




なぜコンテキストエンジニアリングがAIエージェントのフルスタックになりつつあるのか
2025年、AIエージェントは至るところにあります。ほぼすべての企業が、チャットボット、コーディングアシスタント、ナレッジベースを驚異的なスピードで構築しています。魅力的なデモを作るのは簡単ですが、エージェントをデモから信頼性の高い本番対応システムへと引き上げるのは別の課題です。そして、その飛躍を遂げるほぼすべてのチームが、同じ障害に直面します:コンテキストです。
あなたのチャットボットは顧客履歴を見ることができません。あなたのコーディングアシスタントはコードベースを理解していません。あなたのビジネスAIはリアルタイムデータにアクセスしたり、意味のあるアクションを取ったりできません…
この問題を回避するために、チームはあらゆる種類の対策を試してきました:綿密に作り込まれたプロンプト、高度なRAG実装、128k以上のコンテキストウィンドウ、そしてコンポーネントを接続するためのMCPのような標準化プロトコルです。
これらはすべて機能します。しかし、多くの場合サイロ化されています—独立して開発・デプロイされているのです。結果として、パズルの一部は解決しても、AIに全体像を与えられない脆いシステムになってしまいます。
もしコンテキストが後付けではなかったらどうでしょうか? もしそれが基盤だったら? そこで登場するのがコンテキストエンジニアリングです。
AIエージェントにおける「コンテキスト」の理解方法
context engineeringに入る前に、まず「コンテキスト」が実際に何を意味するのかを明確にする必要があります。特に、信頼性の高いAIエージェントを構築する場合には重要です。
コンテキストは、LLMに送信する単一のプロンプトだけではありません。それは、モデルが応答を生成する前に目にするすべてです。コンテキストの関連性と品質が高いほど、出力は良くなり、エージェントの行動も賢くなります。その逆もまったく同じです:ゴミを入れれば、ゴミが出てきます。
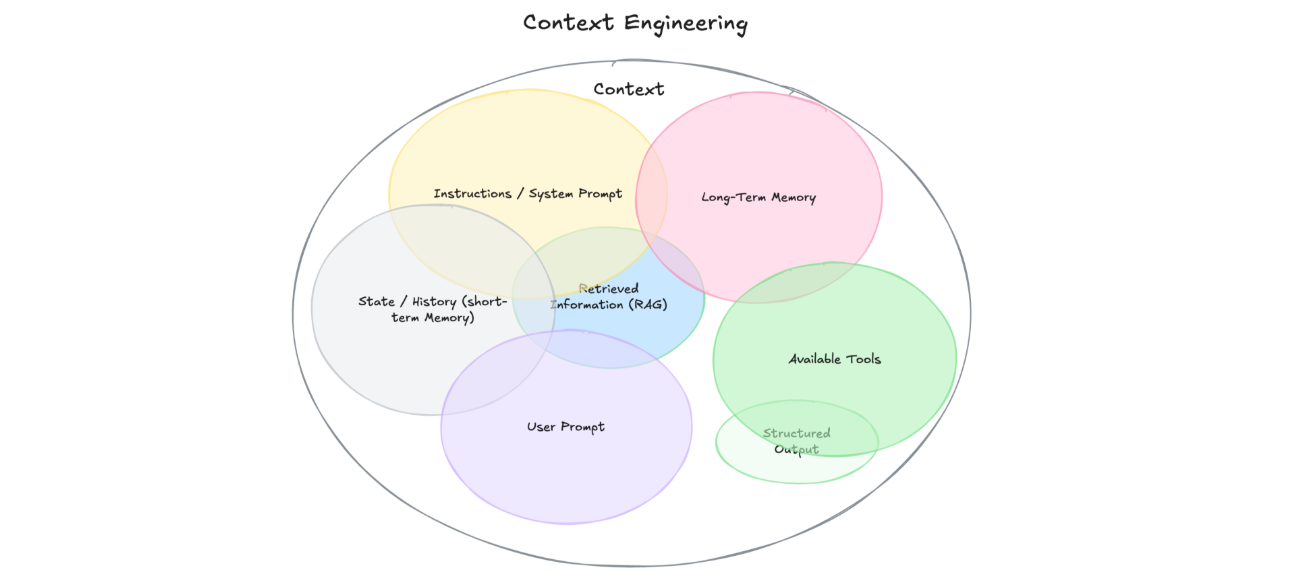
エージェント型AIシステムでは、コンテキストは複数のソースから得られます。その多くを、現在のシステムは効果的に調整するのに苦労しています:
指示 / システムプロンプト – モデルの振る舞いを形作る初期ルールで、多くの場合、例や制約を含みます(例:「当社のナレッジベースにアクセスできるテクニカルサポートエージェントとして振る舞ってください」)
ユーザープロンプト – ユーザーからの直近のタスクや質問(「私のAPI呼び出しが503エラーで失敗しています」)
状態 / 履歴(短期記憶) – これまでの会話で、ユーザーとモデル双方のメッセージを含みます
長期記憶 – 多くのやり取りを通じて集められた永続的な知識。たとえば、ユーザーの好み、過去の作業の要約、記憶された事実など
取得された情報(RAG) – ドキュメント、Milvusのようなベクトルデータベース、またはAPIから取得された、関連性が高く最新の知識(最近のドキュメント、類似の解決済み問題)
利用可能なツール – モデルが呼び出せる関数や組み込み機能(例:check_system_status、create_support_ticket、escalate_to_engineer)
構造化出力定義 – JSONスキーマや特定のフォーマット要件など、モデルの応答に期待される形式
 context engineering.png
context engineering.png
画像クレジット: Philschmid
課題は何でしょうか? ほとんどのエージェントは、本来持てるコンテキストの20〜30%しか使えておらず、それは性能に表れています。パーソナライズすべきときに汎用的な応答を返し、新しい情報が存在するのに古い解決策を提案し、支援するためのツールがあるのにアクションを取れないことがあります。コンテキストエンジニアリングとは、そのギャップを埋めることです。
では、コンテキストエンジニアリングとは何でしょうか?
コンテキストはAIがうまく機能するために必要なすべてのものなので、コンテキストエンジニアリングとは、モデルがそれを—すべてを、適切な形式で、適切なタイミングで—受け取れるようにするシステムを設計する規律です。
この用語は新しいかもしれませんが、その考え方は新しくありません。私たちは何年も前からそこへ向かって進んできました。ただ、それに名前を付けていなかっただけです。RAG、プロンプトエンジニアリング、function calling、MCPなどの技術はすべてパズルのピースです。コンテキストエンジニアリングとは、それらのピースを一貫した全体へと組み合わせることです。
これは、エージェント型AIを構築するための新しいフルスタックだと考えてください。従来のフルスタック開発がフロントエンド、バックエンド、データベースを接続して動作するアプリケーションにするものだとすれば、 コンテキストエンジニアリングは、知識、ツール、推論を接続し、エージェントが実際に扱えるシームレスなインテリジェンス層にします。
その核心にあるのは、コンテキストエンジニアリングにおける3つの主要な原則です。
動的適応 – コンテキストは静的なテンプレートだけでなく、現在のタスクとシステム状態に合わせて自ら形を変えます
ジャストインタイムの組み立て – 適切な情報とツールは、一度にまとめて投入されるのではなく、必要なまさにその時に届きます
最適なフォーマット – LLMが効果的に理解し、行動できるように、すべてが構造化されます
コンテキストを、プロンプトに入れる単なるテキストではなくインフラとして扱うと、完全な状況について推論し、意味のある行動を取り、時間とともにパフォーマンスを向上させるエージェントを作ることができます。
コンテキストエンジニアリングはプロンプトエンジニアリングやRAGとどう違うのか
コンテキストとコンテキストエンジニアリングを理解した後でも、それらをプロンプトエンジニアリングやRAGと混同しやすいものです。いくつかの技術は共通していますが、範囲と目標は異なります。
プロンプトエンジニアリング – LLMの振る舞いを導く入力を作り込む技術です。これには、few-shotの例、ロールプレイ、フォーマット規則、トーン制御が含まれます。応答の形を整えるには強力ですが、不足している知識を追加したり、現実世界のアクションをトリガーしたりすることはできません。
RAG(Retrieval-Augmented Generation) – ハルシネーションを減らすための初期の解決策の1つです。ベクトルデータベース(Milvusなど)から関連文書を取得し、実行時にプロンプトへ注入します。モデルを最新の状態に保つには優れていますが、外部知識の追加だけに焦点を当てており、タスク状態、ユーザー設定、ツール利用の管理までは扱いません。
コンテキストエンジニアリング – それらを包含する分野です。検索、プロンプト設計、ツールオーケストレーション、動的適応を、単一の設計されたシステムへ統合します。目的は、エージェントが効果的に行動できるよう、常に適切な情報、ツール、フォーマットを、適切なタイミングで持てるようにすることです。
こう考えるとよいでしょう。プロンプトエンジニアリングは明確な指示を与えること、RAGは適切な材料を供給すること、そしてコンテキストエンジニアリングはキッチン全体を運営することです。
ベクトルデータベースがコンテキストエンジニアリングを支える仕組み
コンテキストエンジニアリングが新しいフルスタックだとすれば、ベクトルデータベースはそのデータベース層、つまり長期記憶です。なぜなら、AIエージェントにとって最も関連性の高いコンテキストは、ほとんどの場合LLMの学習データの外側、たとえばカスタマーサポートの記録、コードリポジトリ、ナレッジベース記事、センサー読み取り値、さらには画像や音声ファイルの中に存在するからです。
ベクトルデータベースはこの情報を埋め込みとして保存し、セマンティック検索、つまりキーワード一致だけでなく意味に基づいて関連するものを見つけることを可能にします。これはコンテキストエンジニアリングにとって非常に重要です。なぜなら、エージェントが必要とする情報を、必要なまさにその時に、正確に 得られるようにするからです。
ベクトルデータベースがコンテキストエンジニアリングを支える仕組みは次のとおりです。
動的ベクトル検索 – 単純なキーワード検索ではなくセマンティック類似性を用いて、現在のタスクに関連するコンテキストをリアルタイムに提示します。
マルチモーダル対応 – テキスト、画像、音声、動画、さらには構造化データからの埋め込みを1つのシステムで保存・取得します。
鮮度と更新 – 再学習なしにAIの「作業記憶」を最新に保ち、エージェントが新しい情報へ即座に適応できるようにします。
スケーラビリティ – パフォーマンスを低下させることなく数十億のベクトルを扱い、エンタープライズ規模のデプロイを支えます。
コンテキストエンジニアリングされたシステムでは、ベクトルデータベースは単独では機能しません。次のものと連携して動作します。
取得したデータをLLM向けにフォーマットするプロンプト構築層。
テキスト生成を超えたアクションを可能にするツール呼び出し層。
結果に基づいて検索とツール利用を改善するフィードバックループ。
これにより、ベクトルデータベースは受動的なストレージエンジンから、エージェントの推論プロセスの能動的な一部へと変わります。単にクエリに答えるだけでなく、エージェントが下す意思決定を形作るのです。
本番環境のエージェント向けコンテキストエンジニアリングに Milvus が完璧に適合する理由
コンテキストエンジニアリングを支える場合、特に本番レベルの AI Agents を構築する場合、すべてのベクトルデータベースが同じというわけではありません。膨大な量の埋め込みを処理し、複数のデータモダリティに適応し、ボトルネックになることなくミリ秒単位で結果を返せるシステムが必要です。そこで登場するのが Milvus です。
Milvus は、大規模な 高性能セマンティック検索 のためにゼロから設計されたオープンソースのベクトルデータベースです。数十億のベクトルを効率的に保存、インデックス化、取得できるよう構築されており、タイムリーで高品質なコンテキストに依存する、スケーラブルな本番レベルの AI エージェントに最適です。
コンテキストエンジニアリングにおいて Milvus が際立つ理由は次のとおりです。
妥協のないスケール – 数百万でも数十億でも、ベクトルをインデックス化する際に、Milvus はリアルタイムアプリケーション向けの低レイテンシ検索を維持します。
マルチモーダル対応 – テキスト、画像、音声、動画、構造化データからの埋め込みを 1 つのシステムで扱えます。
柔軟なデプロイ – 自社インフラ上で実行することも、Zilliz Cloud を使ってクラウド上で完全マネージドの手間いらずな体験を得ることもできます。
豊富なエコシステム – RAG フレームワーク、AI 開発ツール、既存のデータパイプラインとシームレスに統合できます。
優れたハイブリッド検索 – セマンティック類似性をメタデータフィルターやキーワード検索と組み合わせることで、「過去 2 週間に John がアクセスした、API レート制限に言及し、顧客センチメントがポジティブな価格設定ドキュメントを見つける」といった複雑なビジネスクエリに対応できます
コンテキストエンジニアリングされたアーキテクチャにおいて、Milvus は単なるデータストアではありません。AI エージェントが常に必要な知識をすぐに使える状態にしておくエンジンです。そして Zilliz Cloud と組み合わせれば、クラスター管理やスケーリングの悩みを気にすることなく、エンタープライズグレードの信頼性、弾力性、グローバルな可用性を得られます。
より優れたコンテキストで、よりスマートなエージェントを構築する準備はできていますか?
最も賢い AI エージェントは、最大のモデルによって動いているのではありません。最高のコンテキストによって動いています。コンテキストエンジニアリングがそれを可能にし、その出発点となるのは信頼できる堅牢なベクトルデータベースです。
Milvus は、オープンソースの自由と十億規模のパフォーマンスを提供します。Zilliz Cloud は、Milvus 上に構築された完全マネージドサービスにより、それをさらに発展させます。エンタープライズグレードの信頼性、弾力的なスケーリング、インフラ運用の悩みゼロを実現します。
🚀 あなたに合った方法で始めましょう:
Milvus をローカルまたは自分の環境で実行する。
または、Zilliz Cloud を無料でお試しください。$100 の無料クレジット付きで、セットアップ不要、運用不要です。
目的に特化したベクトルインフラがあなたの AI エージェントに何をもたらせるかを知りたい場合は、お問い合わせ ください。
💡 すでに Pinecone、Weaviate、pgvector、または別のプラットフォームを使用していますか?ダウンタイムゼロでスムーズな移行を支援できます。多くの場合、現在お支払いの 半分のコスト で、しかもより高いパフォーマンスを実現できます。

読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.