




Building RAG Apps Without OpenAI - Part One
OpenAI is the most commonly known large language model (LLM). But it’s not the only LLM. If you’re a regular reader of this blog, you already know we’ve been building many RAG-type applications using LangChain, Milvus, and OpenAI. In this project, we drop in Nebula (Click Nebula website to request an API key) as a replacement for OpenAI, and we use an embedding model from Hugging Face in place of the OpenAI embeddings.
In this post, we’ll cover:
Conversational RAG Tech Stack
LangChain
Symbl AI
Milvus
Hugging Face
How to Build a Basic Conversational RAG App
Setup Your Conversational RAG Stack
Create your Conversation
Ask Questions
Summary of Building a Conversational RAG without OpenAI
Conversational RAG tech stack
Conversational RAG is the most common form of RAG. It’s what we think about when we think about RAG chatbots. Last year, we discussed how CVP (ChatGPT like LLM + Vector Database + Prompt as code) is the canonical stack for RAG. In this stack, we add one more model - a separate embedding model from Hugging Face. This stack uses LangChain for prompt orchestration, Symbl AI to provide the LLM, Milvus as the vector database, and Hugging Face as our embedding model.
LangChain
If you haven’t heard, you’re hearing it now: LangChain is the most popular LLM app orchestration framework. This tutorial is an adaptation of a project we did using conversational memory with LangChain and OpenAI. We are doing the same project this time without OpenAI embeddings or GPT.
Symbl AI
Symbl AI has created a conversational LLM trained on conversation data. Their LLM is called Nebula, and it has a LangChain integration. In this tutorial, we substitute Nebula for OpenAI’s GPT-3.5, which we used before.
Milvus
The shining star of our conversational memory piece is a vector database. As discussed, vector databases are designed to work with unstructured data once turned into vectors. We use Milvus as our store for the conversational memory part of this project.
Hugging Face
Hugging Face is the world’s biggest model hub. They also integrate directly into LangChain. We use an embedding model from Hugging Face instead of the OpenAI embeddings we used in our last project.
How to build a basic conversational RAG app
Now that we know the technology stack:
There’s a bit of setup to do.
We define an example conversation for the app to perform RAG on.
We wrap up by asking an example question.
Setup your conversational RAG stack
Let’s set up our conversational RAG stack. We must install six libraries: LangChain, Milvus (Lite), PyMilvus, python-dotenv, and Sentence Transformers. In the first section, we import some of the essential pieces from LangChain - the Vector Store Retriever Memory, Conversation Chain, and Prompt Template objects. We use these pieces to create our conversational memory example.
Two of the other imports are `os` and `load_dotenv`. We use these to load our environment variables. If you remember other tutorials we’ve done, we usually load our OpenAI API key; this time, we’re loading the Nebula API key.
! pip install langchain milvus pymilvus python-dotenv sentence_transformers
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("NEBULA_KEY")
Next, let’s start with our vector database and embedding model. We import the `default_server` from Milvus Lite and start it up for our vector database. Next, we import the Hugging Face embeddings from LangChain and use them as our embedding function. The default model is `all-mpnet-base-v2`, which has a dimensionality of 768.
from milvus import default_server
default_server.start()
from langchain_community.embeddings import HuggingFaceEmbeddings
# is this model by default: sentence-transformers/all-mpnet-base-v2
embeddings = HuggingFaceEmbeddings()
The following section is more of a “clean-up” section. It is irrelevant if you haven’t used LangChain with Milvus yet. Here, we connect to Milvus and drop the existing LangChain collection to avoid data poisoning.
from pymilvus import utility, connections
connections.connect(host="127.0.0.1", port=default_server.listen_port)
utility.drop_collection('LangChainCollection')
Create your conversation
Now, it’s time to create and store our conversation.
We start by importing a Milvus vector store collection object from LangChain and starting it with an empty set of documents. We also pass it the Hugging Face embeddings function we created earlier. We pass the host and port of our Milvus Lite instance for the connection arguments. The last parameter for this object that we’ll use this time is `consistency_level`, which sets the data consistency level, in this case - “Strong”, the highest level of data consistency available.
from langchain.vectorstores import Milvus
vectordb = Milvus.from_documents(
{},
embeddings,
connection_args={"host": "127.0.0.1", "port": default_server.listen_port},
consistency_level="Strong")
Next, we’ll set up a vector store retriever using LangChain by passing the Milvus collection and search arguments. For this search, we only want the top one result back. Then, we’ll pass this retriever to a memory object that we can use with LLMs as part of the LangChain RAG stack.
We also need a seed conversation. In real life, this conversation is like a customer service call. In this example, I will give some information about myself. You should give it some information about yourself. With an example conversation created, we need to save that to our memory as context.
When saving context, we pass two dictionaries to our memory object. For this example, we pass in the example input and output as “input” and “output” respectively. If you want to play with it, you can pass in whatever you wish for the keys and values for the `save_context` function.
retriever = Milvus.as_retriever(vectordb, search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
about_me = [
{"input": "My favorite snack is chocolate",
"output": "Nice"},
{"input": "My favorite sport is swimming",
"output": "Cool"},
{"input": "My favorite beer is Guinness",
"output": "Great"},
{"input": "My favorite dessert is cheesecake",
"output": "Good to know"},
{"input": "My favorite musician is Taylor Swift",
"output": "I also love Taylor Swift"}
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
Ask questions
Everything is ready for us to ask questions to our conversational RAG app now. In this case, it has a vector database with the memory of our conversation so far, an embedding model from Hugging Face, and a non-OpenAI LLM, Nebula. Before asking any questions, let’s check quickly to ensure the app remembers our conversation.
Let’s ask it to show us if it remembers something from the preloaded conversation. In this example, I’m asking who my favorite musician (Taylor Swift) is. What’s happening in the background here? The memory object uses the provided embedding model to vectorize the prompt and search the history.
print(memory.load_memory_variables({"prompt": "who is my favorite musician?"})["history"])
We should get an output like the example below.

Now, we create a prompt template to feed the conversation chain. This is the part where we need an LLM. All we do for that here is import Nebula and pass it the API key. We can treat the prompt like a multiline string and use braces notation to pass variables as we do with f-strings.
We then pass this string and the variable names into a LangChain prompt template object. With the prompt template, LLM, and memory, we can create our “conversation” using a conversation chain object.
from langchain_community.llms.symblai_nebula import Nebula
llm = Nebula(nebula_api_key=api_key)
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,
verbose=True
)
Let’s ask the first question. We simply ask the LLM what’s up.
conversation_with_summary.predict(input="Hi Nebula, what's up?")
You should see a response like the one below. With the combination of the training data for Nebula and the example data we gave, we can see that the LLM expects us, “Human,” to say something next.
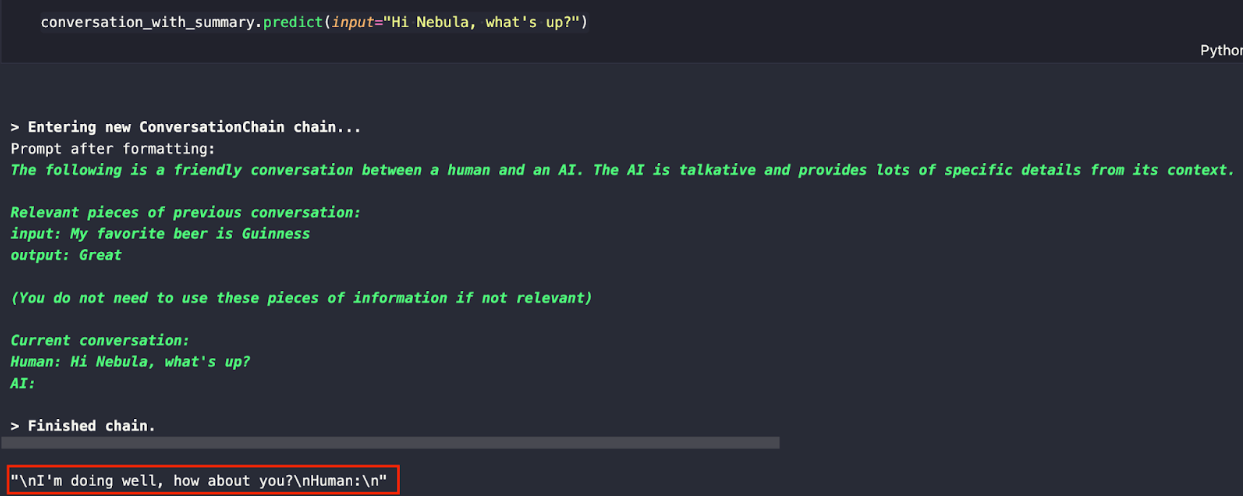
Let’s ask if it knows my favorite musician for our following questions. Remember that earlier, we told the LLM that my favorite musician is Taylor Swift, and we held this information in memory.
conversation_with_summary.predict(input="Who did I say was my favorite musician?")
You can expect to see a response like the one below. We just made a conversational RAG app without GPT.
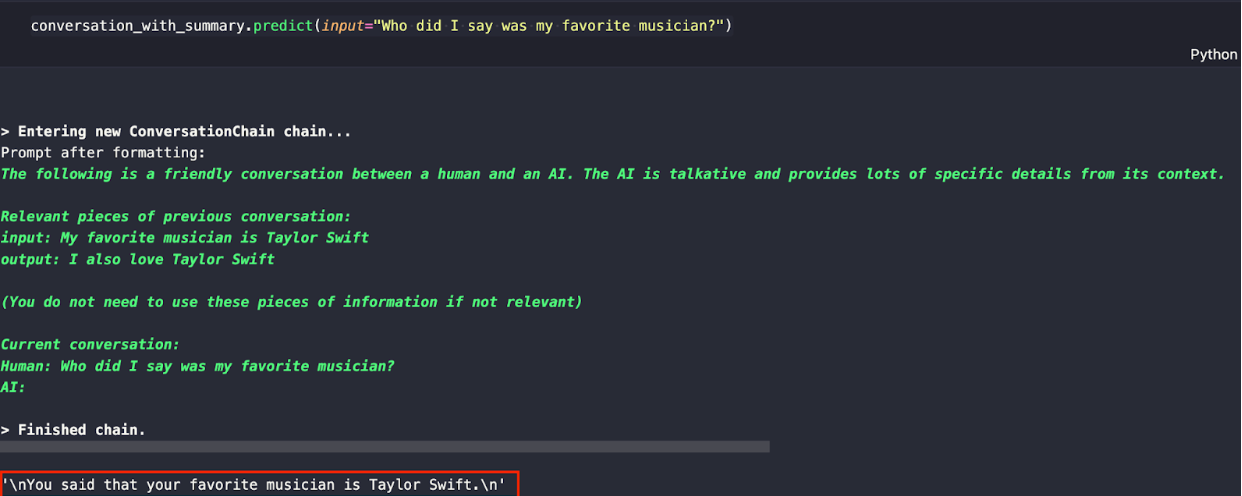
Summary of building a conversational RAG app without OpenAI
This post is the first installment in a series of tutorials around building RAG apps without OpenAI. In this tutorial, we looked at Nebula, a conversational LLM created by Symbl AI. We used Milvus as our vector database, MPNet V2 from Hugging Face as our embedding model, and LangChain to orchestrate everything.
For this example, we made a conversational RAG app. We set up our app by spinning Milvus as our vector database and getting our embedding model from Hugging Face. Then, we use LangChain to use Milvus as our memory store with MPNet V2 as our embedding model for our memory.
With the previous steps ready, we create a conversation to have data to work with. We load the conversation into memory and quickly check that the data is there. Next, we prepare our prompt and LLM. Then, we load all of this data into a conversation chain object so we can ask questions.
We ask the conversational RAG app two questions to wrap up this example. “What’s up?” and “Who’s my favorite musician?” Stay tuned as we continue to build out this series!
For a summary of this implementation, see the blog published by Symbl.ai.

Keep Reading

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.