




VidTok: コンパクトなトークン化で動画処理を再考する
にぎやかな通りの動画を見ることを考えてみてください。建物、木々、道路は各フレームでほとんど同じままで、動くのは人や車両だけです。従来の動画処理手法は各フレームを独立した画像として分析するため、あるフレームから次のフレームへと自然に流れる情報を活用できず、多くの反復的な情報を処理することになります。この冗長性により動画処理は非効率になり、必要以上のストレージ、メモリ、計算量を必要とします。
これに対処するため、論文VidTok: A Versatile and Open-Source Video Tokenizerで紹介されたVidTokは、動画圧縮と表現のための新しいアプローチを提示しています。各フレームを個別に処理する代わりに、VidTokは生の動画を、視覚的な詳細と動きの両方を捉えるコンパクトなトークンへと変換します。これにより、動画の本質的な構造を保持しながら冗長性を減らし、動画生成、編集、検索といったタスクをより効率的にします。
この記事では、従来の動画処理の限界と、VidTokがどのようにより効率的な代替手段を提供するのかを見ていきます。そのアーキテクチャを分解し、空間的および時間的特徴抽出へのアプローチを説明し、動画データをどのように量子化するのかを探ります。
従来の動画処理の限界
多くの動画シナリオ、特に静的な背景や変化が少ない場合では、連続するフレーム間の内容は似たままです。この冗長性を活用する代わりに、従来の手法は各フレームを孤立した画像として扱います。このアプローチは動画データの連続性を考慮しておらず、性能とリソース使用の両方に影響する非効率を引き起こします。
主な問題には以下が含まれます。
過剰な計算負荷: 類似した情報がフレーム間で繰り返し処理され、冗長な計算につながります。これにより処理時間とエネルギー消費が増加し、高解像度動画やリアルタイムアプリケーションでは重大な問題になります。
高いストレージおよびメモリのオーバーヘッド: 各フレームを一意の単位として保存すると、冗長データが蓄積されます。動画全体の時間にわたって、ほぼ同一の背景情報を繰り返し保存することでデータ量が大幅に増加し、ストレージシステムやメモリリソースに負担をかけます。
時間的一貫性の喪失: フレーム間の連続性は、動きを正確に捉えるために必要です。各フレームを孤立させると、連続性を示す微妙な変化をシステムが見逃す可能性があり、動的なシーンにおける詳細の損失や動画再構成時のアーティファクトにつながることがあります。
非効率なデータ利用: 動画の静的な部分を繰り返し処理することは、計算リソースが実際の変化に集中していないことを意味します。その結果、シーンの動的性質を定義する要素ではなく、冗長な情報に処理能力が浪費されます。
これらの課題は、空間的な詳細と動きの流れの両方を保持しながら、動画データをコンパクトで意味のある表現へと圧縮する手法の必要性を強調しています。VidTokは、生の動画データを効率的なトークン化形式へと変換し、冗長性を最小限に抑えながら意味のある変化を対象とすることで、これらの問題に対処します。
VidTokが生の動画データを変換する方法
VidTokは、エンコーディング、正則化、量子化、デコーディングという一連のステップを通じて、高次元の動画をコンパクトな表現へと変換します。
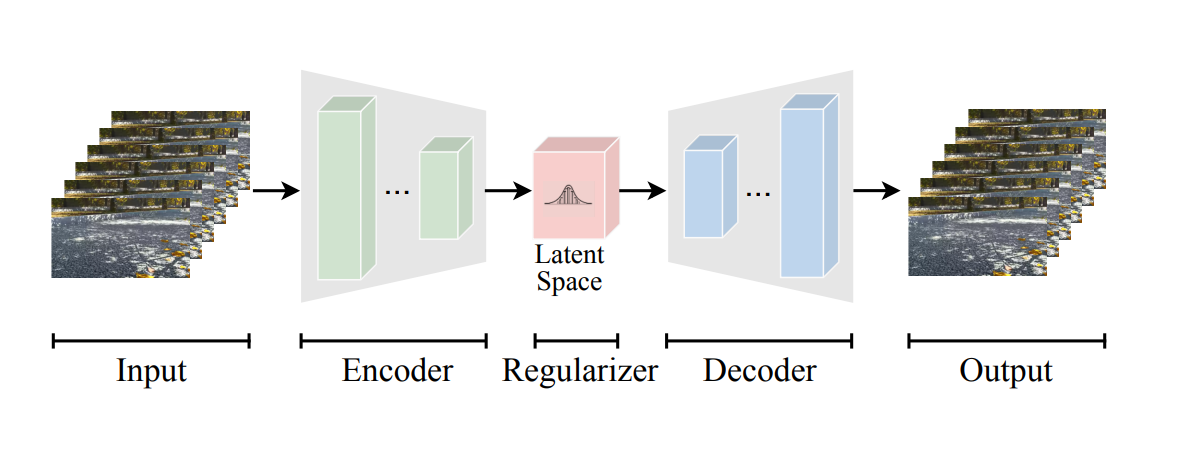
図1. VidTokパイプラインの概要
プロセスは、各フレームから重要な空間特徴を抽出するために畳み込み層を使用するニューラルネットワークであるエンコーダーから始まります。このネットワークは、エッジ、テクスチャ、形状といった重要な詳細を識別します。連続するフレーム間の類似性を活用することで、エンコーダーは静的な情報を繰り返し処理するのではなく、動きを捉える変化に焦点を当てます。
エンコード後、正則化ステップによって、抽出された特徴が構造化された潜在空間(類似した入力が類似したエンコード済み特徴を持つ、データの圧縮された抽象表現)に整理されます。これにより、類似したフレームが類似した表現を生成することが保証され、後の一貫した再構築にとって不可欠です。
正則化に続いて、VidTokは潜在特徴にFinite Scalar Quantization(FSQ)を適用し、離散表現を作成します。FSQは表現の各要素を固定された値の集合のいずれかにマッピングし、従来のベクトル量子化で見られるコードブック崩壊のような問題を回避します。ただし、VidTokは離散トークン化に限定されているわけではなく、動画を固定された離散値ではなく滑らかな潜在空間へマッピングする連続トークン化にも対応しています。連続トークン化は動画生成や拡散ベースのモデルなどのタスクに有用である一方、離散トークン化は圧縮や検索タスクにおいてより効率的です。VidTokは、離散トークンにはFSQを、連続トークンにはKL正則化を使用することで、両方のアプローチのバランスを取り、1種類のみに特化したモデルよりも柔軟性を高めています。
デコーダーは必要に応じて動画を再構築し、トークン化された表現を再構成して、空間的な詳細と時間的な動きのダイナミクスの両方を保持します。動画データをこのトークン化形式に圧縮することで、VidTokは重要な情報を保持しながら冗長性を削減し、動画編集、生成、検索をより効率的にします。VidTokが動画データをどのようにエンコードし量子化するかを見てきたので、次にそのアーキテクチャ構成要素をさらに詳しく見ていきましょう。
VidTokアーキテクチャの内部
VidTokは、生の動画データを、空間的な詳細と動きの情報の両方を捉えるコンパクトなトークン集合に変換するよう設計されています。このアーキテクチャは、冗長性を削減し重要なコンテンツを保持するために連携して機能する、複数の相互接続されたモジュールで構成されています。
2D畳み込みによる空間特徴抽出
プロセスは、個々の動画フレームに2D畳み込み層を適用するエンコーダーから始まります。これらの層は、各画像からエッジ、テクスチャ、形状などの重要な空間特徴を抽出します。たとえば都市の道路シーンでは、ネットワークは静的な背景要素の反復処理を最小限に抑えながら、建物の輪郭、道路標示、標識を検出することを学習します。
3D畳み込みによる時間特徴抽出
動きを捉えるために、VidTokは複数のフレームを同時に処理する3D畳み込み層を採用しています。空間次元と時間次元の両方を考慮することで、これらの層は時間の経過に伴う動きのパターンや遷移を識別します。混雑した交差点のようなシナリオでは、3D畳み込みは大部分が静的な周囲環境を無視しながら、移動する車両や歩行者などの動的な側面に焦点を当てます。
分離された空間および時間サンプリング
VidTokにおける重要な設計上の判断は、空間情報と時間情報を別々に扱うことです。空間サンプリングは、各フレームから詳細を効率的に抽出する専用の2D演算を使用して実行される一方、時間サンプリングは時間経過に伴う変化を追跡するために独立して管理されます。この分離により、ネットワークは最も必要とされる場所にリソースを割り当てることができ、静的コンテンツに対する冗長な計算を削減できます。
AlphaBlender演算子による時間的ブレンディング
フレーム間の滑らかな遷移を維持することは、動きを正確に捉えるために不可欠です。VidTokは、連続するフレームからの特徴をブレンドするためにAlphaBlender演算子を統合しています。この演算子は、次の式に従って重み付き和を計算します。
x=α⋅x1+(1−α)⋅x2
この式では、x1とx2は連続する2つの時刻からの特徴マップを表し、αはそれらの間のバランスを制御します。このブレンディングプロセスは、隣接フレームからの情報を効果的に組み合わせることで、夕日の色相の変化のような緩やかな変化を保持するうえで重要です。VidTokが空間情報と時間情報をどのように処理するかをよりよく理解するために、以下の図をご覧ください。この図は、そのアーキテクチャを示し、特徴抽出とブレンディングに関わるさまざまなコンポーネントを示しています。
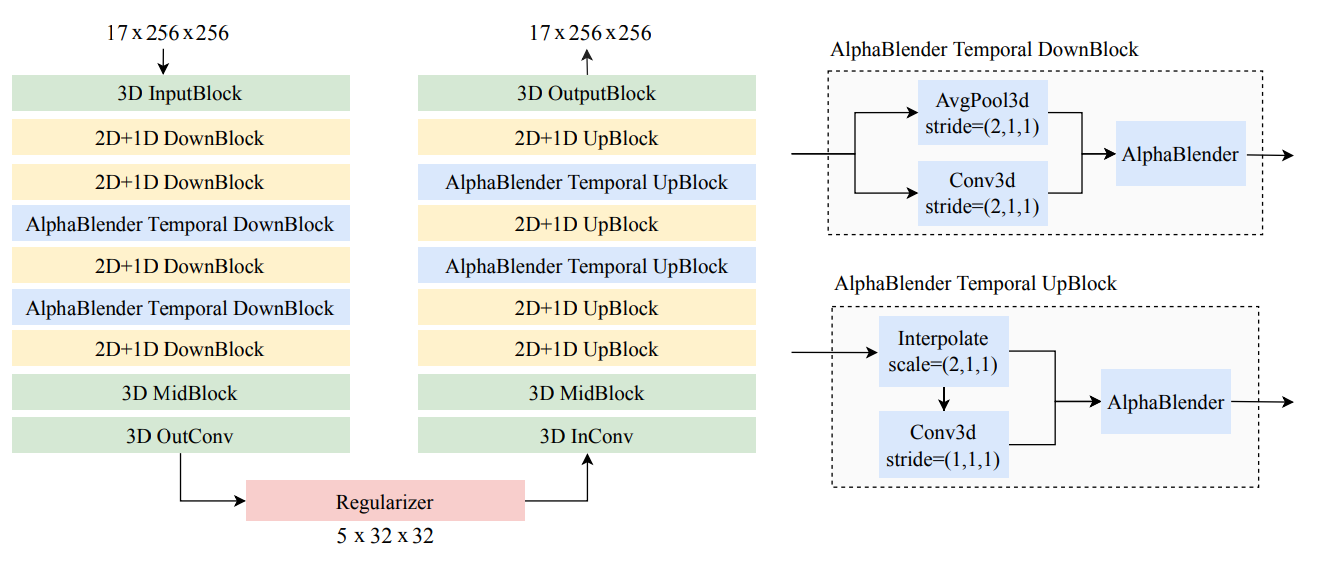
図2. 2D+1D DownBlocks、AlphaBlender Temporal DownBlocks、3D畳み込みを含む、モデルの空間処理と時間処理
VidTokは、空間-時間特徴抽出のための3D畳み込み、効率的な空間処理のための2D+1Dブロック、時間的ブレンディングのためのAlphaBlenderを組み合わせて動画入力を処理します。図の右側では、AlphaBlenderがプーリングと補間を統合して滑らかな動きの表現を維持する方法を詳述しています。この構造により、静的な詳細が保持される一方で、不要なアーティファクトを生じさせることなく時間情報を効率的に取得できます。
有限スカラー量子化(FSQ)
特徴抽出とブレンディングの後、VidTokは有限スカラー量子化(FSQ)を使用して潜在表現を圧縮します。FSQは、潜在ベクトルの各スカラー要素を、事前に定められた固定値の集合のいずれかにマッピングすることで、独立に量子化します。この独立した量子化により、従来のベクトル量子化手法で発生し得るコードブック崩壊のような問題を回避できます。その結果、ほぼすべてのトークンが意味のある情報を持つトークン集合が得られます。
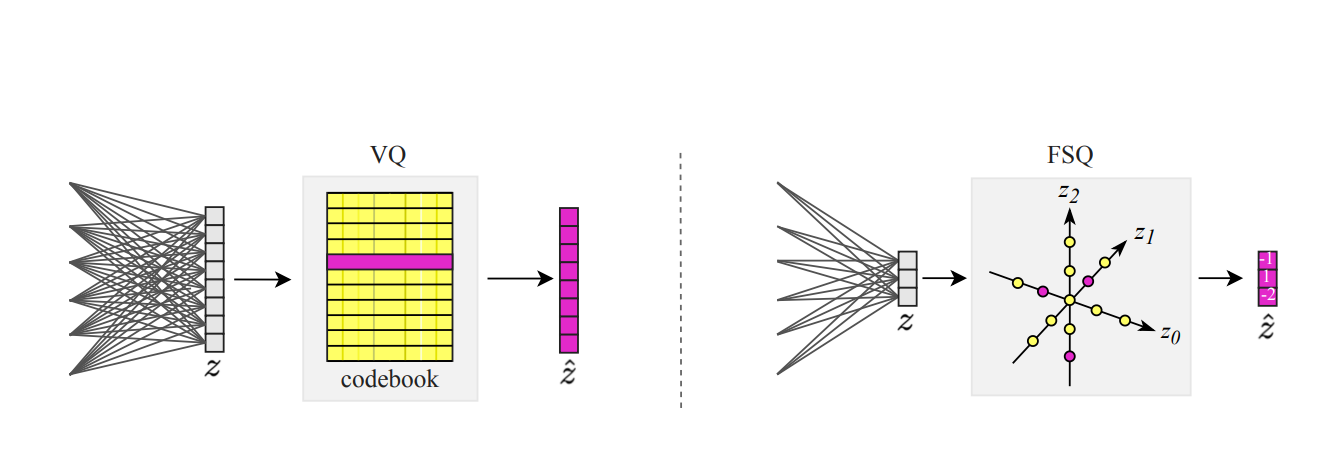
図3. 従来のベクトル量子化とFSQの視覚的比較
上の図は、VQが潜在ベクトル全体を、学習されたcodebook内の最も近いエントリに置き換える方法を示しており、これは不安定性につながる可能性があります。対照的に、FSQは各次元を事前定義された軸(z₀, z₁, z₂)に沿って独立に量子化するため、コードブックが不要になり、より効率的で安定したトークン化が保証されます。この方法により、各トークンが意味のある情報を持つ、より信頼性の高い離散表現が得られます。
デコーダーと再構成プロセス
デコーダーは、コンパクトなトークンから動画を再構成することで、エンコードプロセスを逆にたどります。トークン化された表現を再組み立てし、元の動画の空間的な詳細と時間的な流れの両方を再現します。この再構成はモザイクを組み立てることに似ており、各トークンが完全な画像に寄与します。
トレーニング戦略と正則化
VidTokは、計算効率と高品質な動画再構成のバランスを取る2段階アプローチを用いて学習されます。第1段階では、モデルは低解像度動画で学習され、過度な計算コストをかけずに構造的パターンを捉えられるようになります。これにより、ネットワークはより細かな詳細を扱う前に、一般的な動画特徴を学習できます。第2段階では、高解像度データを用いてデコーダーのみをファインチューニングし、学習効率を維持しながら再構成フレームを洗練します。さらに、学習中にフレームレートを下げることで、モデルは冗長なフレーム単位の更新を処理するのではなく、意味のある時間的変化に集中できるようになります。これにより、動画ダイナミクスにおいて実際に重要な変化を優先することで、動きの表現が向上します。
構造化された潜在空間を維持するために、VidTokは安定性を向上させ過学習を防ぐ正則化手法を適用します。連続トークンに使用される主要な方法の1つがKLダイバージェンスであり、学習された分布が期待される分布からどれだけ逸脱しているかを測定します。KLダイバージェンスを最小化することで、モデルは潜在表現が滑らかに保たれ、過度に集中した値へと崩壊しないようにします。そうした崩壊が起きると、学習される特徴の多様性が制限される可能性があります。
離散トークンについては、利用可能な量子化レベルをより均一かつ多様に使用することを促すために、エントロピーペナルティが適用されます。これらのペナルティがない場合、モデルはごく一部のトークンだけを過剰に使用し、非効率な圧縮や情報損失につながる可能性があります。エントロピー正則化を適用することで、VidTokはトークン空間全体が効果的に活用されるようにし、動画表現の品質を向上させます。これらの手法を組み合わせることで、VidTokは動画トークン化を最適化し、空間情報と時間情報を保持しながら、効率的な動画生成、編集、検索を可能にします。
それでは次に、これらのアーキテクチャ上の選択が、主要なベンチマークや実用的なアプリケーションにおける性能向上にどのようにつながるかを見ていきましょう。
VidTokのベンチマーク性能
学習戦略を改良し、Finite Scalar Quantizationを適用した後、VidTokは動画再構成ベンチマークで高い性能を示しています。評価では、各動画データセットが持つシーンの複雑さや動きのダイナミクスといった課題の中で、空間的な詳細をどれだけ保持し、さまざまな動画データセットにわたって動きをどれだけ捉えられるかを測定します。
VidTokは、MCL-JCVやWebVid-Valなどのデータセットでテストされました。MCL-JCVデータセットは、さまざまな動きのパターンや詳細レベルを持つ動画で構成されている一方、WebVid-Valには実世界のシナリオから得られた自然な動画が含まれています。これらの条件下で、VidTokは29.82 dBのPeak Signal-to-Noise Ratio(PSNR)を達成し、再構成された動画が最小限の歪みで元のコンテンツに非常に近いことを示しました。また、Structural Similarity Index(SSIM)は0.867に達し、フレーム間の空間構造、テクスチャ、コントラストを維持する能力を反映しています。SSIMが高いほど、再構成された動画は元の動画により近く見えます。
Learned Perceptual Image Patch Similarity(LPIPS)指標を用いたさらなる評価では、スコアが0.106となり、元動画と再構成動画の視覚的差異が低く抑えられていることが示されました。VidTokはまた、フレーム間の時間的一貫性と動きがどれだけ保持されているかを測る指標であるFréchet Video Distance(FVD)で160.1を記録しました。
これらの結果は、VidTokが圧縮効率と再構成品質のバランスを取る能力を示しています。トークン化された表現は冗長性を削減しながら重要な情報を保持するため、動画生成、編集、検索のアプリケーションに有用です。これらの結果はVidTokの効率性を示していますが、さらなる改善が可能な領域もまだ存在します。
VidTokと動画トークン化の今後の方向性
VidTokは、動画表現に対する効率的なアプローチを提供し、検索、保存、生成を改善します。現在のモデルは高い成果を達成していますが、その能力をさらに高めるために探求できる領域がいくつかあります。
モーション表現の改善
VidTokは3D畳み込みとAlphaBlenderオペレーターを使用して時間的ダイナミクスを捉えますが、動画における長距離依存関係の処理は依然として課題です。今後の研究では、フレーム間の長距離依存関係を明示的に追跡するTransformerベースの動画アーキテクチャを探求できるでしょう。これらの改善により、特に高速で移動する物体、オクルージョン、または急速な遷移を含むシーンにおいて、モーションの連続性が向上します。
高解像度およびマルチスケールエンコーディング
高解像度動画を効率的に処理することは、依然として未解決の課題です。動画の異なる部分を異なる詳細レベルで圧縮するマルチスケールエンコーディング技術により、計算コストを大幅に増加させることなく、細かなテクスチャをより適切に保持できる可能性があります。これは、メディア制作や医用画像処理など、高品質な動画再構成を必要とするアプリケーションに特に有用です。
より優れた圧縮のための適応量子化
Finite Scalar Quantization (FSQ)はトークン化における安定性を提供しますが、適応量子化によって効率をさらに向上できる可能性があります。シーンの複雑さに基づいてビット割り当てを動的に調整することで、システムは複雑なテクスチャや大きな動きがある領域により多くの詳細を割り当て、静的な領域では冗長性を削減できます。これにより、動画品質を維持しながらストレージを最適化できます。
動画理解のためのクロスモーダル学習
VidTokのトークン化された表現は、テキストや音声などの他のモダリティと組み合わせることで、動画理解を強化できます。今後の研究では、動画トークンをテキスト記述や音響特徴と並べてマッピングする共同埋め込みを探求できるでしょう。これにより、自動キャプション生成、マルチモーダル検索、動画ベースの質問応答などのタスクが改善され、VidTokの潜在的な応用範囲が検索や圧縮を超えて広がります。
これらの領域に注力することで、VidTokは動画処理のためのより強力なツールへと進化し続け、さまざまな業界における保存、検索、分析の効率を向上させることができます。
結論
VidTokは、冗長性を削減し、空間的および時間的な詳細の両方を保持することで、動画処理を改善します。各フレームを孤立した画像として扱うのではなく、動画データをコンパクトなトークンに変換し、保存、圧縮、再構成をより効率的にします。畳み込みエンコーダー、Finite Scalar Quantization (FSQ)、および時間的ブレンディングを適用することで、不要な処理を最小限に抑えながら、意味のある変化に焦点を当てます。
このアプローチにより、重要な詳細を犠牲にすることなく、動画生成、編集、検索などのタスクをより効率的にできます。今後は、モーショントラッキング、マルチスケールエンコーディング、適応量子化の改善によって、その性能をさらに洗練できる可能性があります。効率的な動画処理への需要が高まる中、VidTokは、精度と効率を維持しながら動画データを管理するための構造化されたスケーラブルな方法を提供します。
参考リソース
読み続けて

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.