




ベクトルデータベースによる音声類似度検索の拡大縮小
MilvusやZilliz Cloudのようなベクトルデータベースが、いかに効率的なオーディオ類似性検索を大規模に実現し、音楽推薦やオーディオ検索アプリケーションを変革するかをご覧ください。
想像してみてほしい。よく覚えていない曲を、アプリに向かってハミングするだけで、瞬時にすべての詳細がポップアップ表示されるのだ。魔法のように聞こえるでしょう?そうではなく、これはオーディオ類似検索なのだ。オーディオコンテンツが爆発的に増加している今日の世界では、効率的なオーディオ類似性検索は、音楽の推薦からリアルタイムのコンテンツ検索、さらには複雑なオーディオ分類に至るまで、あらゆるものを強化するために不可欠です。オーディオデータの膨大な量が数百万(さらには数十億)にも膨れ上がる中、従来の検索方法では追いつくことができません。ベクトルデータベースは、オーディオ信号を高次元埋め込みデータに変換することで、スケーラブルで超高速な類似性検索を可能にするゲームチェンジャーです。ベクターデータベースがどのように大規模なオーディオ類似性検索を実現するのか、詳しく見ていきましょう。
オーディオ類似検索の理解
オーディオ類似検索とは何か?
オーディオ類似性検索](https://milvus.io/docs/audio_similarity_search.md)の核心は、与えられたクエリと密接に一致するオーディオを見つけ、検索することです。メタデータやトランスクリプションに依存する従来のキーワード検索に頼る代わりに、このテクノロジーはピッチ、音色、リズムなどのオーディオ特性を分析する機械学習モデルを使用し、より微妙で正確な検索を提供します。
よくある使用例
音楽レコメンデーション** - Spotifyのようなアプリは、頻繁に再生される曲のオーディオ特性を分析し、類似の曲を提案することで、ユーザー体験を向上させる。
ポッドキャスト検索** - ユーザーは、自分の好みに基づいて、似たような内容、声、トーン、またはテーマのポッドキャストを簡単に探すことができます。
音声類似性** - セキュリティ・アプリケーションや音声アシスタントで使用され、話し手の身元を検出したり、話し言葉を一致させたりします。
環境音認識** - 動物の鳴き声を認識することによる野生動物のモニタリングや、音声を手がかりに地震や地滑りの深刻度を追跡することによる災害対応管理に使用されます。
従来の音声検索における課題
従来の音声検索は、手動で割り当てられたタグや音声データのトランスクリプションであるキーワードに大きく依存していました。このアプローチは非常に正確なメタデータを必要とし、豊富なオーディオの特徴を無視するため、検索が困難で不正確になります。さらに、データセットが大きくなるにつれて、手動でオーディオファイルにタグ付けし、インデックスを付けることは非現実的になる。したがって、埋め込みとベクトルデータベースを使用した最新のアプローチにより、大規模な音声検索が可能になります。
オーディオ検索におけるベクトルデータベースのマジック
そもそもベクトルデータベースとは?
ベクトルデータベースとは、テキスト、画像、動画、音声など、あらゆる種類の非構造化データをベクトル埋め込みの形で保存、索引付け、検索できる特殊なデータベースです。 埋め込みは、データの本質的な特徴をとらえた高次元の数値表現(ベクトル)です。これらのエンベッディングは、クエリと格納されたデータを数学的に比較することで類似検索を実行し、効率的で正確な検索を可能にします。ベクトルデータベースは、大規模データに対するスケーラビリティ、リアルタイム処理、高速検索などの機能を備えており、実世界での応用が可能である。
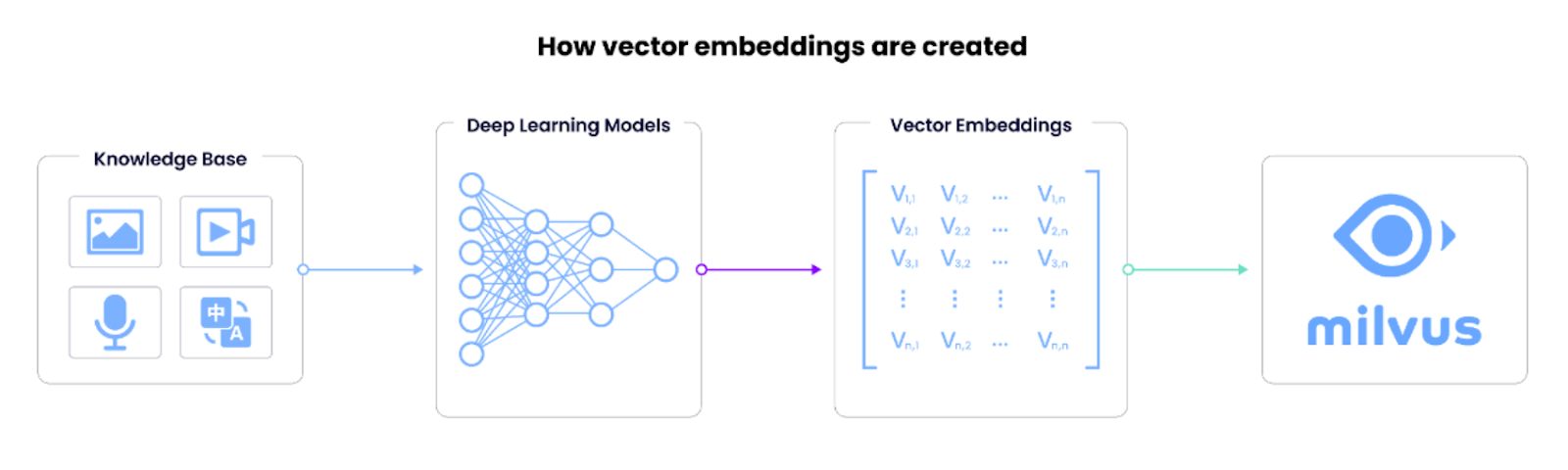
非構造化データからのベクトル埋め込み作成
ベクトルデータベースは埋め込みデータをどのように格納し、インデックスを付けるのか?
ベクトル埋め込みは、効率的な検索を支援するメタデータとともにベクトルデータベースに格納されます。ベクトルインデキシングは、ベクトル埋め込みをインテリジェントに格納し、検索時間を最小化するのに役立ちます。一般的なインデックス技術は、IVF (Inverted File Index)とHNSW (Hierarchical Navigable Small World)である。これらは検索時間を最小化するようにデータセットを分割する。
一般的なベクトルデータベース - MilvusとZilliz Cloud
Milvusはオープンソースのベクトルデータベースで、GPUアクセラレーションとHNSW、IVF、PQのような近似最近傍(ANN)アルゴリズムをサポートしており、音声類似検索、画像検索、推薦システムなどのアプリケーションに最適です。Zilliz Cloudは、Milvusのフルマネージド、クラウドネイティブ版であり、自動スケーリング、高可用性、エンタープライズグレードのセキュリティを備えたサーバーレスインフラストラクチャを提供する。これらのデータベースは、最小限の運用オーバーヘッドで大規模なベクトル検索タスクを効率的に処理することを可能にする。
音声埋め込みが類似検索を可能にする ## How Audio Embeddings Enable Similarity Search
音声埋め込みとは?
オーディオエンベッディングは、ピッチ、テンポ、リズム、音色などの主要な音響特性を捉えたオーディオ信号の数値表現です。このエンベッディングを利用することで、テキストのメタデータに依存することなく、固有の音響特性に基づいてオーディオクリップを直接比較することができます。
オーディオ埋め込みを生成するためのさまざまなテクニックは何ですか?
エンベッディングを作成する前に、生のオーディオ信号は、リサンプリング(一貫性を保つためにサンプルレートを標準化する)、ノイズ除去(不要な背景音を除去する)、セグメンテーション(意味のあるチャンクにオーディオを分割する)などの前処理ステップを受けます。
次に、さまざまな手法で主要な音声の特徴を抽出します:
MFCC(Mel-Frequency Cepstral Coefficients)**です:この特徴量は、音のスペクトル形状を捉えることで人間の聴覚を模倣しており、音声や音楽の分析に有用です。
スペクトログラム**:スペクトログラムは、ピッチ、強度、ハーモニックストラクチャーの変化を強調し、時間経過に伴う周波数の視覚的表現であり、ディープラーニングモデルの入力として広く使用されている。
クロマベースの特徴量**:ピッチクラスの分布を強調することで、オーディオ信号のトーンコンテンツを捉えます。
特徴量が抽出されると、深層学習ベースのモデルはさらにそれを処理して高次元の埋め込みを生成する:
OpenL3:OpenL3:マルチモーダルデータセットで学習されたディープオーディオ表現モデルで、環境音の認識や音楽の類似性などのタスクのために、幅広いオーディオパターンを捉える。
YAMNet**:AudioSetデータセットで学習したMobileNetベースのモデルで、音声、楽器、環境音など500以上のサウンドカテゴリを分類し、埋め込みデータを抽出します。
VGGish**:VGGにインスパイアされたディープニューラルネットワークで、YouTube動画で学習し、オーディオイベントの検出やコンテンツベースの検索などのタスクに適用可能な一般的なオーディオ特徴を抽出するように設計されています。
エンベッディングが生成されると、ベクトルデータベースに保存され、インデックス化されるため、高速でスケーラブルな類似検索が可能になる。
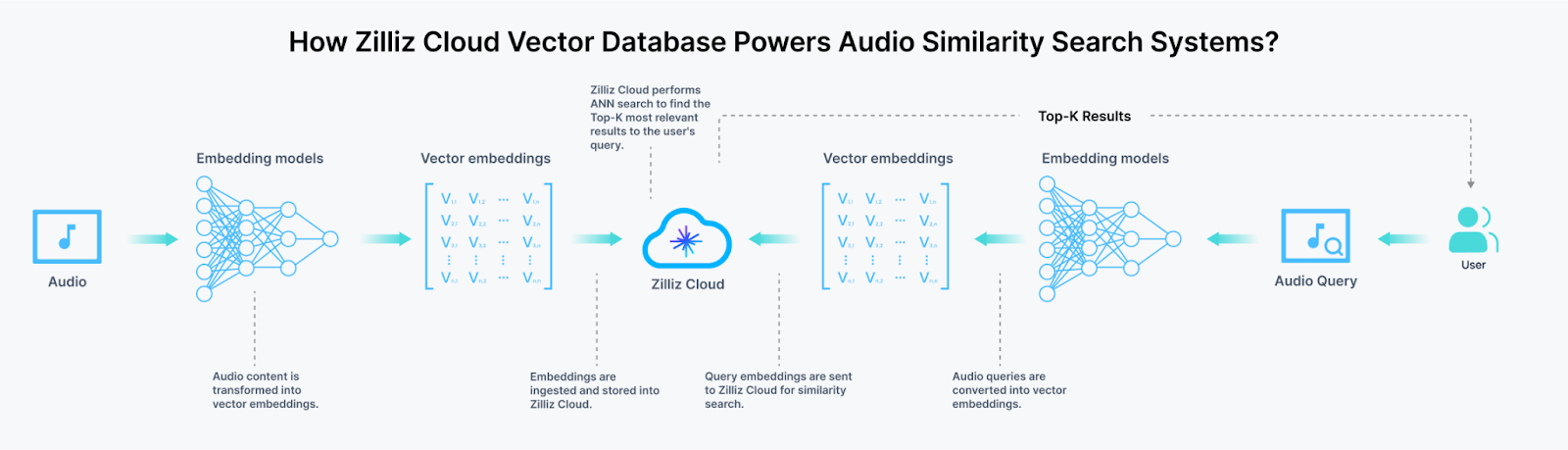
Zilliz Cloudによる音声類似性検索
ベクトルデータベースによる音声類似検索の拡張
オーディオデータセットには何百万ものファイルが含まれる可能性があるため、効率的な検索と取得を実行することが課題となります。ベクターデータベースは、高度な検索アルゴリズムと最適化されたインデックス戦略を提供することで、オーディオ検索システムをスケーラブルにする上で重要な役割を果たします。
大規模オーディオデータセットの管理
ベクトルデータベースが提供するバッチ処理、分散ストレージ、GPUアクセラレーテッドインデキシングなどのテクニックを利用することで、大規模なオーディオデータセットの取り扱いが可能になります。これらの技術により、パフォーマンスを低下させることなく、大量のオーディオエンベッディングを処理することができます。
効率的な検索のためのインデックス戦略
ベクターデータベースは、以下のようなインデックス作成技術を用いて類似検索を最適化します:
- HNSW (Hierarchical Navigable Small World)** - グラフベースのインデックス作成手法で、埋め込みノードの近接ベースの接続を多層に構築する。上位層にはほとんど接続されていないノードが含まれ、下位層にはより密な接続が含まれる。新しいクエリが来ると、上から下へと走査が行われる。
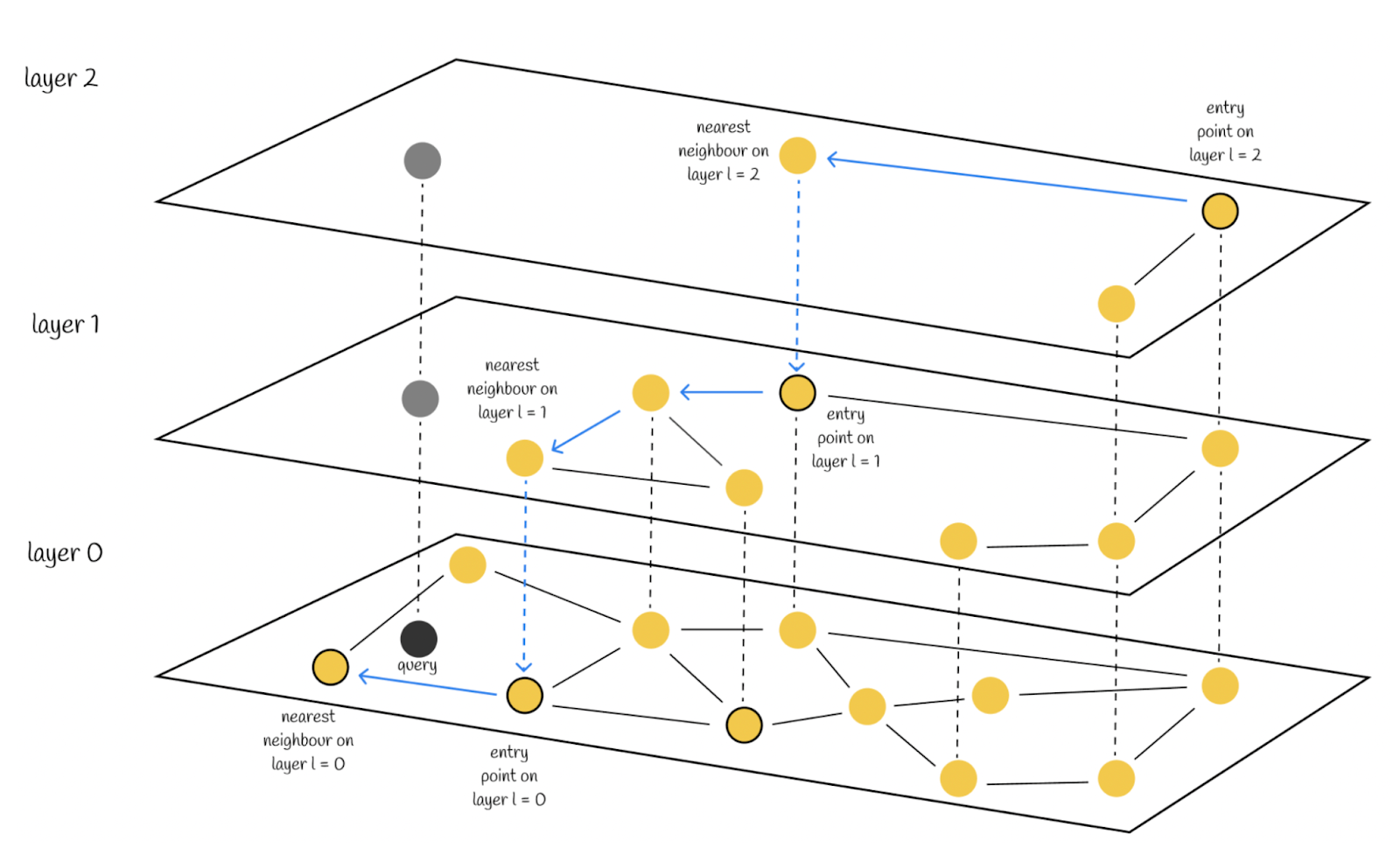
HNSWアルゴリズムでの探索 (出典)
IVF (Inverted File Index)** - K-meansクラスタリングのような技術を用いてデータセット全体をクラスタに分割し、新しいクエリが来たときに最も類似したクラスタを見つけ、さらにその中で検索を行う。
PQ (Product Quantization)** - 高次元のベクトルをより小さなサブベクトルに圧縮し、ストレージ効率と検索速度を向上させる。
高次元データの処理
音声埋め込みデータは高次元の場合が多く、次元の呪いと呼ばれる、計算コストの増大やインデックス作成の効率低下を引き起こします。そのため、主成分分析(PCA)やt-SNEなどの次元削減技術は、重要なオーディオ特徴を失うことなく次元を削減するのに役立ちます。さらに、積量子化(PQ)やスカラー量子化(SQ)のような量子化技術は、ベクトルを圧縮し、ストレージ効率を上げることができます。
リアルタイム検索の実行
全体として、ベクトル・データベースは、効率的な近似最近傍(ANN)検索アルゴリズム、高速インデックス作成技術、分散処理、量子化、インメモリー演算、GPUアクセラレーション、高次元データの効果的な処理によって、低レイテンシーを維持することでリアルタイム検索を可能にします。
オーディオ類似検索のスケーリングツールとフレームワーク
スケーラブルなオーディオ類似検索システムを構築するには、適切なベクトルデータベースと適切な埋め込みモデルやライブラリを選択することが重要です。ここでは、あなたに関連するものを選ぶ方法を説明します。
どのベクトルデータベースが適切か?
ベクターデータベースは、数百万から数十億という規模の高次元埋め込みデータを格納し、インデックスを作成することで、実世界のアプリケーションを高速かつスケーラブルにします。最も一般的なベクトルデータベースは以下の通りです。
Milvus** - Milvusは、HNSWやIVFのような効率的なインデックス作成手法により、リアルタイムの検索と取得のために構築されたスケーラブルなベクターデータベースです。エンタープライズ・アプリケーションや、オープンソースでスケーラブルなオプションをお探しの方に最適です。
Zilliz Cloud** - Milvusのフルマネージド、クラウドネイティブバージョンで、シームレスなスケーリングとデプロイのために最適化されています。サーバーレスアーキテクチャをサポートし、AWS、Google Cloud、その他のクラウドプロバイダーと簡単に統合できる。専用のDevOpsリソースを持たず、プラグアンドプレイのベクター検索ソリューションを求めるチームに最適です。
FAISS (Facebook AI Similarity Search)** - GPUアクセラレーションを活用した迅速な類似検索のためのFacebookのオープンソースライブラリです。オフライン、バッチベースの類似検索や研究アプリケーションに最適です。
どの音声埋め込みモデルを選ぶべきか?
音声埋め込みは、生の音声をベクトル空間で比較できる意味のある特徴ベクトルに変換します。以下のモデルは、事前にトレーニングされたエンベッディングを提供します。
OpenL3:OpenL3:ディープラーニングをベースとしたモデルで、マルチモーダルなデータセットに対して自己教師あり学習を行い、汎用的なオーディオエンベッディングを抽出します。
VGGish**:YouTube-8Mで学習したCNNベースのモデルで、音楽やオーディオの分類によく使われる。
YAMNet**:GoogleのAudioSetを学習させたMobileNetベースのモデルで、環境音の分類に特化している。
その他、CLAP (Contrastive Language-Audio Pretraining)やDEEP Audio Embeddingsは、音声処理や音楽検索のためのドメイン固有のエンベッディングを提供する。
大規模音声検索の性能と効率の最適化
大規模オーディオシステムにおける性能と効率は、以下の点を考慮することで最適化できる。
検索速度と精度を向上させるテクニック
近似最近傍(ANN)検索** - ANNアルゴリズムは、すべてのオーディオ埋め込みを網羅的に比較する代わりに、最も近い一致を素早く近似します。
メモリ使用量と計算量の最適化
PCA (Principal Component Analysis)やAutoencodersのような次元削減技術を使用することで、エンベッディングのサイズを削減し、効率を向上させます。
単一クエリの代わりにバッチ処理を行うことで、計算オーバーヘッドを削減します。
精度と計算効率のバランスをとる方法
例えば、Milvus Searchの'ef'を調整することで、精度を上げることができます。
ドメイン固有の埋め込みを使用し、タスク固有のデータセットでカスタムモデルをトレーニングすることで、ノイズを減らし、検索品質を向上させることができる。
リアルタイムアプリケーションの待ち時間を短縮するテクニック
- エンベッディングのメモリへのプリロード、分散検索の実行、マルチGPU処理の使用などは、待ち時間を短縮し、処理を高速化する方法の一部です。
課題と考察
- データのプライバシーとセキュリティ** - 個人的な音声メモ、生体認証の音声パターン、医療用音声などの音声データは、不正アクセスがプライバシー侵害につながる可能性があるため、慎重に保護する必要があります。権限を管理できる暗号化技術とセキュアなアクセス制御メカニズム(Zilliz Cloudはロールベースのアクセス制御を提供します)を使用して、ユーザーデータを保護することができます。
- スケーラビリティの課題** - オーディオデータセットの量は増加し続ける可能性があるため(数百万から数十億)、システムは検索速度を損なうことなく効率的にスケーリングする必要があります。ベクトル量子化、シャーディング、HNSW インデックスのような技術は、パフォーマンスを向上させるために不可欠です。分散ストレージソリューション(Kubernetes上に展開されたMilvus)を採用することで、システムは低レイテンシーを維持しながら、高いクエリ負荷を処理することができる。
- モデルドリフト** - オーディオ埋め込みは、新しい音、声、音楽スタイルが出現すると、検索システムの精度を低下させるため、古くなる可能性があります。そのため、エンベッディングを適切なものに保つためには、新しいデータに対する継続的な再トレーニングが必要です。パフォーマンスを監視するためにドリフト検出技術を実装し、更新を追跡するためにバージョニングを埋め込むことで、検索結果を正確かつ最新の状態に保つことができます。
- オーディオデータセットのバイアスを軽減することは、公正な結果を保証するために不可欠です。特定のアクセントや言語に特化したエンベッディング・モデルは、不公平な検索結果につながる可能性があります。そのため、多様で代表的なデータを持つことが重要です。さらに、説明可能性のテクニックを使用することで、透明性を提供し、ユーザーに結果を信頼させ、より受け入れやすく解釈させることができます。
結論
ベクトルデータベースによる音声類似検索は、音楽の推薦から環境モニタリングに至るまで、業界を変革している。膨大なデータセットを扱い、電光石火の速さで検索できるこのテクノロジーは、無数の可能性を開いている。しかし、他の強力なツールと同様、データのプライバシー、スケーラビリティ、モデルの関連性については慎重に扱う必要がある。AIが進化し続ける中、オーディオ類似検索は、オーディオAIの世界で新たな可能性を解き放つ基礎技術であり続けるだろう。
参考文献
 Yesha Shastri
Yesha ShastriYesha Shastri, Freelance Technical Writer in AI/ML


