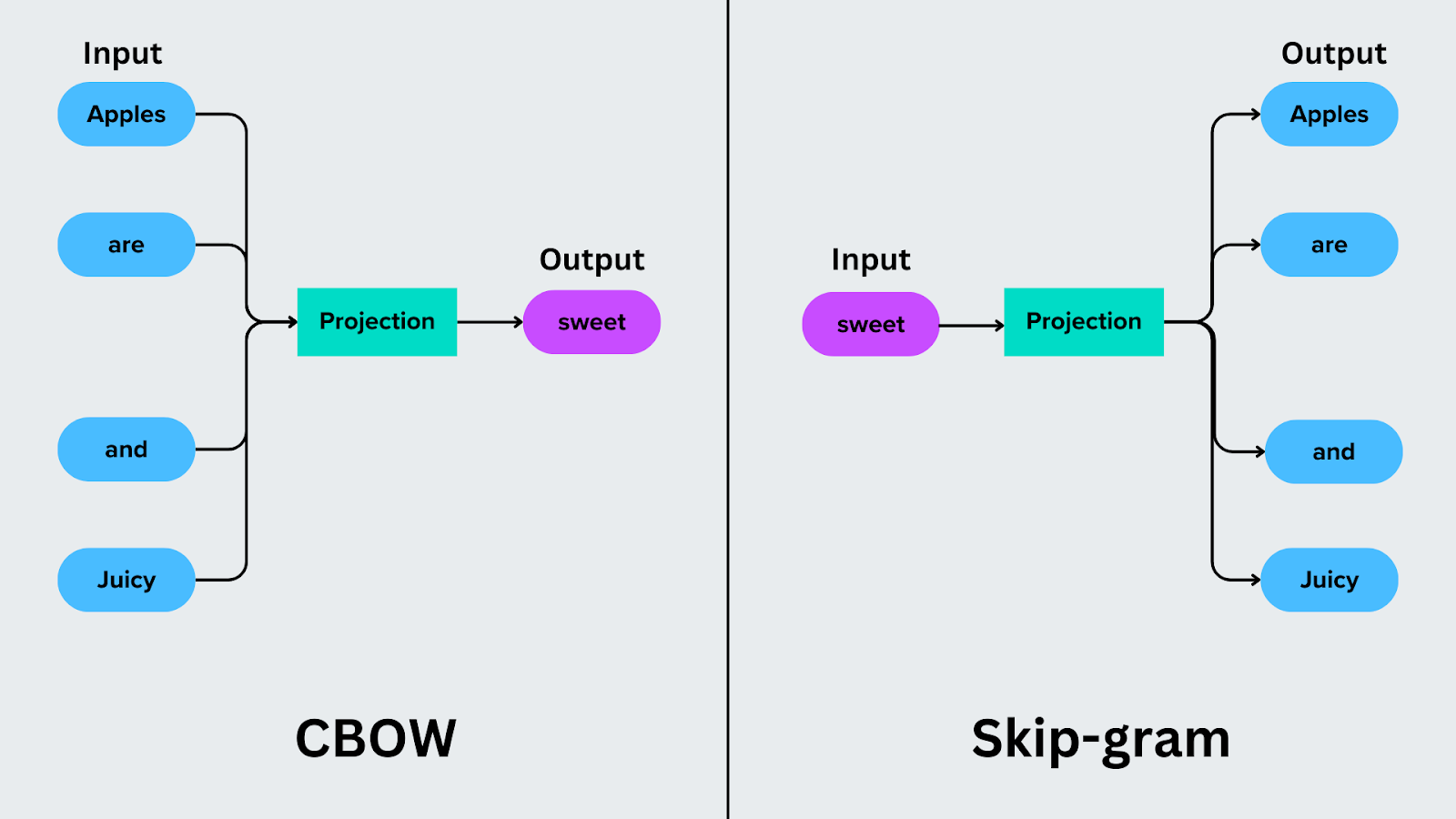 Рисунок - CBOW vs Skip-gram.png
Рисунок - CBOW vs Skip-gram.png
** Рисунок:** CBOW vs Skip-gram
Разница между CBOW и моделью Skip-Gram
Хотя и CBOW, и Skip-Gram нацелены на представление слов в осмысленном виде, они различаются тем, как они обрабатывают и предсказывают слова на основе контекста. Ниже приведено сравнение, чтобы подчеркнуть ключевые различия между этими двумя подходами:
| Файл | Continuous Bag of Words (CBOW) | Skip-Gram | |
|---|---|---|---|
| Цель | Определяет целевое слово, используя окружающий контекст. | Предсказывает контекстные слова на основе целевого слова. | |
| Эффективность | Быстрее обучается. | Медленнее в обучении. | |
| Фокус | Хорошо работает с часто встречающимися словами. | Эффективно справляется с редкими словами. | |
| Сложность | Более простая и эффективная с точки зрения вычислений. | Более сложный и требовательный к вычислениям. | |
| Польза | Подходит для таких задач, как предсказание слов и автокоррекция. | Идеально подходит для специализированных задач, таких как рекомендательные системы. | |
| Контекстное окно | Рассматривайте среднее значение всех контекстных слов. | Оценивайте отдельные контекстные слова по отдельности. | |
| Требования к размеру набора данных | Хорошо работает на небольших наборах данных. | Лучше работает с большими наборами данных. | |
| Пример | Предсказывает "лай" из фразы "Собака ___". | Предсказывает "The", "dog" и "is" от "barking". |
Таблица: CBOW против Skip-Gram
Реализация Word2Vec на Python
Ниже приведена реализация Word2Vec на языке Python с использованием методов CBOW и Skip-Gram. Этот код тренируется на небольшом пользовательском наборе данных для изучения вкраплений слов, демонстрируя, как оба метода работают для выявления отношений между словами на основе их контекста. Обе части кода предназначены для сравнения того, как CBOW и Skip-Gram по-разному изучают отношения между словами, но они имеют одинаковые параметры для справедливого сравнения. Реализацию можно найти ниже в этом Kaggle notebook.
Код
из gensim.models import Word2Vec
# Небольшой, сфокусированный корпус
корпус = [
["кошка", "собака", "лаяла"],
["собака", "преследовал", "кошка"],
["кошка", "сидела", "коврик"],
["собака", "бежала", "быстро"],
["кошка", "бежала", "быстро"],
["собака", "сидела", "коврик"].
]
# Обучение модели CBOW
cbow_model = Word2Vec(
sentences=corpus,
vector_size=10, # Меньший размер вектора для простоты
window=2, # Размер контекстного окна
min_count=1, # Включить все слова
sg=0 # Установить sg=0 для CBOW
)
# Обучение модели скип-грамм
skipgram_model = Word2Vec(
sentences=corpus,
vector_size=10, # Меньший размер вектора для простоты
window=2, # Размер контекстного окна
min_count=1, # Включить все слова
sg=1 # Устанавливаем sg=1 для скип-грамм
)
# Функция для отображения векторов слов и похожих слов
def display_model_results(model, model_name):
print(f"\n--- {имя_модели} ---")
for word in ["cat", "dog"]:
print(f "Вектор слов для '{слово}': {model.wv[word][:5]}...") # Отображение первых 5 значений вектора
similar_words = model.wv.most_similar(word, topn=3)
print(f "Наиболее похоже на '{слово}': {[(w, round(sim, 2)) for w, sim in similar_words]}")
# Отображение результатов модели CBOW
display_model_results(cbow_model, "CBOW Model")
# Отображение результатов модели Skip-Gram
display_model_results(skipgram_model, "Skip-Gram Model")
Выходные данные:
--- Модель CBOW ---
Вектор слов для 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Наиболее похожие на 'кошка': [('собака', 0.54), ('быстрый', 0.33), ('лаял', 0.23)]. Вектор слов для 'собака': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Наиболее похожие на 'собака': [('кошка', 0.54), ('быстро', 0.3), ('бежала', 0.1)]
--- Модель скип-грамм ---
Вектор слов для 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Наиболее похожие на 'кошка': [('собака', 0.54), ('быстрый', 0.33), ('лаял', 0.23)]. Вектор слов для 'собака': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Наиболее похожие на 'собака': [('кошка', 0.54), ('быстро', 0.3), ('бежала', 0.1)]
В части кода CBOW:
Модель обучается с помощью параметра sg=0, который указывает Word2Vec на использование метода Continuous Bag of Words.
CBOW определяет слово, используя контекст окружающих его слов. Например, в предложении ["собака", "преследовал", "кошка"] модель может использовать слова "собака" и "кошка", чтобы предсказать слово "преследовал".
Вектор_размер=10 определяет размер вкраплений слов (сколько чисел представляют каждое слово).
Окно=2 задает контекстное окно, то есть рассматривается не более 2 слов до и после целевого слова.
В части кода Skip-Gram:
Модель обучается с помощью параметра sg=1, который переключает Word2Vec на метод Skip-Gram.
Skip-Gram определяет окружающие слова по заданному целевому слову. Например, если целевое слово - "преследовать", модель предсказывает "собака" и "кошка" в качестве его соседей.
Аналогично CBOW:
vector_size=10 определяет размер вкраплений слов.
window=2 задает диапазон рассматриваемых контекстных слов.
Преимущества Word2Vec
Ниже приведены некоторые ключевые преимущества, которые делают Word2Vec основополагающей техникой в НЛП:
Захватывает семантические отношения: Word2Vec создает вкрапления, в которых семантически схожие слова (например, "король" и "королева") располагаются близко друг к другу в векторном пространстве, что позволяет анализировать и использовать эти отношения в задачах НЛП.
Контекстуальное понимание: Анализируя совместную встречаемость слов в больших корпорациях, Word2Vec улавливает контекстно-зависимые отношения, позволяя моделям лучше понимать значение слов в конкретных контекстах.
Эффективное представление: Вкрапления слов являются плотными и низкоразмерными по сравнению с разреженными представлениями, такими как одноточечное кодирование, что делает их эффективной техникой с точки зрения памяти и вычислительных затрат.
Управление большими словарями: В отличие от старых методов, Word2Vec эффективно масштабируется для больших наборов данных и словарей, что делает его практичным для реальных приложений.
Поддержка трансферного обучения: Предварительно обученные вкрапления Word2Vec можно повторно использовать в различных задачах, что экономит время и вычислительные ресурсы, улучшая результаты.
Арифметика в словах: Word2Vec поддерживает осмысленную векторную арифметику для вычисления аналогий типа "король - мужчина + женщина = королева" непосредственно с помощью вкраплений.
Примеры использования Word2Vec
Word2Vec имеет широкий спектр применения в задачах НЛП. Ниже приведены некоторые из практических и эффективных примеров его использования:
Машинный перевод: Улучшает сопоставление слов между языками, используя вкрапления для выравнивания слов с похожими значениями для повышения точности перевода.
Анализ настроения: Определяет тон текста, анализируя связи слов и контекст, чтобы классифицировать положительные, отрицательные или нейтральные настроения.
Поисковое ранжирование: Улучшает работу поисковых систем благодаря пониманию сходства между поисковыми запросами и проиндексированным контентом, что приводит к получению более релевантных результатов.
Рекомендации продуктов: Сопоставляет предпочтения пользователей с продуктами или услугами, анализируя текстовые описания и находя похожие товары.
Топологическое моделирование: Организует и анализирует большие текстовые массивы данных, объединяя документы в кластеры на основе сходства вкраплений слов.
Автозаполнение текста: Предлагает релевантные слова или фразы, предсказывая контекстуально схожие слова, улучшая пользовательский опыт при наборе текста или использовании инструментов кодирования.
Чатботы: Обеспечивает лучшее понимание пользовательского ввода и контекста, помогая чат-ботам генерировать точные и релевантные ответы.
Ограничения Word2Vec
Несмотря на свои преимущества, Word2Vec имеет и свои ограничения:
Отсутствие понимания контекста: Word2Vec генерирует одно вложение для каждого слова, независимо от его контекста. Например, слово "банк" будет иметь одно и то же векторное представление, независимо от того, относится ли оно к берегу реки или к финансовому учреждению.
Зависимость от данных: Для эффективного обучения требуются большие и качественные наборы текстовых данных. Плохо подобранные или небольшие наборы данных могут привести к неоптимальным вкраплениям.
Работа с редкими словами: Проблемы с редкими словами или терминами, не входящими в словарный запас, поскольку их может быть недостаточно в обучающих данных для создания значимых вкраплений.
Нет представления на уровне предложения: Word2Vec фокусируется на вкраплениях на уровне слов и не предоставляет представления для целых предложений или документов, что ограничивает его сферу применения специфическими задачами NLP.
Игнорирует порядок слов: Модель рассматривает слова в контекстном окне, но не учитывает их последовательность, что может повлиять на понимание грамматики или структуры предложения.
Устаревшая по сравнению с современными моделями: Word2Vec в основном вытеснен такими современными моделями, как BERT, GLoVE и GPT, которые обеспечивают контекстные и более надежные вкрапления.
Преодоление разрыва: от Word2Vec к GloVe, BERT и GPT
Такие предиктивные модели, как Word2Vec, создают вкрапления слов, ориентируясь на локальный контекст с помощью нейронных сетей. Однако их зависимость от близлежащих пар слов влечет за собой ограничение: Они не могут уловить более широкие, глобальные отношения во всем корпусе текстов. Например, хотя Word2Vec отлично справляется с определением ассоциаций слов поблизости, он часто упускает более обширные семантические связи.
Чтобы решить эту проблему, система [GloVe (Global Vectors for Word Representation)] (https://zilliz.com/glossary/glove) использует глобальную статистику кокуррентности для создания вкраплений слов. Она анализирует, как часто слова встречаются вместе во всем корпусе, чтобы уловить как локальный контекст, так и более широкие семантические связи для более полного представления языка.
Совсем недавно такие модели, как BERT (Bidirectional Encoder Representations from Transformers) и GPT (Generative Pre-trained Transformer), вышли за рамки статических вкраплений. BERT ввела контекстные вкрапления, представляя слова по-разному в зависимости от их использования в предложении, а GPT сосредоточилась на генерации связного текста путем понимания последовательного контекста. Эти модели еще больше изменили НЛП, включив динамические представления, учитывающие контекст, и устранив ограничения более ранних методов, таких как Word2Vec и GloVe.
Word2Vec с Milvus: эффективный векторный поиск для приложений НЛП
Word2Vec позволяет создавать вкрапления слов, которые необходимы для таких задач, как семантический поиск, сходство документов и рекомендательные системы, где понимание отношений между словами имеет решающее значение. Однако эффективное управление и запрос обширных коллекций вкраплений может оказаться сложной задачей.
Именно здесь на помощь приходит Milvus, векторная база данных с открытым исходным кодом, разработанная Zilliz. Milvus предоставляет надежное решение для хранения, индексирования и запроса вкраплений Word2Vec или любых других типов вкраплений в масштабе для беспрепятственной интеграции в рабочие процессы NLP. Вот как Word2Vec и Milvus работают вместе:
Эффективное управление вкраплениями слов: Word2Vec генерирует высокоразмерные вкрапления для слов словаря, которые могут значительно увеличиваться в размере при больших наборах данных. Milvus эффективно обрабатывает эти вкрапления путем:
Масштабируемое хранилище: Хранение миллионов вкраплений слов без снижения производительности.
Быстрое извлечение: Оптимизированные алгоритмы обеспечивают быстрый поиск похожих вкраплений, что очень важно для приложений NLP в реальном времени, таких как рекомендательные системы или чат-боты.
Улучшенный семантический поиск: вкрапления Word2Vec отлично справляются с выявлением связей между словами. В сочетании с Milvus эти вкрапления могут использоваться для расширенного семантического поиска. Например:
Поиск синонимов или родственных терминов (например, запрос "король" позволяет получить вкрапления типа "королева" или "принц").
Реализация надежных систем поиска, таких как [Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation), которые опираются на сходство слов для получения лучших результатов.
Упрощенные рабочие процессы НЛП: Milvus упрощает рабочие процессы НЛП с использованием Word2Vec за счет:
Позволяет эффективно хранить и запрашивать предварительно обученные вкрапления Word2Vec.
Поддержка интеграции с механизмами машинного обучения для кластеризации, сходства документов и поиска в реальном времени.
Заключение
Word2Vec изменил работу с языковыми данными, представив вкрапления слов, которые отражают значения и связи слов. Он решил многие проблемы традиционных методов, такие как неспособность уловить семантическое и синтаксическое сходство. Он используется в таких приложениях, как анализ настроения, перевод и рекомендательные системы. Несмотря на свои недостатки, Word2Vec заложил основу для многих достижений в этой области и повлиял на разработку более сложных моделей, таких как GLoVE, BERT и GPT.
Вопросы и ответы по Word2Vec
- **Что такое Word2Vec и почему он важен?
Word2Vec - это модель машинного обучения, которая создает плотные векторные представления слов, называемые вкраплениями слов, на основе их контекста. Она важна, поскольку позволяет улавливать взаимосвязи и значения слов для таких задач НЛП, как анализ настроения, перевод и поиск.
- **Чем Word2Vec отличается от традиционных методов представления слов?
В отличие от традиционных методов, таких как одноточечное кодирование, которые представляют слова в виде разреженных векторов без присущих им связей, Word2Vec создает плотные вкрапления, которые фиксируют семантическое и синтаксическое сходство между словами, что делает его гораздо более эффективным и значимым.
- Какие основные архитектуры используются в Word2Vec?
Word2Vec имеет две основные архитектуры: Continuous Bag of Words (CBOW) и Skip-Gram. CBOW определяет целевое слово из окружающего контекста, а Skip-Gram выявляет контекстные слова по заданному целевому слову. Каждая из них имеет свои преимущества в зависимости от конкретного случая использования и набора данных.
- **Каковы основные сценарии использования Word2Vec?
Word2Vec используется в таких приложениях, как анализ настроения, машинный перевод, рекомендательные системы, ранжирование поиска, моделирование тем и разработка чатботов. Его способность понимать отношения между словами делает его универсальным для различных задач НЛП.
- **Каковы ограничения Word2Vec?
У Word2Vec есть несколько недостатков, включая отсутствие понимания контекста (например, она не различает разные значения одного и того же слова), зависимость от больших наборов данных для обучения, неспособность уловить порядок слов или смысл на уровне предложения. Эти недостатки привели к разработке более совершенных моделей, таких как GloVe, BERT и GPT.
Связанные ресурсы
- Что такое Word2Vec?
- Зачем нам нужен Word2Vec?
- Как работает Word2Vec?
- Реализация Word2Vec на Python
- Преимущества Word2Vec
- Примеры использования Word2Vec
- Ограничения Word2Vec
- Преодоление разрыва: от Word2Vec к GloVe, BERT и GPT
- Word2Vec с Milvus: эффективный векторный поиск для приложений НЛП
- Заключение
- Вопросы и ответы по Word2Vec
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно