




テキストから音声へ:TTS技術の深層
機械的デバイスからニューラル ネットワークまで、音声合成技術の進化を探ります。TTS の仕組み、一般的なモデルの比較、Google Cloud Platform を使用した実装について学びます。
#はじめに
音声合成(Text-to-Speech:TTS)技術は、機械が書かれたテキストを人間のような音声に変換することを可能にし、音声AIの世界で重要な役割を果たすまでに発展した。人工知能、機械学習、ディープラーニングの継続的な進歩により、これらのシステムは自然さと明瞭さを飛躍的に向上させている。その結果、デジタルコンテンツをより利用しやすくするだけでなく、機械が人間とどのように相互作用するかを強化し、テクノロジーとユーザー体験のギャップを埋めている。
今日、TTS技術は幅広い分野で不可欠なものとなっている。Siri、Alexa、Google Assistantのようなバーチャルアシスタントは、音声合成(TTS)技術)に依存して音声応答を提供し、アクセシビリティツールは、書かれたテキストを理解するためにテキストを音声に変換することで、視覚障害者を支援する。コンテンツ制作者も、オーディオブック、ニュースの自動読み上げ、ポッドキャストやビデオの合成音声にこの技術を活用している。さらに、リアルでカスタマイズ可能な音声を生成できるようになったことで、音声クローンや多言語音声合成など、エキサイティングな可能性が広がっている。
このブログでは、TTS技術の進化を探り、その背後にある仕組みを分析します。基本的なパイプラインを分解し、様々な合成技術を検証し、その課題と倫理的な懸念について議論します。最後に、Google Cloud Platformを使ってTTSソリューションを実装します。
##音声合成(TTS)を理解する
音声合成は、書かれたテキストを自然な音声の話し言葉に変換するAI主導の技術です。話し言葉をテキストに変換する自動音声認識(ASR)とは異なり、TTSはテキストを音声に変換することで、逆の働きをします。最新のTTSシステムは通常、2段階のアーキテクチャを採用しています。第1に、テキストを言語的・韻律的特徴に変換するテキスト分析フロントエンド、第2に、実際の音声を生成する音声合成バックエンドです。
**第一段階フロントエンド
テキスト処理:*** 最初の段階では、テキストを合成用に準備します。これには、略語の展開、特殊文字の処理、数字の話し言葉への変換などのテクニックが含まれます。これらのステップにより、テキストがきれいになり、次のステージに進む準備が整います。
音声転写:*** テキストが処理されると、システムはそれを音素(単語を構成する明確な音)に変換します。このステップは、テキストが話されたときにどのように聞こえるかを正確に捉えるために不可欠です。
プロソディモデリング:*** 音声をより自然に聞こえるようにするため、プロソディモデリングが導入されます。このステップでは、スピーチにリズム、ストレス、イントネーショ ンを加え、人間の会話の流れを模倣します。韻律がなければ、単調でロボット的な音声になってしまいます。
**第二段階バックエンド
- 音声合成:*** 最後に、システムは処理されたテキストから音声波形を生成し、ユーザーが聞く音声を作成します。これは、これまでのすべてのステップの集大成であり、シームレスな音声出力となります。
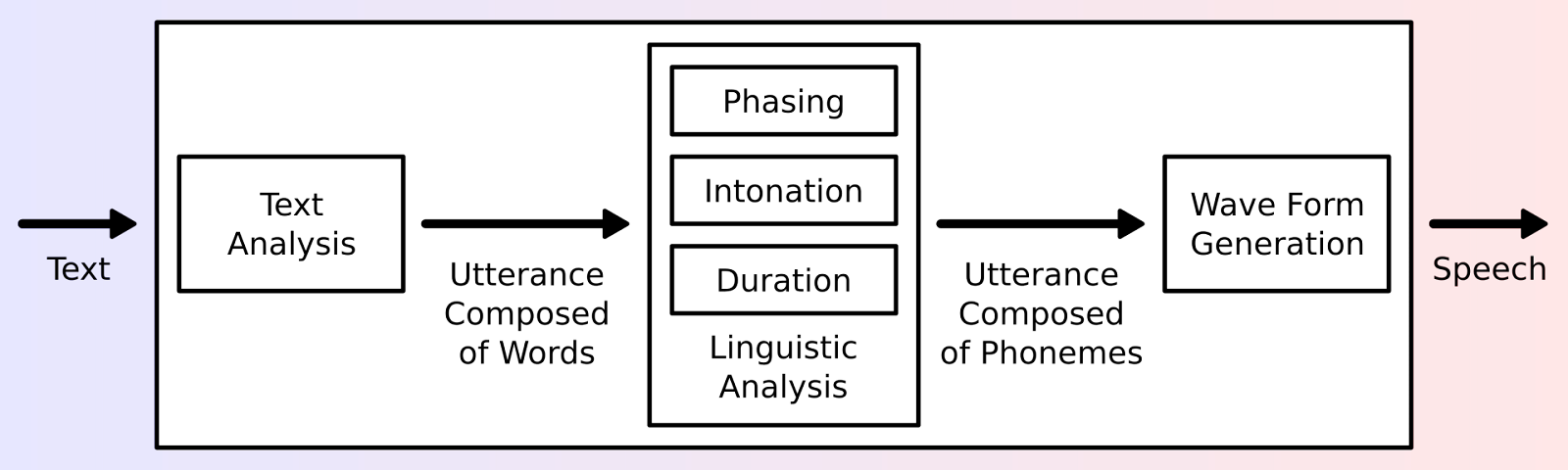
図1: 典型的なTTSシステムの概要 (Source)_。
これらのコンポーネントを組み合わせることで、聞き取りやすいだけでなく、自然でリアルな音声が生まれます。
TTS 技術の進化
TTS技術の発展には、機械的な装置から最先端のディープラーニングモデルまで、絶え間ない進歩が見られます。TTS技術がどのように進化してきたかを探ってみよう。
初期の開発
1930s:最初の機械式音声合成器 - Voder
TTSにおける初期の重要な開発のひとつは、1930年代にベル研究所のホーマー・ダドリーが開発したVoder(Voice Operation Demonstrator)である。Voderは、キーボードを使って人間のような音声を生成する機械式音声合成装置でした。当時としては画期的な発明であり、後の音声合成の進歩の基礎を築いた。しかし、ヴォーダーの出力は、デジタルや音声学的なアプローチではなく、機械的な音の生成に基づいていたため、非常にロボット的な音だった。
**20世紀半ば:ルールベース・システム
20世紀半ばには、音声合成の方法としてルールベースのシステムが登場し始めた。これらのシステムは、音声を生成するためにテキストに適用される固定発音規則(例:音声規則、ストレスパターン)に依存していました。ルールは多くの場合、言語学的、音韻論的な原理に基づいていましたが、システムには言語の複雑な変化を扱う能力がなく、ロボット的で単調な音声になっていました。
20世紀後半:統計的手法と隠れマルコフモデル(HMM)。
計算能力が向上するにつれて、統計的手法がTTSの品質向上に重要な役割を果たすようになりました。最も重要なブレークスルーのひとつは、隠れマルコフモデル(HMM)という形で登場しました。HMMは、音声の連続の確率を推定し、その確率を使用してより自然な音声を生成する統計モデルです。HMMによって、TTSシステムは、ピッチ、スピード、トーンといった人間の音声のばらつきをより効果的に扱えるようになり、ルールベースのシステムと比べて、より明瞭で流暢な音声出力が可能になった。HMMベースの合成は、特に自動電話システムや初期の音声アシスタントなどのアプリケーションにおいて、合成音声の品質を大幅に向上させた。
最新のニューラルネットワークベースTTS技術
音声合成(TTS)技術が進歩するにつれて、様々な合成技術が登場し、それぞれが音声品質、柔軟性、アプリケーションの面で異なる利点を提供してきました。ディープラーニングの導入は、ニューラルネットワークに依存して高品質の音声を直接生成するシステムの新時代をもたらした。Tacotron、WaveNet、FastSpeech**のような主要モデルは、エンドツーエンドのディープラーニングプロセスを使用することで、TTSに革命をもたらしました。
利点**:これらの技術は、韻律とリズムを大幅に改善し、非常に自然で、表現力豊かで、明瞭な音声を生成します。また、さまざまな感情、アクセント、発話パターンを表現できる音声を生成するための柔軟性も向上しています。
不利な点多くの場合、膨大な学習データと計算資源を必要とする。
**主なモデル
WaveNet**:Google DeepMindによって開発された、生の音声波形を直接生成する深層生成モデル。ボコーダーとして使用する場合、イントネーション、ピッチの変化、呼吸音などの詳細な時間的依存関係を捉えることで、スペクトログラムを自然な音声に変換する。
タコトロンシリーズシーケンスツーシーケンス学習により、テキストからメルスペクトログラム(人間が音の周波数を知覚するのに適した、知覚的にスケーリングされた表現)を生成し、WaveNetのようなボコーダーで波形に変換します。Tacotron 2は、強い韻律、リズム、感情表現を持つ、高品質で自然な音声で知られています。
FastSpeechシリーズ**:Tacotronシリーズと比較して、Tacotronの自己回帰的な性質を非自己回帰的なアプローチに置き換えたモデルで、学習と推論にかかる時間が短縮されますが、表現力が犠牲になる可能性があります。
TTSの仕組みプロセスの分解
TTSは高品質な音声を生成するために、複数の段階のパイプラインをたどります。上記の2段階のプロセスの各パートをコード例とビジュアライゼーションで分解し、各段階がどのように機能するかを説明します。
テキストの前処理
テキストの前処理では、生の入力テキストを音声合成に適した形式に変換します。以下に、最も一般的なテクニックを含む、テキストの正規化方法の例を示します:
1.略語の展開(例:"Dr."→"doctor")
2.数字の変換(例:「50.00」→「50)
3.特殊文字の取り扱い(例:「50.00ドル」→「50ドル)
def preprocess_for_tts(text):
# 基本略語辞書
略語辞書 = {
'dr.': 'doctor'、
}
# マッチングしやすいようにテキストを小文字に変換する
words = text.lower().split()
processed_words = [].
for word in words:
# ドル額を処理する
if word.startswith('$'):
number = float(word.replace('$', ''))
processed_words.append(num2words(number) + " ドル")
# 略語を展開する
elif word in abbreviations:
processed_words.append(abbreviations[word])
# プレーンの数字を変換
elif word.replace('.', '').isdigit():
processed_words.append(num2words(float(word)))
else:
processed_words.append(word)
return '.join(processed_words)
# 例
text = "スミス先生は50ドルを支払った"
processed_text = preprocess_for_tts(text)
print(f "処理済み: {processed_text}")
出力:
処理結果:スミス医師は50ドルを支払った
これらの前処理ステップを実行することで、テキストが正規化され、TTSパイプラインでさらなる分析や合成ができるようになる。
音声変換
音素は音声の最小単位であり、テキストを音素に変換することは正確な発音に不可欠です。このステップにより、システムは書かれた単語を対応する音にマッピングすることができ、音声生成がより自然で明瞭になります。基本的な音素変換はフォネマイザーライブラリを使って行うことができますが、TTSシステムでは通常、文脈や言語固有のルールを考慮した、より洗練された変換器ベースの音素変換(G2P)モデルを使用します。以下に、フォネマイザーを使った基本的な例を示します。
インポート phonemizer
# テキストの音訳
text = "こんにちは、世界!"
phonemes = phonemizer.phonemize(text)
print("Phonetic Transcription:", phonemes)
出力
音声転写: həloʊ wɜːld
韻律モデル
ルールベースのような従来の TTS システムでは、ピッチ、ストレス、イントネーション* を調整することで、音声をより自然に聞こえるようにするために、韻律が別途追加されていました。これらの要素は、感情や強調、会話の流れを伝えるのに役立つため、人間に近い音声を生成するために不可欠です。しかし、Tacotron 2のような最新のニューラルTTSモデルは、エンドツーエンドのアプローチを採用しており、トレーニング中に音声変換と韻律モデリングの両方を内部で処理するように学習します。音素変換と韻律を別々のルールに頼るのではなく、これらのモデルはテキストから直接自然な音声を生成するように学習します。
from TTS.api import TTS
# 音素と韻律の両方を扱うTacotronモデルを事前にトレーニングしてロードする。
model = TTS(model_name="tts_models/ja/ljspeech/tacotron2-DDC")
# 自然な発音と韻律を持つ音声を生成する
model.tts_to_file(text="Hello, world!今日はいかがお過ごしですか?", file_path="output_with_prosody.wav")
波形生成
音声特徴を生成した後、TTSパイプラインの次の重要なステップは、これらの特徴を実際の オーディオ波形に変換し、再生またはオーディオファイルとして保存することです。波形を生成するための合成技術には、次のようなものがあります:
1.連結合成:この手法では、あらかじめ録音された音声セグメントを組み合わせます。高品質な出力が得られる反面、連結がシームレスでないとロボットのように聞こえることがあります。
2.フォルマント合成:この技術は、数学的モデルを使用して人間の声道をシミュレートし、音声を生成します。音声の特徴をよりコントロールできますが、一般的に人工的な音声になります。
3.ニューラル合成:これは最新の高度な手法で、ディープラーニングモデルを使用して、非常に自然な音声を生成します。まず、Tacotron 2のようなニューラル・ネットワークがテキストからメル・スペクトログラムを生成し、次にWaveNetのようなニューラル・ボコーダーがこれらのスペクトログラムを実際の音声波形に変換します。Tacotron 2はWaveNetと組み合わせられることが多いが、HiFi-GANのような他のボコーダーを使うこともでき、それぞれ速度と品質のトレードオフが異なる。
前のコードでは、合成された音声をWaveform Audio File Format (.wav)として保存しました。音声出力をよりよく理解するために、音声信号の周波数と振幅を経時的にプロットすることで、メルスペクトログラムと波形の両方を視覚化することができます。プロットを見ることで、音の強さが時間と共にどのように変化するかを観察し、音声パターンを視覚的に理解することができます。
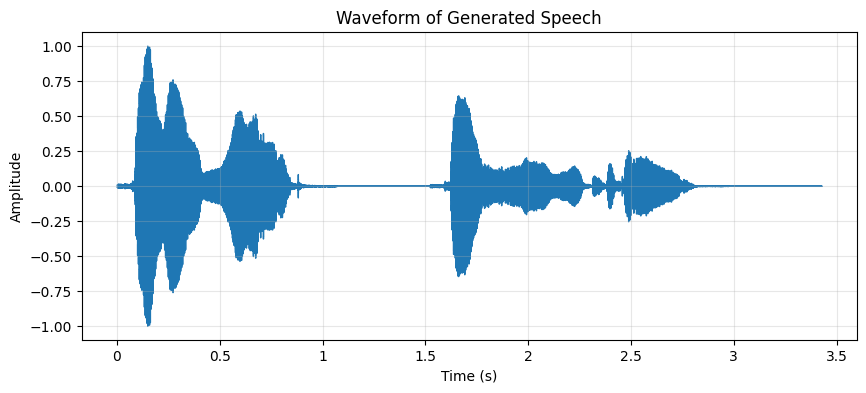
図2: 時間経過に伴う振幅の変化を示す波形。
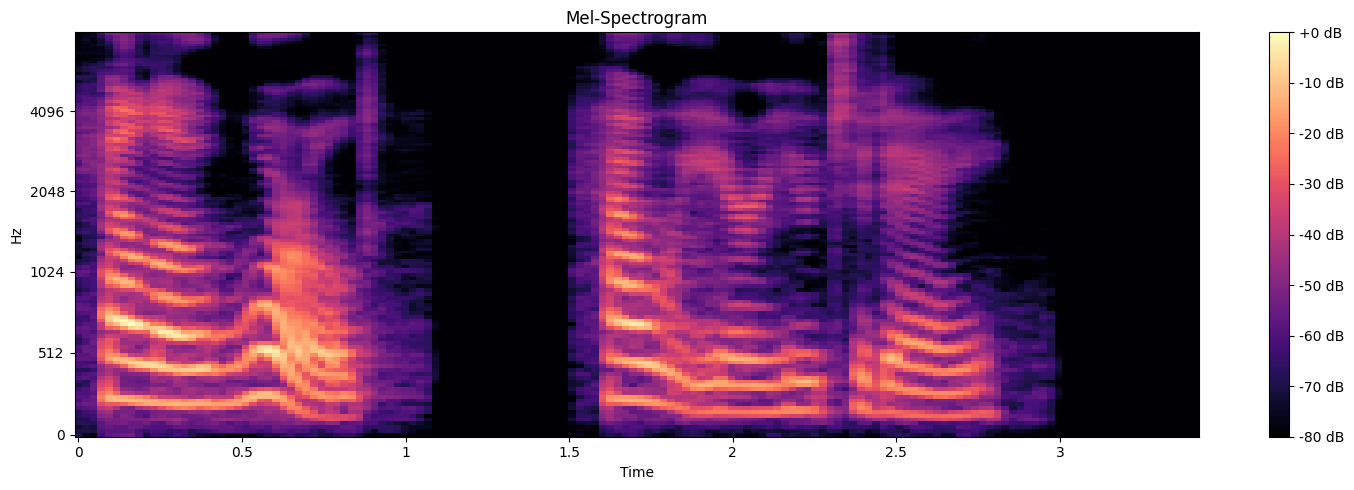
図3:周波数(Hz)とその強度(dB)の経時変化を示すメル・スペクトログラム_。
アプリケーションに適したTTSモデルの選択
アプリケーション用に音声合成(TTS)モデルを選択する場合、特定のユースケースにお ける音声合成の効果に影響するさまざまな要因を考慮することが重要です。以下に、主な検討事項を挙げ、一般的なTTSモデルとプラットフォームの概要を説明します。
考慮すべき主な要因
音声品質**:多くのアプリケーションで最も重要な要素は、生成される音声の品質です。高品質の TTS システムは、自然で明瞭、かつ表現力豊かな音声を生成します。
遅延**:遅延とは、TTSモデルが音声を生成する速度のことです。リアルタイム・アプリケーション(バーチャル・アシスタント、カスタマー・サービス・ボットなど)では、スムーズなユーザー・エクスペリエンスを確保するために、低遅延が不可欠です。
言語サポート**:異なる言語背景を持つユーザーをターゲットとするアプリケーションでは、幅広い言語やアクセントをサポートするTTSモデルを選択することが重要です。プラットフォームによっては、さまざまな方言や地域のアクセントの音声を幅広く選択できるものもあります。
人気のあるTTSモデルとプラットフォーム
TTSソリューションは、クラウドベースのサービスとオープンソースモデルの2種類に大別できます。Google Cloud TTS、Amazon Polly、Microsoft Azure Speechのようなクラウド・サービスは、高い信頼性を備えたプロダクション・レディのAPIを提供しますが、柔軟性はそれほど高くありません。Mozilla TTSのようなオープンソースモデルは、カスタムトレーニングや修正が可能ですが、より多くの技術的専門知識と計算リソースが必要です。
| :------------------------:| :----------:| :--------------------------------------------------------------------------: | モデル | プロバイダ | 特徴 || Google|多言語に対応、高品質なニューラル音声合成 | Google Cloud TTS|Google| 複数の音声と言語、高品質のニューラル音声をサポート。 | | Amazon Polly|AWS| 発話速度、ピッチ、音量など、カスタマイズ可能な音声パラメータを提供。| | Microsoft Azure Speech| マイクロソフト|様々な表現力豊かな音声でニューラルTTS機能を提供。 | | モジラTTS|オープンソース|無料、オープンソースで、よりコントロールしたい開発者のためにカスタマイズ可能。 |
これらのプラットフォームは、高品質の自然な音声、カスタマイズ機能、より柔軟性を求めるための無料かつオープンソースのソリューションなど、特定のニーズに応じてさまざまなオプションを提供します。
課題と限界
近年、TTSテクノロジーは大きな進歩を遂げていますが、いくつかの課題や限界も残っており、TTSの全体的な有効性や多様なアプリケーションへの導入に影響を与えています。これらの課題は、TTSシステムの信頼性と責任性を確保するために注意を払う必要がある。
自然さと表現力
TTSの著しい進歩にもかかわらず、自然さと表現力は依然として懸念される分野である。Tacotron 2やFastSpeech**のような最新のモデルは、非常に明瞭でクリアな音声を生成することができますが、人間のスピーカーのように流れるように感情を伝えるとなると、まだ不十分です。スピーチがロボットっぽく聞こえたり、人間のスピーチにある微妙な感情のニュアンスが欠けたりすることがあります。
多言語の課題
複数の言語やアクセントを扱うことは、もうひとつの大きなハードルです。言語の音声構造、文法規則、発話パターンは大きく異なるため、すべての言語を同じように扱える単一のモデルを作成することは困難です。さらに、同じ言語でも地域によってアクセントが異なるため、正確な発音と自然な音声を確保するためには、独自のトレーニングデータが必要になることがよくあります。TTSモデルは、代表的でない方言や言語で苦労することがあり、多様なユーザーベースが関与するグローバルなアプリケーションで問題になります。
倫理的懸念
TTS 技術が進歩するにつれて、倫理的な影響が懸念されるようになっている。主なリスクのひとつは、TTSをディープフェイク技術に悪用する可能性である。これは、誤った情報の拡散や詐欺行為といった悪意のある活動に利用される可能性がある。さらに、TTSモデルのバイアスは重大な問題である。歪んだ、または代表的でないデータセットでモデルが訓練された場合、人種、性別、またはアクセントのバイアスが永続化し、音声対話における差別的な結果につながる可能性があります。
計算コスト
最後に、高度なニューラルネットワークを使用して高品質で自然な音声を生成するには、かなりの計算コストがかかります。WaveNetやTacotron 2**のようなディープラーニングモデルは、膨大な量のトレーニングデータと強力なコンピューティングリソースを必要とするため、中小企業や個人の開発者には手が届かないことがよくあります。その結果、品質と効率の両方についてモデルを最適化することは、継続的な課題となっています。
Google CloudによるTTSアプリケーションの実装
Google CloudはText-to-Speech APIを提供しており、高品質なニューラルネットワークベースの音声合成をアプリケーションに簡単に統合できます。このAPIは、事前に訓練されたさまざまな音声を提供し、複数の言語とアクセントをサポートし、SSML(音声合成マークアップ言語)や音声チューニングなどの機能によってカスタマイズできます。
Google CloudのTTS APIを使用する最大の利点の1つは、すべての処理がクラウドで処理されるため、リソースを消費しないことです。そのため、バーチャルアシスタントやカスタマーサポートボットから、オーディオブックやアクセシビリティツールまで、幅広いアプリケーションに適しています。
環境のセットアップ
1.必要なライブラリのインストール: PythonアプリケーションでGoogle CloudのText-to-Speech APIを使用するには、google-cloud-texttospeechライブラリをインストールする必要があります。
pip install google-cloud-texttospeech
Google Cloudアカウントと認証のセットアップ
以下の手順に従って、GoogleクラウドプロジェクトのセットアップとAPIの認証を行ってください。
Google Cloud プロジェクトを作成します。
音声合成 API を有効にします。
サービスアカウントとjsonキーを作成します。
credentials.jsonキーファイルをダウンロードします。
環境変数にクレデンシャル・ファイルを指すように設定する。
インポート os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "credentials.json"
TTS アプリケーションの実装
環境が整ったので、Google Cloud APIを使って音声合成機能を実装しましょう。
text_to_speech()`関数は入力されたテキストをGoogle CloudのText-to-Speechサービスを使って音声に変換します。
言語、性別(FEMALE、MALE、NEUTRAL)をカスタマイズでき、オプションで音声名を指定できます。例えば、voice_name='en-US-Wavenet-C'は高品質のWavenet voiceのいずれかを使用します。
音声はMP3ファイルとして保存されます。
from google.cloud import texttospeech
# 音声合成APIのクライアントをセットアップする
def setup_tts_client():
# 認証用の環境変数が設定されていることを確認する
if 'GOOGLE_APPLICATION_CREDENTIALS' not in os.environ:
raise EnvironmentError("GOOGLE_APPLICATION_CREDENTIALSが設定されていません。")
client = texttospeech.TextToSpeechClient()
クライアントを返す
# 音声合成APIを使ってテキストを音声に変換する
def text_to_speech(text, language_code='en-US', gender='FEMALE', voice_name=None):
client = setup_tts_client()
# 合成入力と音声パラメータを設定する
synthesis_input = texttospeech.SynthesisInput(text=text)
# 性別と言語に基づいて音声を選択する
voice_params = texttospeech.VoiceSelectionParams(
language_code=language_code、
ssml_gender=texttospeech.SsmlVoiceGender[gender]、
名前=音声名
)
# 音声設定(音声エンコード形式)を設定する
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3、
speaking_rate=1.0、
pitch=0.0
)
# 音声合成のリクエスト
response = client.synthesize_speech(input=synthesis_input, voice=voice_params, audio_config=audio_config)
# 音声をMP3ファイルに保存
with open('output.mp3', 'wb') as out:
out.write(response.audio_content)
print("音声をoutput.mp3として保存")
# 使用例
text = "こんにちは、Zillizの音声合成の世界へようこそ!"
text_to_speech(text, gender='FEMALE', voice_name='en-US-Wavenet-C')
結論
基本的な機械的システムから今日の高度なニューラル・ネットワークに至るまで、音声合成(TTS)技術は長い道のりを歩んできた。これらの技術革新により、合成音声の自然さが大幅に改善され、より人間に近く、理解しやすくなった。TTSは現在、バーチャルアシスタント、アクセシビリティツール、コンテンツ生成などのアプリケーションで広く使用されており、ユーザーにより高い利便性とインタラクションを提供している。
この技術の発展は新たな可能性を引き出し、教育、エンターテインメント、カスタマーサービスなどの分野におけるユーザー体験を向上させている。TTSは、デバイスとのハンズフリーインタラクションを可能にし、視覚障害者がコンテンツにアクセスするのを助け、チャットボットや音声アシスタントのような自動化システムに力を与える。AIが進歩し続けるにつれ、TTSシステムはさらに洗練され、特定のユーザーのニーズを満たすために、よりダイナミックでパーソナライズされた音声を提供するようになっています。
今後、TTSはさらにシームレスで、適応性が高く、効率的になると予想される。AIの革新は、感情や文脈の感度を高め、インタラクションをより自然に感じさせる、より表現力豊かな音声につながるだろう。これによって、デバイスとのインタラクション方法が変化し、アクセシビリティ、コミュニケーション、コンテンツの生成と消費の方法がさらに強化されるだろう。
次のディープダイブをご覧ください:"【正しいオーディオトランスフォーマーの選択:徹底比較】(https://zilliz.com/learn/choosing-the-right-audio-transformer-in-depth-comparison)"
 Benito Martin
Benito MartinFreelance Technical Writer
読み続けて

音声データに最も使用されている埋め込みモデルトップ10
Wav2Vec 2.0、VGGish、OpenL3など、最も人気のある10種類のオーディオ埋め込みモデルをご紹介します。AIアプリケーションのために音をベクトルに変換する方法を学ぶ

マルチモーダルAIの強化:音声、テキスト、ベクトル検索の橋渡し
この記事では、音声、テキスト、ベクトル検索を橋渡しすることで、マルチモーダルAIがどのようにAIシステムを強化するかを探る。

ベクトルデータベースによる音声類似度検索の拡大縮小
MilvusやZilliz Cloudのようなベクトルデータベースが、いかに効率的なオーディオ類似性検索を大規模に実現し、音楽推薦やオーディオ検索アプリケーションを変革するかをご覧ください。