




ラガを使ったRAG評価
*この記事はクリスティ・バーグマン、シャフル・エス、ジティン・ジェームズが執筆しています。
検索はGenerative AIシステムの重要な構成要素であり、その課題はRetrieval Augmented Generation (RAG) において特に顕著である。Retrieval Augmented Generationは、大規模言語モデル(LLMが訓練された膨大なデータに基づいて応答を生成することで、AI搭載チャットボットを強化する。RAGシステムが洗練されているにもかかわらず、WikiEvalのようなベンチマークの低いスコアによって強調されるように、検索精度は重要なハードルのままである。これらの課題を克服するためには、包括的な評価フレームワークを確立し、RAGパラメータを微調整し、最適なパフォーマンスを達成するために徹底的な実験に取り組むことが不可欠である。
しかし、RAG実験を行う前に、どの実験が最良の結果であったかを評価する方法が必要です!。
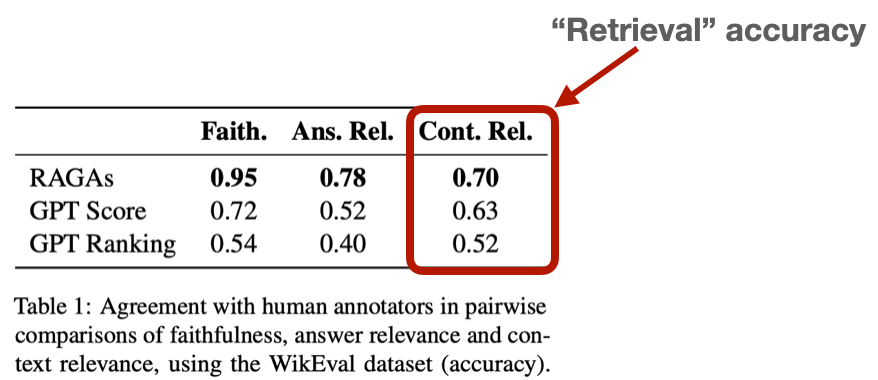
画像出典:https://arxiv.org/abs/2309.15217
ラガとは?
Ragasは、Retrieval Augmented Generation (RAG)システムのパフォーマンスを評価するために設計された特別な評価フレームワークです。高度な大規模言語モデル(LLM)をジャッジとして活用することで、RAG実装の有効性を評価するための構造化されたアプローチを提供します。Ragasは評価プロセスの自動化に重点を置き、AIが生成した応答を評価するためのスケーラブルで費用対効果の高いソリューションを提供します。このフレームワークは、バイアスに対処し、自然言語出力に対して連続的で説明可能なスコアを提供することを目的としています。Ragasは、直感的なメトリクスを提供し、検索品質の評価プロセスを合理化することで、複雑なRAGシステムの評価を簡素化します。
RAGシステム評価の重要性
RAGシステムを効果的に評価することは、AI対応を洗練させるために不可欠です。強固な評価フレームワークは、実験が信頼できる結果を生み出し、AIが正確で文脈に適した回答を提供することを保証します。評価プロセスを自動化することで、この作業を合理化・迅速化し、費用対効果と拡張性を高めることができます。
審査員としてのLLMの活用
評価](https://arxiv.org/pdf/2306.05685)のためにGPT-4のような大規模言語モデル(LLM)を使用することは、関連性や精度を含む検索品質の様々な側面を評価する能力により、支持を得ている。あるLLMが別のLLMを評価するのは異例に思えるかもしれないが、調査によると、GPT-4は人間の評価とほぼ80%の確率で一致しており、これは人間の一致の「ベイズ限界」と一致している。この方法は、評価プロセスを自動化し、スケーラビリティを提供し、手作業によるラベリングと比較してコストを削減します。
LLMに基づく評価へのアプローチ
LLMをRAG評価の判定に使用するには、主に2つのアプローチがある:
1.MT-Benchは人間のグランドトゥルースとして検証された質問と答えのペアのみを判定するためにLLMを使用します。LLMが異なるデコーダー(生成AIコンポーネント)を評価するために80のQ-Aペアを使用する前に、人間が最初に質問と回答を吟味し、質問が十分に複雑で、テストに値することを確認する。ペーパー、コード、リーダーボード。
2.Ragasは、LLMを直接ジャッジとして使うことのバイアスを克服し、説明可能で直感的に理解できる連続スコアを提供するパラダイムを形成することによって、LLMが自然言語出力を効果的に評価できるという考えに基づいて構築されています)。Paper, Code, Docs.
このブログの残りの部分では、RAG評価の自動化とスケーラビリティを重視したRagasを紹介する。
Ragas に必要な評価データ
Ragasのドキュメント](https://docs.ragas.io/en/stable/howtos/applications/data_preparation.html)によると、RAGパイプラインの評価には4つの重要なデータが必要です。
1.質問:質問。
2.コンテキスト:質問の意味に最も合致するデータからのテキストチャンク。
3.回答:質問に対するRAGチャットボットからの生成された回答。
4.グランドトゥルースアンサー:質問に対する予想される答え。
ラガ評価指標](https://assets.zilliz.com/RAG_Evaluation_Metrics_8f5973cd74.png)
主な評価指標
各評価指標については、その基礎となる公式を含め、ドキュメントに説明があります。例えば、忠実度。RagasはRAGシステムの有効性を評価するために、様々な評価スコアを提供しています:
忠実度**:このスコアは、生成された回答が提供されたコンテキストの情報をどれだけ正確に反映しているかを評価します。このスコアは、生成された回答が、それが導き出されたコンテキストと一致していることを保証し、回答の事実上の正確さを測定します。スコアの範囲は 0 から 1 で、値が高いほど正確性と一貫性が高いことを示します。
解答の関連性:回答の関連性:この回答の関連性の評価基準は、生成された回答がプロンプトにどの程度対応しているかを評価します。回答の完全性と関連性に重点を置き、不完全な回答や冗長な回答にはペナルティを課します。関連性のスコアは質問、文脈、回答から導き出され、スコアが高いほどプロンプトとの整合性が高いことを示します。
文脈想起**:コンテキスト・リコールは検索されたコンテキストがどの程度効果的に真実の回答と一致するかを測定します。これは、予想されたものと比較して、検索に成功した関連する部分の割合を計算します。スコアの範囲は 0 から 1 で、値が高いほど関連するコンテキストの大部分が検索されたことを示す。
コンテキスト精度**:このメトリクスは、最も関連性の高いコンテキスト項目が、関連性の低い項目よりも上位にランク付けされているかどうかを評価する。すべての適切なコンテキスト・チャンクがリストの上位に表示されるかどうかをチェックする。コンテキスト精度は、質問、グランドトゥルース、およびコンテキストを使用して決定され、スコアが高いほど関連する情報の順位付けが優れていることを示します。
コンテキスト関連性**:このコンテキスト関連性スコアは、検索されたコンテキストが質問にどの程度関連しているかを評価します。コンテキストがクエリの意図と一致する度合いを測定します。メトリックの範囲は0から1で、値が高いほどコンテキストが質問に適切であることを示します。
Context Entity Recall:このメトリクスは、検索されたコンテキストが、グランドトゥルースで言及されたエンティティをどの程度キャプチャしているかを計算する。これは、Ground Truthのエンティティの総数に対する、コンテキストとGround Truthの両方で見つかったエンティティの割合を測定する。スコアが高いほど、コンテキスト内の重要なエンティティをよりよく捕捉していることを示す。
これらのメトリクスの計算方法の詳細は、彼らの論文を参照。
RAG 評価コードの例
この評価コードは、既にRAGのデモを持っていることを前提としています。私のデモでは、Milvus Technical documentationとMilvusの検索用ベクトルデータベースを使用してRAGチャットボットを作成しました。私のデモの全コード RAG notebook と Eval notebooks はGitHubにあります。
このRAGデモを使って、私は質問をし、MilvusからRAGコンテキストを取得し、LLMからボットの応答を生成しました(以下の最後の2つの列を参照)。さらに、同じ質問に対する "ground truth "回答も提供している(以下の "context "列)。
OpenAI、(HuggingFace)データセット、ragas、langchain、pandasをインストールする必要があります。
# pip install openai dataset ragas langchain pandas
import pandas as pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
表示(eval_df.head())

pandasのデータフレームをHuggingFaceデータセットに変換します。
from datasets import Dataset
def assemble_ragas_dataset(input_df):
question_list, truth_list, context_list = [], [], [].
question_list = input_df.Question.to_list()
truth_list = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[コンテキスト] for コンテキスト in コンテキスト_リスト].
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# グラウンドトゥルースリストからHuggingFaceデータセットを作成する。
ragas_ds = Dataset.from_dict({"question": question_list、
"contexts": context_list、
"answer": rag_answer_list、
"ground_truth": truth_list
})
return ragas_ds
# pandas dfからRagas HuggingFace Datasetを作成する。
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Ragasが使用するデフォルトのLLMモデルはOpenAIのgpt-3.5-turbo-16kで、デフォルトの埋め込みモデルはtext-embedding-ada-002です。両方のモデル](https://docs.ragas.io/en/stable/howtos/customisations/bring-your-own-llm-or-embs.html)を好きなものに変更することができます。
LLM-as-judge](https://zilliz.com/blog/technique-and-challenges-in-evaluating-your-genai-app-using-llm-as-a-judge)のモデルは、OpenAIの最新ブログで、これが一番安いと発表されているので、ピン止めのgpt-3.5-turboに変更しておきます。また、埋め込みモデル も、text-embedding-3-small に変更しました。ブログによると、これらの新しい 埋め込み は、圧縮モード をサポートしているとのことです。
以下のコードでは、RAG contextの評価メトリクスのみを使用して、関連文書の検索品質の測定に焦点を当てています。
import os, openai, pprint
from openai import OpenAI
# env変数にapiキーを保存する。
openai_api_key=os.environ['OPENAI_API_KEY'].
# 見たいメトリクスを選択する。
from ragas.metrics import ( context_recall, context_precision, faithfulness, ) 以下のようにします。
metrics = ['context_recall', 'context_precision', 'faithfulness'] メトリクスを選択します。
# llm-as-criticを変更する。
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# エンベッディングも変更します。
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# 各メトリックに使われるデフォルトモデルを変更します。
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# データセットを評価する。
from ragas import evaluate
ragas_result = evaluate( ragas_input_ds、
metrics=[ context_precision, context_recall, faithfulness, ]、
llm=ragas_llm、
)
# 評価を見る
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

私のデモRAG notebookとEval notebooksの全コードはGitHubで見ることができる。
結論
このブログでは、自然言語AIシステムを進歩させるための検索拡張生成([RAG])技術](https://zilliz.com/learn/guide-to-chunking-strategies-for-rag)に特に重点を置きながら、生成AIにおける検索の現在進行形の課題について探った。効果的な実験は、特定のデータやユースケースに合わせてRAGパラメータを最適化し、最高のパフォーマンスを保証するために不可欠である。RAGシステムの評価は、LLMを評価者として使用する自動化によって大幅に強化できるようになりました。我々は、主要なRAG評価指標とその計算方法を取り上げ、その実用的なアプリケーションへの洞察を提供した。さらに、RagasパッケージとともにMilvusベクトルデータベースを使用した実装例を紹介し、これらのツールがRAG評価フレームワークの改善とscale your RAGにいかに効果的に利用できるかを実証した。このアプローチは、評価プロセスを合理化するだけでなく、AI主導のソリューションにおけるコンテキスト検索の全体的な有効性を高める。さらなる探求のために、RAGシステムの評価とRAGパイプラインの洗練についての理解を深めるために、実世界のアプリケーションを調査し、課題に取り組み、将来の方向性を探求し、ベストプラクティスを遵守し、追加のリソースにアクセスすることを検討してください。
 Christy Bergman
Christy BergmanChristy Bergman is a passionate Developer Advocate at Zilliz. She previously worked in distributed computing at Anyscale and as a Specialist AI/ML Solutions Architect at AWS. Christy studied applied math, is a self-taught coder, and has published papers, including one with ACM Recsys. She enjoys hiking and bird watching.
読み続けて

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.