




OpenAIなしでRAGアプリを作る - パート2:Mixtral、Milvus、OctoAI
*このブログはYujian TangとThierry Moreauが書いています。
Retrieval Augmented Generation(RAG)は、2023年に登場するLLMの最も人気のあるユースケースです。ほとんどの例では、OpenAIのGPT LLMを使ってRAGを構築する方法を示していますが、このシリーズでは、OpenAIなしでRAGを構築する方法について触れます。OpenAIなしでRAGを構築する 前編](https://zilliz.com/blog/building-rag-apps-without-openai-part-I)はこちら。
このチュートリアルはこのシリーズの2回目で、Milvus、OctoAIを通してホストされるMixtral、そしてLangChainを使ってRAGを構築することをカバーしています。特に、このチュートリアルでは、Mixtralの多くの利点の氷山の一角である多言語機能を共有します。
このブログでは
- MMO(L)オープンソースRAGテックスタック
- Mixtral
- Milvus
- OctoAI
- LangChain
- RAGアプリのアーキテクチャ
- RAGツールのセットアップ
- データの選択と読み込み
- OctoAIとMixtralでデータを照会する
- まとめ
GitHubのノートブック](https://github.com/ytang07/octoai_milvus/blob/main/MMO_RAG.ipynb)を見つけてください。
MMO(L)オープンソースRAGテックスタック
RAGアプリを構築する方法はたくさんあり、前回の市場調査では、LLMスタックに50種類以上のツールがあることがわかりました。この例では、4つに焦点を当てる:LLMとしてMixtral、ベクトルデータベースとしてMilvus、LLMとエンベッディングモデルを提供するOctoAI、そしてオーケストレータとしてLangChainです。アーキテクチャに入る前に、関係するツールについて少し学んでおこう。
ミクストラル
Mixtral 8x7B、略して "Mixtral "は、フランスのAIスタートアップ Mistral がリリースした最新モデルである。2023年12月に発表され(2024年1月には 論文が発表される)、先行する大規模言語モデル Mistral 7B の大幅な拡張を意味する。Mixtralは8x7BのSparse Mixture of Experts (SMoE)言語モデルであり、オリジナルのMistral 7Bよりも実質的な機能を備えている。より大きくなり、推論時に47Bのパラメータのうち13Bのアクティブパラメータを使用し、複数の言語、コード、32kのコンテキストウィンドウをサポートする。2024年初頭の時点で、MixtralはLLM leaderboardsでトップスコアを獲得したオープンソースモデルである。
ミルバス
私たちのRAGアプリメモリの核心は、ベクトルデータベースです。Milvusは、エンタープライズアプリケーションを対象とした高度にスケーラブルなベクターデータベースです。Milvus固有の分散システム構造により、ベクターの真の生産レベルに近づくにつれて、シームレスなスケーリングが可能になります。Milvusはまた、マルチテナンシー、ロールベースのアクセス制御、高可用性といったエンタープライズ向けの機能も提供しています。
オクトAI
OctoAIは、LLMモデルをプロダクションスケールで実行するためのインフラストラクチャを提供します。OctoAIは、AI開発者がOctoAIのホストモデルを簡単に統合できるようにします。OctoAIのホストモデルには、MixtralやNous Hermesのようなコミュニティファインチューンを含む強力なオープンソースモデルが用意されています。OctoAIの新規登録者の約10人中9人はMixtralをLLMモデルとして選択しており、今日OctoAIのMixtralは顧客のために毎日数十億のトークンを生成しています。このチュートリアルでは、非常に人気のあるMixtralモデルの代わりにGPTを使用します。
ラングチェーン
LangChainは間違いなく市場で最も人気のあるLLMアプリフレームワークです。LangChainは、あなたが想像できるほとんどすべてのツールとの統合を含んでいます。様々な使い方ができますが、この例ではすべてを接続するために使います。LangChainを通してMilvusとOctoAIのエンドポイントをロードし、LangChainを使ってすべてを "チェーン "します。
RAGアプリのアーキテクチャ
各RAGアプリには4つの重要なコンポーネントがあります:LLM、ベクターデータベース、エンベッディングモデル、そしてオーケストレーターです。その下にはインフラレイヤーがあります。このセットアップでは、LLMとしてMixtralを、ベクトルデータベースとしてMilvusを、エンベッディングモデルとしてGTE Largeを、オーケストレータとしてLangChainを、そしてGTE LargeとMixtralにサービスを提供するインフラレイヤーとしてOctoAIを使用しています。
RAGツールのセットアップ
RAGツールのセットアップから始めましょう。このセクションでは、LLMとエンベッディングの推論エンドポイントをセットアップし、ベクトルデータベースをスピンアップします。前提条件のインストールから始めましょう。Milvusと連携するためには pymilvus と milvus が必要である。この例ではLangChainの機能を使うために langchain、sentence-transformers、tiktoken が必要である。最後に、OctoAIの埋め込みAPIとテキスト補完APIと連携するために octoai-sdk も必要である。
MilvusとOctoAIのインポートを含む、LangChainから必要なインポートのほとんどをロードするために、この最初のコードブロックを使います。LLMChainモジュールもロードして、関数をチェーンできるようにし、PromptTemplateモジュールはLLMにプロンプトを渡すのに使う。また、環境変数をメモリにロードする必要がある。これを行う方法はたくさんあるが、この例ではpython-dotenvライブラリのload_dotenv` を使う。
# pip install pymilvus milvus langchain sentence-transformers tiktoken octoai-sdk python-dotenv
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.llms.octoai_endpoint import OctoAIEndpoint
from langchain_community.embeddings import OctoAIEmbeddings
from langchain_community.vectorstores import Milvus
from dotenv import load_dotenv
import os
load_dotenv()
# 以下の行は、OCTOAI_API_TOKENが必要であることを示すためのものです。
os.environ["OCTOAI_API_TOKEN"] = os.getenv("OCTOAI_API_TOKEN")
次のステップはLLMアクセスの初期化です。OctoAIを使うと、ホストされたモデルに簡単にアクセスすることができます。LangChainの OctoAIEndpoint を使い、モデルにアクセスするためのエンドポイント(コードに示されている)を渡します。必要なLLMパラメータも渡す。この例では、モデル名、最大トークン数(出力されるプロンプトの長さ)、その他、モデルに何をさせるか(例:システムプロンプト)、出力をどの程度クリエイティブにするか("presence_penalty"、"temperature"、"top_p")を指定するパラメータを渡します。埋め込みには、OctoAIのエンドポイントURLを渡します。デフォルトでは、GTE Largeを使用します。今後、OctoAIにエンベッディングモデルが追加される予定です。
llm = OctoAIEndpoint(
endpoint_url="https://text.octoai.run/v1/chat/completions"、
model_kwargs={
"model":"mixtral-8x7b-instruct-fp16",
"max_tokens":128,
「presence_penalty": 0:0,
温度0.01,
「top_p":0.9,
「メッセージ":[
{
"role":"system": "システム"、
"content":"あなたは役に立つアシスタントです。可能であれば、回答は1つの短い段落にとどめてください、
},
],
},
)
embeddings = OctoAIEmbeddings(endpoint_url="https://text.octoai.run/v1/embeddings")
最後はベクトルデータベースです。ここでは、ベクトルデータベースとしてMilvus Liteを使用します。Milvusから default_server をインポートし、 start() 関数を呼び出してサーバを起動する。
from milvus import default_server
default_server.start()
データの選択と読み込み
すべての設定が完了したら、いよいよデータをロードします。この例では、GitHub Repoにデータがあります。データを入手したい場合は、Wikipediaからスクレイピングすればよい。データが手に入ったら、次はそれをベクターデータベースにロードします。この作業にはLangChainとMilvusを使います。
これらのドキュメントをロードするためにLangChainから必要な2つのインポートはテキストスプリッター(この場合は CharacterTextSplitter)と Documentである。これで、データディレクトリ全体をLangChainの抽象化である "Documents "のリストとして読み込むことができる。この例では、"data "というタイトルのディレクトリをロードしている。また、Documentsのリストを保持するために空のリストを作成します。
次に、ディレクトリ内の各ファイルをループします。ファイルを読み込み、テキストスプリッターを使ってテキストをチャンクします。この例では、チャンクサイズを512、チャンクの重なりを64としている。これらは単に、通常理にかなっている傾向があるから選んだだけである。結果がどのように異なるか、ご自由に調整してください。
テキストをチャンクしたら、それをいくつかのメタデータとともにドキュメントとして保存する。テキストと一緒に保存するメタデータは、ドキュメントのタイトルと、そのチャンクがドキュメント内のどの位置にあるかを示すチャンク番号です。
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import ドキュメント
files = os.listdir("./data")
file_texts = [] です。
for file in files:
with open(f"./data/{file}") as f:
file_text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64、
)
text = text_splitter.split_text(file_text)
for i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text、
metadata={"doc_title": file.split(".")[0], "chunk_num": i}))
ドキュメントの準備ができたら、いよいよベクターデータベースに挿入します。LangChainのMilvusインテグレーションを使って from_documents 関数を呼び出します。ドキュメント、埋め込みモデル、Milvus Liteインスタンスの接続引数、コレクションの名前を渡します。as_retriever()`メソッドを呼び出すだけで、LLMが追加され、Milvusをベクトルデータベースとして使用することができます。
vector_store = Milvus.from_documents(
file_texts、
embedding=embeddings、
connection_args={"host":"localhost", "port": default_server.listen_port}、
コレクション名="都市"
)
retriever = vector_store.as_retriever()
OctoAIとMixtralを使ってデータを照会する
すべての準備が整いました。これでLangChainを使って、パズルの一部を検索するオーケストレーションができる。まずLangChainにテンプレートを渡します。プロンプトテンプレートに2つの変数を渡す必要があります。テンプレートの文字列をf-stringのように扱い、それを PromptTemplate から from_template 関数に渡します。
テンプレートの後、"チェーン "部分をセットアップする。コンテキストを渡すために RunnablePassthrough モジュールが必要で、出力をパースするために StrOutputParser モジュールが必要である。それから、チェーンをセットアップする。まず、LangChainにコンテキストと質問を取得する場所を伝え、次にそれらをプロンプトにパイプし、LLMにパイプし、最後に文字列出力パーサーにパースさせます。質問をするには、単純にチェーンをinvokeします。
template = """以下のコンテキストのみに基づいて質問に答えます:
{コンテキスト}
質問{質問}
"""
prompt = PromptTemplate.from_template(template)
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever, "question":RunnablePassthrough()} {"context": retriever
| プロンプト
| プロンプト
| StrOutputParser()
)
chain.invoke("シアトルの街の大きさは?")
シアトルの街の大きさは?"の例では、以下のような出力が期待されます。レスポンスは正確で、ベクター・データベースに保存したウィキペディアの情報に裏付けられている。

オクトAIによるMixtralの多言語機能の活用

Mixtralを使っているのだから、多言語の専門知識など、ユニークな機能を活用しよう。OctoAIを使う良い点は、同じエンドポイントを異なる命令で活用し、異なることができることです。この場合、英語ではなくフランス語で答えるようにモデルに指示します。
# 他のオープンソースモデルを凌駕するMixtalの多言語機能を紹介しましょう。
# 私たちのベクターDBには英語のテキストが入力されています。
# は英語のテキストで最もよく機能します。しかし、Mixtralはフランス語、ドイツ語、スペイン語、イタリア語の多言語機能を備えています。
しかし, Mixtralはフランス語, ドイツ語, # スペイン語, # イタリア語に対応した優れた多言語能力を持っています.ここでのRAGは
# RAG は英語のテキストに基づいて実行されますが、ユーザーの回答を生成すると、Mixtral LLM は異なる言語(フランス語)のトークンを生成します。
llm = OctoAIEndpoint(
endpoint_url="https://text.octoai.run/v1/chat/completions"、
model_kwargs={
"model":"mixtral-8x7b-instruct-fp16",
"max_tokens":128,
「presence_penalty": 0:0,
"温度":0.1,
「top_p":0.9,
「メッセージ":[
{
"role":"system": "システム"、
"content":"あなたは英語ではなくフランス語で応答する親切なアシスタントです、
},
],
},
)
また、Mixtralにフランス語で答えてもらうために、少し修正したテンプレートを使います。プロンプトは新しいテンプレートから作り直す必要があり、チェーンは新しいプロンプト、テンプレート、LLMから作り直す必要があります。チェーンは同じように呼び出すことができます。英語で同じ質問をし、フランス語での応答を期待する。
template = """以下のコンテキストのみに基づいてフランス語で質問に答えます:
{コンテキスト}
質問{質問}
"""
prompt = PromptTemplate.from_template(template)
chain = (
{"context": retriever, "question":RunnablePassthrough()}を実行する。
| プロンプト
| プロンプト
| StrOutputParser()
)
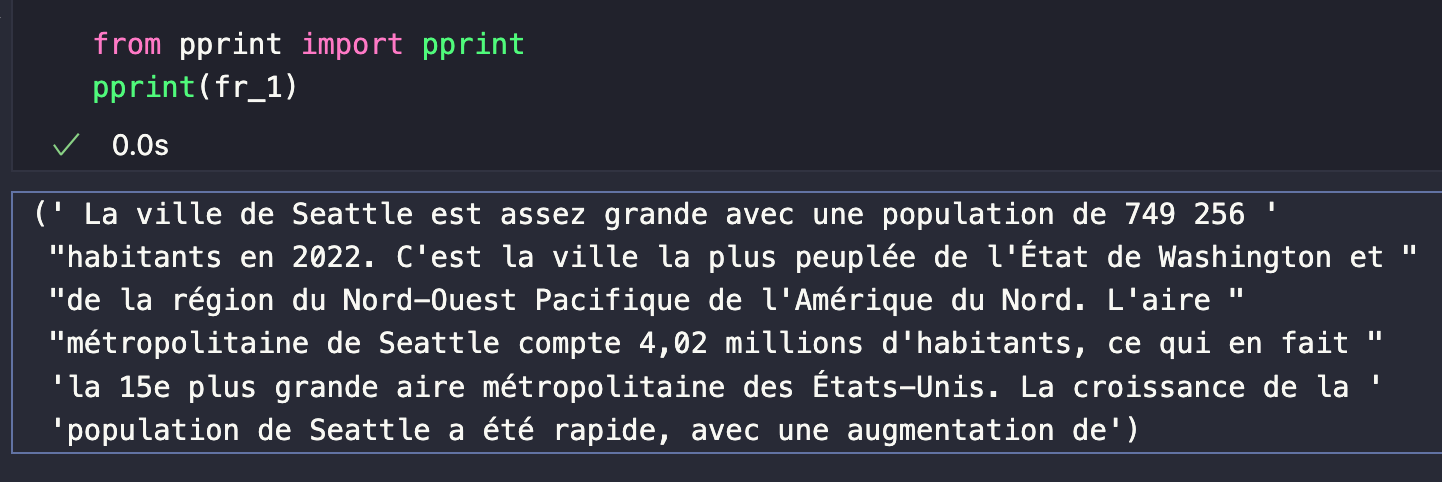
chain.invoke("シアトルの街の大きさは?")
レスポンスは以下の画像のようになるはずだ。
要約
このチュートリアルでは、OpenAIを使わずにRAGを構築する別の方法を探りました。パート1](https://zilliz.com/blog/building-rag-apps-without-openai-part-I)では、LLMとしてSymbl.AIを使いましたが、今回はOctoAIがホストするMistralのMixtralを使いました。RAGフレームワークの他の部分としては、ベクトルデータベースとしてMilvus、オーケストレータとしてLangChain、埋め込みモデルとして同じくOctoAIがホストしているGTE-Largeを使用しました。
RAGツールをセットアップし、サンプルデータとしてWikipediaを読み込む。そして、LangChainを使ってデータをMilvusに読み込み、"le big model "を重ねる。最後に、Mixtralのユニークな機能の一つである、多言語での作業能力についても時間をかけて調べました。この例では、フランス語を使いました。次回は、他の言語も試してみましょう!

読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.