




ガーベッジ・イン、ガーベッジ・アウト:お粗末なデータキュレーションがAIモデルを殺す理由
現代社会では、データは石油と同じくらい貴重なものとなっている。企業は従来、モデルを構築し、洞察を得るために膨大な量のデータを収集することに重点を置いてきたが、その焦点は量よりも質に移りつつある。現在、多くの企業は、大規模なデータセットを集めることよりも、質の高いデータを持つことの方が重要であると認識している。しかし、このシフトは重大な課題を明らかにしている。多くの企業は、既存のデータを十分に理解し、効果的にキュレーションすることに苦戦しているのだ。
Zilliz主催のUnstructured Data Meetupでは、EncordのリードMLソリューションエンジニアであるAlexandre Bonnetが、不十分なデータキュレーションの落とし穴と企業がこれらの課題を克服する方法について講演し、この問題を取り上げた。彼はデータ品質と市場動向の重要性を強調し、企業が高品質なデータ生産パイプラインを確立するためのロードマップを提示した。このブログでは、Alexandre氏の重要なポイントを振り返ります。また、YouTubeで彼の講演をフル視聴することもできます。
EncordのAlexandre Bonnet氏による7月の非構造化データ・ミートアップでの講演](https://assets.zilliz.com/encord_1_778f16b268.JPG)
AIの進化
アレックスは、企業における従来のAIアプリケーションから最新のジェネレーティブAIへのシフトについて議論している。約10年前、AIモデルはユースケースごとにゼロから構築する必要があり、一般的に1種類のデータ(ユニモーダル)だけを扱うように制限されていた。こうした初期のモデルは、主にデータ・サイエンティストやエンジニアからなる技術チームが使用していた。しかし、今日のAIの状況は、YOLO、GPT、Claudeのような基礎モデルによって大きく進化しており、特定のドメイン向けに比較的簡単に微調整することができる。さらに、最新のアーキテクチャは複数のデータタイプ(マルチモーダル)を処理できるため、深い技術的背景を持たない一般ユーザーでもAIにアクセスできるようになっている。このシフトにより、さまざまな業界でAIが広く採用され、ワークフローやプロセスが合理化されている。
図- 従来のAIと現代のAI](https://assets.zilliz.com/Figure_Traditional_AI_vs_Modern_AI_1624576ae0.png)
アレックスは、「この10年間、人工知能のあらゆる分野の研究が爆発的に進展している」と指摘する。合成データやジェネレーティブAIなどの分野では進歩が見られるものの、コンピュータビジョンの進歩は比較的遅れている。これは、非構造化画像データを理解することの複雑さによるところが大きく、独特の課題を突きつけている。
図:過去10年間におけるAIの様々な分野での発展](https://assets.zilliz.com/Figure_Developments_in_different_spaces_of_AI_over_the_past_decade_40cdb0b723.png)
アレックスは、AIの3つの柱を強調している:データ、モデル、計算です。トランスフォーマー](https://zilliz.com/learn/NLP-essentials-understanding-transformers-in-AI)、アテンション・メカニズム、特定のタスクに対して微調整が可能な大規模言語モデル(LLMs)などのモデル・アーキテクチャにおける急速な進歩がある一方で、ハードウェア、特に複雑なモデルを訓練するために設計された高性能GPUの開発においても大きな進歩があった。**しかし、モデルや計算能力におけるこのような進歩にもかかわらず、データ品質は成熟の初期段階にとどまり、遅れをとり続けている。
図:AIの柱](https://assets.zilliz.com/Figure_Pillars_of_AI_6f3ea9a788.png)
AIにとってデータ品質が重要な理由
ノイズの多いデータセットや不潔なデータセットで学習されたテキストベースのモデルは、しばしば論理的誤りや意味不明な文字を含む出力を生成する。同様に、いくつかの拡散ベースのもののような画像モデルは、透かしのような予期せぬアーチファクトを含むビジュアルを生成することが知られている。根本的な原因は?**データの管理不足である。
図:データクリーニング vs データキュレーション](https://assets.zilliz.com/Figure_Data_cleaning_vs_data_curation_e046fa1bf5.png)
明確にするために、データキュレーションとは、ラベリングやモデルトレーニングのためにデータを整理、管理、準備することであり、特定のタスクに関連し、構造化されていることを保証することである。データクリーニングは、重複の除去、破損サンプルの修正、ノイズへの対処など、データのエラーや不整合の特定と修正に重点を置く。どちらのプロセスも、高品質で信頼できるデータのみがモデルトレーニングに使用されることを保証します。
大規模なトレーニングデータのクリーニングと改良は大きな課題である。例えば、YouTubeの動画を使ってマルチモーダルモデルをトレーニングするタスクを考えてみよう。膨大な量のデータには、破損した音声、不適切な言語、または無関係なコンテンツが含まれている可能性があります。データを厳密にキュレーションしなければ、これらの問題はAIモデルのパフォーマンスと信頼性を低下させる可能性がある。
効果的なデータキュレーションには、データセットを綿密にフィルタリング・分析し、高品質で適切なデータのみがモデルに入力されるようにすることが含まれます。アレックスは、「優れたデータは優れたモデルに等しい**」という原則が、生成AIにおいて特に当てはまると強調する。産業環境における溶接欠陥の検出や、手術ロボット工学の支援など、分野特有のアプリケーションでは、トレーニング・データは関連性が高く、意図されたユースケースを正確に反映したものでなければならない。このレベルのキュレーションは、モデルがエッジケースを効果的に処理し、失敗のリスクを低減するのに役立ちます。
アレックスはプレゼンテーションの中で、十分にキュレーションされたデータの重要性を示す例を紹介した。ある例では、GPT-4のようなビジョンベースの言語モデル(VLM)が、画像内のスクールバスが正面を向いているのか後ろを向いているのかを識別できなかった。この失敗は、洗練されたモデルであっても、高品質でキュレーションされたデータがなければ苦戦することを浮き彫りにしており、モデルの精度とパフォーマンスを向上させるためには、包括的なデータのキュレーションとクリーニングが必要であることを強調している。
図:視覚ベースのLLMは、ノイズの多い訓練データのためにモデル性能が低い](https://assets.zilliz.com/Figure_Vision_based_LL_Ms_have_poor_model_performance_due_to_noisy_training_data_035ad9dcc4.png)
領域特異的なモデルの微調整のためのデータキュレーション
さて、AIのパフォーマンスにとってデータの質が重要であることを学んだところで、データ・キュレーションが特定のドメインのモデルを微調整する上でいかに重要な役割を果たすかを示す例を探ってみよう。
LLaVAはMeta AIによって開発された汎用大規模言語モデルで、人間の言語を理解するのに非常に長けている。しかし、医療分野などより専門的な分野に適応させるには、的を絞ったデータキュレーションの努力が必要です。この微調整の過程で、医療用途に特化したAIアシスタントであるLaVA-Medが誕生しました。
このプロセスにおける主なステップを紹介しよう:
図:医療知識によるLLMのファインチューニング](https://assets.zilliz.com/Figure_Fine_tuning_LLM_with_medical_knowledge_c6d8b9a3ce.png)
医療概念のアライメント
最初の微調整段階では、利用可能なデータセットのわずか4%-教科書や研究論文から入手した画像とテキストのペア-60万-を使用した。モデルが本質的な医学概念を学習できるよう、バランスの取れたデータセットを作成するために、かなりの時間と労力が費やされた。このプロセスでは、人間の専門知識と半自動化技術を組み合わせ、キュレーションされたデータが医療領域のニュアンスを正確に反映するようにした。
医療インストラクションのチューニング
第2段階では、医療クエリへの対応方法を学習するために、6万件の質問と回答のペアを用いてモデルを微調整した。この段階により、モデルは入力プロンプトを理解し、関連する情報を取得し、医療コンテキストに基づいた正確な回答を生成できるようになった。インストラクションチューニングに重点を置くことで、実世界の医療状況においてコンテキストを意識した支援を提供するモデルの能力が向上した。
トレーニング用に少量で質の高いデータセットを作成することで、チームはLLaVA-Medを効率的に微調整し、正確な結果を得ることができました。このケーススタディは、ドメイン固有の大規模言語モデル(LLM)の開発におけるデータキュレーションの重要性を強調しています。また、綿密なキュレーションと的を絞ったファインチューニングによって、汎用モデルを医療分野で輝きを放つ特化型ツールに変貌させることができることも強調している。
データ品質とキュレーションの進化トレンド
従来のデータパイプラインでは、収集されたデータは通常、手作業によるアノテーションか、人間が監視するモデルを使用したプレアノテーションを受けていた。その後、アノテーションされたデータはモデルのトレーニングに使用され、その後デプロイされる。この直線的なアプローチはシナリオによっては有効かもしれないが、特殊なユースケース、特に膨大な量の非構造化データを扱う場合には不十分である。
こうした課題に対処するために、アレックスはより柔軟で堅牢なデータパイプラインの必要性を強調している。最新のパイプラインは、データのキュレーションを強化するための追加ステージを組み込むことができる。データが収集され、データウェアハウスに保存されると、外部ツールを活用して、モデルのトレーニングに進む前にデータを検証し、クリーニングし、キュレーションすることができる。これらのツールは、データセットを改良するための重要なステップであるアノテーション後に、データのラベリング品質を保証する。
図-最新のデータパイプラインにおけるデータキュレーションと検証ツール](https://assets.zilliz.com/Figure_Data_Curation_and_Validation_tools_in_modern_data_pipelines_69d06ef923.png)
さらにAlexは、モデルデプロイメント後のモニタリングパイプラインの設定の重要性を強調している。これらのパイプラインは、継続的な評価と改善を可能にし、モデルが新しいデータに適応し、正確さを維持することを保証する。パイプラインを改良し、これらの追加ステップを実施することで、企業はデータの品質を高め、モデルのパフォーマンスを向上させることができます。
データのキュレーションとクリーニングにおける共通の課題
データのキュレーションとクリーニングには、AIモデルの効率と精度を妨げるさまざまな課題がある:
手作業によるデータレビュー:手作業によるデータレビュー:何時間ものビデオ映像をスクロールするなど、大規模なデータセットを手作業でレビューすることは、時間がかかるだけでなく、エラーが発生しやすい。
アドホック・アプローチ**:適切な永続化レイヤーを持たないその場しのぎのソリューションに頼ることは、しばしば不整合を引き起こし、データキュレーションプロセスを効果的に管理することを困難にする。
データ品質の問題**:データセットには重複や破損したサンプル、ノイズの多い情報が含まれていることが多く、モデルのパフォーマンスを低下させる可能性があります。
クロスモーダル相互作用**:異なるデータモダリティ(例:テキスト、画像、ビデオ)間の関係を分析することは複雑であり、正確なデータ表現と相互作用を保証するための高度なツールと技術を必要とします。
組織がデータキュレーションの課題を克服する方法
アレックスは、重複、破損データ、ノイズの多いサンプルなどの一般的なデータ品質の課題に取り組むためにEncordで開発された革新的なアプローチを共有します:
- エンベッディング・ベースのアプローチ**:非構造化データは、埋め込みモデルを通して高次元のベクトル埋め込みに変換し、Milvusのようなベクトルデータベースに保存することができます。組織は、低次元空間における埋め込みを視覚化することによって、異常や異常値を素早く特定することができる。このアプローチは、非構造化データの検索、整理、キュレーションを容易にする。
図:エンベッディングを使ってトレーニングデータのサンプルを可視化する](https://assets.zilliz.com/Figure_Using_Embeddings_to_Visualize_Training_Data_Samples_0b8bbf19d2.png)
データ品質メトリクス**:ぼやけ具合、明るさ、埋め込み類似度などの指標は、コンピュータビジョンタスクにおける画像データセットの品質を評価するために使用することができます。
データキュレーションのための自然言語処理**:自然言語処理により、トレーニングやテストに最も関連性の高いデータサンプルのみをフィルタリングして選択し、ノイズを減らしてモデルの精度を向上させることができます。
パーシステンス・レイヤー適切な永続化レイヤーを実装することは、データキュレーションプロセスを管理し、結果の一貫したキャプチャと保存を可能にするために非常に重要です。
データ重複排除**:エンベデッドベースの類似性測定は、重複サンプルの特定と削除に役立ち、データ品質を向上させ、ストレージの必要性を削減します。これはまた、補強のための類似データポイントの発見にも役立ちます。
メタデータの検証**:自動化されたツールは、データの完全性を保証し、破損したサンプルを検出するためにメタデータを検証します。Encordはこのタスクのために設計された特別なツールを提供し、プロセスを合理化します。
データクリーニング**:異常値検出、インピュテーション、正規化などの技術により、データセットのノイズに対処し、高性能モデルのトレーニングに適したデータを確保します。
効果的なデータキュレーションとクリーニングの利点
モデル性能の向上:** 高品質なデータは、より正確で信頼性の高いモデルにつながります。
トレーニング時間の短縮: **クリーンでキュレーションされたデータはトレーニングプロセスを加速させる。
コストの削減: **追加的なデータ収集とラベリングの必要性を回避することで、組織はコストを削減することができます。
モデルの説明可能性の向上:よくキュレーションされたデータは、モデル出力の解釈可能性を向上させます。
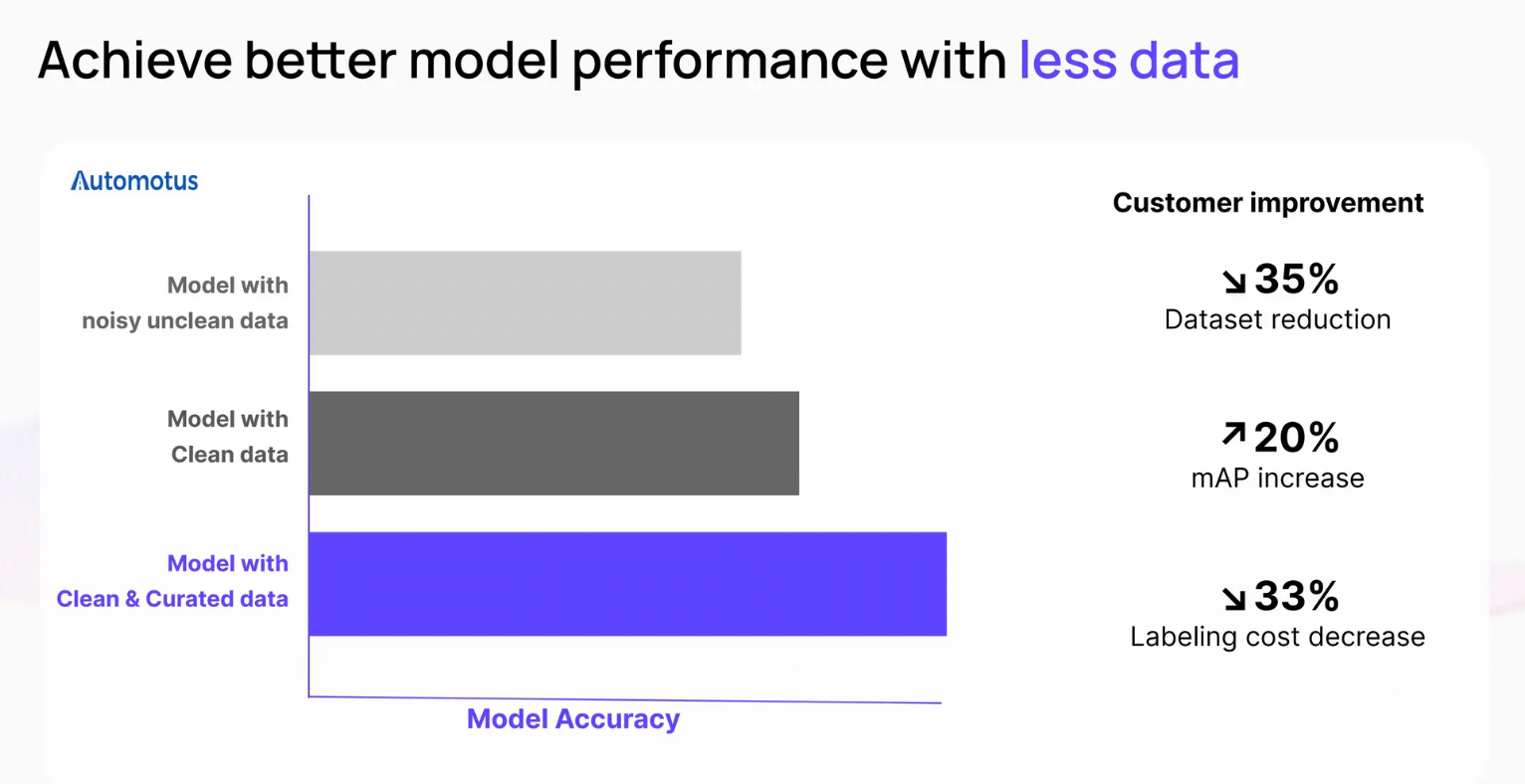
結論
効果的なデータキュレーションは、AIアプリケーションが複雑化するにつれて、特にビデオやテキストのような複数のデータタイプを扱うアプリケーションでは、ますます重要になります。アレックスの講演では、画像やテキストデータセットのキュレーションに関連する様々な課題と、これらの問題がモデルのパフォーマンスに直接どのように影響するかについて、より深い理解を得ることができます。
ベクトル埋め込みやNLPベースのクエリなどのテクニックは、チームがデータをより良く可視化し、誤ったラベル付けや重複したサンプルを識別し、モデルトレーニングの前にデータセットをより効率的にクリーニングするための貴重なツールを提供します。データサイエンスチームが確実に成功するためには、画像埋め込みやテキスト埋め込みなど、特定のデータタイプに合わせた適切な埋め込みモデルを選択し、Milvusのようなベクトルデータベースを活用してデータの保存と検索プロセスを効率化する必要があります。
最終的には、高品質のデータキュレーションに投資することで、モデルのパフォーマンスを向上させるだけでなく、エラーのリスクを低減し、AIワークフローの全体的な効率を高めることができます。
その他のリソース
ベクターデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
読み続けて

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.