




Finding the Right Fit: Embedding Creation for AI Retrieval (RAG) in Zilliz Cloud Pipelines from OSS, VoyageAI, and OpenAI
This post is written by Christy Bergman and Jiang Chen.
Welcome to our blog post on embedding models tailored to AI Retrieval Augmented Generation (RAG) applications. Here’s what we’ll cover:
Introduction to how embedding models are used in RAG (Generative AI with retrieval)
Introduction to SBERT, the most common type of embedding model
MTEB leaderboard of embedding models and how to use it
Six embedding models automatically included in Zilliz Cloud Pipelines
Explanation of each model and tips on selecting the best embedding model for your needs
Let's dive in!
Add Your Data to AI With Rag: How Embedding Models + LLMs Are Used
Retrieval Augmented Generation (RAG) has emerged as the go-to approach for question-answering bots. However, given the knowledge training cutoff date inherent in all models, they may lack awareness of recent data. Most production use cases supplement their models with specific knowledge to bridge this gap.
Are your AI answers stuck in the past? Tired of bots that only know what they were trained on?
RAG presents a solution by integrating your data into the AI's knowledge. This pattern uses embedding models and Large Language Models (LLMs). Here's how it works:
Data prep using an Embedding Model: Kickstart RAG by using an embedding model to generate vector embeddings of chunks of text from ALL your documents. This becomes YOUR vector space representing YOUR domain knowledge, with each piece of information represented as a vector.
Indexing and Search using the same Embedding Model: Computers can quickly run vector searches once your knowledge is encoded into vectors. Organizing the vectors into data structures for search algorithms is called Indexing. Indexes are used in Vector Databases like Milvus. When you ask a question, the database will use the index to find the closest vectors (representing sentences or paragraphs) in your domain knowledge vector space to your question vector. Create your question vector using the same embedding model used to embed your data.
- Answer generation with an LLM Model: This is the “Generative AI” part. In this step, a LLM model, such as ChatGPT, leverages your relevant domain knowledge to answer the question. RAG data is fed to the LLM model by injecting the top-K retrieved texts into the prompt, which includes your question, context (Top-K texts), and instructions such as “Answer the question using just the knowledge in the context of this prompt”.
With RAG, the LLM generates an answer based on your given domain knowledge, instantly accessing the latest data and understanding your questions better.
This RAG pattern is supported by research; see the paper Lost in the Middle. The paper shows that the Recall accuracy of answers generated by LLMs decreases with the number of retrieved texts stuffed into the model’s Context prompt. In addition:
LLMs have limits on the context size (right now, it’s 128K for GPT-4 Turbo).
Cost per token, so it’s more expensive to pass all the information all the time.
Sentence-BERT Embedding Models
Modern embedding models are derived from the Encoder-part of transformers; while LLM models (such as ChatGPT) are built from the Decoder-part of transformers. The most common embedding model class is SBERT (Sentence-BERT), which builds on BERT but specializes in understanding complete sentences. So, SBERT can tell the difference between "The cat sat on the mat" and "The mat sat on the cat" - something basic BERT wouldn't!
Semantics refers to the meaning behind words. This is particularly important in the context of LLMs because the same words may have different meanings based on context, order, or usage. For more information on SBERT, interested readers should see these good backgrounder articles about that model here.
Suppose you are coding RAG applications from scratch. An excellent place to start is by selecting an embedding model from the HuggingFace MTEB Leaderboard, sorted (descending) by the "Retrieval Average'' column since it is most relevant to RAG. Then, choose the smallest, highest-ranking embedding model. The leaderboard is constantly changing! But switching the embedding model with HuggingFace in Python is as simple as adjusting a single variable.
MTEB Retrieval performance is measured by Normalized Discounted Cumulative Gain at 10 (NDCG@10). This metric measures the quality of top-K lists by calculating ratio sums where higher-ranking items are given more weight than lower-ranking items as returned to a user in proportion to an ideal ranked order.
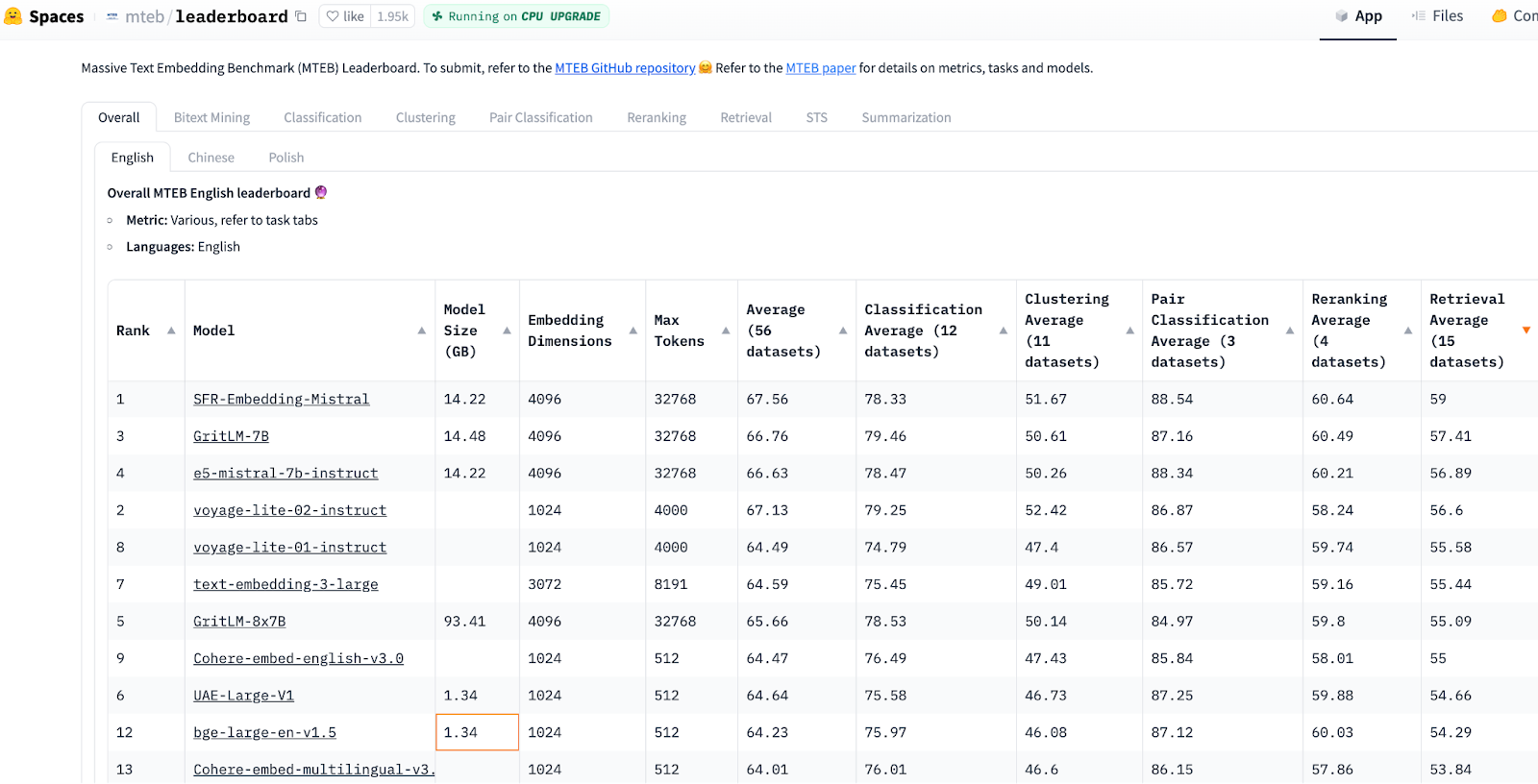
Image source: HuggingFace MTEB Leaderboard, accessed Feb 20, 2024.
Massive Text Embedding Benchmark (MTEB) evaluates embedding models across 8 tasks and 58 datasets (10 multilingual 112 languages). The eight tasks are bitext mining, classification, clustering, pair classification, reranking, retrieval, semantic textual similarity (STS), and summarization.
6 Key Embedding Models Built into Zilliz Cloud Pipelines
Zilliz Cloud Pipelines recently launched support for a rich set of embedding model choices.
| Creator | Model | Embedding Dim | Context Length | Use Case Tasks | Open Source | *MTEB Score |
| BAAI | bge-base-en-v1.5 | 768 | 512 | General EN text | Yes | 53 |
| BAAI | bge-base-zh-v1.5 | 768 | 512 | General ZH text | Yes | 69 |
| VoyageAI | voyage-2 | 1024 | 4K | High-quality RAG chatbots | No | Not available |
| VoyageAI | voyage-code-2 | 1536 | 16K | High recall rate Code completion | No | Not available |
| OpenAI | text-embedding-3-small | 512-1536 | 8K | Real-time Multilingual text chatbots | No | 62 (512) 62 (1536) |
| OpenAI | text-embedding-3-large | 256-3072 | 8K | Real-time Multilingual text chatbots | No | 65 (3072) 62 (256) |
*HuggingFace MTEB Leaderboard, sorted descending by Retrieval, accessed Feb 26, 2024.
Embedding Dim = length of vector produced by a model; larger vectors might capture more meaning but may be less storage-efficient.
Context Length = maximum number of tokens the model can process at once at a single time step. Most embedding models' output vectors are normalized, so dot-product and cosine similarity are equal.
⚠️ Note: Even though MTEB benchmarks offer valuable guidance, some models are known to be overfitted! Always conduct your own evaluations!
With Zilliz Cloud Pipelines, you can get started for free by signing up and building your RAG application without DevOps or ML infrastructure hassles.

Image source: Blog Announcing Embedding Models built into Zilliz Cloud Pipelines
BAAI/bge-base-en(or zh)-v1.5 embedding models
These open-source SBERT models are available on HuggingFace. Some advantages to these small models:
Small, open source, and CPU-friendly.
It’s a good choice for working on a laptop or/or tiny cloud resources.
Fastest for ingestion while chunking data and query latency each time a question is asked.
Cost-effective since API calls are free and GPU is not required.
Trained in both Chinese and English languages.
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | *MTEB Score |
| BAAI | bge-base-en-v1.5 | 768 | 512 | General EN text | Yes | 53 |
| BAAI | bge-base-zh-v1.5 | 768 | 512 | General ZH text | Yes | 69 |
*HuggingFace MTEB Leaderboard, sorted descending by Retrieval, accessed Feb 26, 2024.
VoyageAI’s voyage-2 and voyage-code-2 embedding models
These proprietary models are trained using contrastive learning and importance resampling on different data and fine-tuned for different tasks. Voyage-2 is trained on dialog data and fine-tuned for conversation intent. Voyage-code-2 is trained on code data and fine-tuned for code completion.
Note: Voyage-lite-02-instruct listed on the MTEB leaderboard (sorted descending by STS or “diverse corpora” category) is different and not to be confused with the production models voyage-2 and voyage-code-2 described here.
Some advantages to these models:
For technical documentation RAG chatbots, voyage-01 (deprecated) was shown to have higher retrieval quality (measured as NDCG@10). Voyage-2 is the newer version.
For code tasks, voyage-code-2 has a 14% higher recall rate for code-intensive text.
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | MTEB Score |
| VoyageAI | voyage-2 | 1024 | 4K | High-quality RAG chatbots | No | Not available |
| VoyageAI | voyage-code-2 | 1536 | 16K | High recall rate Code completion | No | Not available |
OpenAI’s text-embedding-3-small(or large) embedding models
From OpenAI, the newest embedding models rank higher on the MTEB leaderboard than their previous ada-002. These new embedding models also have higher multilingual performance (MIRACL) and lower pricing.
According to OpenAI’s blog, compression-aware training was used to create the embeddings. Traditional dimensionality-reduction techniques such as quantization save space but at a huge accuracy loss because compression is applied “post-hoc” after embeddings were learned. Compression-aware training, such as Matryoshka Representation Learning, learns embeddings at different sizes (dimensions), with some accuracy loss, though not as significant as with PCA.
Impressively, both models support smaller embeddings without sacrificing the retrieval quality much. For example, reducing the vector dimension from 3072 to 256 only reduces the MTEB score from 65% to 62%. However, that is a 12X lower memory requirement! While there is an accuracy-cost tradeoff associated with lower dimensionality, in the age of AI-powered Chatbots, fast responses are sometimes prioritized over answer accuracy.
Some advantages to these models:
Improved multilingual capabilities.
Lower-dimension vectors with the smallest inference overhead and much less accuracy loss than traditional binary- or product-quantization.
| Creator | Model | Embedding****Dim | Context Length | Use Case Tasks | Open Source | *MTEB Score |
| OpenAI | text-embedding-3-small | 512-1536 | 8K | Real-time Multilingual text chatbots | No | 62 (512) 62 (1536) |
| OpenAI | text-embedding-3-large | 256-3072 | 8K | Real-time Multilingual text chatbots | No | 65 (3072) 62 (256) |
*HuggingFace MTEB Leaderboard, sorted descending by Retrieval, accessed Feb 26, 2024.
Below is a code example to call the new embedding models. The full code is located in our bootcamp github.
# STEP 1. CONNECT TO MILVUS
# !pip install pymilvus
from pymilvus import connections, utility
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("ZILLIZ_API_KEY")
# Connect to Zilliz cloud using endpoint URI and API key TOKEN.
CLUSTER_ENDPOINT="https://in03-xxxx.api.gcp-us-west1.zillizcloud.com:443"
connections.connect(
alias='default',
uri=CLUSTER_ENDPOINT,
token=TOKEN,
)
Next, we specify the OpenAI embedding model.
# STEP 2. EMBEDDING MODEL.
import openai, pprint
from openai import OpenAI
# OpenAI embedding model name, `text-embedding-3-large` or `ext-embedding-3-small`.
EMBEDDING_MODEL = "text-embedding-3-small"
EMBEDDING_DIM = 512
Next, we create a no-schema Milvus collection and specify an index.
# STEP 3. CREATE A NO-SCHEMA MILVUS COLLECTION AND USE AUTOINDEX.
from pymilvus import MilvusClient
COLLECTION_NAME = "MilvusDocs_text_embedding_3_small"
# https://milvus.io/docs/using_milvusclient.md
mc = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN)
# Check if collection already exists, if so drop it.
has = utility.has_collection(COLLECTION_NAME)
if has:
drop_result = utility.drop_collection(COLLECTION_NAME)
print(f"Successfully dropped collection: `{COLLECTION_NAME}`")
# Create the collection.
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
Next, we read LangChain technical docs as .html files downloaded into a folder. Chunk and embed the docs. The example below uses LangChain’s built-in HTML parser as the chunking strategy. Your chunking strategy could be much simpler.
# STEP 4. PREPARE DATA: CHUNK AND EMBED
# Read docs into LangChain.
from langchain.document_loaders import DirectoryLoader
path = "../RAG/rtdocs/pymilvus.readthedocs.io/en/latest/"
loader = DirectoryLoader(path, glob='*.html')
docs = loader.load()
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter
from bs4 import BeautifulSoup
# Define the headers to split on for the HTMLHeaderTextSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
]
# Create an instance of the HTMLHeaderTextSplitter
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# Specify chunk size and overlap.
chunk_size = 511
chunk_overlap = np.round(chunk_size * 0.10, 0)
print(f"chunk_size: {chunk_size}, chunk_overlap: {chunk_overlap}")
# Create an instance of the RecursiveCharacterTextSplitter
child_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap,
length_function = len,
)
# Split the HTML text using the HTMLHeaderTextSplitter.
start_time = time.time()
html_header_splits = []
for doc in docs:
soup = BeautifulSoup(doc.page_content, 'html.parser')
splits = html_splitter.split_text(str(soup))
for split in splits:
# Add the source URL and header values to the metadata
metadata = {}
new_text = split.page_content
for header_name, metadata_header_name in headers_to_split_on:
# Handle exceptions if h1 does not exist.
try:
header_value = new_text.split("¶ ")[0].strip()[:100]
metadata[header_name] = header_value
except:
break
split.metadata = {
**metadata,
"source": doc.metadata["source"]
}
# Add the header to the text
split.page_content = split.page_content
html_header_splits.extend(splits)
# Split the documents further into smaller, recursive chunks.
chunks = child_splitter.split_documents(html_header_splits)
Insert the chunks and embeddings into Milvus.
# STEP 5. INSERT CHUNKS AND EMBEDDINGS IN ZILLIZ.
# Convert chunks to a list of dictionaries.
chunk_list = []
for chunk in chunks:
# Generate the embeddings.
response = openai_client.embeddings.create(
input=chunk.page_content,
model=EMBEDDING_MODEL,
dimensions=EMBEDDING_DIM
)
embeddings = response.data[0].embedding
# Assemble embedding vector, original text chunk, metadata.
chunk_dict = {
'vector': embeddings,
'chunk': chunk.page_content,
'source': chunk.metadata['source'],
'h1': chunk.metadata['h1'][:50],
}
chunk_list.append(chunk_dict)
# Insert data into the Milvus collection.
insert_result = mc.insert(
COLLECTION_NAME,
data=chunk_list,
progress_bar=True)
# After the final entity is inserted, call flush to stop growing segments left in memory.
mc.flush(COLLECTION_NAME)
Ask a Question of Milvus, which is now loaded with Milvus technical documentation embeddings.
# Define a sample question about your data.
SAMPLE_QUESTION = "What do the parameters for HNSW mean?"
# Embed the question using the same encoder.
response = openai_client.embeddings.create(
input=SAMPLE_QUESTION,
model=EMBEDDING_MODEL,
dimensions=EMBEDDING_DIM
)
query_embeddings = response.data[0].embedding
# Define output fields to return.
OUTPUT_FIELDS = ["h1", "h2", "source", "chunk"]
# Run semantic vector search using your query and Milvus vector database.
start_time = time.time()
results = mc.search(
COLLECTION_NAME,
data=[query_embeddings],
output_fields=OUTPUT_FIELDS,
limit=2,
consistency_level="Eventually"
)
Generate an answer using ChatGPT and the retrieved text context chunks.
LLM_NAME = "gpt-3.5-turbo"
TEMPERATURE = 0.1
RANDOM_SEED = 415
# Separate all the context together by space.
contexts_combined = ' '.join(context)
SYSTEM_PROMPT = f"""Use the Context below to answer the user's question. Be clear, factual, complete, concise.
If the answer is not in the Context, say "I don't know".
Otherwise answer with fewer than 4 sentences and cite the grounding sources.
Context: contexts_combined
Answer: The answer to the question.
Grounding sources: {context_metadata[0]['source']}
"""
# Generate response using the OpenAI API.
response = openai_client.chat.completions.create(
messages=[
{"role": "system", "content": SYSTEM_PROMPT,},
{"role": "user", "content": f"question: {SAMPLE_QUESTION}",}
],
model=LLM_NAME,
temperature=TEMPERATURE,
seed=RANDOM_SEED,
)
# Print the question and answer along with grounding sources and citations.
print(f"Question: {SAMPLE_QUESTION}")
for i, choice in enumerate(response.choices, 1):
pprint.pprint(f"Answer: {choice.message.content}")
print("\n")
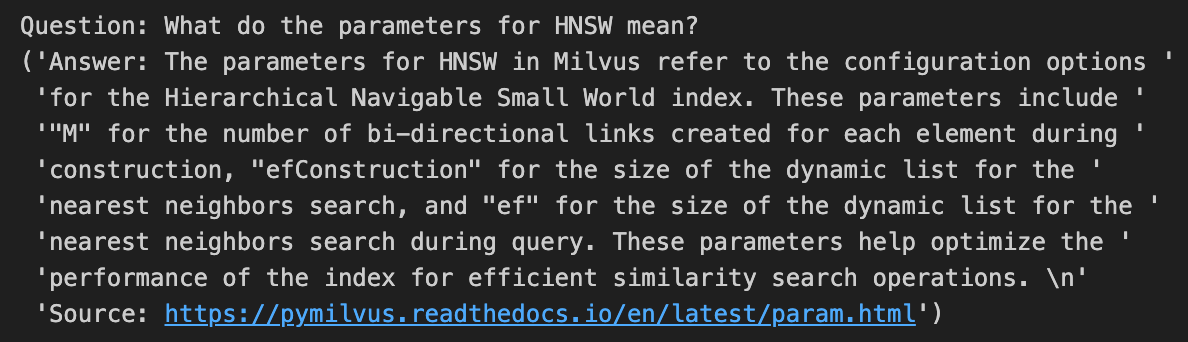
The answer using text-embedding-3-small with reduced embeddings dim=256 is perfect compared to the same answer with dim=1536, at least for this RAG example!
Conclusion
In this blog, we introduced how embedding models are used in RAG and SBERT, the most common type of embedding model. We showed the MTEB leaderboard of embedding models and explained how to use it. Then, we went through the six different embedding models automatically included in Zilliz Pipelines. Different embedding models are best for different use cases; we discussed when to choose which model. Finally, we showed code to call the new OpenAI embedding models; and the full code is located in our bootcamp github.
References
Milvus (give us a star!)
Tutorial on Encoder-Decoder parts of transformers
Tutorial on SBERT Encoder embedding models
HuggingFace MTEB Leaderboard of embedding models
HuggingFace model card for BAAI/bg-large-en-v1.5
VoyageAI embedding models
OpenAI embedding models

Keep Reading

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.