




2025年に知っておくべきAI検索エンジントップ5
#はじめに
ChatGPTのような大規模言語モデル(LLM)の開発により、インターネットでの情報検索はより効率的で簡単になった。大規模言語モデルは何十億ものパラメータを持つ膨大なテキストコーパスで学習され、人間の言語を理解し解釈することができます。従来、検索エンジンは、ユーザーが質問したときに最も関連性の高いウェブページやリンクを見つけるために、キーワードマッチングやランク順のような単純な手法に頼っていました。しかし、Open AI SearchやPerplexityのような検索エンジンは、 LLMsと統合されており、ユーザーの意図を正確に識別し、ユーザーのクエリに対してカスタマイズされた応答を生成することができる。 AI検索エンジンは、ヘルスケア、eコマース、エンターテイメントのような業界において、マルチモーダルなクエリサポートが顧客体験を向上させることができる、数多くのアプリケーションを持つことができる。例えば、ユーザーは商品の写真をアップロードし、類似品を検索したり、音声コマンドで素早く要件を指示することができる。
この記事では、いくつかの主要なAI検索エンジンを紹介し、その内部構造、主な特徴、課題について説明する。
1.OpenAIサーチ(GPT駆動型)
OpenAI検索は、様々な検索結果を分析し、ユーザーのクエリに対して人間のような応答を生成することができる、広く使われているAI検索エンジンである。会話形式でクエリを実行できるため、ユーザーフレンドリーなインターフェイスとなっている。タスクの複雑さに応じて、最新版のGPT-4や、より費用対効果の高いGPT-3.5などのGPT(Generative Pre-trained transformers)モデルを搭載しています。
Open AI Searchの主な機能:
文脈理解:** GPTモデルは、自己注意メカニズムを使用するトランスフォーマーベースのアーキテクチャを持ち、ユーザーの過去の入力を保存して処理し、文脈的に正しい答えを検索することができます。
パーソナライズされた回答:**従来の検索エンジンのようにリンクの束を提供するのではなく、Open AIはGPTモデルを使用してすべてのソースをスキャンし、関連する情報を抽出し、ユーザーが好む形式で要約します。例えば、ユーザーはGPTに簡潔な箇条書き、詳細な段落、統計レポートなどの回答を生成させることができます。
コードと技術サポート:** GPTモデルは、Python、C++、Javascriptのような異なるプログラミング言語を理解する訓練も受けており、ユーザーのコードのデバッグや最適化を支援することができます。
エンベッディングを使用した正確なデータ検索:**ウェブ検索とは別に、ユーザーはドキュメントやデータセットをアップロードし、OpenAIを使用して必要な情報を検索することもできます。OpenAIは、ユーザーからのクエリをベクトル埋め込みに変換するAPIを持っており、ベクトルデータセットと照合され、最も類似したデータポイントを見つけることができます。 2.グーグルAIの概要
現在の課題
GPTモデルは定期的に更新されるが、検索はリアルタイムで行われないため、最新の進歩を見逃す可能性がある。
一般化バイアス**は、GPTのようなLLMの一般的な課題であり、非常に広範なデータセットで学習されるため、回答が必要な技術的な深さやニュアンスを欠く可能性がある。これは、ヘルスケアや法律など、高い専門知識が不可欠な分野でよく直面する問題です。
オープンAI検索は引用リンクや直接の情報源を提供しないため、ユーザーは結果を利用する前に追加の事実確認を行う必要があるかもしれない。
GPTモデルは、基礎となる学習データに偏りがある場合、性別やコミュニティに対して意図せず偏った回答を生成する可能性があります。
2.グーグルAIの概要
グーグルのAI検索エンジンは、リアルタイムでウェブサーフィンをすることで、ユーザーのクエリに対して正確でパーソナライズされた回答を生成することができる。この検索エンジンはGoogle Geminiと統合されており、テキスト、画像、動画、音声を含む様々なデータタイプを処理・生成するように設計されたマルチモーダルLLMである。このLLMは、会話中の文脈を保持するために最適化されたトランスフォーマーベースのアーキテクチャを持つ。ジェミニの最新バージョンは、強化されたコンテキストウィンドウのような高度な機能を備えており、推論質問や詳細なレポートの生成のような複雑なクエリを処理することができる。Geminiとは別に、検索エンジンは、会話AIタスクのために特別に設計されたLaMDA(Language Model for Dialogue Applications)のようなモデルも使用している。
主な機能
MLベースのランキングアルゴリズム:** Google AIは、RankNetやLambdaRankのような機械学習アルゴリズムを使用して、情報の質を優先して検索結果をランク付けしている。これらのアルゴリズムは、キーワードの関連性、バックリンク、ユーザー行動、信頼性などを通じて、ウェブページのコンテンツの質を測定する。
推論とロジックの向上:** Googleの検索エンジンは、論理的な推論においても著しい向上を示しており、複雑なクエリを処理することができる。数学的データセットで学習されたPaLM(Pathways Language Model)を使用している。
リアルタイム画像・動画処理:***広範なマルチモーダルサポートが、Google AIを他の検索エンジンと一線を画している。ユーザーは画像や動画をアップロードし、検索エンジンに問い合わせることができる。例えば、植物の写真をアップロードし、Googleに "この植物は何ですか?""この植物にはどんな肥料を使えばいいですか?"と問い合わせることができる。また、顔認識、物体検出、ウェビナーやパネルディスカッション中のビデオからライブのトランスクリプトを生成するためにも使用できる。
最新のGeminiモデルは、より長いコンテキストウィンドウで開発されているため、大規模なクエリをより適切に処理することができる。例えば、ユーザーは300ページの市場動向ドキュメントをアップロードし、"市場動向が季節性によってどのように影響されたかを要約しますか?"と尋ねることができます。
100以上の言語への翻訳:** GoogleのLLMは、中国語、ヒンディー語など100以上の地域言語で訓練されています。ニュース記事や原稿、書籍の正確な翻訳にも利用できる。
現在の課題
透明性と説明性の低さ:Google AIは複数の複雑なモデルに依存しており、ある反応や判断がなされた理由を説明するのは難しい。
グーグルは、パーソナライズされた検索結果を提供するために、膨大な量のユーザーデータを収集・処理している。そのため、ユーザーデータのプライバシーやセキュリティに懸念が生じる。
スピードに最適化されているため、結果を生成する際に詳細な情報を見逃す可能性がある。
3.ビング検索
Bing検索はマイクロソフトによって開発され、検索の関連性を高めるために伝統的なウェブ検索技術とAIモデルを組み合わせている。Bing ChatはOpen AIのGPTモデルとBERT(Bidirectional Encoder Representations from Transformers)と統合されている。これは、ウェブクローリングや高度なMLモデルによるインデックスのような伝統的なランキングテクニックのミックスを使用し、適切なバランスを見つける。Bing Chatは、ユーザーの履歴や位置情報などに基づいて結果をフィルタリングするため、パーソナライズされたショッピング体験にも使用できます。
主な機能
包括的なウェブ検索:** Bingは、ウェブクローラーのような自動化されたボットを使用して、何十億ものウェブページを閲覧し、メタデータ、ページ構造、メディアを抽出します。クローリング後、データはBingの検索インデックスとランキングに流れ、ユーザーにとって最も関連性の高いウェブページをショートリスト化する。
Microsoft Eco Systemとの統合:** Bing Searchは、MS Word、Powerpoint、Microsoft Teams、Onedriveなど、多くのMicrosoft製品と統合されている。ユーザーは、Bing AIを使用して、「気候変動への取り組みに関する5つのポイントを含むスライドを作成する」といったプロンプトを使用して、PowerPointプレゼンテーションの下書きをすることができます。Outlookでは、電子メールの下書きやスケジューリングに使用できる。
ビジュアル検索と動画プレビューをサポート:** Bingはマルチモーダル検索もサポートしています。例えば、ユーザーは雑誌から靴の画像をアップロードし、プロンプトに "どこでオンラインでこの靴を見つけることができますか?"と尋ねることができます。ビング・チャットはまた、応答を生成する間にインタラクティブなビデオ・プレビューを提供し、ユーザーはアイコンの上にカーソルを置くと、実際のリンクに行かなくてもチラッと見ることができる。
パーソナライズされた検索結果: Bing検索は、最寄りのレストランや地域で開催されるイベントを見つけることになると、優れたパフォーマンスを発揮します。それは顧客の地理的位置を使用し、検索に最も関連性の高い一致を見つける。ビングマップもビング検索と一緒に利用でき、より簡単に視覚化できます。
これらとは別に、ビング・サーチにはマイクロソフトのリワード・プログラムがあり、ユーザーは検索でポイントを獲得し、後で利用することができる。
現在の課題:
ビングAI検索は、ドメインに特化したクエリでは文脈理解に限界があり、オープンAIやグーグルAI検索と比較して高度な推論を行うことができない。複雑なクエリに直面すると幻覚を見ることもある。
ビング検索は主にビング検索のインデックスに依存しているため、新しいウェブページや更新されたウェブページのインデックスに遅延がある場合、結果が正確でない可能性がある。
アップルやグーグルのエコシステムのような他の製品との統合は限られている。
4.複雑さ
Perplexity AIは、ユーザーのクエリに対して、出典の引用とともに文脈に関連した回答を提供する検索エンジンである。このプラットフォームは、Open AIのGPT、Claude、Mistral、独自のカスタムモデルなど、様々なLLMと統合されている。Perplexityは、出典とともに検証可能な回答を提供することに重点を置いているため、研究者に広く利用されている。多様なLLMのセットを使用し、それらの応答を集約することで、幅広いクエリに対応している。
主な機能
ソースの引用を提供:** Perplexityは、回答の透明性に重点を置いているため、競合他社とは一線を画している。ユーザーのクエリに対して、引用/ソースへのリンクとともに、直接的で簡潔な回答を提供します。
動的な LLM モデルの選択:*** Perplexity は様々な LLM と統合されているため、必要とされる複雑さ、ドメイン、深さに基づいて、与えられたクエリに最も適切なモデルを選択します。例えば、安全性を重視する会話にはClaudeモデルを、曖昧で複雑なクエリにはGPT-4を活用することができます。
フリーミアムモデル:*** このプラットフォームには、学生や研究者が利用できる無料版と、企業が大規模に利用できる有料版がある。
また、リアルタイムのウェブ統合が可能で、最新の更新された回答を提供することができる。
現在の課題:
バックエンドの複数のモデルにクエリーを行い、最終的なレスポンスを集約するため、使用量が多いときはレスポンスが比較的遅れることがある。
パーソナライズされた検索機能は、無料層のユーザーには制限されている。
サードパーティのLLMやAPIを使用しているため、ユーザーデータが保存される可能性があり、データプライバシーに関する懸念がある。
5.アークサーチ
Arc SearchはAIを搭載したモバイル・ブラウザで、ユーザーのデータ・プライバシーを優先しつつ、迅速なレスポンスを生成する。IoSとAndroidデバイスの両方で利用でき、ユーザーに柔軟性を提供する。コンサルタント、マーケティングチーム、リサーチャーが市場動向やソーシャルメディアパターンなどを素早く調査するために使用できる。
主な機能
ブラウズ・フォー・ミー」機能:I**Tは、ユーザーのクエリを入力し、関連情報を検索し、カスタマイズされたウェブページを作成するブラウズ・フォー・ミー機能を備えています。ユーザーは、複数のリンクやサイトを経由するのではなく、作成されたカスタマイズされたウェブページを読むだけでよい。
データ・プライバシー:** Arc Searchは、ユーザーのデータ・プライバシーを重視しており、GoogleやBingのような検索エンジンと比較して、データ・トラッカーが非常に限られています。
ユーザー中心のインターフェイス:** Arc Searchは、シンプルでユーザーフレンドリーなインターフェイスで設計されており、ユーザーは「リーダーモード」に変更することで、すっきりとした読書体験を得ることができます。また、ユーザーのためにカスタマイズ可能なウィジェットをサポートしています。
広告ブロック:**広告やポップアップをブロックする機能が組み込まれており、ユーザーは気が散ることなく集中することができます。
現在の課題:
Arch の検索はスピードとシンプルさのために最適化されていますが、複雑なクエリに直面した場合、レスポンスに十分な情報が得られないことがあります。
リアルタイムのデータ検索はインターネット接続に依存しているため、オフラインでは機能しない。
企業で大規模に使用するための機能が不足しており、特定のニッチな分野に限定されている。
RAGでカスタムAI検索を構築する
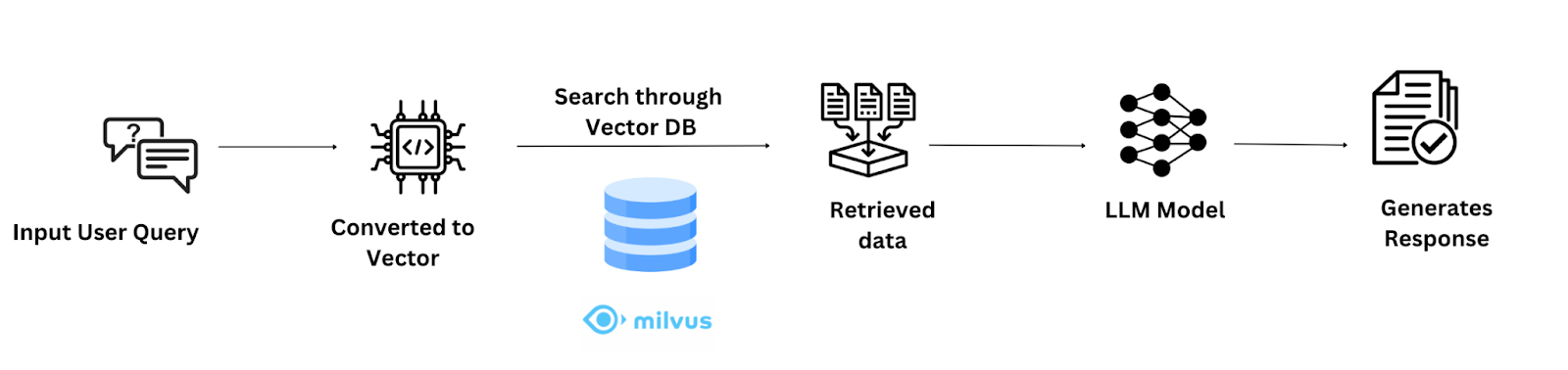
RAG(Retrieval-Augmented Generation)とは、LLMモデルを検索技術と組み合わせて、ユーザーのクエリに対してコンテキストに関連した応答を生成する手法である。
RAGベースのアーキテクチャには2つの主要コンポーネントがある:
1.レトリーバー・コンポーネント:このコンポーネントは、ユーザーからのクエリに対して、データベースから関連情報を取得する。これを構築するために、まずデータセットを収集し、API/埋め込みモデルを使用してベクトル埋め込みに変換します。これらのベクトル・データ・ポイントは、Milvusのようなベクトル・データベースに格納することができる。次に、ユーザークエリもベクトルに変換し、類似検索を使って最も近いベクトル点を見つけることができる。
- 生成コンポーネント:レトリーバーから抽出されたデータは、GPTやMistralのような大規模言語モデルに渡すことができる。LLMは、抽出されたデータから単純に要約された応答を生成するよう促される。
RAGシステムは、検索の関連性、応答時間などのメトリクスを通して継続的に評価される必要がある。独自のRAGの構築](https://zilliz.com/blog/build-rag-app-with-milvus-qwen-and-vllm)に興味がある方は、私たちのブログをご覧ください。
まとめ
AI検索エンジンは、私たちの検索、買い物、リサーチの方法を一変させた。上記のブログで取り上げた5つのAI検索エンジンはすべて、クエリに対して素早くパーソナライズされた回答を生成し、ユーザーの時間と労力を大幅に節約することができる。企業や個人は、クエリの複雑さ、プライバシーの必要性、その他の要因に基づいてAI検索を選択することができる。
オープンAIは、曖昧で複雑なクエリや、企業における大規模な使用に最適である。
Google AIは、リアルタイム検索やマルチ・モデル・クエリ(画像や動画を検索する)に適している。
ビング検索は、AIと従来の検索の両方のバランスを取りながら、最適なローカライズされた検索結果を提供できる。
Perplexityは、透明性が重要な研究目的のための最適なソリューションです。
Arc Searchは、スピードとプライバシーを重視する個人のコンテンツ制作者や学生に最適です。
また、データセットのLLMを微調整することで、ドメイン固有のクエリ用にRAGベースのAI検索エンジンを開発することもできます。
比較表
| カテゴリ|OpenAI Search|Google AI Search|Bing Search|Perplexity AI|Arc Search* |
| 特徴|サマリー、API|リアルタイム、マルチメディア|会話型AI|引用、軽量|ビジュアル、プライバシー・ファースト|特徴|サマリー、API|リアルタイム、マルチメディア|会話型AI|引用、軽量|ビジュアル、プライバシー・ファースト | 限界 | リアルタイムのデータは限定的 | 文脈的な深さに欠ける | インデックスが小さい | ニッチ、小規模 | インデックスが限定的 | | ベスト・ユースケース | ベストユースケース|カスタムAIアプリ、リサーチ|一般、リアルタイム|MSエコシステム、ショッピング|ファクトチェック|クリエイティブ、プライベートユース | スケーラビリティ*|エンタープライズユース|グローバルインフラ|エンタープライズユース|中小規模|限定的
読み続けて

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.