




本番環境のRAGで知っておくべきコンテキストエンジニアリング技術トップ10
RAGやエージェントのデモを最初に構築するとき、たいていはうまく動きます。小さなデータセット、いくつかのプロンプト、そしてシンプルな検索があれば、数時間でプロトタイプを動かせることもよくあります。
本当の課題は、そのシステムを本番環境で動かそうとしたときに現れます。利用が増えるにつれて、問題はすぐに表面化します。検索は遅くなり、回答の信頼性は下がり、レイテンシは増え、コストも上がります。小さなデモで機能していたものは、実データ、実ユーザー、そしてより長いコンテキストが関わると、しばしば破綻します。
この時点で、問題はモデルだけではないことに気づくのが普通です。モデルに渡すコンテキストをどのように準備し、渡すかも重要です。ここで コンテキストエンジニアリング が登場します。これは、言語モデルが回答を生成するために使用する情報を検索し、整理し、洗練し、管理することに焦点を当てます。
この記事では、コンテキストエンジニアリングが実際にどのように機能するかを説明します。コンテキストを構築し、効率的に処理し、時間の経過とともに管理するための最近のアプローチを見ていきます。これらの手法は、シンプルなデモを、本番環境で安定して動作できるシステムへと発展させるのに役立ちます。
注: この記事は主に論文 https://arxiv.org/html/2507.13334v1に基づいています。
コンテキストエンジニアリングとは?
コンテキストエンジニアリングは、大規模言語モデルが質問にうまく答えるために必要な情報を組み立てることに焦点を当てます。この情報はプロンプトに限定されません。ユーザーのクエリ、検索されたドキュメント、会話履歴、その他の関連データも含まれます。目的は、精度を向上させ、応答時間を短縮し、コストを制御することです。
この作業は主にアルゴリズムによって自動的に行われます。コンテキストエンジニアリングは、プロンプトエンジニアリング、検索拡張生成(RAG)、マルチエージェント技術を、別々に使うのではなく、1つのシステムに統合します。
実際には、コンテキストエンジニアリングの構成には2つの部分があります。1つ目は、データ検索、処理、オーケストレーションを担う 基盤コンポーネント です。2つ目の層は、これらのコンポーネントを完全なアプリケーションへと組み合わせる、より 複雑なシステム で構成されます。チームは、さまざまな本番シナリオに合わせて、これらの部品を組み合わせたり再利用したりできます。
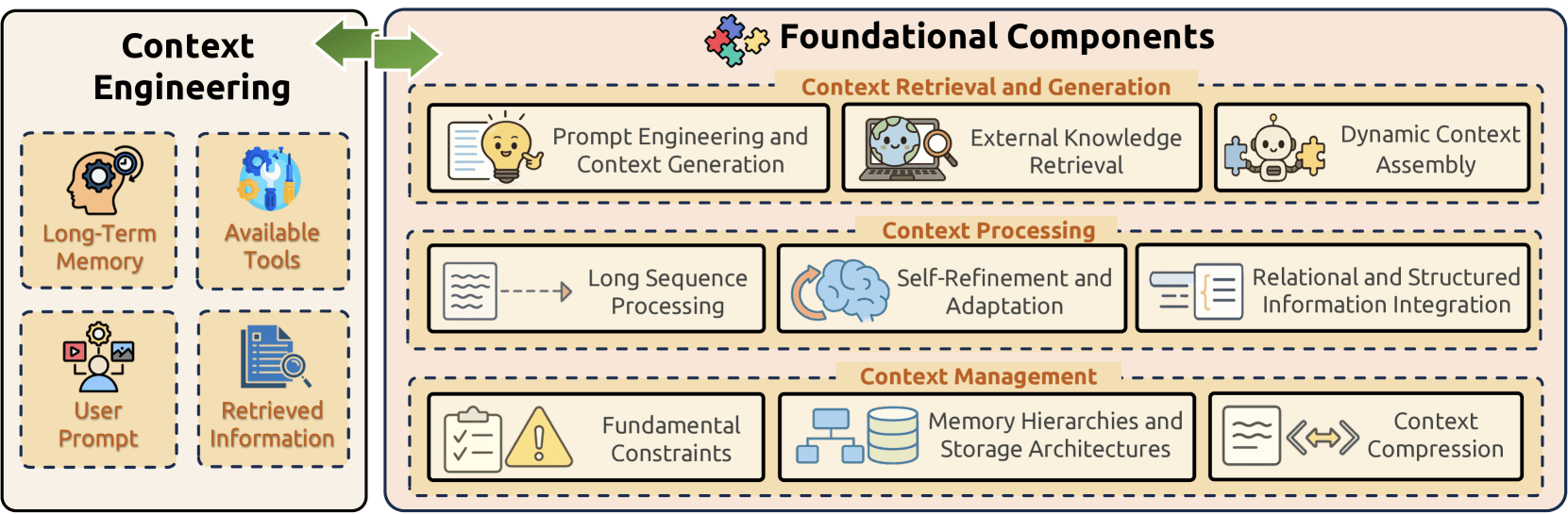
基盤コンポーネント
コンテキストエンジニアリングは、大規模言語モデルにおける情報管理の中核的な課題にまとめて対処する、3つの基本コンポーネントの上に構築されています。
- コンテキスト検索と生成 は、プロンプトエンジニアリング、外部知識検索、動的なコンテキスト組み立てを通じて、適切なコンテキスト情報を取得します。
- コンテキスト処理 は、長いシーケンスの処理、自己改善メカニズム、構造化データ統合を通じて、取得した情報を変換し最適化します。
- コンテキスト管理 は、根本的な制約への対処、高度なメモリ階層の実装、圧縮技術の開発を通じて、コンテキスト情報の効率的な整理と活用に取り組みます。
実践における複雑なシステム
これらの基盤コンポーネントの上で、コンテキストエンジニアリングはいくつかの一般的なタイプの複雑なシステムを通じて適用されます。
検索拡張生成(RAG) により、モデルは質問に答える前にナレッジベース内の情報を参照できます。これにより、モデルが推測するのではなく、実際の最新データに基づいた回答であることを確保しやすくなります。実際には、RAGはシンプルなモジュール型パイプラインとして構築することも、検索を制御するエージェントによって駆動することも、より豊かなコンテキストのためにナレッジグラフと組み合わせることもできます。
メモリシステム は、モデルが複数のやり取りにわたって情報を追跡できるようにします。短期メモリは現在の会話の詳細を保持し、長期メモリは過去の会話や学習した知識を保存します。これにより、複数ターンの会話の一貫性が高まり、システムが時間とともに改善されやすくなります。
ツール統合型推論 により、モデルはテキスト推論のみに頼るのではなく、計算機、検索エンジン、API などの外部ツールを使用できます。この仕組みで重要なのは、ツールの結果を適切なタイミングでコンテキストに挿入し、モデルがそれらを効果的に利用できるようにすることです。
マルチエージェントシステム は、複雑なタスクを処理するために連携して動作する複数のモデルを使用します。各エージェントには特定の役割があり、システムはそれらがどのように通信し、情報を共有し、同期を保つかを調整して、一貫した結果を生成します。
コンテキスト処理
先ほど、コンテキストエンジニアリングの3つの主要部分である コンテキスト検索と生成、コンテキスト処理、コンテキスト管理 を紹介しました。これらは実用的なコンテキストシステムの基本的な構成要素です。
コンテキスト処理 は特に重要です。取得された生の情報を受け取り、モデルがより効率的に理解して利用できるように、整理し、形を整え、構造化します。
このセクションでは、実際のシステムでコンテキスト処理がどのように行われるか、そしてどのようなアプローチが一般的に使用されているかを見ていきます。
長いコンテキストの処理
非常に長いコンテキストの処理は高コストです。なぜなら、Transformer モデルは自己注意を使用しており、入力長が増えるにつれてスケーリングが悪化するためです。シーケンスが長くなるほど、計算量とメモリ使用量が急速に増加し、本番システムにおいて実際のボトルネックを生み出します。
たとえば、Mistral-7B の入力長を 4K から 128K トークンに拡張すると、計算コストは約 122倍に増加します。メモリ使用量も、プリフィルとデコードの両方で急激に増加します。実際には、Llama 3.1 8B のようなモデルでは、単一の 128K トークンリクエストに最大 16 GB のメモリが必要になる場合があります。
これらの制限を回避するために、研究者は主に3つのアプローチを使用しています。
1つ目は、Mamba のような、設計上より低コストで実行できる新しいモデルアーキテクチャを構築することです。もう1つは、位置補間のような技術を使用して、既存のモデルがはるかに長い入力を処理できるようにすることです。3つ目のアプローチは、冗長な作業を避け、メモリをより効率的に使用することで計算方法を改善し、長いコンテキスト処理をより高速かつ少ないリソースで行えるようにします。
(1) 長いコンテキストのためのアーキテクチャ革新
Transformer の二次コストに対処するため、研究者は長いシーケンス処理をより低コストかつ効率的にする新しいモデルアーキテクチャを開発してきました。
- 状態空間モデル(SSM) は、固定サイズの隠れ状態を通じて線形の計算量と一定のメモリ要件を維持し、Mamba のようなモデルは、従来の Transformer よりも効果的にスケールする効率的な再帰計算メカニズムを提供します。
- 拡張注意 のアプローチである LongNet は、トークン距離が増えるにつれて指数関数的に拡大する注意領域を採用し、トークン間の対数的依存関係を維持しながら線形の計算量を実現し、10億トークンを超えるシーケンスの処理を可能にします。
- Toeplitz Neural Networks(TNN) は、相対位置がエンコードされた Toeplitz 行列でシーケンスをモデル化し、時空間複雑性を対数線形に削減し、512 個の訓練トークンから 14,000 個の推論トークンへの外挿を可能にします。
- 線形注意 メカニズムは、自己注意をカーネル特徴マップの線形内積として表現することで、計算量を O(N²) から O(N) に削減し、非常に長いシーケンスを処理する際に最大 4000倍の高速化を実現します。
非注意 LLM のような代替アプローチは、再帰メモリ Transformer やその他のアーキテクチャ革新を採用することで、二次的な障壁を突破します。
(2) 位置補間とコンテキスト拡張
位置補間技術は、未知の位置へ外挿するのではなく、位置インデックスを賢く再スケーリングすることで、モデルが元のコンテキストウィンドウの制限を超えたシーケンスを処理できるようにします。
- ニューラルタンジェントカーネル(NTK)アプローチは、コンテキスト拡張のための数学的に根拠のあるフレームワークを提供し、YaRN(Yet another RoPE-based Interpolation method)はNTK補間と線形補間およびアテンション分布補正を組み合わせています。
- 2段階アプローチ: LongRoPEは2段階アプローチにより2048Kトークンのコンテキストウィンドウを実現します。まずモデルを256K長にファインチューニングし、その後、最大コンテキスト長に到達するために位置補間を行います。
- 位置系列チューニング(PoSE)は、複数の位置補間戦略を組み合わせることで、最大128Kトークンまでの印象的な系列長拡張を示しています。
- Self-Extend 技術は、グループ化アテンションと近傍アテンションという二段階アテンション戦略を採用して、遠隔および隣接トークン間の依存関係を捉えることで、ファインチューニングなしにLLMが長いコンテキストを処理できるようにします。
(3) 効率的処理のための最適化技術
中核となるモデルアーキテクチャを変更することなく、研究者たちは長文コンテキスト処理をより効率的にするためのさまざまな最適化技術も開発してきました。
Grouped-Query Attention(GQA)は、クエリヘッドをグループに分割し、キーおよびバリューヘッドを共有させることで、マルチクエリアテンションとマルチヘッドアテンションのバランスを取りながら、デコード中のメモリ要件を削減します。
FlashAttentionは、非対称なGPUメモリ階層を活用して、二次関数的な要件ではなく線形のメモリスケーリングを実現し、FlashAttention-2では非行列乗算演算の削減と最適化された作業分配により、およそ2倍の速度を提供します。
Ring Attention with Blockwise Transformersは、Blockwise Transformersを用いて複数デバイスに計算を分散し、ブロック単位の計算を活用しつつ通信をアテンション計算と重ね合わせることで、極めて長い系列の処理を可能にします。
疎アテンション技術には、LongLoRAにおけるShifted sparse attention(S²-Attn)やSF-Attnを用いたSinkLoRAが含まれ、これらは大幅な計算量削減とともに、フルアテンションのパープレキシティ改善の92%を達成します。
メモリ管理とコンテキスト圧縮は、長い入力のコストを削減します。Rolling Buffer Cacheはアテンションウィンドウを制限してKVキャッシュメモリを縮小し、StreamingLLMは重要なトークンと直近のコンテキストのみを保持することで長い系列をサポートします。Infini-attentionやH2Oのような他の手法は、圧縮メモリとより賢いキャッシュ削除によって効率を改善します。
文脈的自己洗練と適応
自己洗練により、LLMは人間の推敲プロセスを反映した循環的フィードバック機構を通じて出力を改善でき、強化学習アプローチとは異なるプロンプトエンジニアリングを介した対話的な自己相互作用によって自己評価を活用します。
考え方はシンプルです。複雑なタスクでは、すべてを一度で正しく行うよりも、最初のバージョンを書いてから修正するほうが簡単です。モデルが自分の作業を確認し、段階的に改善することを学ぶと、推論、コード作成、創造的タスクでより良い性能を発揮し、新しい状況にもより容易に適応します。
(1) 基礎的な自己洗練フレームワーク
- Self-Refine フレームワークは、同じモデルを生成器、フィードバック提供者、洗練器として使用し、完全な初期解を生成するよりも、エラーを特定して修正するほうがしばしば容易であることを示しています。
- Reflexion は、言語的フィードバックを通じた将来の意思決定のために、エピソード記憶バッファに内省的テキストを保持します。一方で、単純なプロンプティングでは信頼性の高い自己修正を可能にできないことが多いため、構造化されたガイダンスが不可欠であることが示されています。
- N-CRITICS フレームワークは、初期出力を生成LLMと他のモデルの両方が評価するアンサンブルベースの評価を実装し、タスク固有の停止基準が満たされるまで、まとめられたフィードバックが洗練を導きます。
(2) メタ学習と自律的進化
より高度な段階では、コンテキストの自己洗練はメタ学習と自律的改善に焦点を当てます。その目標は、モデルがタスクを解くだけでなく、時間とともによりよく学ぶ方法も学べるようにすることです。
SELF は、限られた例でLLMにメタスキル(自己フィードバック、自己洗練)を教え、その後、モデル自身の訓練データを生成・フィルタリングすることで継続的に自己進化させます。自己報酬メカニズムにより、単一のモデルが実行者と審判という二重の役割を担い、自らに割り当てる報酬を最大化する反復的な自己判断を通じて、モデルが自律的に改善できるようになります。
Creator フレームワークは、作成、意思決定、実行、認識を含む4つのモジュールからなるプロセスを通じて、LLMが独自のツールを作成し使用できるようにすることで、このパラダイムを拡張します。
Self-Developing フレームワークは、最も自律的なアプローチを表しており、実行可能なコードとしてアルゴリズム候補を生成する反復サイクルを通じて、LLMが自らの改善アルゴリズムを発見、実装、洗練できるようにします。
マルチモーダルコンテキスト
マルチモーダル大規模言語モデル(MLLM)は、画像、音声、3Dデータのような入力を扱うことで、テキストを超えます。これらの異なる種類の情報を、モデルが推論できる単一のコンテキストに統合します。
これにより、より高度なアプリケーションが可能になりますが、異なるモダリティの統合、それらをまたいだ推論、長く複雑な入力の処理といった新たな課題も生じます。
(1) マルチモーダルコンテキスト統合
コンテキスト統合は、マルチモーダルコンテキスト処理の中核です。画像、テキスト、音声など、異なるモダリティからの情報を、モデルが推論に使える単一の表現へ統合することを目的としています。
基本的なアプローチでは、CLIPのようなエンコーダを使用して画像をトークンに変換し、その後、すべてを言語モデルに送る前にテキストトークンに追加します。これは実装が容易ですが、異なるモダリティはしばしば緩やかにつながったままになります。
より高度な手法は統合を改善します。クロスモーダルアテンションにより、モデルは内部で視覚トークンとテキストトークンの直接的な関係を学習でき、これは画像編集や視覚推論のようなタスクに重要です。
長い入力や複雑な入力に対応するため、階層的な設計では各モダリティを段階的に処理します。一部のシステムでは、それぞれを個別に処理する代わりに、複数の画像や入力からの情報をモデルに渡す前に統合することもあります。
その他の研究では、テキスト専用モデルを適応させること自体を避け、最初からマルチモーダルデータとテキストを一緒に訓練します。クロスモーダル推論はこれを基盤とし、モデルが各モダリティを単独で理解するだけでなく、画像とテキストの両方を通じて表現される皮肉のように、それらが組み合わされたときに生じる意味も理解することを求めます。
(2) 外部マルチモーダルエンコーダとアライメントモジュール
マルチモーダルコンテキスト統合は、主に2つの部分、すなわち外部マルチモーダルエンコーダ と、それらを言語モデルに接続するアライメントモジュール の上に構築されています。
現在のほとんどのシステムでは、各種類のデータは専用のエンコーダによって処理されます。たとえば、画像はCLIPのようなモデルで処理され、音声はCLAPのようなモデルで扱われます。これらのエンコーダは、ピクセルや音波のような生の入力を特徴ベクトルに変換します。
次にアライメントモジュールは、これらの特徴を言語モデルの埋め込み空間へ変換し、テキストトークンと一緒に機能できるようにします。一部のシステムはMLPのような単純なマッピングを使用し、他のシステムは、学習可能なクエリトークンを使用してテキストに最も関連する視覚特徴を選択するQ-Formerを使用します。
このモジュール式の構成により、システムの保守が容易になります。エンコーダは、言語モデル全体を再訓練することなく更新または交換できるため、実世界での展開において重要です。
関係的および構造化コンテキスト
大規模言語モデルは、テキストベースの入力要件と逐次的アーキテクチャの制限により、表、データベース、知識グラフを含む関係的および構造化データを処理する際に根本的な制約に直面します。
線形化は、複雑な関係や構造的特性を保持できないことが多く、情報がコンテキスト全体に分散している場合には性能が低下します。
この問題を解決するために、研究者たちは、言語モデルが利用できる形式で構造化データを表現する方法を探ってきました。その目的は、複雑な推論やファクトチェックを伴うタスクでモデルの性能を向上させることです。
(1) 知識グラフ埋め込みとニューラル統合
高度なエンコーディング戦略は、エンティティと関係を数値ベクトルに変換する知識グラフ埋め込みによって構造的な制約に対処し、言語モデルアーキテクチャ内での効率的な処理を可能にします。
グラフニューラルネットワークは、エンティティ間の複雑な関係を捉え、GNNコンポーネントをトランスフォーマーブロックと並べて組み込むGraphFormersのような特殊なアーキテクチャを通じて、知識グラフ構造全体にわたるマルチホップ推論を促進します。
(2) 言語化
一般的なアプローチの1つは、知識グラフ、表、データベースレコードなどの構造化データを自然言語テキストに変換し、既存の言語モデルのアーキテクチャを変更せずに直接利用できるようにすることです。他の方法では、言語的関係に基づいて入力テキストを構造化された層に再編成したり、重要な情報を抽出してグラフ、表、または関係スキーマとして明示的に表現したりします。
場合によっては、構造化データをプログラミング言語で表現する方が、自然言語よりもうまく機能します。たとえば、知識グラフにPythonコードを使用したり、データベースにSQLを使用したりすると、構造がより明確に保持されるため、複雑な推論タスクでより高い性能につながることがよくあります。また、少ないパラメータで構造化データを扱いながら良好な性能を維持するために、コンパクトな行列表現を使用するリソース効率の高いアプローチもあります。
(3) ハイブリッドアーキテクチャ
表や知識グラフのような複雑な関係を持つ構造化データを扱うために、研究者たちは、大規模言語モデルと、グラフニューラルネットワークなどのグラフ構造データ向けに設計されたコンポーネントを組み合わせるハイブリッドアーキテクチャを探求してきました。
いくつかの実用的なアプローチが用いられています。GraphTokenは、特殊トークンを追加することで関係を明示化し、モデルがグラフ上で推論するのを助けます。Heterformerは、1つのフレームワーク内でテキストとグラフ構造を一緒に処理し、計算コストを制御しながら関係情報を保持します。
他の方法では、異なる形で知識を統合します。K-BERTは、学習時に知識グラフ情報を追加することで、モデルがこれらの関係を事前に学習できるようにします。KAPINGは、再学習なしに推論時に関連知識を取得します。より高度な設計では、アダプターとアテンションを使用してグラフ情報をモデルに直接融合し、より密接な統合を実現します。
結論
コンテキストエンジニアリングは、本番環境でLLMシステムがどのように機能するかを理解するための有用な方法を提供します。一般に、それは主に3つのプロセス、すなわちコンテキストの取得と生成、コンテキスト処理、そしてコンテキスト管理を含みます。これらのステップが一体となって、情報がどのように収集され、準備され、モデルに渡されるかを決定します。
その中でも、コンテキスト処理は、取得された情報がモデルに届く前にどのように整理、組織化、圧縮されるかを決定するため、特に重要です。紙幅の制約により、この記事では主にこの部分に焦点を当て、実際のシステムで使用されるいくつかのアプローチを概観しました。検索とコンテキスト管理も重要な領域であり、今後の議論でさらに探求できます。
RAGやエージェントシステムを構築していて、コンテキスト、コスト、レイテンシに関する本番環境の課題に直面している場合は、Slack Channelに参加して、他のエンジニアとコンテキストエンジニアリングについて議論してください。また、Milvus Office Hoursを通じて、デモから本番対応システムへ移行するための実践的なガイダンスを得られる短い1対1のセッションを予約することもできます。
読み続けて

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.