




LLMアプリのLangChainによる様々なチャンキング戦略の実験
チャンキングは、Retrieval-augmented generation (RAG)アプリケーションを構築する上で、最も困難な問題の一つである。チャンキングとは、下流処理のために、文章をより小さく、管理しやすい断片に分割するプロセスのことである。単純に聞こえるが、悪魔は細部に宿る。チャンキング戦略の選択を誤ると、無関係な結果や不完全な結果につながり、AIシステムが正確な回答を提供することが難しくなる。例えば、小さすぎるチャンクは文脈を見逃す可能性があり、大きすぎるチャンクは無関係な情報を返す可能性がある。
このチュートリアルでは、異なるチャンキング戦略が同じデータセットの検索パフォーマンスにどのような影響を与えるか、特にLangchainチャンキングを使ったユースケースに焦点を当てます。このチュートリアルの最後には、チャンクサイズとオーバーラップが検索品質にどのように影響するかを理解し、特定のユースケースに適したパラメータを選択するための実践的な洞察を得ることができるでしょう。この記事のコードはGitHub Repo on LLM Experimentationにあります。
LangChainの概要とチャンキングが重要な理由
LangChainはLarge Language Modelです。オーケストレーションフレームワークで、ドキュメントロードとテキスト分割のためのツールが組み込まれている。その柔軟性により、チャンキングが検索された情報の関連性と完全性を決定する上で重要な役割を果たすRAGアプリケーションを構築するための一般的な選択肢となっている。
チャンキングは、2つの主要なパラメータを選択することを含む:与えられたチャンク、サイズとオーバーラップ。
チャンクサイズは各チャンクに含まれる文字やトークンの数を定義する。より大きなチャンクはより多くのコンテキストを捉えますが、無関係な情報を返すリスクがあり、小さなチャンクは精度を確保しますが、必要なコンテキストを失う可能性があります。オーバーラップは、連続するチャンク間で共有されるテキストの量を決定します。これは、特に段落をまたいでつながったアイデアの連続性を保つのに役立ちますが、重複が多すぎると処理のオーバーヘッドが増加します。これらのパラメータを最適化することで、正確な検索に不可欠な、テキスト分割時のコンテキストの把握とフォーカスの維持のバランスをとることができます。
チャンキングストラテジーはRAGワークフロー以外にも幅広く応用できる。コンテキストを意識したチャットボットでは、チャンク化されたテキストに依存して、ユーザーからの問い合わせに対して簡潔かつ包括的な応答を提供することができます。例えば、サポートボットはチャンキングを使用して、ユーザーを圧倒することなく、トラブルシューティングガイドを実行可能なステップに分割することができる。同様に、ナレッジグラフの構築においても、チャンキングは生のテキストからエンティティや関係を抽出し、非構造化ドキュメントを構造化データに変換するのに役立ちます。これらの例は、適切なチャンキング戦略がいかに下流のAIタスクを強化するかを示しています。
チャンキングの問題点を理解する
最適化されていないチャンキング戦略は、検索において重大な問題を引き起こす可能性がある。チャンクサイズが小さいと、十分なコンテキストが得られず、検索結果が断片的になったり、不完全になったりします。例えば、製品マニュアルにクエリをかけると、「ステップ1:電源を入れる」のような断片的な情報が返され、その後のステップに関する情報が添付されていないことがあります。逆に、アプリケーションがテキストを過度に大きな塊に分割すると、検索される情報の特異性が薄れてしまいます。簡潔なトラブルシューティングの手順を期待する意味的類似性のクエリは、セクション全体を返す可能性があり、ユーザーが関連する詳細をピンポイントで特定することが難しくなります。
オーバーラップは、さらに複雑なレイヤーを追加する。オーバーラップがないと、システムは連続したチャンク間の思考の連続性を失う可能性がある。しかし、過剰な重複は冗長性をもたらし、ストレージや処理コストを増加させます。これらのトレードオフのバランスをとることは、検索システムが正確で実用的な回答を確実に提供するために不可欠です。
LangChainコードのインポートとセットアップ
この最初のセクションでは、インポートとその他のセットアップツールに焦点を当てます。下のコードを見て最初に気づくことは、インポートがたくさんあるということでしょう。よく使われるのはosとdotenvです。これらは単に環境変数として使用されます。Pythonとpymilvusクライアントを使って、LangChainでのテキスト分割の手順を説明しよう。
一番上に、docを取り込むための3つのインポートがあります。まず、NotionDirectoryLoaderがあり、Markdown/Notionドキュメントを含むディレクトリをロードします。そして、Markdown HeaderとRecursive Characterテキストスプリッターです。これらは、ヘッダー(ヘッダースプリッター)、または事前に選択された文字区切り(再帰的スプリッター)に基づいて、マークダウン文書内のテキストを分割します。
次に、retrieverインポートです。Milvusは私たちのベクトルデータベース、OpenAIEmbeddingsは私たちの埋め込みモデル、そしてOpenAIは私たちのLLMです。SelfQueryRetrieverは、LangChainネイティブのretrieverで、ベクトルデータベース自身にクエリすることができます。LangChainを使ってベクターデータベースに問い合わせる](https://zilliz.com/blog/using-langchain-to-self-query-vector-database)方法については、こちらの記事で詳しく書いています。
最後のLangChainインポートは、AttributeInfoです。これは、ご推察の通り、self-query retrieverに情報を持つ属性を渡します。最後に、pymilvusインポートについて触れたいと思います。LangChainでベクトル・データベースを扱うのにこれらは必要ありません。これらのインポートは最後にデータベースをクリーンアップするために使います。
関数を書く前に最後にすることは、環境変数をロードし、いくつかの定数を宣言することです。headers_to_split_on変数は必須で、マークダウンで分割したいヘッダをリストアップします。path**は、LangChainにNotionのドキュメントがどこにあるかを教えるだけです。
インポート os
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from pymilvus import connections, utility
from dotenv import load_dotenv
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_CLUSTER_01_URI")
zilliz_token = os.getenv("ZILLIZ_CLUSTER_01_TOKEN")
headers_to_split_on = [
("##", "Section")、
]
パス='./notion_docs'
チャンキング実験機能の構築
実験関数のビルドはこのチュートリアルで最も重要な部分です。前述したように、この関数はドキュメントの取り込みと実験のためのパラメーターをいくつか受け取ります。docsへのパス、分割するヘッダー(splitters)、チャンクサイズ、チャンクサイズの最大オーバーラップ、そして最後にコレクションを削除してクリーンアップするかどうかを指定する必要があります。コレクションの削除のデフォルトはtrueです。
コレクションを作成したり削除したりするのはできるだけ控えめにしたい。回避策を探すうちにスクリプトが変わるかもしれません。
この関数は、上でリンクしたLangChainでNotionを使う関数とよく似ています。最初のセクションでは、Notion Directory Loaderを使ってパスからドキュメントをロードします。最初のWebページのhtmlコンテンツだけを取り込んでいることに注意してください(1ページしかありません)。
次に、スプリッタを取得します。まず、マークダウンスプリッタを使って、上で渡したヘッダで分割する。次に、再帰的スプリッターメソッドを使って、チャンクサイズとオーバーラップに基づいて分割します。
これが必要な分割のすべてだ。分割が終わったら、コレクション名をつけて、デフォルトの環境変数、OpenAIのエンベッディング、スプリット、コレクション名を使って、LangChain Milvusインスタンスを初期化します。また、AttributeInfoオブジェクトを使ってメタデータフィールドのリストを作成し、セルフクエリに "セクション "があることを伝えます。
このすべてのセットアップで、LLMを取得し、それをpythonのセルフクエリーリトリーバーに渡します。そこから、ドキュメントに関する質問をすると、retrieverが魔法をかけてくれます。どのチャンク戦略をテストしているのかも教えてくれるように設定しました。最後に、コレクションを削除することもできます。
def test_langchain_chunking(docs_path, splitters, chunk_size, chunk_overlap, drop_collection=True):
path=docs_path
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# ページのセクションヘッダに基づいてグループを作成しよう。
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=splitters)
md_header_splits = markdown_splitter.split_text(md_file)
# テキストスプリッタを定義する
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits=text_splitter.split_documents(md_header_splits)。
test_collection_name = f "EngineeringNotionDoc_{chunk_size}_{chunk_overlap}"
vectordb = Milvus.from_documents(documents=all_splits、
embedding=OpenAIEmbeddings()、
connection_args={"uri": zilliz_uri、
"token": zilliz_token}、
collection_name=test_collection_name)
metadata_fields_info = [
属性情報(
name="Section"、
type="文字列またはリスト[文字列]"、
type="文字列またはリスト[文字列]"
),
]
document_content_description = "文書の主なセクション"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
res = retriever.get_relevant_documents("What makes a distinguished engineer?")
print(f"""チャンキング戦略からの回答:
{チャンクサイズ}, {チャンクオーバーラップ}"")
for doc in res:
print(doc)
# これは大まかなクリーンアップに過ぎない。
# しかし、実際の実験のユースケースを理解するためには、多くのユーザーを考慮する必要があります。
if drop_collection:
connections.connect(uri=zilliz_uri, token=zilliz_token)
utility.drop_collection(test_collection_name)
LangChain のテストと結果
さて、ここからがエキサイティングなところだ!テストと結果を見てみよう。
LangChainチャンクのテストコード
以下の簡単なコードブロックは、実験用の関数を実行する方法です。5つの実験を追加しました。このチュートリアルではchunk strategiesを2の累乗で32から512まで、オーバーラップを2の累乗で4から64までテストします。テストするには、タプルのリストをループし、上で書いた関数を呼び出します。
chunking_tests = [(32, 4), (64, 8), (128, 16), (256, 32), (512, 64)].
for test in chunking_tests:
test_langchain_chunking(path, headers_to_split_on, test[0], test[1])
出力全体はこんな感じだ。では、個々の出力を覗いてみましょう。私たちが選んだ質問例は、"優れたエンジニアとは何か?"であることを思い出してください。
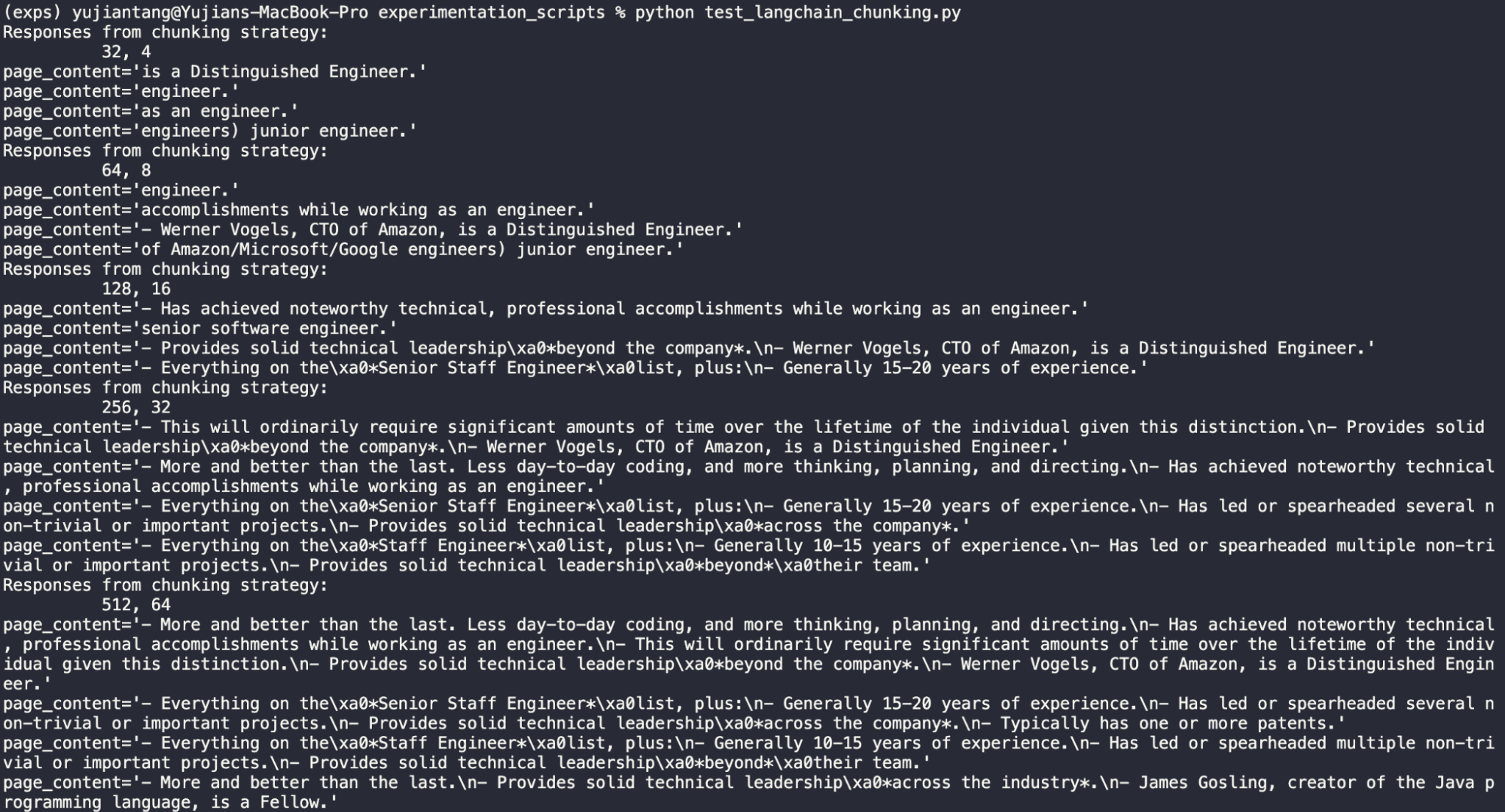
長さ32、重なり4
さて、ここから明らかに32は短すぎることがわかる。この文章はまったく役に立たない。「Is a Distinguished Engineer "は最も回りくどい推論である。
長さ64、重なり8
64と8は最初からあまり良くない。しかし、これは著名なエンジニアの例を示している。アマゾンのCTO、ヴェルナー・ヴォーゲルスだ。

長さ128、重なり16
128になると、より完全な文章が見られるようになる。"engineer. "タイプの単語や回答は少なくなっている。これは悪くない。ヴェルナー・フォーゲルに関する部分と、"Has achieved noteworthy technical, professional accomplishments while working as an engineer."(エンジニアとして働いている間に、技術的、専門的に特筆すべき業績を達成した)をなんとか抜き出している。最後の項目は、実際にはプリンシパル・エンジニアの項目である。
ここでの欠点は、xa0やnのような特殊文字の例がすでに出てきていることだ。これは、おそらくチャンキングの長さが長すぎることを物語っている。

長さ256、重なり32
このチャンキングの長さは確かに長すぎると思う。必要なエントリーを引っ張ってくるだけでなく、"Fellow"、"Principal Engineer"、"Senior Staff Engineer "からのエントリーを引っ張ってくる。しかし、最初のエントリーはDistinguished Engineerのもので、3つのポイントをカバーしている。

チャンクの長さ512、重なり64
256は長すぎるだろうということはすでに述べた。しかし、この512の最初のプルは、実際には著名なエンジニアのためのセクション全体である。個々の「行」や「ノート」が欲しいのか、それともセクション全体を引っ張りたいのか。それはユースケースによる。

異なるチャンキング戦略の実験まとめ
さて、このチュートリアルではlangchainチャンキングPythonを使って、チャンクのサイズとチャンクの重なりの戦略を強調するパラメータ化されたアプローチで、5つの異なるテキスト分割戦略を見てきました。この単純な5つのチャンク戦略でわかったジレンマの1つは、チャンクサイズによって個々の断片を取得するかセクション全体を取得するかということです。128チャンクは個々の「行」や著名なエンジニアに関する「メモ」を取得するのに適していますが、512チャンクはセクション全体を取得することができます。
しかし、256はそれほど良くなかった。
この3つのデータから、テキスト・スプリッターについてわかることがある。理想的なチャンクサイズを見つけるのが難しいということだけではない。チャンクサイズを作成する際には、回答に何を求めるかを考える必要があるということでもある。
まだ、さまざまなオーバーラップをテストしていないことに注意してください。チャンク戦略を学び、身につけたら、オーバーラップをチェックするのは論理的な次のステップです。多分、今後のチュートリアルで、別のライブラリを使ってカバーすることになるでしょう。お楽しみに!
実験からの洞察
これらの実験から、チャンクサイズとオーバーラップの微妙な関係が浮き彫りになりました。小さいチャンクはピンポイントの正確さが要求されるタスクに優れ、大きいチャンクは広範な文脈が要求される質問に適しています。一方、オーバーラップはこれらの目的のバランスをとる上で極めて重要な役割を果たします。
ここで観察されたトレードオフは画一的なものではないことを強調しておきます。理想的なチャンキング・パラメータは、特定のユースケースに大きく依存する。会話エージェントやクイックルックアップツールのようなアプリケーションは、より小さなチャンクで正確な回答を得ることができます。一方、複雑な法律文書を要約するような調査集約型のワークフローでは、包括的なコンテキストを確保するために大きなチャンクが必要になります。
実世界のシナリオでは、多くの場合、ハイブリッドアプローチが最良の結果をもたらします。ユーザーのクエリと意図に基づいてチャンクサイズを動的に調整することで、開発者は効率と検索品質のバランスを取ることができる。このようなアプローチには、インテリジェントなクエリ・ルーティングや、ユーザーのニーズに合わせたアダプティブ・チャンキング・パイプラインのレイヤーを追加することが含まれる。
今後の検討事項
このチュートリアルで行った実験は、ほんの始まりに過ぎない。将来的には、異なるチャンクサイズを組み合わせて多段階のセグメンテーションを行う、階層的なチャンキング戦略を検討することも可能である。さらに、テキストと画像の埋め込みを組み合わせるなど、マルチモーダルなデータ検索に拡張することで、より複雑なユースケースの可能性が広がります。
また、オーバーラップが多様なデータセットの検索にどのような影響を与えるかをより良く理解するために、オーバーラップを系統的に実験する可能性もある。LangChainと一緒に他のフレームワークを統合することで、チャンキングアプローチをさらに洗練させ、新しい最適化テクニックを発見することができる。例えば、Haystackのようなフレームワークは、LangChainのワークフローを補完できる追加検索機能を提供する。
最後に、ユーザーからのフィードバックを検索プロセスに取り入れることで、チャンキング戦略を学習し、時間とともに最適化する適応的なシステムを構築することができる。よりきめ細かい実験により、堅牢でユーザー中心のRAGパイプラインを確立することが可能である。
結論
チャンキングは RAG アプリケーションの検索ワークフローに不可欠な要素である。このチュートリアルでは、チャンクサイズとオーバーラップを注意深く調整することの重要性を示し、異なる戦略が検索結果にどのように影響するかを示した。
コンテキストと精度のトレードオフのバランスを取ることで、開発者は様々なユースケースに対してシステムを最適化することができる。このチュートリアルでは基礎的な実験を取り上げましたが、さらなる探求の可能性は広大です。AIを活用した検索システムの最適化に関するより高度なチュートリアルや洞察にご期待ください。
参考文献
チャンキング、またはテキスト分割戦略は進化し続けているので、私たちはこれらの様々な戦略のコレクションを作り始めました。お楽しみください!
A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG). このガイドでは、RAG(Retrieval-Augmented Generation)システムにおけるチャンキング戦略の様々な側面について検討しました。
この投稿では、ウェブサイトからコンテンツを抽出し、それをRAGアプリケーションのLLMのコンテキストとして使用する方法を説明します。しかし、その前にウェブサイトの基礎を理解する必要があります。
効率的な検索拡張世代(RAG)を構築するための3つの重要な戦略を探る。Retrieval Augmented Generation (RAG)は、AIを搭載したチャットボットで独自のデータを使用するための便利なテクニックです。このブログ記事では、RAGを最大限に活用するための3つの重要な戦略について説明します。
Pandas DataFrame: Chunking and Vectorizing with Milvus. チャンクテキストと埋め込みを含む全てのデータをPandas DataFrame内に保存すれば、Milvusのベクトルデータベースに簡単に統合してインポートすることができます。
 Yujian Tang
Yujian TangYujian Tang is a Developer Advocate at Zilliz. He has a background as a software engineer working on AutoML at Amazon. Yujian studied Computer Science, Statistics, and Neuroscience with research papers published to conferences including IEEE Big Data. He enjoys drinking bubble tea, spending time with family, and being near water.
読み続けて

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.