




オーディオデータ入門処理テクニックと主な課題
音声データ、その特徴、処理技術、主要な課題を発見。AIアプリケーションで効果的に取り組む方法を学びます。
世界の音声認識市場が活況を呈している。専門家の予測では、2025年には173.3億米ドル](https://straitsresearch.com/report/voice-and-speech-recognition-market#:~:text=is%20projected%20to%20reach%20from%20USD%2017.33%20billion%20in%202025%20to%20USD%2061.27%20billion%20by%202033)に達し、2033年には612.7億米ドルに達する。
数字が物語っている。音声アシスタントは毎日何十億ものクエリーを処理し、音楽プラットフォームは楽曲を分析して推薦し、AI補聴器はリアルタイムで音を強化する。このような成長にもかかわらず、生の音声は依然として複雑な課題である。
ある調査によると、世界のAI音声処理ソフトウェア市場規模は2033年までに約180億米ドルになると予想されている。音声認識](https://zilliz.com/ai-faq/what-is-speech-recognition)と自然言語処理技術の進歩がこの成長を後押ししている。音声データの量は急速に増加しており、効率的な処理はより困難になっている。AIモデルの信頼性を維持するためには、より優れた前処理とデータクリーニング技術が必要です。
A Developer's Handbook to Mastering Audio AI](https://zilliz.com/learn/top-10-most-used-embedding-models-for-audio-data)の最初の投稿であるこの記事では、オーディオデータの基礎と不可欠な準備テクニックを開発者に紹介します。生のオーディオをAIモデルのためのクリーンで構造化された入力に変換するのに役立つ、核となる概念と前処理方法を説明します。この記事の最後には、オーディオデータを処理し、Pythonライブラリを使用してオーディオデータを処理する際の重要な課題に取り組むことができるようになります。

Siri - Appleの音声AIアシスタント| ソース
オーディオデータとは?
オーディオデータとは、音波をデジタルで表現したものです。アナログの音信号(人の話し声、音楽、環境ノイズなど)を一連の数値に変換することで取り込まれます。このプロセスでは、連続的な音波を離散的な間隔でサンプリングし、コンピュータが処理できる形式で保存します。一般的なオーディオファイル形式は以下の通り:
波形オーディオファイル(WAV):** 編集に理想的な、非圧縮の高音質オーディオ。
MPEG-1 Audio Layer 3(MP3):**ファイルサイズを小さくするために品質を犠牲にした圧縮フォーマット。
Free Lossless Audio Codec(FLAC): ロスレス圧縮。
オーディオ・データのグラフィカルな表現。
オーディオデータの特徴
音声データには、その品質やAIアプリケーションでの使いやすさに影響する、いくつかの重要な特徴があります。以下に定義する:
サンプリングレート:*** サンプリングレートとは、1秒間に採取されるオーディオスナップショットの数 のことで、キロヘルツ(kHz)で測定されます。サンプリングレートが高ければ高いほど、より詳細な情報が得られますが、ファイルサイズも大きくなります。例えば、AI音声認識システムは、明瞭さと効率のバランスをとるために16kHzのサンプリングレートを使用しています。
ビット深度:*** ビット深度は各オーディオサンプルの精度を決定し、動的解像度に影響します。ビット深度が高いほど、より広い範囲の音を捉えることができます。例えば、AIベースの音楽生成では、ニュアンスに富んだ音の変化を捉えるために24ビットの深さが使用されます。
チャンネル:** チャンネルはオーディオトラックの数を示し、モノ(1チャンネル)とステレオ(2 チャンネル)が最も一般的です。ステレオは没入体験のための空間的なコンテクストを強化し、モノラルは音声を明瞭にするのに適しています。例えば、ポッドキャストは通常モノラルですが、音楽は空間を作り出すためにステレオでミックスされることがよくあります。
ダイナミックレンジ:** ダイナミックレンジは、オーディオ録音の最も小さい音と最も大きい音の差です。広いダイナミックレンジは、クリッピングや聞き取れないディテールを防ぐために、注意深いノーマリゼー ションが必要です。例えば、クラシック音楽の録音のダイナミックレンジは、柔らかいピアノソロと大きなブラスセクションの違いです。
周波数:*** 周波数とは音の高さのことで、ヘルツ(Hz)単位で測定され、人間の聴覚は20Hzから20kHzの範囲である。AIモデルは音声処理を強化するために、しばしば無関係な周波数をフィルタリングする。例えば、AI音声認識モデルは、人間の音声に集中するために、300Hz以下の周波数をフィルタリングする。
これらの特性は、音声が現実世界の音をどれだけ正確に表現するかを決定し、ノイズ除去や特徴抽出などの前処理ステップに影響を与えます。
オーディオの前処理テクニック
前処理は、AIベースのオーディオ分析における重要な最初のステップです。生の非構造化オーディオデータを、分析とモデルトレーニングのために、クリーンで、使用可能な、標準化された形式に変換します。データクリーニング、リサンプリング、正規化、セグメンテーションなどの前処理ステップにより、信頼性の高いAIモデルを作成する準備が整います。
このガイドでは、librosa、noisereduce、pydub、numpy、matplotlib.pyplotという、オーディオ操作とデータ可視化のための一般的なライブラリを使用して、各前処理ステップを示します。librosaのビルトイン "trump "オーディオデータセットが、デモ用のデータセットとなります。Numpyは数値演算に、matplotlib.pyplotはオーディオ信号を可視化するグラフのプロットを支援します。
データのクリーニング
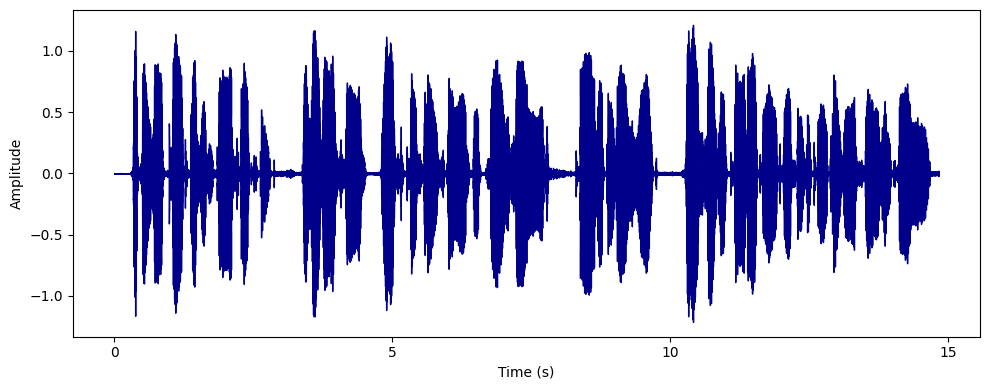
データクリーニングとは、生オーディオから不要なノイズやアーチファクトを除去し、音質を可能な限り 高くすることです。このステップでは、バックグラウンドノイズ、クリック、歪みなど、解析の妨げとなるものを除去します。
例えば、ノイズの多いオーディオクリップを扱う場合、それをクリーニングすることで、気が散ることなく主要なオーディオの特徴に集中することができます。noisereduce ライブラリにあるようなノイズ除去技術を使うことができます。ノイズリダクションを適用することで、S/N比を改善し、音声認識や音楽分析のようなタスクのためにオーディオの明瞭度を向上させます。
コード例
インポート librosa
import noisereduce as nr
インポート librosa.display
インポート matplotlib.pyplot as plt
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
clean_audio = nr.reduce_noise(y=y, sr=sr)
plt.figure(figsize=(10, 6))
librosa.display.waveshow(cleaned_audio, sr=sr)
plt.title("Cleaned Trumpet Audio Signal")
plt.xlabel("Time (s)")
plt.ylabel("振幅")
plt.tight_layout()
plt.show()
データクリーニング後のトランペット・データセットの音声信号。
リサンプリング
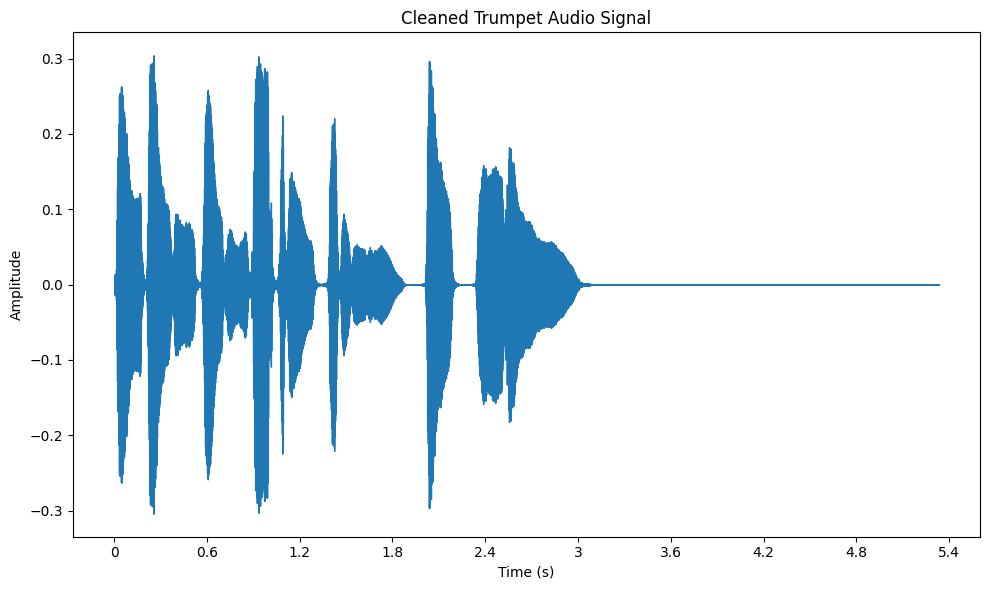
リサンプリングは、オーディオ信号のサンプルレートを変更するプロセスで、異なるデータセット間の一貫性を 確保します。これは、サンプルレートが異なるさまざまなソースのオーディオを扱うときに特に重要です。
たとえば、あるオーディオクリップが 44.1 kHz で、他のクリップが 22.05 kHz の場合、22.05 kHz のような共通のレートにリサンプリングすることで、データセット全体の統一性を確保できます。librosa では、librosa.resample 関数を使って簡単に行うことができます。リサンプリングは、すべてのオーディオファイルが一貫した方法で処理されることを保証し、特徴抽出や分類のようなタスクを実行する際に非常に重要です。
コード例
インポート librosa
インポート librosa.display
インポート matplotlib.pyplot as plt
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
target_sr = 16000
y_resampled = librosa.resample(y, orig_sr=sr, target_sr=target_sr)
plt.figure(figsize=(10, 6))
librosa.display.waveshow(y_resampled, sr=target_sr)
plt.title("Resampled Trumpet Audio Signal (16 kHz)")
plt.xlabel("Time (s)")
plt.ylabel("振幅")
plt.tight_layout()
plt.show()
リサンプリング後のトランペット・データセットの音声信号
正規化
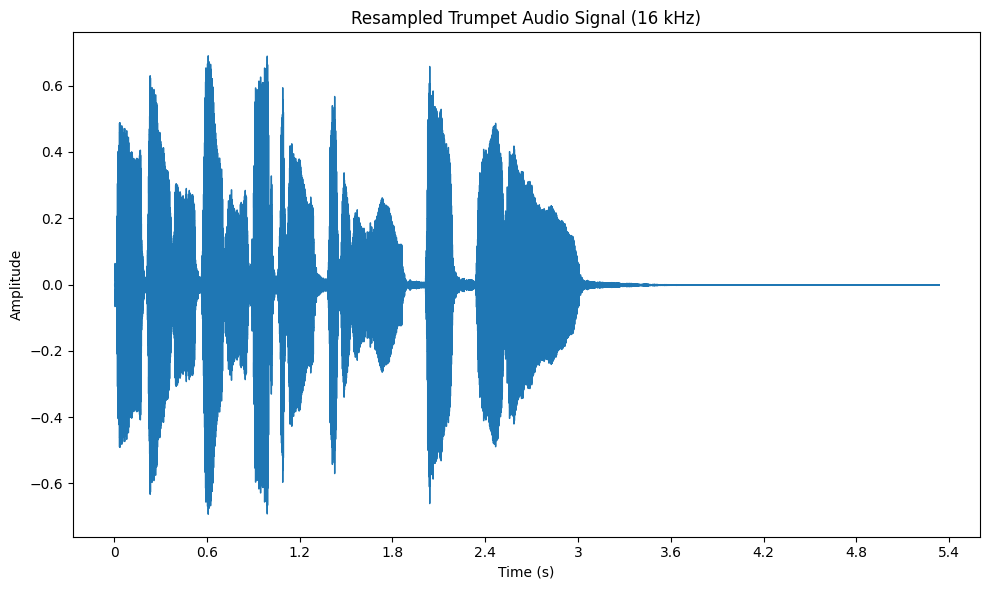
正規化とは、オーディオ信号の振幅を、標準的な範囲、通常は -1 から 1 の間にスケーリングするために使われる技法です。音量レベルが異なる複数のソースからのオーディオを扱うときには、重要なステップです。
オーディオを正規化することで、すべてのクリップで一貫した音量が保証されます。これは、プレイリストを作成するときや、機械学習モデル用のオーディオを準備するときに特に便利です。librosa では、librosa.util.normalize 関数を使ってオーディオを正規化し、matplotlib を使って波形を可視化することで、正規化の効果を見ることができます。
コード例
インポート librosa
インポート librosa.display
インポート matplotlib.pyplot as plt
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
y_normalized = librosa.util.normalize(y)
plt.figure(figsize=(10, 6))
librosa.display.waveshow(y_normalized, sr=sr)
plt.title("Normalized Trumpet Audio Signal")
plt.xlabel("Time (s)")
plt.ylabel("振幅")
plt.tight_layout()
plt.show()
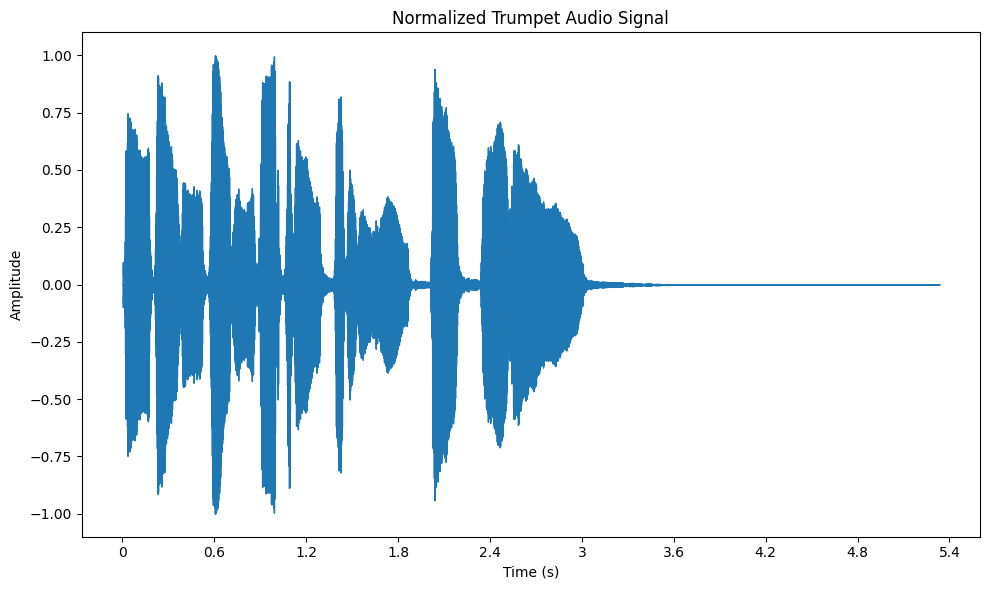
正規化後のトランペット・データセットの音声信号
セグメンテーション
セグメンテーションは、オーディオファイルをより小さく、管理しやすい塊に分割することです。これは、長いオーディオファイルを、より小さなセクションに分割して分析する必要がある場合に便利です。例えば、演奏の長い録音を分析する場合、オーディオを個々の音符やフレーズに分割したいと思うかもしれ ません。
セグメンテーションを使えば、ファイル全体を一度に処理する必要なく、オーディオの特定の部分に焦点を当てることができます。これにより、分析がより効率的になります。pydubライブラリは、オーディオをセグメント化する簡単な方法を提供します。このライブラリを使えば、ファイルを特定の長さ、たとえば2秒のチャンクに分割して、的を絞った分析を行うことができます。
コード例
from pydub import AudioSegment
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
audio_segment = オーディオセグメント(
y.tobytes()、
frame_rate=sr、
sample_width=2、
チャンネル数
)
セグメント長 = 10 * 1000
セグメント = [].
for start_ms in range(0, len(audio_segment), segment_length):
segment = audio_segment[start_ms:start_ms + segment_length].
segments.append(segment)
segment[0].export("segment_0.wav", format="wav")
print("最初のセグメントを 'segment_0.wav' として保存")
特徴抽出のテクニック
特徴抽出技術は、生の音声を構造化されたデータに変換し、機械が効果的に音を処理・分析するのに役立ちます。これらの技術は、音声認識や音楽分析などのタスクに不可欠なパターンや特徴を明らかにします。主なテクニックをいくつか紹介します:
スペクトログラムとMFCC
スペクトログラム](https://zilliz.com/ai-faq/what-are-spectrograms-and-how-are-they-used-in-speech-recognition)は、オーディオ信号の周波数が時間とともにどのように変化するかを視覚化するもので、時間、周波数、振幅を1つのグラフにまとめたものです。これは、Short-Time Fourier Transform (STFT) を使って作成されます。STFT は、オーディオを小さな時間セグメントに分割し、それぞれの周波数スペクトルを計算します。
例えば、音楽の録音では、スペクトログラムによって、トランペットやバイオリンのような楽器の明確な周波数が明らかになり、それらが全体の音にどのように寄与しているかを示すことができます。音声処理では、各母音に固有の周波数特性があるため、スペクトログラムは母音の識別に役立ちます。
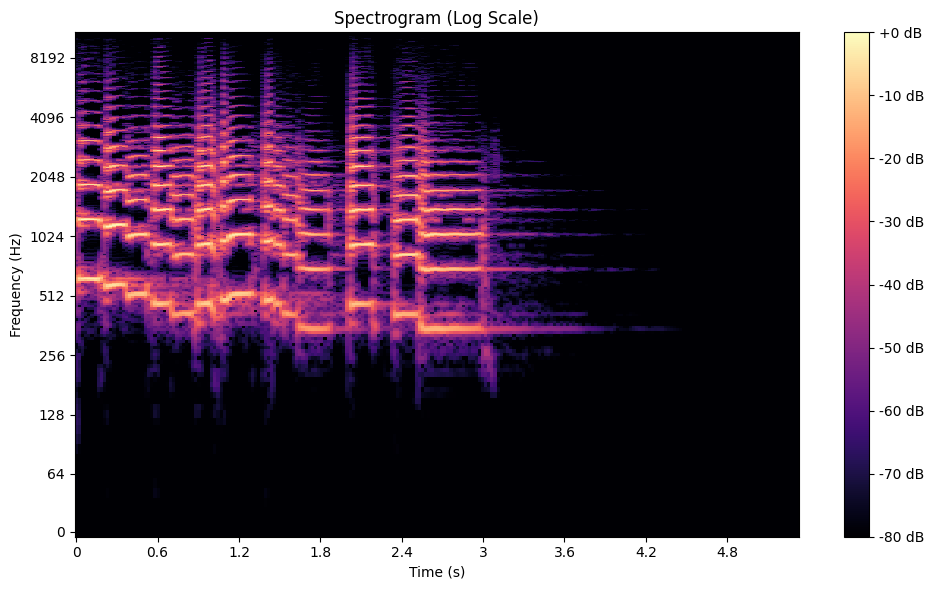
トランペットデータセットのスペクトログラム
メル・スペクトログラム** は、周波数をメル・スケールにマッピングしたバリエーションで、音に対する人間の耳の感度を模倣したものです。直線的な周波数スケールとは異なり、melスケールは人間がより知覚しやすい低周波を強調します。このため、melスペクトログラムは音声や音楽の分析に最適である。このスペクトログラムを作成するには、STFTを適用し、得られたスペクトルをmelフィルターバンクに通します。
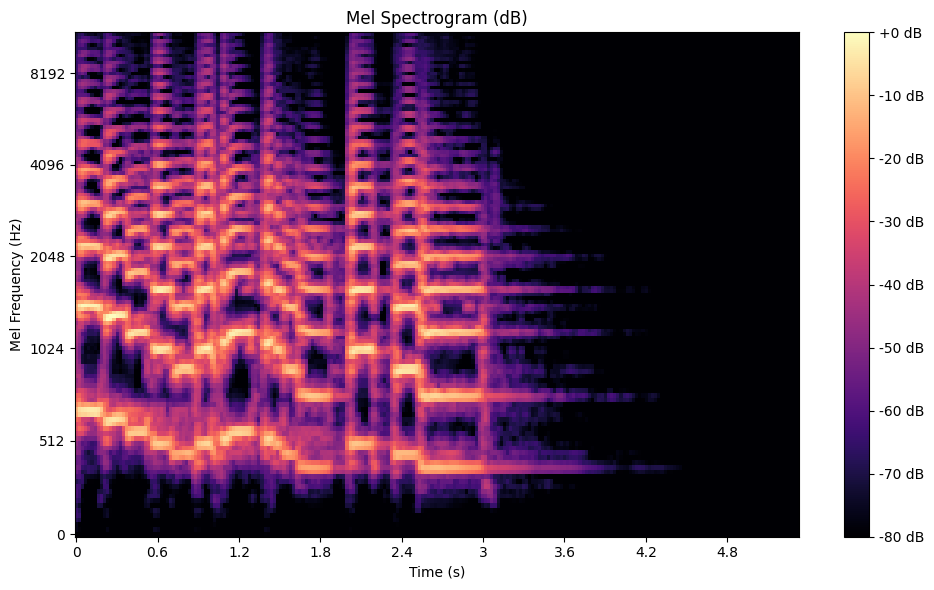
トランペットデータセットのメルスペクトログラム
Mel-Frequency Cepstral Coefficients (MFCC)は、メル・スペクトログラムをコンパクトな特徴セットに圧縮することで、これをさらに一歩進めます。MFCCは、まず信号をあらかじめ強調し、フレームに分割することで計算されます。次に、高速フーリエ変換(FFT)でパワースペクトルを計算する。パワースペクトルはメルスケールフィルターバンクでフィルターされ、対数スケーリングされ、最後に離散コサイン変換(DCT)で変換される。このプロセスにより、オーディオの本質的な音色特性を効率的に捉えることができます。以下はPythonを使ってMFCCを生成する方法です:
インポート librosa
import librosa.display
import matplotlib.pyplot as plt
np として numpy をインポート
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
mel_spectrogram = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128, fmax=8000)
mel_spectrogram_db = librosa.power_to_db(mel_spectrogram, ref=np.max)
plt.figure(figsize=(10, 6))
librosa.display.specshow(mel_spectrogram_db, sr=sr, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram (dB)')
plt.xlabel('Time (s)')
plt.ylabel('Mel Frequency (Hz)')
plt.tight_layout()
plt.show()
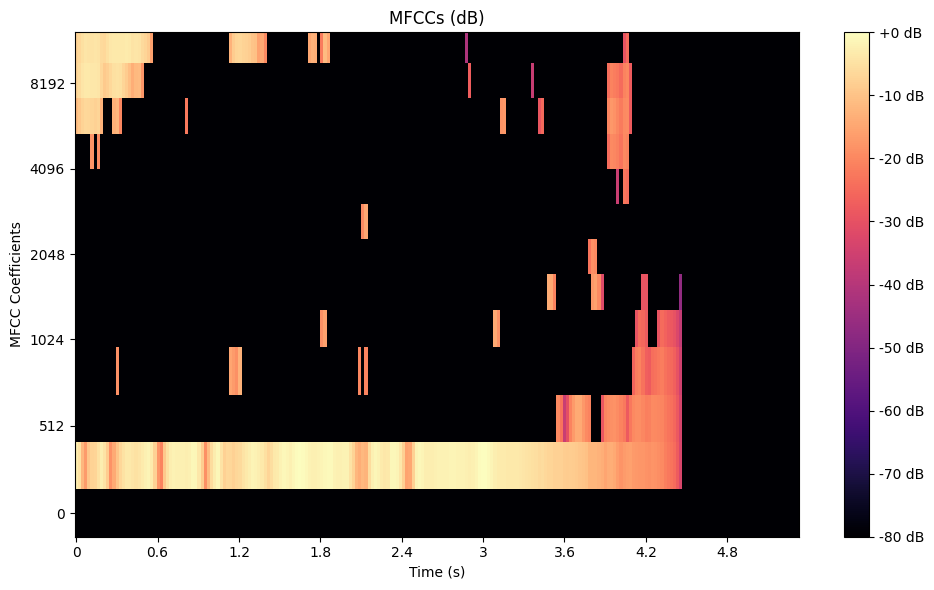
トランペット・データセットのメル周波数セプストラル係数.
埋め込み
オーディオ埋め込みは、オーディオデータの高レベル表現で、多くの場合、Wav2VecやVGGishのような事前に訓練されたディープラーニングモデルを用いて抽出される。これらのエンベッディングは、スピーチの感情的なトーンや曲のジャンルといった意味的な情報を捉えており、転移学習に理想的である。例えば、ヘルスケアAIはエンベッディングを使って、咳の音が特定の病気を示しているかどうかを分類することができる。ここでは、事前に訓練されたモデルを使用してエンベッディングを抽出する方法を説明します:
import torch
from transformers import Wav2Vec2Processor, Wav2Vec2Model
インポート librosa
import matplotlib.pyplot as plt
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-960h")
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=16000) # Wav2Vec2 で必要なサンプルレートが 16kHz であることを確認する。
入力 = processor(y, sampling_rate=sr, return_tensors="pt", padding=True)
with torch.no_grad():
embeddings = model(**inputs).last_hidden_state
plt.figure(figsize=(10, 6))
plt.imshow(embeddings[0].numpy()[:, :50], aspect='auto', cmap='viridis')
plt.title('Wav2Vec2 Audio Embeddings')
plt.xlabel('Frames')
plt.ylabel('Embedding Dimensions')
plt.colorbar()
plt.tight_layout()
plt.show()
print("Embedding shape:", embeddings.shape)
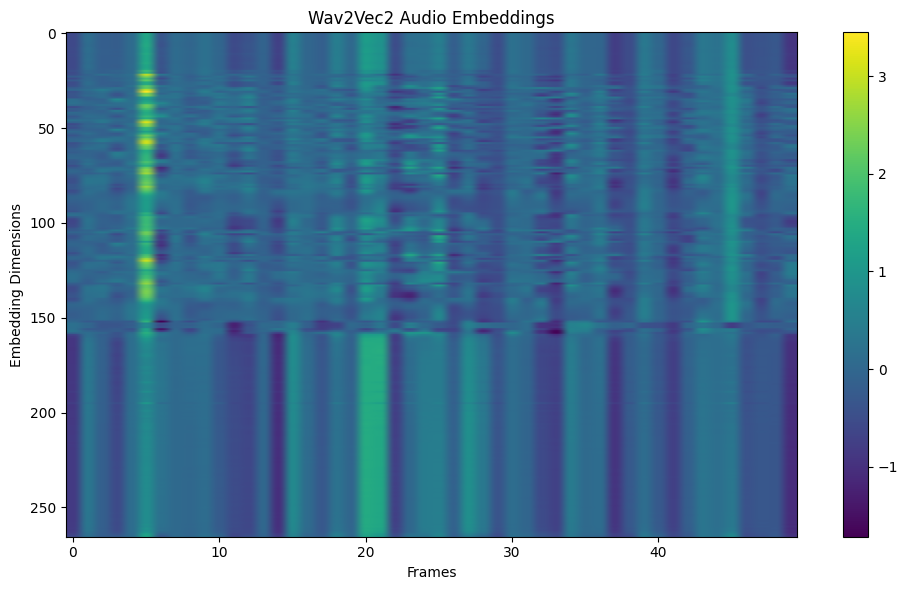
Way2Vec2による音声埋め込みをフレーム0-40にわたって可視化する。
ピッチとテンポの分析
ピッチとは、音の高低のことで、基本的には音符を決定します。オーディオ分析では、ピッチを抽出することは、音の基本周波数を特定することを意味します。このための一般的な方法の1つが、短時間フーリエ変換(STFT)です。Librosa のようなツールを使えば、librosa.piptrack のような関数を使って、ピッチの値を経時的に追跡することができます。このような分析は、音楽の分類のような分野で重要な役割を果たし、音色の違いを理解することで、ジャンルやムードによって曲を分類するのに役立ちます。
最近では、畳み込みニューラルネットワークのような技術が、特により困難なオーディオ環境において、ピッチ推定の精度を高めるために使用されています。
テンポは音楽の速さを示し、1分あたりの拍数(BPM)で測定される。テンポの分析には、オーディオ信号内の拍のタイミングを検出することが含まれます。アルゴリズムは多くの場合、エネルギーのピークやスペクトルの変化を識別してテンポを推定します。Librosaは、全体のテンポとビート位置を推定するために、librosa.beat.beat_track関数を提供しています。
テンポ分析は、DJソフトウェアやプレイリストの作成など、スムーズな体験のために異なるトラックのペースを合わせることが重要な作業には不可欠です。最近、新しい手法により、ノイズやリバーブのある厳しい環境でもテンポ推定が改善されました。
ここでは、librosaを使ってピッチとテンポを分析する方法を説明します:
インポート librosa
インポート librosa.display
import matplotlib.pyplot as plt
np として numpy をインポート
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path, sr=None)
ピッチ、マグニチュード = librosa.piptrack(y=y, sr=sr)
pitch_values = [] (ピッチ値)
for i in range(pitches.shape[1]):
index = magnitudes[:, i].argmax()
pitch = pitches[index, i].
pitch_values.append(pitch if pitch > 0 else np.nan)
tempo, beats = librosa.beat.beat_track(y=y, sr=sr)
if isinstance(tempo, np.ndarray):
テンポ = テンポ[0]
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(pitch_values, color='b')
plt.title('ピッチ分析')
plt.xlabel('Frames')
plt.ylabel('ピッチ(Hz)')
plt.subplot(2, 1, 2)
librosa.display.waveshow(y, sr=sr, alpha=0.6)
plt.vlines(librosa.frames_to_time(beats, sr=sr), -1, 1, color='r', linestyle='--', label='Beats')
plt.title(f'テンポ分析(テンポ:{tempo:.2f} BPM)')
plt.xlabel('時間 (s)')
plt.ylabel('振幅')
plt.tight_layout()
plt.show()
print(f "推定テンポ:{テンポ:.2f} BPM")
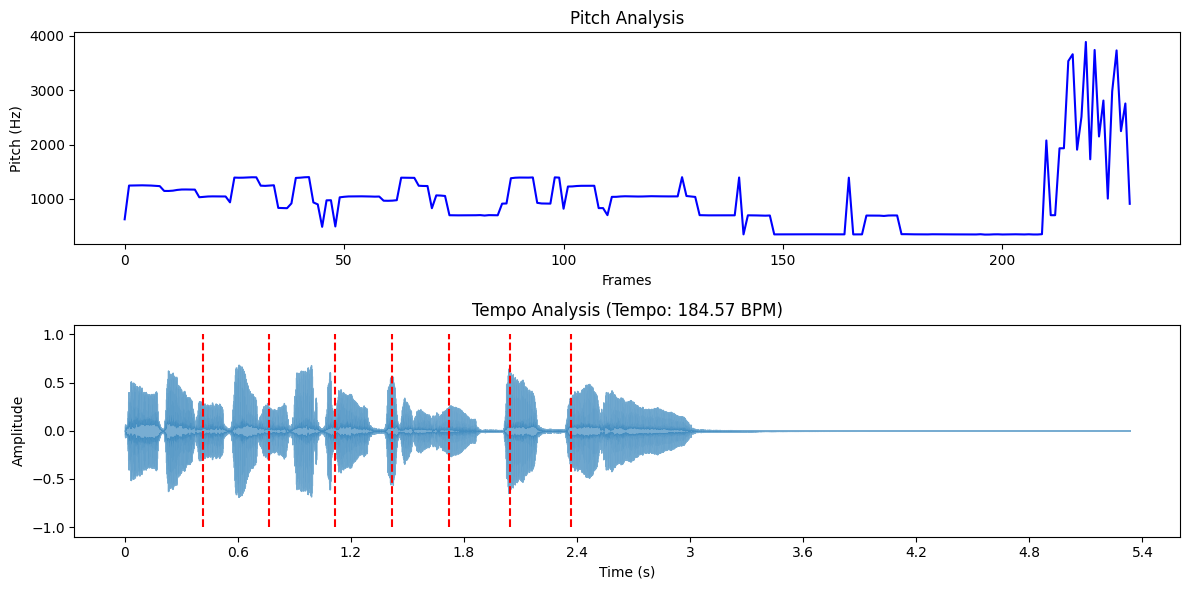
トランペット・データセットのピッチとテンポ分析
オーディオデータを扱う上での主な課題
前処理と特徴抽出はオーディオAIワークフローのバックボーンを形成していますが、実世界での実装は根強いハードルに直面しています。これらの課題は、現在のツールの限界を試し、創造的な問題解決を要求します。主な課題をいくつか紹介しよう:
データ品質:*** 生オーディオには、ノイズ、歪み、欠落セグメントなどがあり、モデルのパフォーマンスを低下させます。ノイズ除去や正規化などの技術は品質を向上させます。高品質なラベル付きデータセットもまた、正確なモデルをトレーニングするために不可欠であり、慎重なアノテーションと前処理を必要とします。
スケーラビリティ:*** 高音質オーディオは、大容量のストレージと計算能力を必要とします。効率的なリサンプリング、圧縮、分散コンピューティングがこの問題を解決するのに役立ちます。クラウドベースのストレージと並列処理フレームワークは、大規模アプリケーションのパフォーマンスをさらに最適化することができます。
Domain-Specific Requirements: さまざまなアプリケーションには固有のニーズがあり、普遍的なソリューションは困難です。カスタム・パイプラインと専門知識が不可欠です。例えば、法的な場面での音声認識には、音楽分析とは異なる処理技術が必要です。
リアルタイム処理:*** バーチャルアシスタントやライブテープ起こしサービスなど、多くの音声AIアプリケーションはリアルタイム処理を必要とします。そのため、シームレスなユーザー体験を保証するために、低レイテンシーモデル、最適化されたアルゴリズム、効率的なハードウェアアクセラレーションが要求されます。
オーディオデータ処理のためのツールとライブラリ
このような課題に対処するため、開発者はオーディオ処理用に設計された専用ツールに頼っています。
Python ライブラリ
Pythonは、オーディオデータ処理用のライブラリの豊富なエコシステムを提供しており、開発者にとって最適な選択肢となっています。
1.1. Librosa: Librosa は、オーディオ解析のための多機能なライブラリです。オーディオをロードし、MFCC やスペクトログラムのような特徴を抽出し、テンポ推定やピッチ検出のようなタスクを実行するためのツールを提供します。例えば、Librosaは音楽ストリーミングプラットフォームが曲のリズムを分析したり、ジャンルを分類したりするのに役立ちます。
2)PyDub:オーディオファイルの操作に最適なPyDubは、スライス、マージ、リサンプリングのようなタスクを簡素化します。例えば、長い通話記録を分析するセキュリティシステムは、PyDubを使ってキーワード検出のために短いセグメントに分割することができます。
3.**ディープラーニングのために作られたTorchAudioはPyTorchとシームレスに統合され、オーディオのロード、変換の適用、エンベッディングの抽出のためのツールを提供する。音声テキスト変換システムのような、カスタム音声AIモデルのトレーニングに特に役立つ。
可視化ツール
可視化ツールは、オーディオデータとその変換をよりよく理解するのに役立ちます。これらのツールは、前処理ステップの結果を解釈し、デバッグするための鍵となります。
1.1. Matplotlib: 有名なプロットライブラリ、Matplotlib は、波形、スペクトログラム、MFCC を可視化することができます。例えば、スペクトログラムをプロットすると、音楽トラックや音声録音の周波数パターンを識別するのに役立ちます。
2)Plotly:インタラクティブなビジュアライゼーションのために、Plotly は、ユーザーがズーム、パン、および詳細にオーディオデータを探索することを可能にします。これは、産業機械音の異常の特定など、複雑な音声信号の分析に特に役立ちます。
要約
オーディオAIの急速な成長には、慎重なデータ準備が必要です。生オーディオには、AIのパフォーマンスを妨げるノイズや不整合が含まれていることがよくあります。前処理は、不要な音のクリーニング、サンプルレートの調整、音量レベルのバランス、管理しやすいクリップへのファイル分割など、重要なステップを通じてこれらの問題に対処します。これらの技術により、信頼性の高い分析のための均一で高品質な入力が作成されます。
効果的な処理は、オーディオの潜在能力を引き出します。スペクトルパターンやセマンティック埋め込みなどの機能は、機械が文脈や意味を理解するのに役立ちます。これらの手法を拡張し、特殊なニーズに適応させることには課題が残されています。明確な前処理と最新のツールを優先させることで、開発者は実世界の音声をヘルスケア、セキュリティ、エンターテイメントなどの分野で実用的な洞察に変換するAIシステムを構築することができます。サウンド主導のイノベーションの未来は、これらの基本をマスターすることから始まります。
関連リソース
Milvusに基づく音声検索](https://zilliz.com/blog/audio-retrieval-based-on-milvus)
音声認識システムが直面する一般的な問題とは](https://zilliz.com/ai-faq/what-are-common-issues-faced-by-speech-recognition-systems)
リアルタイム音声認識の課題は何か](https://zilliz.com/ai-faq/what-are-the-challenges-of-realtime-speech-recognition)
スペクトログラムとは何か、音声認識でどのように使われているか](https://zilliz.com/ai-faq/what-are-spectrograms-and-how-are-they-used-in-speech-recognition)
Milvus Bootcamp](https://github.com/milvus-io/bootcamp)
音声類似度検索とは](https://zilliz.com/ai-faq/what-is-audio-similarity-search)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

音声データに最も使用されている埋め込みモデルトップ10
Wav2Vec 2.0、VGGish、OpenL3など、最も人気のある10種類のオーディオ埋め込みモデルをご紹介します。AIアプリケーションのために音をベクトルに変換する方法を学ぶ

正しいオーディオトランスの選択:徹底比較
オーディオ・トランスが音響処理をどのように向上させるかをご覧ください。その原理、選択基準、一般的なモデル、アプリケーション、主な課題を探ります。

マルチモーダルAIの強化:音声、テキスト、ベクトル検索の橋渡し
この記事では、音声、テキスト、ベクトル検索を橋渡しすることで、マルチモーダルAIがどのようにAIシステムを強化するかを探る。