




Understanding Database Sharding

Understanding Database Sharding
Modern websites and applications rely heavily on database technologies to handle read and write requests from multiple users. However, as an application’s popularity increases, the number of users rises, and it becomes challenging to provide optimal customer experience due to frequent database crashes.
So, how can developers scale up their databases to address rising demand? While the answer can vary depending on the use case, database sharding is one straightforward and cost-effective method. It is easy to implement and offers significant performance improvements.
Despite its simplicity, database sharding can be a confusing concept. This post will explain its meaning, implementation techniques, alternatives, benefits and challenges, and use cases to help you understand when and how to apply the most suitable sharding method.
What is Database Sharding?
Database sharding breaks down an extensive database into smaller chunks called shards and distributes them across multiple machines. Each machine uses the same technology, working in parallel to process large data volumes.
It is one of many methods to help speed up data processing and ensure high availability. If a single machine or database server fails due to request overload, other servers can still process read and write requests, maintaining a smooth user experience.
However, sharding only works as long as data is available and accessible. It allows developers to organically distribute the workload and reduce latency.
Replication and partitioning are other techniques to prevent downtime. These methods are more appropriate for smaller databases. Replication involves copying an entire database across multiple servers while partitioning breaks down a database and stores it in a single machine. Later sections will explain these approaches in more detail.
How Does Database Sharding Work?
Sharding is a form of horizontal scaling where developers install additional nodes or servers to store multiple data partitions. Each partition becomes an independent table sharing the same schema as the original database. However, the information in each shard is unique, and developers store the individual chunks across multiple computers, called nodes.
For instance, the following table illustrates a single database representing information on customers and the items they purchased.
| Customer ID | Name | Item Purchased |
| 10001 | A | Shirt |
| 10002 | B | Cap |
| 10003 | C | Shirt |
| 10004 | D | Shoes |
A developer can use database sharding to split the database into smaller partitions, called logical shards, on separate machines or physical shards.
Server 1
| Customer ID | Name | Item Purchased |
| 10001 | A | Shirt |
| 10002 | B | Cap |
Server 2
| Customer ID | Name | Item Purchased |
| 10003 | C | Shirt |
| 10004 | D | Shoes |
Sharding works on a shared-nothing architecture, where a single node in a computer cluster processes user requests independently. When a user tries to access the database, only the shard containing the user’s information will become active and process the incoming request.
Developers divide the data into logical shards using a shard key. They can select the key based on a column that organizes data into groups or create a new one. The following sections will explain how a shard key operates and helps develop data groups for efficient sharding.
Sharding Methods
Developers can implement multiple sharding techniques based on the use case and the nature of the data they want to process. Popular methods include range-based sharding, hashed sharding, directory sharding, and geo-sharding.
Range-based Sharding
Range-based or dynamic sharding splits a database into shards based on a specific value range. The diagram below illustrates how a developer can divide a table into shards using a price range.
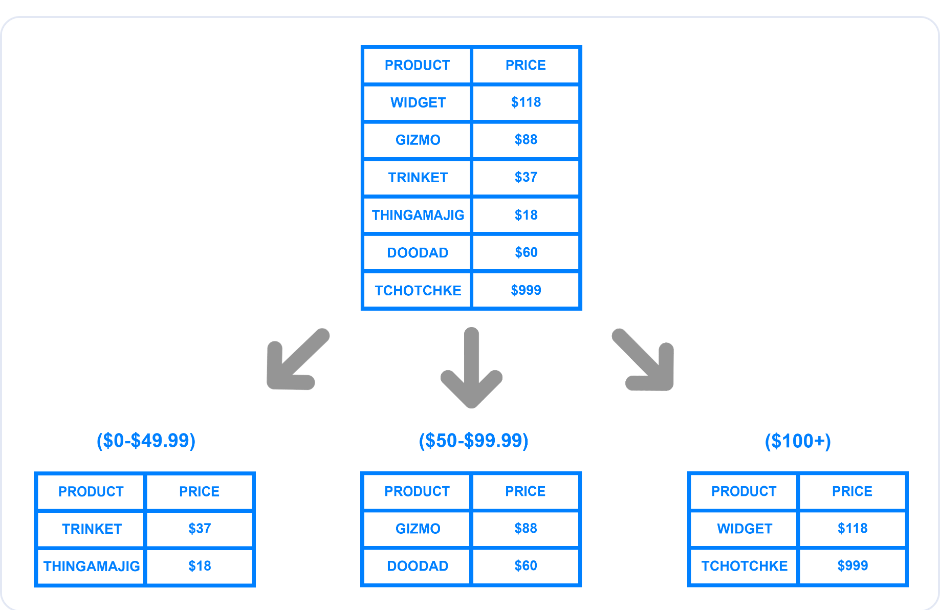 Range-based sharding based on price.png
Range-based sharding based on price.png
Range-based sharding based on price
The example shows three logical shards created using price ranges. The developer can assign each chunk a unique shard key and store them on separate physical shards or machines. When writing a record to the database, the system will determine the appropriate shard to which the data belongs based on the price range and update it accordingly.
Although implementing dynamic sharding is straightforward, it can overload a particular shard if it contains more records than others. In the example above, if more customers purchase items with a price over $100, the data volume in the third shard will be more than the volume in others.
The uneven distribution can beat the purpose of sharding, as only a single shard will contain most of the data, causing the system to slow down. Also, the method requires a lookup table that stores the unique shard key and the corresponding ranges.
Hashed Sharding
Hashed sharding assigns a hash key to each record based on a specific column. Developers generate hash keys using a hash function that takes the values in the column as input. They can divide the data by determining the records that belong to a corresponding key or hash value.
For instance, developers can select a column and use its values to generate hash values. These values can serve as the shard key for each chunk, and developers can store them on different machines. The diagram below illustrates the process.
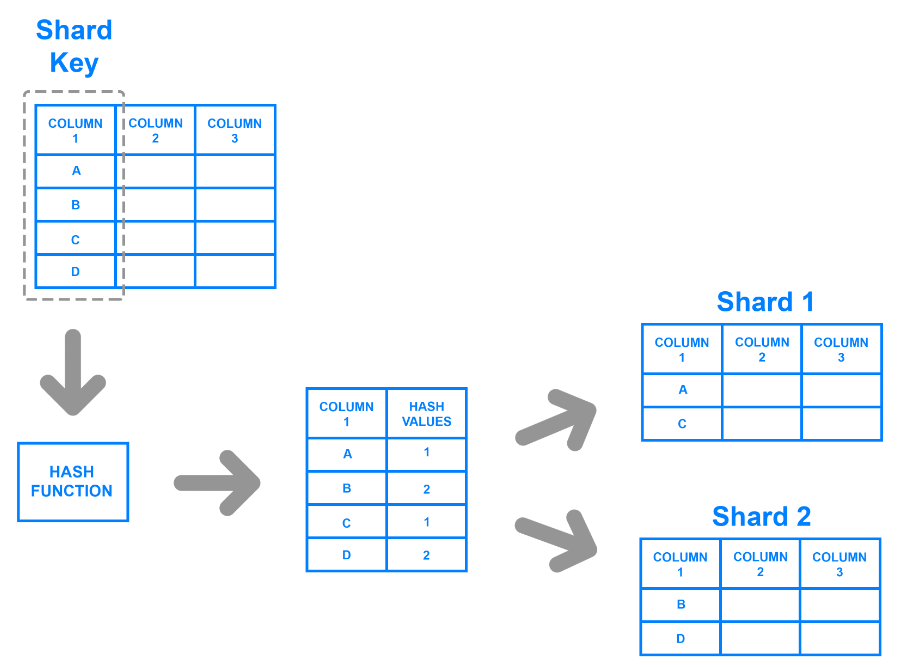 Hashed sharding.png
Hashed sharding.png
Hashed sharding overcomes the problem of uneven distribution as the hashing function or algorithm doesn’t need a user-defined shard key to partition the data. However, it becomes challenging to query data from individual shards as the keys don’t group data based on any meaningful criteria. An algorithm randomly generates the hash values and divides the data in an ad-hoc manner.
For instance, in range-based sharding, the keys reflect the ranges of a particular value in the table and relate to the data structure more meaningfully. Querying shards based on value ranges is quicker than querying data based on hash keys.
In addition, adding more shards or upgrading the systems requires the developer to re-run the entire hashing algorithm on all the records. This process is necessary to balance the data volume across machines but can involve significant downtime and computing resources.
Directory Sharding
Directory sharding is more flexible than the methods discussed above. It divides data based on the values of a particular column and uses a lookup table to determine which shard a record belongs to.
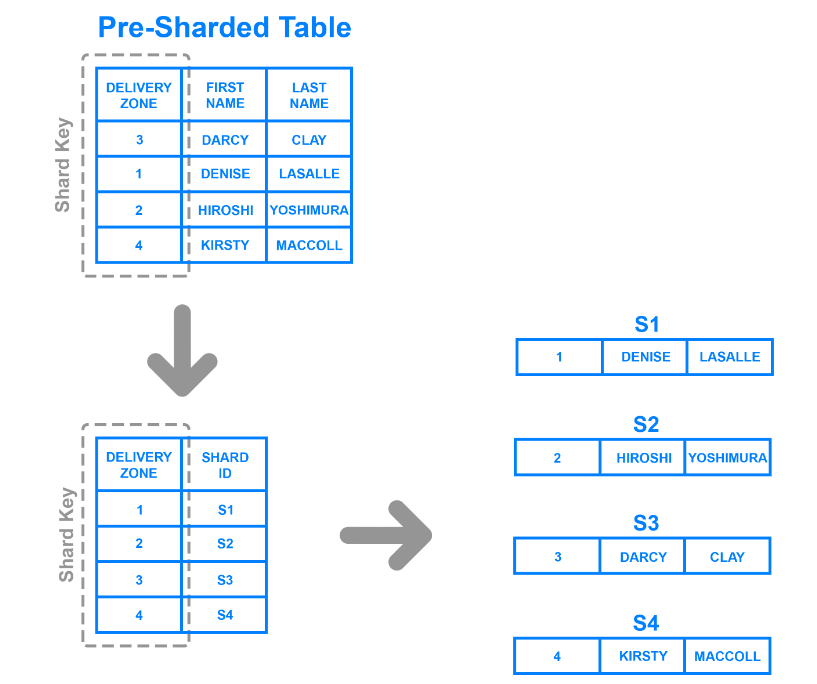 Directory sharding based on delivery zone.png
Directory sharding based on delivery zone.png
Directory sharding based on delivery zone
For instance, the illustration shows how to use the Delivery Zone column as the shard key and split data according to the zones to which a customer belongs. The method created four distinct shards, as the table has four zones.
Unlike range-based sharding, data partitions are more versatile as they don’t have to adhere to strict value ranges. Also, it allows developers to update shards more quickly, as they don’t have to generate keys algorithmically for all the values in a particular column.
However, the technique requires a lookup table to address incoming requests, slowing down processing speed. Also, selecting a column that results in an extensive number of shards can significantly increase the lookup table size and latency.
Selecting a Shard Key
Efficient database sharding requires developers to determine an appropriate sharding key to ensure equal data distribution across shards. In an uneven distribution, specific shards can become data hotspots containing more data than others.
The shard key must also simplify the query process to increase processing speed and prevent downtime. In addition, determining an appropriate shard key relies on selecting the right column.
The list below highlights three significant factors developers can consider when choosing the most suitable column for generating the shard key.
- Cardinality: Cardinality specifies the maximum number of shards a developer can create based on distinct values in a column. For instance, selecting a column containing three distinct values will result in three shards. Directory-based sharding is helpful when a column’s cardinality is low.
- Frequency: Frequency refers to the percentage of data belonging to a particular shard key. For instance, in range-based sharding based on prices, specific price ranges may contain around 80% of the total records, resulting in a data hotspot.
- Dynamic Shards: The data volume in dynamic shards changes as the demand for an application changes. For instance, as the application becomes popular, user demographics may change, and sign-ups from customers in the 20-25 age range may increase. Range-based sharding based on age can result in a data hotspot as more data will be present in the shard corresponding to the 20-25 age range.
To ensure effective database sharding, developers must consider a shard key’s cardinality and frequency and determine whether it will result in dynamic shards.
Comparison with Alternatives
Database sharding is one method for scaling databases. Other methods include vertical scaling, replication, and partitioning. Understanding how these differ from sharding will help developers use the correct scaling method for specific scenarios.
Vertical Scaling
Vertical scaling involves upgrading an existing server’s capacity. Developers can install additional CPUs, hard disks, and other software to improve performance.
The method helps in cases where a single machine is adequate for handling user requests, and only incremental improvements are necessary to boost performance.
While it is less costly than sharding, it only increases server capacity to a limited degree, as only a single machine is available to process user requests.
Replication
Replication occurs when developers make copies of the same database and store them across multiple computers. Like sharding, the method ensures high availability since if one computer fails, others remain active.
Sharding and replication are similar as they distribute processing across multiple machines. However, sharding splits the data into various chunks, while replication copies the entire data without breaking it down.
Sharding is more appropriate for large databases as replication will require servers with high storage capacity. Maintaining and updating each replica on different machines is costly and time-consuming.
Partitioning
Partitioning splits a database into multiple groups and stores them on a single machine. The method is suitable when you want to improve query performance, and the database size is not large enough to warrant storage of partitions across different machines.
It can help optimize data archiving by allowing developers to partition data according to date and time. They can move specific records with timestamps older than a certain threshold to an archival table and use another table to store the latest records.
Benefits of Database Sharding
Database sharding is a valuable strategy for efficient data management. Businesses reliant on extensive data to operate their websites, applications, and other data-driven software must adopt sharding to maximize the benefit of their database technology.
The list below mentions a few benefits sharding offers organizations in more detail.
Scalability: By splitting data across multiple machines, sharding allows businesses to scale their database systems more efficiently to support increasing workloads.
Minimal Downtime: Sharding ensures high availability by operating on a shared-nothing architecture. The strategy allows for a better user experience, as the failure of one machine will not affect the performance of others.
Easy to Upgrade: Implementing performance upgrades is more efficient, as developers can separately update individual machines without shutting down the entire system.
Challenges of Database Sharding
Although sharding offers significant benefits, developers can face a few challenges that increase implementation complexity. The list below highlights these issues with potential mitigation strategies.
Uneven Distribution: Uncertainty regarding data volume and variety can cause hotspots to appear. Despite an effective shard key, the nature of data may change, requiring developers to select or create a new key. Developers must carefully assess the suitability of database sharding in specific scenarios. It is possible that replication or vertical scaling is more practical than sharding in different situations.
Complex to Manage: Managing multiple machines is complex as developers must constantly monitor the health of each node to identify and resolve issues quickly. Robust monitoring systems with real-time alert mechanisms can help mitigate these issues by notifying relevant teams in case of server failures.
Maintenance Costs: Maintaining multiple on-premises servers is costly and requires additional staff with relevant expertise to resolve issues during maintenance. Organizations can migrate to cloud infrastructure to host various shards and have the cloud vendor perform regular maintenance checks behind the scenes.
Database Sharding Use Cases
Although the above sections briefly highlight the use cases in which sharding is beneficial, the list below categorizes and explains these scenarios in more detail.
Large-scale Web Applications: E-commerce sites with an extensive user base, social media platforms, car-hailing apps, and gaming websites are ideal candidates for database sharding. Sharding can help such sites' administrators balance load more effectively and prevent downtime during peak hours.
Big Data Analytics: For users who analyze big data, sharding can help improve processing speed by distributing the load across multiple servers.
Content Delivery Networks (CDNs): A CDN is a group of servers distributed across different locations to handle requests from users in nearby geographical locations. Developers can shard databases according to users' locations and distribute the data across these servers for faster response times.
FAQs about Database Sharding
- What is the difference between sharding and partitioning?
While sharding and partitioning split data into smaller chunks, sharding distributes each chunk across different machines or nodes. In contrast, partitioning stores each chunk within a single machine.
- What is the difference between sharding and replication?
Replication copies the entire database and stores them on different machines. Compared to sharding, which partitions the database across rows and stores each chunk on multiple servers, replication offers higher availability but requires more computing resources and storage capacity.
- How do you choose the correct shard key?
Choosing an appropriate shard key requires developers to determine the proper column for dividing the data. A shard key must have low cardinality and equal frequency.
Cardinality refers to the maximum number of shards possible according to column values. For instance, selecting a column that contains four distinct values will result in four shards. Frequency refers to the proportion of data that each shard contains.
Also, select or create shards that remain static throughout the application’s lifecycle. Shards whose data volume is likely to change may result in hotspots, with some shards getting more volume than others.
- What are the main challenges of database sharding?
Database sharding increases query overhead as developers must write queries to access data from multiple machines to perform analysis.
It also increases infrastructure costs as organizations must maintain multiple servers and monitor their health to prevent outages.
Also, updating and rebalancing shards is complex if data volume and variety increase. A sharding technique suitable in one situation may no longer be practical in others.
- Is database sharding suitable for small applications?
Although database sharding is a valuable technique for improving processing speed and throughput, it is inappropriate for small applications. It is only practical to implement when the data volume reaches a point where it becomes unsustainable to maintain a single database on a single server.
Related Resources
Although developers usually apply sharding to structured datasets, the following resources will help you understand the concept within the context of unstructured data and vector databases:
- What is Database Sharding?
- How Does Database Sharding Work?
- Sharding Methods
- Selecting a Shard Key
- Comparison with Alternatives
- Benefits of Database Sharding
- Challenges of Database Sharding
- Database Sharding Use Cases
- FAQs about Database Sharding
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free