




Voyage AIエンベッディングと検索とRAGのためのリランカー
#はじめに
以前は、AIは主に情報を分析し、提案するために活用されていた。しかし、ジェネレーティブAIの出現により、私たちは新しいユニークなコンテンツを生成できるようになった。それはクールな響きに聞こえるが、時にはそのコンテンツが誤解を招くこともある。
RAG(Retrieval Augmented Generation)が登場し、大規模な言語モデルの出力を最適化することで、クエリのコンテキストを提供する。ZillizとVoyage AIは、後の記事で紹介するように、RAGパイプラインを簡単に構築できるように提携した。Voyage AIは、ドメインごとにカスタマイズされた埋め込みモデルと検索用のリランカーを提供している。この記事では、その一部について説明する。
ZillizクラウドパイプラインとVoyage AIでRAGを作る.png](https://assets.zilliz.com/Crafting_RAG_with_Zilliz_Cloud_Pipelines_and_Voyage_Ai_025861fdff.png)
モデルの埋め込みとVoyage AI
コンピュータは、テキストや画像のようなデータから情報を理解することはできません。私たちは、非構造化データの背後にあるセマンティクスをコンピュータに理解させるために、埋め込みモデルを使用します。このセクションでは、エンベッディング・モデルの基本、ジェネレーティブAIにおけるその有用性、そしてなぜRAGがエンタープライズ向けジェネレーティブAIの主流であるのかについて説明します。
エンベッディング・モデルの概要
埋め込みモデルは、与えられたデータに対してベクトル埋め込みを作成する深層学習モデルです。これらのモデルは、与えられたテキスト、画像、音声、あるいは数値以外のあらゆる形式のデータを、コンパクトなベクトル表現に変換します。この表現はvector embeddingとも呼ばれ、情報を数値ベクトル空間にマッピングします。
非構造化データをベクトル埋め込みにエンコードする](https://assets.zilliz.com/Encoding_unstructured_data_into_vector_embeddings_53014d10dc.png)
生成AIの欠点
煩雑なタスクを自動化し、最小限の労力で結果を出すその魅力的な能力により、企業レベルでのジェネレーティブAIの利用は急増している。ジェネレーティブAIが様々なシナリオを支援してくれることは称賛に値するが、欠点もある。ChatGPT](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code)のようなGenAIのモデルは、複数のドメインからの数百万から数兆のデータエントリーを基に訓練された一般的なモデルである。この事実は時に問題となる。モデルは確率的であり、提供されたコンテキストに基づいて次の単語を生成する。文脈が限られていたり、モデルにとって新しいものであったりすると、幻覚を見始める。そこでRAGが輝く。
RAGと幻覚を減らす方法
RAG](https://zilliz.com/learn/Retrieval-Augmented-Generation)のテクニックは、提供されたクエリを埋め込むために、ドメイン固有の埋め込みモデルを使う必要がある。このクエリは、次にベクトルデータベースに持ち込まれ、そこで類似の文脈ベクトル埋め込みをフェッチするためにセマンティック検索が適用される。そして、ベクトルデータベースと提供されたクエリから、関連するすべての文書がモデルに渡される。モデルは、クエリからの追加情報とコンテキストを使用して、関連性の高い、最新かつ正確な結果を作成する。このようにして、RAGアーキテクチャはモデルからの幻覚を減らし、よりロバストで信頼性の高いLLMを可能にする。
RAGアーキテクチャ](https://assets.zilliz.com/The_RAG_architecture_c9573d7132.png)
さて、ここまで埋め込みモデルとRAGにおけるその役割について説明してきましたが、次にVoyage AIの埋め込みモデルについて説明しましょう。Voyage AIは、効果的かつ効率的なRAG技術を実行するために、様々な領域にわたってカスタマイズされた埋め込みモデルを提供しています。これらのモデルは、ZillizによるMilvusのようなベクトルデータベースと接続され、生成されたクエリに関連するベクトル埋め込みを格納・検索する。
Voyage AI埋め込みモデル
Voyage AIは、様々な効率的かつ効果的なドメイン固有および汎用の埋め込みモデルを提供します。これらのモデルは検索とRAGに大きく貢献します。一般的な埋め込みモデルよりも高い検索品質を提供します。
複数のエンベッディングモデルの中で、最も優れたものには voyage-code-2、voyage-law-2、voyage-large-2-instruct がある。Voyage AIは、特定のコード、法律、金融、多言語ドメインのためにこれらのモデルを開発した。さらに、私たちは特定のユースケースに応じてこれらのモデルをカスタマイズすることができる。最新のモデルを見てみよう:
- voyage-code-2:**クエリに関連するコードをピンポイントで提供することに精通したモデル。次の図は、コード検索タスクに対するvoyage-code-2のパフォーマンスを示している:
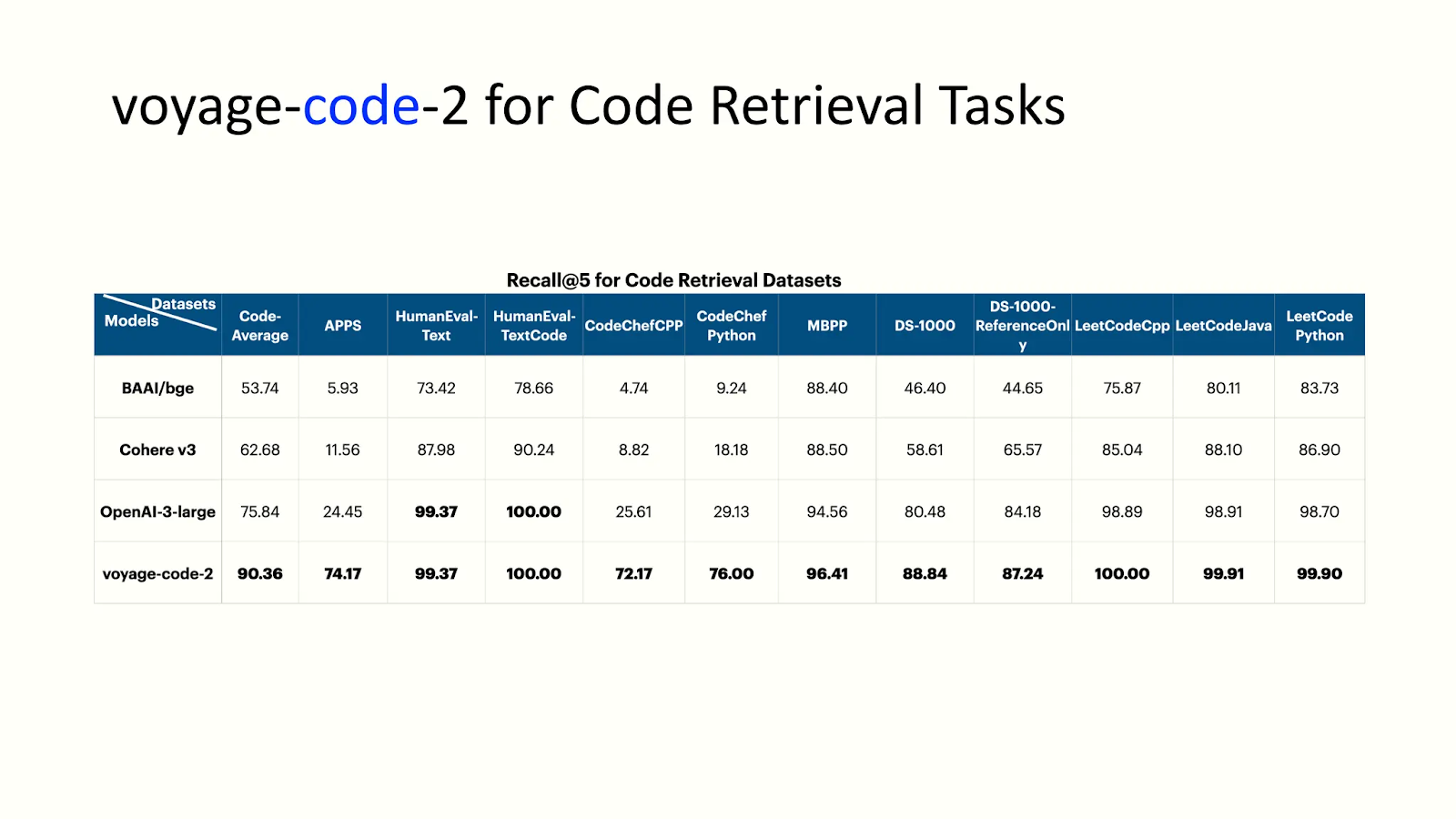 voyage-code-2の性能分析.png
voyage-code-2の性能分析.png
- voyage-law-2:法律文書の文脈と埋め込みを得るために学習されたモデル。voyage-law-2:voyage-law-2:**法律文書のコンテキストと埋め込みを取得するために学習されたモデル。以下の図はvoyage-law-2の性能を強調している:
voyage-law-2の性能分析](https://assets.zilliz.com/Fig_4_voyage_law_2_performance_analysis_3de17cc965.png)
上の図は、Voyage AI埋め込みモデルの性能を示しており、Massive Text Embedding Benchmark (MTEB)によってトップランクにランクされています。
再ランカーとVoyage AI
我々は、RAGがそのようなモデルの幻覚を減らすことで、GenAIの出力の質を向上させることを議論した。しかし、GenAIモデルのコンテキストウィンドウに関連する若干の問題が残っている。コンテキストウィンドウとは、AIモデルが処理のために任意の時点で取り込める情報の最大量のことである。ウィンドウが小さければモデルが得られる情報は少なくなり、大きければ処理コストと時間が増大する。
リランカーは、提供されたクエリとの関連性スコアを計算することで、最適な結果を得るためにベクトル・データベースからフェッチされたドキュメントをランク付けする。ランク付けは、最も関連性の高い(情報量の多い)文書をコンテキストウィンドウ内に収まるようにフィルタリングし、最も正確な結果を生成するのに役立つ。
RAG技術が文脈情報を提供し検索を支援するためにベクトル埋め込みをフェッチするのに対して、これらのモデルはLLMに最も関連性の高いデータを提供するために、関連性スコアを使用してフェッチされたすべての埋め込みを再ランク付けする。
シンプル・リランカー・アーキテクチャ](https://assets.zilliz.com/Fig_5_Simple_Reranker_Architecture_7cb4012b8d.png)
Voyage AIリランカー
Voyage AIはrerank-lite-1として知られるリランカーモデルを開発した。このボヤージ・モデルは、待ち時間と品質を最適化した汎用のリランカーである。4000トークンのコンテキストウィンドウを持つ。次の図はこのモデルの性能を示している。
voyage:ranke-lite-1の性能分析](https://assets.zilliz.com/Fig_6_voyage_ranke_lite_1_performance_analysis_0046bbd927.png)
Zilliz CloudパイプラインでVoyageエンベッディングを使う
ZillizとVoyage AIは、Zilliz Cloud上で非構造化データを検索可能なベクトル埋め込みデータに変換することを合理化するために提携しました。
ここでは、Zilliz CloudとVoyage AI埋め込みモデルを統合し、埋め込み生成と検索を効率化する方法を紹介します。また、この統合とCohere(LLM)を使ってRAGアプリケーションを構築する方法も紹介します。さあ、始めましょう。
Zilliz Cloudのセットアップ
1.まずはZilliz Cloudを立ち上げます。まだZilliz Cloudのアカウントを持っていない場合は、無料でサインアップしてください。
2.2.初めてログインすると、以下のコンソールが画面に表示されます。
クラスタ作成用Zillizクラウドコンソール](https://assets.zilliz.com/Zilliz_cloud_console_for_creating_a_cluster_b45e5c9cad.png)
3.必要に応じてクラスタ**を作成します。Zillizは、学習、実験、プロトタイピングのための無料階層を提供し、後で異なる本番プランに移行することができます。
 Zillizで新しいクラスタを作成する.png
Zillizで新しいクラスタを作成する.png
4.新しいクラスタを作成すると、接続に必要なすべての情報が表示されます。
クラスタへの接続](https://assets.zilliz.com/Connection_to_the_cluster_b03e2b9819.png)
プロジェクトID**は上部メニューバーのProjectsから取得できます。対象のプロジェクトを探し、そのIDをプロジェクトID欄にコピーします。
プロジェクトIDのプロジェクトダッシュボード](https://assets.zilliz.com/Projects_Dashboard_for_Project_ID_f2e2578120.png)
5.これでクラスタへの接続に必要な材料はすべて揃いました。いよいよパイプラインを構築します。RAGアプリケーションのLLMとしてCohereを使用します。そのために cohere をインストールします。
pip install cohere
このnotebookに必要なインポートは以下の通りです。
インポート os
インポートリクエスト
以下のコードでは、CLOUD_REGION、CLUSTER_ID、API_KEY、PROJECT_ID を設定している:
CLOUD_REGION = 'gcp-us-west1'
CLUSTER_ID = 'あなたのCLUSTER_ID'
API_KEY = 'あなたのAPI_KEY'
PROJECT_ID = 'あなたのPROJECT_ID'
Zillizクラウドパイプライン
Zilliz Cloud Pipelinesは、非構造化データを検索可能なベクトルコレクションに変換し、埋め込み、取り込み、検索、削除の処理を行います。Zilliz Cloudは3種類のパイプラインを提供しています:
1.1. 取り込みパイプライン:構造化されていないデータを検索可能なベクトル埋め込みデータに変換し、Zilliz Cloudのベクトルデータベースに格納します。入力フィールドを変換し、検索のための追加情報を保持するための様々な機能が含まれています。
1)**検索パイプラインこのパイプラインは、クエリ文字列をベクトル埋め込みに変換し、対応するテキストとメタデータと共にTop-Kの類似ベクトルを検索することで、セマンティック検索を可能にします。このパイプラインで使用できる関数は1つだけである。
2)削除パイプライン:指定されたエンティティをコレクションから削除する。
取り込みパイプライン
Ingestion パイプラインでは、関数を指定して、入力データに基づいて動作をカスタマイズできます。現在、4 つの関数をサポートしています:
- INDEX_DOC
:INDEX_DOC: ドキュメントを入力として受け取り、チャンクに分割し、各チャンクの埋め込みベクトルを生成する。入力フィールドをコレクション内の4つの出力フィールド(doc_name、chunk_id、chunk_text、embedding)にマッピングする。 - PRESERVE`:通常、出版社情報やタグなどのメタ情報に使用される。
- index_text`:各テキストをベクトル埋め込みに変換し、入力フィールド(text_list)を2つの出力フィールド(textとembedding)にマッピングすることでテキストを処理する。
- index_image`:画像埋め込みを生成し、2つの入力フィールド(image_url と image_id)を2つの出力フィールド(image_id と embedding)にマッピングすることで画像を処理する。
以下のコードスニペットでは、リクエストをZillizクラウドにポストするためにrequestsライブラリを使用します。postリクエストは、URL、ヘッダー、送信データから構成されます。ヘッダーを作りましょう:
headers = {
"Content-Type":"Content-Type": "application/json"、
"Accept":"application/json", "Accept": "application/json"、
"Authorization": f "ベアラ {API_KEY}"
}
以下のコードで collection_name と embedding_service を定義する。エンベッディング・サービスは、Voyage AIモデル、特にvoyage-2を利用します。voyage-2は、検索タスク、技術文書、一般的なアプリケーションで優れたパフォーマンスを示しています。
create_pipeline_url = f "https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines"
コレクション名 = 'Documents'
embedding_service = "voyageai/voyage-large-2"
以下のコードでは、ingestion_pipelineのindex関数を定義しています:
data = {
"name":"name": "ingestion_pipeline"、
"description":"テキスト埋め込みを生成し、タイトル情報を保存するパイプライン"、
"type":"ingestion"、
"projectId":PROJECT_ID、
"clusterId":CLUSTER_ID、
"collectionName": コレクション名、
"functions":[
{
"name":"index_doc"、
"action":"INDEX_DOC"、
"language":"ENGLISH"、
「埋め込み": embedding_service
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
pipelineId`は後でデータベースにデータを取り込むために使用されます。このステップの後、クラスタに作成されたコレクションと、インジェストパイプラインを見ることができます:
ingestion_pipe_id = response.json()["data"]["pipelineId"]。
print(ingestion_pipe_id)
>> pipe-cf...
これがクラウドに作成されたコレクションだ:
クラウドで作成されたコレクション](https://assets.zilliz.com/Collection_created_in_the_cloud_308ece51be.png)
そして、インジェスト・パイプラインは以下のようになる:
Zillizクラウドのインジェストパイプライン](https://assets.zilliz.com/Ingestion_Pipeline_in_Zilliz_Cloud_50c4cb2929.png)
検索パイプライン
検索パイプラインは、クエリ文字列をベクトル埋め込みに変換し、Top-K最近傍ベクトルを取得することで、セマンティック検索を容易にします。Search パイプラインには SEARCH_DOC_CHUNK 関数があり、クラスタの指定と検索元のコレクションが必要です。
Zillizは多くの関数をサポートしている。ここでは SEARCH_DOC_CHUNK を使用する。この関数はユーザクエリを入力し、知識ベースから関連するdocチャンクを返す。
data = {
"projectId":PROJECT_ID、
"name":"search_pipeline"、
"description":"テキストを受け取り、意味的に類似したdocチャンクを検索するパイプライン"、
"type":"search"、
"functions":[
{
"name":"search_chunk_text"、
"action":"search_doc_chunk"、
"inputField":"query_text"、
"clusterId": f"{CLUSTER_ID}"、
"collectionName": f"{コレクション名}"、
"embedding": embedding_service
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
search_pipe_id = response.json()["data"]["pipelineId"]。
インジェストパイプラインと検索パイプラインを作成しました。いよいよこの記事を取り込みパイプラインに挿入し、検索パイプラインを実行します。
インジェストパイプラインの実行
Ingestionパイプラインは、AWS S3やGoogle Cloud Storage (GCS)のようなオブジェクトストレージサービスからファイルを取り込むことができる。取り込めるファイル形式は、.txt、.pdf、.md、.htmlなどです。Zillizコンソールからインジェストパイプラインを実行できる。ステップ・バイ・ステップで実行しよう。
1.左側のPipelinesからingestion_pipelineに移動する:
クラウド上に作成されたパイプライン](https://assets.zilliz.com/Ingestion_Pipeline_created_in_the_cloud_b6ba63c171.png)
2.Run**をクリックすると、以下の画面が表示される:
インジェスト・パイプラインにファイルを添付する](https://assets.zilliz.com/Attach_file_in_the_ingestion_pipeline_dde5ac4b59.png)
テキストファイルをアタッチし、パイプラインを実行します。成功すると、テキストファイルがコレクションにロードされます。これがデータのプレビューです:
コレクションのデータプレビュー](https://assets.zilliz.com/Data_preview_of_the_collection_80f7867cdb.png)
検索パイプラインの実行
RAG (retrieval augmented generation)には2つの主要なコンポーネントがある:レトリーバーとLLMである。リトリーバを作成するのは、検索パイプラインを実行するのと同じくらい簡単である。検索パイプラインはクエリーを取り込み、データベースから最も関連性の高いチャンクを検索する。以下のコードでは、関数retrieverがqueryとtopk(選択するドキュメントの数)を受け取り、検索パイプラインを実行します。
def retriver(question, topk):
run_pipeline_url = f "https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{search_pipe_id}/run"
data = {
"data":{
"query_text": question
},
「params":{
"limit": topk、
"オフセット":0,
"outputFields":[
"chunk_text"、
"id"、
"doc_name"
],
}
}
response = requests.post(run_pipeline_url, headers=headers, json=data)
return [result['chunk_text'] for result in response.json()['data']['result']].
LLMとしてCohereを使用するRAGアプリケーション
ドキュメントを取得した後、CohereをLLMとして使用します。プロンプトに包まれた Cohere チャット API に検索されたドキュメントを提供し、それについて質問します。
インポート cohere
co = cohere.Client(api_key="your_api_key")
def chatbot(query, topk):
チャンク = retriver(query, topk)
response = co.chat(
model="command-r-plus"、
message=f "この情報: '{[chunks for chunk in chunks]}' が与えられたら、次の{query}に対するレスポンスを生成してください"
)
return response.text
question = "法的な検索タスクに適したモデルを探しています"
print(chatbot(question, 2))
これがチャットボットからの返答です:
提供された情報によると、あなたは特に法的な検索タスクに熟達したモデルに興味があるようです。その場合、あなたのニーズに最も適したモデルは "voyage-law-2" です。
結論
Voyage AIは、ドメインごとにカスタマイズされた埋め込みモデルと、高度な検索のためのリランカーを提供する。Zilliz Cloud Pipelinesは、Voyage AIモデルとZilliz Cloudをシームレスに統合し、RAGの開発をより効率化します。
この記事では、人気のvoyage AIエンベッディングモデルとリランカー、そしてZilliz Cloudとの統合について説明した。また、Voyage AI、Zilliz Cloud Pipeline、およびCohereを使用したRAGの構築方法を実演しました。
詳細については、Unstructured Data Meetup by Zilliz..** でのTengyu Maの講演のリプレイをご覧ください。

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.