



セキュアでパーミッションを意識したRAGの展開
急ピッチで進む人工知能の分野において、Retrieval Augmented Generation (RAG)は、OpenAIのGPTシリーズやGoogleのGeminiのような生成モデルの能力を強化する強力なアプローチとして登場した。しかし、大きな可能性には大きな責任が伴う。特に、機密データを保護し、プライバシー規制の遵守を確保することに関しては。
組織がAI主導のソリューションにますます依存するようになる中、これらの技術のセキュリティ上の意味を理解することは極めて重要である。データを保護するだけでなく、ユーザーの信頼を構築する強力なセキュリティ対策を導入することは、本番に対応できるRAGアプリケーションにとって不可欠です。
最近Zillizが主催したUnstructured Data Meetupで、Opsinの共同創設者であるOz Wassermanは、RAGの展開における重要なセキュリティ上の考慮点を強調し、データの匿名化、強力な暗号化、入出力の検証、堅牢なアクセス制御など、重要なセキュリティ対策の重要性を強調した。
このブログでは、セキュアでアクセス許可を意識したRAGのデプロイメントの重要な側面について説明します。また、Milvus vector databaseとLlamaIndexのポストプロセッサーを使用したRAGパイプラインのノートブックの例を通して、機密情報を削除し、データのプライバシーとコンプライアンスを確保するように設計されていることを説明します。RAG アーキテクチャ図
オズは講演の中で、まず図1に示すような基本的なRAGアーキテクチャについて説明した。基本的に、RAGシステムは、ベクトルデータベースを搭載した知識ベースを統合することで、大規模言語モデル(LLM)を強化し、ユーザーのクエリに応じて関連するコンテンツを検索するための文書を格納する。このアプローチは、精度を向上させ、より大きな文脈的関連性を保証し、スタンドアロンのLLMの出力でしばしば見られる幻覚を最小限に抑えます。
しかし、この基本的なパイプラインには、様々な段階に統合されない限り、特定のセキュリティ対策が欠けている。Oz氏は、DistributedApps.aiのKen Huang氏によるRAGワークフロー・チャート(図2を参照)を強調した:
データソース/VectorDBステージ
検索ステージ
生成ステージ
図- RAGチャットボットを促進するベクトルデータベース.png](https://assets.zilliz.com/Figure_Vector_database_facilitating_RAG_chatbot_1a87eb1206.png)
図1:RAGの基本アーキテクチャ
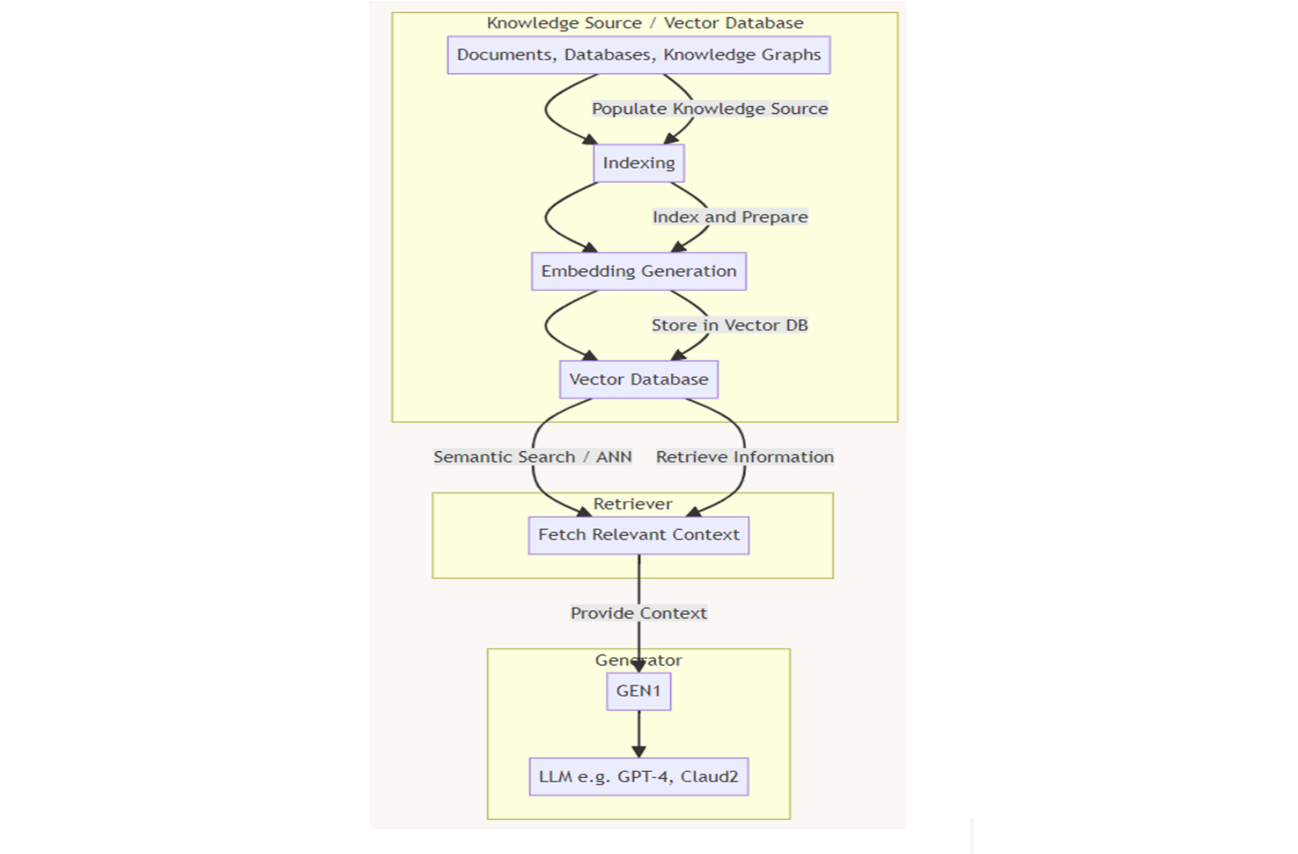 図2- 詳細RAGアーキテクチャ (著者- Ken Huang)
図2- 詳細RAGアーキテクチャ (著者- Ken Huang)
図2:詳細なRAGアーキテクチャ(著者:Ken Huang)_。
データソース/VectorDBステージ
MilvusやZilliz Cloud(マネージドMilvus)のようなベクトルデータベースは、非構造化データから変換されたベクトル埋め込みを保存し、インデックスを付け、検索する。これらは貴重な情報の重要な保管場所である。しかし、データ漏洩や不正アクセスのターゲットになる可能性もあり、暗号化、アクセス制御、データの匿名化などの強固な保護戦略の実装が必要です。
図3- データソース:VectorDBセキュリティコントロール.png](https://assets.zilliz.com/Figure_3_Data_Source_Vector_DB_Security_Controls_fd4f503610.png)
図3:データソース/VectorDBセキュリティコントロール
最初のセキュリティ・スレッドは、データの匿名化にあります。データには、一般的に個人を特定できる情報(PII)と呼ばれる個人の機密情報が含まれています。このデータは個人のプライバシーを保護するために匿名化されなければなりません。このステップは、この情報が特定の個人を特定できないようにするため、データ処理の前に必須です。
いったんデータが匿名化されると、関連するコンテンツを検索するためのセマンティック検索を可能にするために、インデックスを作成し、埋め込みデータを生成することができる。この段階で重要なのは、誰がベクターデータベースにデータを保存し、ベクターデータベースからデータを取り出すことができるのか、言い換えれば、誰がベクターデータベースにアクセスできるのかを定義することである。不正アクセスを防止するためには、厳密なアクセス制御の実施が不可欠であり、その結果、データの操作や漏洩が発生する可能性がある。
アクセス制御はいくつかの段階に分けることができます:
認証:認証:一般的にOAuth 2.0のような方法を用いて、ユーザーの身元を確認する。
認可**:認証された本人確認に基づき、特定のパーミッションやアクセス権をユーザーに付与する。
トレーサビリティデータへのアクセス試行がログに記録され、追跡できるようにアクセスを監視し、セキュリティ・コンプライアンスのための監査証跡を提供する。
これらの対策は、ベクター・データベースを保護し、許可されたユーザーのみが機密データにアクセスできるようにするのに役立ちます。
もう一つのセキュリティ・レイヤーは、暗号化で追加することができ、静止時(保存時)や転送時(送信時)にデータをわからなくすることができる。伝統的な暗号化は暗号鍵を使用しますが、差分プライバシーや分散化 & シャーディングのような、より高度な技術もデータセキュリティを強化するために採用されるようになってきています。
Zilliz Cloudは、Milvusが提供するフルマネージドベクトルデータベースサービスです。データセキュリティ](https://docs.zilliz.com/docs/data-security?_gl=1rfgiz4_gaNjg5MjI1NDU3LjE3MjU1NTY4MDE._ga_KKMVYG8YF2MTcyNjQwNDkxMy4xMS4wLjE3MjY0MDQ5MTMuMC4wLjA._ga_Q1F8R2NWDP*MTcyNjQwNDkxMy4xMS4wLjE3MjY0MDQ5MTMuMC4wLjA.#storing-and-transmitting-data-with-encryption)対策が可能です。プライベート・リンクのような公共インターネット・アクセスを避けるための他のソリューションや、定期的で安全なデータ・バックアップを確保するためのバックアップとリストア、データ紛失時のナレッジ・ベース回復なども提供できる。
図6-Zilliz多層エンタープライズ・グレード・セキュリティ](https://assets.zilliz.com/Figure_6_Zilliz_Multi_layered_Enterprise_grade_Security_b96f560d8a.png)
図6:Zillizマルチレイヤー・エンタープライズグレード・セキュリティ_ (出典)
検索段階
検索段階は、セキュリティ上の懸念に対処しなければならないもう一つの重要な段階である。前の段階と同様に、クエリによる知識ベースへのアクセスの制御は不可欠である。さらに、この段階では、いくつかのセキュリティリスクも軽減する必要がある:
1.クエリの検証クエリの検証:クエリの検証は、プロンプト・インジェクション攻撃を防ぐために非常に重要です。このアプローチは、ユーザー入力がシステムの脆弱性を悪用し、データへの不正アクセスや不正操作につながる可能性がないことを保証する。
2.類似検索のリスク:類似検索に関連するリスクを管理することも重要である。類似検索が不注意に機密情報を暴露したり、制限されたデータへの不正アクセスを提供したりしないよう、適切な対策を講じる必要がある。
図7-クエリ検証ステップ](https://assets.zilliz.com/Figure_7_Query_Validation_Step_83cd928663.png)
図7:クエリ検証ステップ
オズは社内モデルを紹介しながら、プロンプト注入の例(図8参照)を共有した。これはプロンプト操作の良い例であり、プロンプトを変更してデータを取得する。
図8-プロンプト・インジェクションの例](https://assets.zilliz.com/Figure_8_Example_of_Prompt_Injection_30fbc4b3e5.png)
図8:プロンプト・インジェクションの例_」()
さらに、オズは類似検索に関連するいくつかのリスクについて議論した:
1.データ漏洩:データ漏洩**:類似検索クエリを操作することで、攻撃者は検索メカニズムに影響を与え、機密データを間接的に取得することができる。
2.検索結果の操作:検索結果の操作**:攻撃者は検索プロセスを変更することで、どの検索結果が取得されるかに影響を与え、制限された情報が漏洩する可能性があります。
3.偵察とパターン分析:偵察とパターン分析**:攻撃者は検索クエリやレスポンスのパターンを分析することで、データベー スの構造を把握し、保存されているデータに対する洞察を得る可能性があります。
4.リソースの枯渇:継続的または過度のクエリにより、サービス拒否状態が発生し、システム・リソースが枯渇し、他のユーザーに対する可用性が低下する可能性があります。
アクセス制御やデータ検証のように、検索段階でも同様のセキュリティ技術を実装しなければならないことがわかる。さらに、データがコンポーネント間で転送される際には、(転送中の)暗号化を考慮しなければならない。
生成ステージ
RAGパイプラインの最終段階は生成段階であり、ラージ・ランゲージ・モデル(LLM)がベクトル・データベースから検索されたコンテンツに基づいて応答を生成する。この段階ではLLMが中心的な役割を果たしますが、モデルの学習に使用されるデータの性質によっては、セキュリティとコンプライアンスの問題が発生する可能性があります。主なリスクには以下のようなものがある:
1.データプライバシー侵害:データのプライバシー侵害**:個人を特定できる情報(PII)やその他の機密情報を含むデータを学習させた場合、LLMは不注意に機密情報や個人情報を明らかにする可能性がある。その結果、GDPRやHIPAAなどのプライバシー規制に抵触する可能性があります。
2.出力操作:攻撃者は入力クエリに影響を与えることでLLMの出力を操作し、悪意のある、あるいは誤解を招くようなコンテンツを生成する可能性がある。これは、出力が検証されることなく信頼される環境では特に問題となる。
3.バイアスと攻撃的コンテンツ:学習データに偏った要素や攻撃的な要素が含まれている場合、LLMは偏った回答や攻撃的な回答を生成する可能性があり、特に本番環境では法的責任につながる可能性がある。
このようなリスクに対処するためには、生成されたコンテンツを注意深く後処理する必要があります:
コンテンツフィルタリング:コンテンツフィルタリング:出力を自動的にフィルタリングして、機密性の高い、偏った、または攻撃的なコンテンツを検出し、ブロックする。
出力の検証**:モデルの応答を検証し、ユーザーに配信する前にセキュリティポリシーや規制基準に準拠していることを確認します。
モデルの微調整**:モデルが規制に準拠したデータで微調整されていることを確認し、有害な出力を避けるために強化学習戦略を適用する。
これらの戦略を取り入れることで、生成段階をより安全で信頼性の高いものにし、セキュリティ・レイヤーを追加することができる。
それでは、データの匿名化の例を掘り下げましょう。異なるLlamaIndexポストプロセッサーを比較し、データプライバシー侵害の例を示します。
LlamaIndexとMilvusを用いた安全なRAG
以下のnotebookは、LLMフレームワークとしてLlamaIndex、ベクトルデータベースとしてMilvus、そしてPIIマスキングに特化した3つの異なるモジュールで構築されたRAGパイプラインの例である:1つはHugging Face NERモデル、もう1つはLLM(OpenAI)とマイクロソフトのライブラリであるPresidioを使用する。
全コードはこちらのcolab notebookでも確認できる。
ステップ1:環境変数の設定
OpenAIのモデルを使ってモジュールをテストするには、OpenAIのキーが必要です。
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
ステップ2:プライベートデータでテキストを定義する
まず、クレジットカード番号、名前、生年月日などの個人情報を含む短いテキストを定義します。
from llama_index.core.postprocessor import NERPIINodePostprocessor
from llama_index.core.schema import TextNode, NodeWithScore
text = ""
こんにちは、私はサラ・ミッチェルです。3714-496089-47322という番号の新しいクレジットカードを手に入れました。
個人メールアドレスはsarah.mitchell@mailbox.com、現在シドニーに住んでいます。
ところで、公共料金をカード番号6011-5832-9109-1726で支払おうとしたのですが、うまくいきませんでした。
銀行取引では、このIBAN:NL91ABNA0417164300を使っています。
また、Wi-Fiの問題についても教えてください。IPアドレス203.0.113.15によってブロックされ続けています。
https://www.sarahs-lifediary.org/、私の個人ブログで家族の写真を共有しました。
祖父のジョージ・ストーンは1921年生まれ、祖母のエミリー・クラークソンは1925年生まれです。
最後の質問ですが、私のメインカード(末尾が8473のカード)の利用限度額はいくらですか?
"""
node = TextNode(text=text)
ステップ 3: PII マスキングの NER モデル:NERPIINodePostprocessor
NERPIINodePostprocessorはLlama Indexのモジュールで、NER(名前付きエンティティ認識)に特化したHugging Faceモデルを使用してその情報をマスクする。
from llama_index.core.postprocessor import NERPIINodePostprocessor
from llama_index.core.schema import TextNode, NodeWithScore
processor = NERPIINodePostprocessor()
new_nodes = processor.postprocess_nodes([NodeWithScore(node=node)])
print(new_nodes[0].node.get_text())
このモデルはいくつかの情報を隠蔽しているが、プライベートなデータはまだ見えている。このアプローチを使用すると、データが漏れることになる。したがって、別のモデルやアプローチを使用しなければならない。
"""
出力する:
こんにちは、私は[PER_9]です。3714-496089-47322という番号の新しいクレジットカードを手に入れました。
個人メールアドレスはsarah.mitchell@mailbox.com、現在[LOC_169]に住んでいます。
ところで、公共料金をカード番号6011-5832-9109-1726で支払おうとしましたが、うまくいきませんでした。
銀行取引にはこのIBAN: NL91ABNA0417164300 を使っています。
また、Wi-Fi[MISC_374]の問題についても教えてください。IPアドレス203.0.113.15によってブロックされ続けています。
https://www.sarahs-lifediary.org/、個人ブログで家族の写真を共有しました。
祖父の[PER_545]は1921年生まれ、祖母の[PER_599]は1925年生まれです。
最後の質問ですが、私のメインカード(末尾が8473のカード)の利用限度額はいくらですか?
"""
ステップ4:PIIマスキングのためのLLM:PIINodePostprocessor
PIINodePostprocessor は Llama Index のモジュールで、LLM モデルを使って機密情報をマスキングする。このアプローチの効率をテストするために、デフォルトのOpenAIモデルを使用します。
from llama_index.core.postprocessor import PIINodePostprocessor
from llama_index.core.schema import TextNode, NodeWithScore
from llama_index.llms.openai import OpenAI
processor = PIINodePostprocessor(llm=OpenAI())
new_nodes = processor.postprocess_nodes([NodeWithScore(node=node)])
print(new_nodes[0].node.get_text())
このアプローチに従って、モデルはすべての機密情報を認識し、それに応じてマスクすることができる。
"""
出力する:
CREDIT_CARD_NUMBER1]という番号の新しいクレジットカードを手に入れました。
Eメールアドレスは[EMAIL]で、現在[CITY]に住んでいます。
ちなみに、公共料金をカード番号[CREDIT_CARD_NUMBER2]で支払おうとしましたが、うまくいきませんでした。
銀行取引にはこのIBAN: [IBAN]を使っています。
また、Wi-Fiの問題についても教えてください。IPアドレス[IP_ADDRESS]によってブロックされ続けています。
URL]の個人ブログで家族の写真を共有しました。
祖父の[NAME3] [NAME4]は[DATE1]生まれで、祖母の[NAME5] [NAME6]は[DATE2]生まれです。
最後の質問ですが、私のメインカード([CREDIT_CARD_ENDING]で終わるカード)の利用限度額はいくらですか?
"""
ステップ5:PIIマスキングのためのプレシディオ
最後に、NERに特化したSpacyモデルを使って機密情報をマスクするマイクロソフトのライブラリ、Presidioをテストする。
from llama_index.postprocessor.presidio import PresidioPIINodePostprocessor
from llama_index.core.schema import TextNode, NodeWithScore
from llama_index.llms.openai import OpenAI
processor = PresidioPIINodePostprocessor()
new_nodes = processor.postprocess_nodes([NodeWithScore(node=node)])
print(new_nodes[0].node.get_text())
今回、モデルはクレジットカード番号以外のすべての情報をマスクできることがわかる。次のステップでは、このモデルを使っていくつかのクエリをテストし、クレジットカード番号の一部が利用可能であるため、データプライバシー侵害がどのように起こり得るかを示します。
"""
出力
3714-<US_DRIVER_LICENSE_1>-47322という番号の新しいクレジットカードを手に入れました。
Eメールアドレスは<EMAIL_ADDRESS_1>で、現在<LOCATION_1>に住んでいます。
ところで、公共料金をカード番号<IN_PAN_1>9109-1726で支払おうとしましたが、うまくいきませんでした。
銀行取引では、このIBAN:<IBAN_CODE_1>を使っています。
また、Wi-Fiの問題についても教えてください。IPアドレス<IP_ADDRESS_1>でブロックされ続けています。
<URL_1>の個人ブログで家族の写真を共有しました。
祖父の<PERSON_2>は<DATE_TIME_2>生まれで、祖母の<PERSON_1>は<DATE_TIME_1>生まれです。
最後の質問ですが、私のメインカード(末尾が8473のカード)の利用限度額はいくらですか?
"""
ステップ6:Milvusを使った検索
まず、テキストを格納するMilvusベクトルデータベースを作成しましょう。
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(
uri="./milvus_demo.db", dim=1536, overwrite=True
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex([n.node for n in new_nodes], storage_context=storage_context)
次に、いくつかのクエリーをテストしてみよう。
最初のクエリは正しく動作します。正しい答えが返され、情報はマスクされたままです。
response = index.as_query_engine().query(
"その人の名前は何ですか?"
)
print(str(response))
"""
出力する:
人物の名前は <PERSON_3> です。
"""
次に、クレジットカード番号を取得しようとすると、運転免許証としてマスキングされた完全な番号が取得されることがわかる。
response = index.as_query_engine().query()
"クレジットカードの番号は何番ですか?"
)
print(str(response))
"""
出力する:
クレジットカードの番号は3714-<US_DRIVER_LICENSE_1>-47322です。
"""
しかし、すべてのクレジットカード発行会社にはIIN(発行者識別番号)が割り当てられていることも知られている。最初の数字が発行元を示す。この場合、37はアメリカン・エキスプレスを意味します。もしご存じなければ、機種を尋ねて確認することができます。
response = index.as_query_engine().query()
"クレジットカード番号の発行会社は何ですか?"
)
print(str(response))
クレジットカード番号の発行元はアメリカン・エキスプレスです。
つまり、この情報はテキストで提供されていないにもかかわらず、モデルはカード発行会社を認識できることがわかります。つまり、このモデルは発行元に関するクレジットカード情報で訓練されており、その知識で答えを提供できるのです。これは、上述の生成段階におけるデータプライバシー侵害の例である。
結論
OzはRAGパイプラインの様々な段階を説明し、セキュリティ上の懸念に対処できる点を強調した。最初の重要な懸念は、データの匿名化であり、機密データが権限のない第三者によってアクセスされないようにすることである。しかし、LLM基礎モデルがこのデータでトレーニングされた可能性があり、モデル自体がデータ漏洩の潜在的な原因となっていることを忘れてはならない。
データへのアクセスと送信を安全にするためには、アクセス制御と暗号化が重要である。これらの技術は高いレベルのセキュリティと制御を提供するが、プロンプト・インジェクションや検索操作のような脅威は、依然として機密情報に対するリスクとなる。
したがって、潜在的な脅威を軽減するためには、パイプライン全体に複数のセキュリティ層を追加することが 不可欠です。本番稼動可能なRAGアプリケーションは、システムが攻撃に対する回復力を持ち、規制基準に準拠していることを保証するために、各段階で強固なセキュリティ対策を統合する必要がある。
その他のリソース
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
データに適した埋め込みモデルの選択](https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data)
Trulensを使ってマルチモーダルRAGを評価する](https://zilliz.com/blog/evaluating-multimodal-rags-in-practice-trulens)
言語パワーを解き放つ:LangChain入門 ](https://zilliz.com/learn/LangChain)
GenAIエコシステムの風景:LLMとベクトルデータベースを超えて】(https://zilliz.com/blog/landscape-of-gen-ai-ecosystem-beyond-llms-and-vector-databases)

読み続けて

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.