




Generative AI Uncovered: Как машины теперь понимают и генерируют текст, изображения и идеи

TL;DR: Генеративный ИИ (GenAI) - это подмножество технологий искусственного интеллекта, предназначенных для создания нового контента, начиная от текста и изображений и заканчивая музыкой и видео. Он работает на основе изучения закономерностей и особенностей огромного количества данных, а затем использует эти знания для создания оригинальных результатов. Ключевыми примерами GenAI являются генераторы текста, такие как GPT (Generative Pre-trained Transformer), создатели изображений, такие как DALL-E, и системы синтеза аудио. Эти модели ИИ особенно ценятся за их способность автоматизировать творческие задачи, повышать производительность и способствовать инновациям в различных отраслях. Однако они также создают проблемы, такие как возможность генерирования недостоверной информации и этические проблемы, связанные с авторскими правами и авторством.
Generative AI Uncovered: Как машины теперь понимают и генерируют текст, изображения и идеи
Представьте себе мир, в котором машины активно творят - создают истории, музыку и произведения искусства, а не просто выполняют команды. Это становится реальностью с помощью генеративного ИИ, который расширяет границы творчества и технологий.
Здесь мы обсудим современные способы применения генеративного ИИ, его работу и этические проблемы, которые он поднимает, чтобы понять эту технологию и ее более широкие последствия.
Что такое генеративный ИИ?
**Традиционные модели ИИ, такие как [нейронные сети] (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) и алгоритмы машинного обучения, сосредоточены на выявлении закономерностей для выполнения таких задач, как регрессия или [классификация] (https://zilliz.com/glossary/classification). Генеративный ИИ, с другой стороны, делает еще один шаг вперед, распознавая связи внутри данных, включая звуки, изображения и текст. Он использует эти связи для создания нового материала на основе того, что он узнал, вместо того чтобы просто классифицировать или предсказывать.
Например, при обучении на тысячах портретов генеративный ИИ изучает характеристики лица, такие как расположение черт и стиль освещения, что позволяет ему создавать совершенно новые, но реалистично выглядящие портреты. При создании текстов генеративный ИИ анализирует большие объемы текстов, чтобы уловить поток, тон и выбор слов, которые затем используются для построения оригинальных предложений или историй.
Популярные генеративные модели включают Claude и GPT-4 для генерации текста, Midjourney и DALL-E3 для генерации изображений по текстовым подсказкам, а также Jukedeck. Jukedeck сочиняет оригинальную музыку, применяя выученные шаблоны.
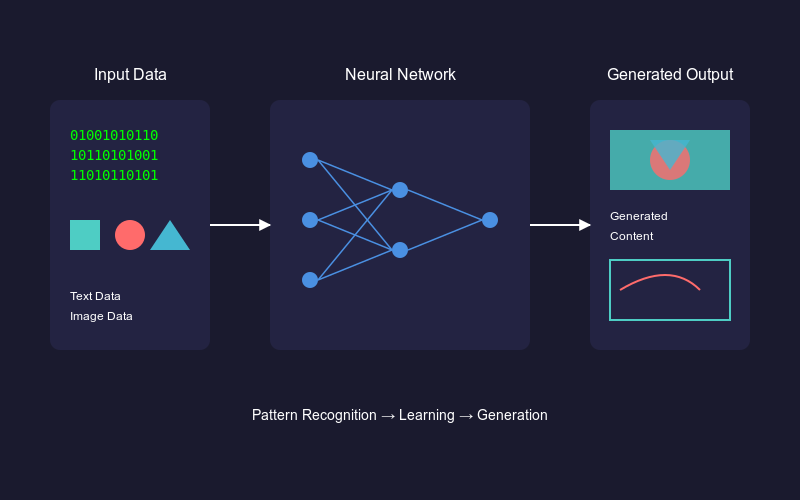 Рисунок - Архитектура генеративного ИИ - от данных к творению.png
Рисунок - Архитектура генеративного ИИ - от данных к творению.png
Рисунок: Архитектура генеративного ИИ: от данных к созданию
Как работает генеративный ИИ?
По своей сути генеративный ИИ учится на огромных объемах данных, чтобы уловить глубинные закономерности и взаимосвязи. Вот как он работает на практике.
Изучение закономерностей и распределения данных
Генеративные модели исследуют большие массивы данных, например текстовые документы, аудиозаписи или фотографии, чтобы определить, как сосуществуют различные характеристики. В Обработка естественного языка (NLP) модель изучает, как слова сочетаются друг с другом, создавая предложения и выражая смысл. Благодаря такому глубокому пониманию ИИ может создавать контент, который кажется естественным и соответствующим контексту.
Генерирование новых данных
После того как модель усвоила эти шаблоны, она может приступить к созданию нового контента:
Использование случайного шума (для изображений): Диффузионные и визуальные генеративные модели начинают с генерации случайного шума, а затем применяют серию шагов денуазинга для создания целостного изображения. Этот процесс денуации позволяет диффузионным моделям создавать уникальные визуальные образы, сохраняя при этом основные элементы обучающих данных.
Токенизация (для текста): При генерации текста модели разбивают предложения на лексемы - слова или фразы. Предсказывая следующую лексему в последовательности, ИИ строит предложения, логично переходящие из одного в другое.
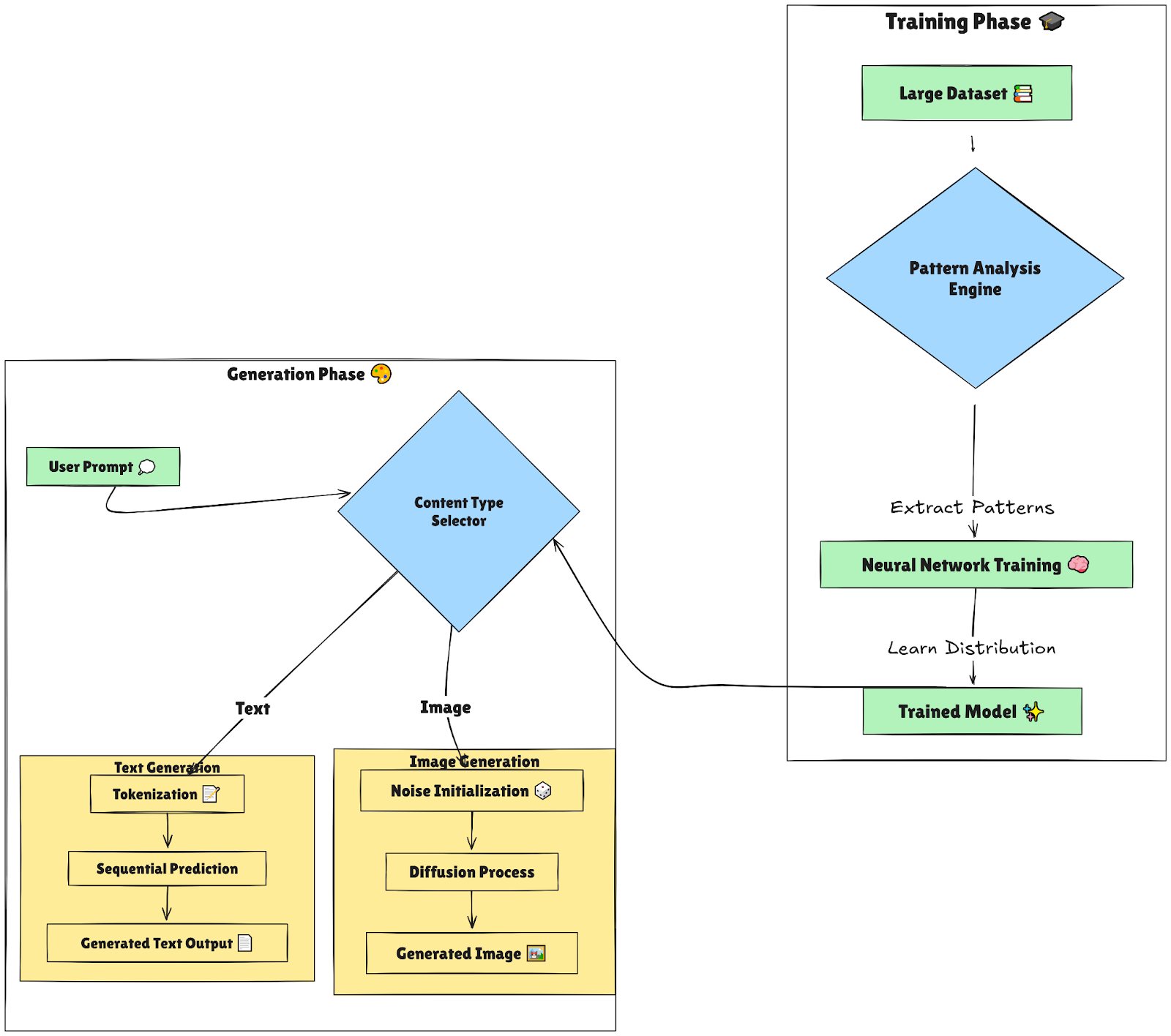 Рисунок - Рабочий процесс генеративного ИИ.png
Рисунок - Рабочий процесс генеративного ИИ.png
Рисунок: Рабочий процесс генеративного ИИ
Типы генеративных моделей ИИ
Под зонтик генеративного ИИ подпадают различные типы моделей, которые имеют весьма неоднородные механизмы генерации новых данных.
Генеративные адверсарные сети (GAN)
**Генеративные адверсарные сети, или ГАС, ** являются одним из самых революционных подходов в генеративном ИИ. По своей сути GAN состоят из двух нейронных сетей, вступивших в творческий поединок. Первая, называемая генератором, пытается создать данные, которые имитируют обучающий набор данных, например реалистичные изображения или реалистичные видео. Второй, известный как дискриминатор, выступает в роли критика, пытаясь отличить реальные данные от творений генератора. Благодаря этому состязательному процессу генератор со временем совершенствуется и учится создавать настолько реалистичные данные, что даже дискриминатор оказывается обманутым. GAN использовались для генерации гиперреалистичных изображений, создания глубоких подделок и улучшения данных для задач машинного обучения. Такие приложения, как StyleGAN, генерирующий потрясающе детализированные человеческие лица, и CycleGAN, переводящий изображения из одной области в другую (например, превращающий фотографии в картины), демонстрируют огромный потенциал этой технологии.
Вариационные автокодировщики (VAE)
В то время как GAN полагаются на конкуренцию, вариационные автокодировщики (VAE) используют более структурированный подход к генеративному ИИ. VAE кодируют входные данные в сжатое латентное пространство, а затем декодируют их обратно, чтобы восстановить оригинал или создать новые вариации. Отличительной чертой VAE является их вероятностный подход к кодированию, гарантирующий, что латентное пространство является гладким и непрерывным. Это делает VAE идеальными для создания вариаций данных, таких как морфинг одного лица в другое или интерполяция между различными объектами. Помимо генерации, VAE также используются для таких задач, как сжатие данных и обнаружение аномалий. Например, они могут моделировать "нормальные" модели данных и выделять отклонения, что полезно для выявления мошенничества или выбросов в наборах данных.
Диффузионные модели
Диффузионные модели представляют собой новую волну генеративного ИИ, предлагая замечательные результаты в таких задачах, как генерация изображений. Эти модели вдохновлены естественным процессом диффузии, в котором порядок теряется со временем, подобно капле чернил, растекающейся в воде. Диффузионные модели учатся обращать этот процесс вспять: начиная со случайного шума, они постепенно улучшают данные, пока не появится последовательный и реалистичный результат. Такой итеративный подход позволяет генерировать высокодетализированные и сложные данные. Развитие диффузионных моделей было отмечено такими приложениями, как Stable Diffusion и DALL-E 2, которые переосмыслили возможности синтеза изображений, включая создание великолепных визуальных эффектов из простых текстовых описаний.
Модели авторегрессии
Авторегрессионные модели идеально подходят для ситуаций, когда ключевыми являются последовательные данные, такие как текст, музыка или речь. Эти модели предсказывают каждую часть данных по одному шагу за раз, используя предыдущие результаты в качестве исходных данных для будущих предсказаний. Эта последовательная природа позволяет авторегрессионным моделям отлично справляться с такими задачами, как генерация текста, где важны связность и контекст. Например, такие модели, как GPT (Generative Pre-trained Transformer) , могут писать эссе, рассказы и даже фрагменты кода, имитируя человеческое творчество. В аудио WaveNet использует тот же принцип для создания реалистичной речи и высококачественного синтеза аудио. Способность генерировать связный, учитывающий контекст контент делает авторегрессионные модели незаменимыми в обработке естественного языка и генеративных задачах.
Трансформаторы
[Модели на основе трансформеров (https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles) являются основой современного генеративного ИИ. Они работают благодаря механизму внимания, который позволяет им фокусироваться на релевантных входных данных и улавливать дальние зависимости. Их универсальность охватывает множество областей, от генерации человекоподобного текста (например, GPT-4) до создания потрясающих визуальных эффектов (например, DALL-E) и обработки аудио (например, Whisper). Трансформеры хорошо справляются с такими задачами, как генерация текста, синтез изображений и мультимодальные приложения, эффективно и контекстно обрабатывая данные. В отличие от моделей, специфичных для конкретной области, трансформеры адаптируются к различным типам данных, что делает их незаменимыми в самых разных приложениях - от разговорного ИИ до творческих инструментов, закрепляя их роль в качестве краеугольного камня инноваций генеративного ИИ.
Генеративный ИИ продолжает развиваться, и каждый тип модели привносит уникальные сильные стороны и возможности в различные творческие и практические приложения. Выбор зависит от ваших конкретных потребностей и приложения, которое вы создаете - будь то создание реалистичных изображений, сочинение музыки или написание захватывающих рассказов.
Сравнение с традиционными моделями ИИ
Генеративный ИИ отличается от традиционных подходов к ИИ. Вот как можно сравнить эти стратегии:
| Аспект | Генеративный ИИ | Дискриминативный ИИ |
| Цель | Создание новых данных, похожих на обучающие данные | Классификация или предсказание результатов на основе входных данных |
| Обработка данных | Изучает все распределение данных | Изучает границы принятия решений между классами |
| Примеры | GANs, VAEs, Transformers, Diffusion Models | CNNs, SVMs, Random Forests, Logistic Regression |
| Типичные приложения | Синтез изображений, генерация текстов, аудио композиции | Классификация изображений, обнаружение объектов, классификация текстов |
| Требования к обучению | Большие наборы данных с подробными характеристиками и шаблонами | Маркированные наборы данных с четкими различиями между классами |
| Сложность | Часто требует больших вычислительных ресурсов | Обычно менее требователен к вычислениям |
| Сильные стороны | Обеспечивает творческую генерацию контента и реалистичный синтез | Высокая точность в задачах классификации и прогнозирования |
Генеративный ИИ: преимущества и проблемы реального мира
Благодаря творческому подходу к решению проблем, проектированию и созданию, генеративный ИИ стал полезным инструментом для профессионалов в различных областях. Позволяя людям составлять текст, генерировать визуальные образы, экспериментировать с музыкой или кодом, он меняет методы работы. Однако, несмотря на эти преимущества, существуют реальные проблемы, связанные с генеративным ИИ.
Преимущества
Автоматизированное создание контента: Генеративный ИИ поддерживает творческие задачи в писательстве, дизайне и музыке. Писатели используют его для подготовки идей, а дизайнеры создают шаблоны для запуска проектов. Музыканты также могут экспериментировать с новыми композициями перед записью. Это ускоряет творческий процесс, оставляя место для человеческих прикосновений.
Персонализированный опыт: Генеративный ИИ помогает создавать индивидуальные рекомендации, соответствующие интересам пользователя. Он анализирует прошлое поведение, чтобы создавать релевантную рекламу и контент. В маркетинге и электронной коммерции такой персонализированный подход усиливает связь с аудиторией.
Вдохновение новыми идеями: Генеративный ИИ рождает свежие идеи, особенно в области исследований и дизайна продуктов. Он может предлагать новые соединения в таких областях, как фармацевтика. Творческий подход ИИ предлагает отправные точки, которые эксперты могут доработать.
Создание дополнительных данных: Генеративный ИИ может создавать синтетические данные для областей, где реальные данные скудны или дорогостоящи. Это ценно в таких областях, как здравоохранение, помогая обучать модели для диагностики. Синтетические данные помогают улучшить модели, сохраняя их качество.
Вызовы:
Галлюцинации: Это относится к явлению, когда модель генерирует неверную, сфабрикованную или вводящую в заблуждение информацию, которая представляется как фактическая или точная.
Высокие требования к данным и вычислительным мощностям: Генеративный ИИ требует больших массивов данных и передовых вычислений. Задачи с высоким разрешением, такие как генерация изображений, требуют мощного оборудования и длительного времени обучения. Эти требования могут ограничить доступ для небольших авторов и компаний.
Обеспечение качества и согласованности: Производство высококачественного контента с помощью генеративного ИИ может быть сложной задачей. Модели могут испытывать трудности с согласованностью или создавать повторяющиеся результаты. В таких областях, как медицинская визуализация, поддержание точности очень важно.
Этические соображения: Генеративный ИИ вызывает этические проблемы, включая предвзятость и потенциальное злоупотребление. Например, глубокие подделки могут создавать обманчивый контент. Тщательный мониторинг результатов работы ИИ - это ключ к предотвращению дезинформации и недобросовестных действий.
Приватность и безопасность данных: Генеративный ИИ опирается на большие массивы данных, что может привести к риску для конфиденциальности. При неправильном обращении конфиденциальная информация может быть повторена моделями. Надежные гарантии конфиденциальности очень важны, особенно в таких отраслях, как здравоохранение.
Необходимость четкого регулирования: По мере развития генеративного ИИ растет и потребность в регулировании. Этические стандарты и рекомендации помогают обеспечить пользу ИИ для общества. Четкие правила снижают вероятность злоупотреблений, таких как распространение дезинформации или создание спама.
Дополненная генерация с извлечением информации (RAG) и GenAI
Хотя многие генеративные модели, в частности большие языковые модели (БЯМ), способны генерировать различные типы контента, у них есть ограничения. Одной из самых больших проблем является проблема "галлюцинаций", под которой понимается явление, когда модель генерирует неверную, сфабрикованную или вводящую в заблуждение информацию, которая представляется как фактическая или точная. Это происходит потому, что генеративные модели обучаются на автономных и общедоступных данных, поэтому они не могут генерировать контент, связанный с самыми свежими или закрытыми данными.
Retrieval Augmented Generation (RAG) - это методология обработки естественного языка, которая расширяет возможности генеративных моделей путем их интеграции с компонентами поиска. Такой подход позволяет модели динамически получать внешнюю информацию, а затем генерировать ответы, основанные как на полученных данных, так и на ее внутренних знаниях.
Система RAG включает в себя векторную базу данных, например Milvus, модель встраивания и большую языковую модель (LLM). Система RAG сначала использует модель встраивания для преобразования документов в векторные вкрапления и сохраняет их в векторной базе данных. Затем она извлекает релевантную информацию для запроса из этой векторной базы данных и предоставляет полученные результаты в LLM. Наконец, LLM использует полученную информацию в качестве контекста для создания более точных результатов.
 Рисунок - RAG workflow.png
Рисунок - RAG workflow.png
Вопросы и ответы
**1. Что может создать генеративный ИИ? Только ли для текста?
Генеративный ИИ может создавать не только текст, но и 3D-модели, музыку, фотографии и фильмы, комбинируя шаблоны из примеров для создания уникального контента, например музыки или пейзажей.
**2. Чем генеративный ИИ отличается от других инструментов ИИ?
Генеративный ИИ создает оригинальный контент, например новые изображения или истории, в то время как стандартный ИИ в основном распознает или предугадывает существующие данные, например определяет кошку.
**3. Существуют ли этические проблемы с генеративным ИИ?
К числу проблем, связанных с генеративным ИИ, относятся вопросы конфиденциальности и потенциальное усиление предубеждений, вызванных обучающими данными. Он может создавать реалистичные изображения или видео, как глубокие подделки, что делает его ответственное использование необходимым для предотвращения дезинформации и недобросовестных действий.
**4. Где в наши дни используется генеративный ИИ и какое влияние он оказывает?
Генеративный ИИ используется в различных областях, включая обслуживание клиентов, здравоохранение, игры и музыку. Он предлагает быстрые решения и способствует развитию инновационных подходов в разных отраслях.
**5. Как обстоят дела с векторными базами данных и почему они необходимы для генеративного ИИ?
Векторные базы данных хранят сложные паттерны данных, необходимые для генеративного ИИ, позволяя быстро находить информацию для создания контента в режиме реального времени и повышая контекстуальную точность результатов.
Связанные ресурсы
- Что такое генеративный ИИ?
- Как работает генеративный ИИ?
- Типы генеративных моделей ИИ
- Сравнение с традиционными моделями ИИ
- Генеративный ИИ: преимущества и проблемы реального мира
- Дополненная генерация с извлечением информации (RAG) и GenAI
- Вопросы и ответы
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно