




Scalable and Reliable: A Simple Guide to Distributed Computing
Scalable and Reliable: A Simple Guide to Distributed Computing
Distributed computing is the practice of running tasks or processes across multiple connected computers to boost performance, scalability, and reliability. Instead of relying on one powerful machine, the workload is split among several nodes, which can handle larger data sets and computations more efficiently. This approach forms the backbone of many modern data-driven applications, including e-commerce platforms, machine learning pipelines, real-time analytics, IoT sensor networks, and high-performance research simulations.
 Distributed Computing
Distributed Computing
Figure: Distributed Computing
From Single Servers to Distributed Systems: The Evolution
For a long time, many organizations relied on large, centralized servers—often called monolithic architectures to run their applications. However, this setup came with some clear drawbacks:
Limited scalability: Adding more capacity meant buying bigger servers, which was expensive and time-consuming.
Single point of failure: The entire system would stop if the main server went down.
Complex updates: Making changes or upgrades was risky because everything was housed in one place.
Clusters, which group smaller servers together, provided some relief but still didn’t fully solve the scaling and reliability issues. That’s where distributed computing stepped in. By dividing tasks and data across multiple connected nodes, distributed systems:
Scale faster and more affordably: You can add more nodes instead of replacing a single large server.
Improve fault tolerance: If one node fails, others can keep the system online.
Handle heavy workloads: Multiple nodes working together can process large volumes of data more efficiently.
Modern solutions like Milvus from Zilliz build on these principles to manage vast amounts of high-dimensional data. Milvus supports large-scale similarity searches by distributing data across multiple nodes and maintains high performance, even under demanding conditions.
How does Distributed Computing Work?
Distributed computing is a model where multiple machines (or nodes) work together to accomplish tasks that would be difficult or inefficient to handle on a single machine. Each node in a distributed system can perform specific functions, such as storing data or processing computation, and the system coordinates these tasks to operate as a unified whole. Hence, this approach leads to higher performance, better fault tolerance, and flexible scaling options.
Core Principles
Task Distribution: The main idea behind distributed computing is to break large jobs into smaller tasks and assign them to various nodes. By dividing workloads, each node can work on its piece in parallel, which speeds up processing and prevents any one machine from becoming overloaded.
Data Partitioning: The data is split into segments (often called “shards”). Each node stores one or more of these segments for parallel reads and writes. This speeds up data access and makes it easy to scale: when the data grows, you add more nodes and partition it further.
Synchronization and Coordination: Because tasks and data are spread out, it becomes critical that nodes stay in sync to prevent conflicting updates. Distributed systems use protocols and algorithms, such as consensus mechanisms, to ensure that each node maintains a consistent data view. These methods help all parts of the system agree on changes, even when they occur simultaneously.
Components of Distributed Systems
 Components of Distributed System
Components of Distributed System
Figure: Components of Distributed System
Nodes (or Hosts): Each node runs tasks or stores data. In many cases, nodes can be physical servers, virtual machines, or containers. When using a system like Milvus, each node can hold a segment of the vector index, enabling distributed searches across large datasets without overwhelming any single machine.
Network: The network is the glue that connects all nodes. It carries data and messages between machines to share results and update one another. Reliable and fast network connections are vital for seamless communication.
Load Balancers:When multiple nodes are ready to accept incoming requests, load balancers distribute the traffic evenly. This prevents any node from handling too many requests at once. By spreading the load, the system can handle spikes in traffic and maintain steady performance.
Database Server: A database server is responsible for storing, managing, and retrieving structured or unstructured data across multiple nodes. In a distributed architecture, databases can be sharded (dividing data into smaller chunks across various nodes) or replicated (keeping copies of data across nodes for fault tolerance).
Message Queues and Coordination Services: Distributed systems often rely on messaging tools (like Apache Kafka or NATS) or coordination services (like ZooKeeper) to manage node communication. These tools help schedule tasks, track progress, and make sure that two nodes are not performing the same work simultaneously. They also handle system-wide announcements—such as when a node comes online or goes offline, so the rest of the system can adapt.
Types of Distributed Computing Architectures
Distributed computing can take many forms, depending on how nodes interact and share responsibilities. Below are some common architectures, along with examples of how they work in different scenarios, including the Milvus database. Choosing the right distributed architecture depends on workload size, latency requirements, and cost constraints.
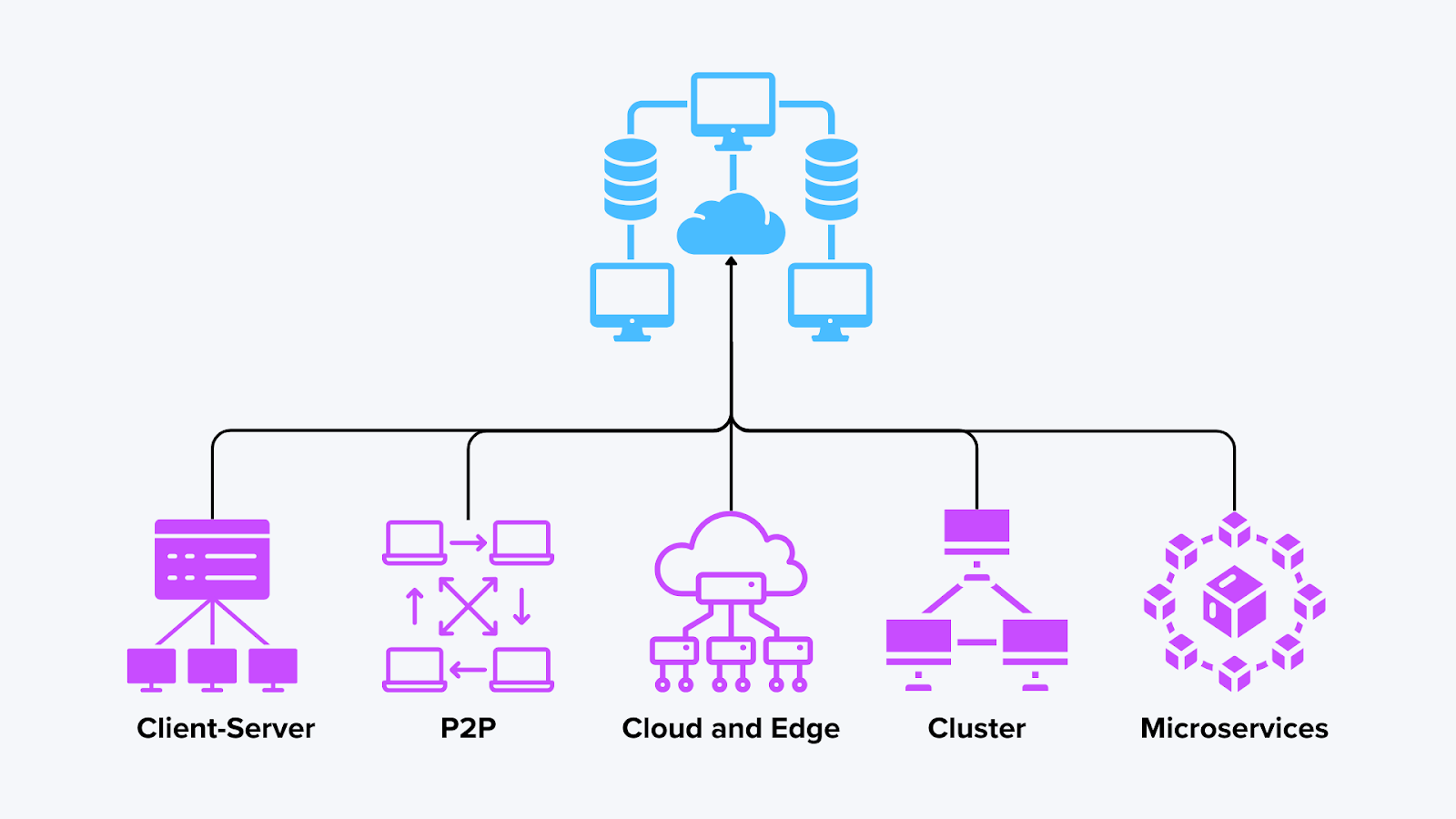 Types of Distributed Computing
Types of Distributed Computing
Figure: Types of Distributed Computing
1. Client-Server Model
In the client-server model, one or more central servers handle requests from multiple client devices. Each server is typically more powerful than an individual client and hosts the main business logic or data storage. The clients send requests (such as fetching data or running computations), and servers respond with the requested information or results.
Pros: Clear separation of roles, centralized control, and simplified security management.
Cons: Clients may lose access to the service if a server goes down. Scaling can also be challenging if requests exceed the server’s capacity.
2. Peer-to-Peer (P2P) Networks
Peer-to-peer architectures treat all nodes as equals. Each node can act as both a client and a server, sharing resources or files without relying on a central server. In this architecture, nodes connect directly to each other. Instead of requesting data from a single authoritative server, peers exchange data among themselves.
Pros: There is no single point of failure, and scaling by adding more peers can be easier.
Cons: Managing data consistency and quality of service can be difficult in fully decentralized environments.
3. Cluster Computing
A cluster is a group of servers that work together so closely that they appear as a single system. Tasks can be split across nodes for parallel processing, making cluster computing popular for high-performance workloads. Servers in a cluster often share storage, and tasks are divided among them by a scheduling system or load balancer. If one server fails, the others can continue operating.
Milvus Architecture: Milvus uses clustered nodes to manage large volumes of vector data. Distributing vector indexes across multiple machines can efficiently handle billions of high-dimensional vectors. This clustering approach boosts performance and resilience, especially when dealing with massive search or recommendation workloads.
Pros: Great for parallel processing and fault tolerance.
Cons: It can be complex to manage and require higher hardware investments.
4. Cloud and Edge Computing
Cloud computing provides on-demand resources (like virtual machines, storage, and services) over the Internet. Edge computing places processing and data storage closer to the data source (e.g., IoT devices) to reduce latency. In cloud computing, organizations run applications on remote servers maintained by cloud providers. Capacity is typically scalable on short notice. In edge computing, data generated by devices is processed locally or in nearby edge data centers, reducing the need to send everything to a central cloud.
Pros: Elastic scaling, flexibility, and potentially lower operational costs. Edge setups also improve responsiveness for time-sensitive tasks.
Cons: Requires stable network connections (in the case of cloud computing), and edge devices may have limited resources.
5. Microservices
Microservices break an application into smaller, loosely coupled services that communicate over a network. Each service handles a specific function, such as user authentication or data indexing. Services can run on separate machines or containers. They expose APIs for communication and can scale independently to match their specific workload.
Pros: It simplifies updates, as each service can be changed without affecting the entire system. It also allows for specialized scaling, where only the most heavily used services receive additional nodes.
The cons are that it adds complexity to managing many services while ensuring smooth functioning. Monitoring, logging, and deploying updates require careful planning.
Use Cases of Distributed Computing
Distributed computing has a wide range of modern solutions. Below are some of the most common scenarios where organizations benefit from splitting workloads and data among interconnected nodes:
Big Data Analytics and Real-Time Processing: Organizations run large datasets in parallel across multiple nodes to speed up analysis. Data keeps flowing in, and updates happen almost instantly. This is crucial in the finance, healthcare, and e-commerce sectors, where quick insights guide decisions.
Machine Learning and AI Model Training: Complex models are trained faster when computations run on many machines simultaneously. This setup efficiently handles large feature sets and trims overall training time. It’s common in image recognition, NLP, and personalized recommendations.
High-Traffic Web Applications and E-Commerce: Requests are spread across multiple servers, so no single machine gets overwhelmed. If one server fails, the rest keep running to avoid heavy downtime. With flexible scaling, sudden spikes like holiday sales are easier to handle.
Internet of Things (IoT) and Sensor Networks: Numerous sensors feed data into distributed nodes, which process it close to the source for quicker responses. This localized approach improves monitoring and helps with real-time alerts. It’s widely adopted in smart cities, manufacturing, and connected vehicles.
Scientific Research and High-Performance Computing (HPC): Heavy tasks like climate simulations are split into smaller jobs that run in parallel. This drastically shortens calculation times and supports global scientific collaborations. Researchers can refine models faster and push innovation forward.
Content Delivery Networks (CDNs): Store files and media on servers worldwide, allowing users to access content from the closest node. This setup reduces load times and network delays, making it vital for streaming services, large file downloads, and high-traffic websites.
Benefits of Distributed Systems
Organizations turn to distributed systems to handle ever-growing data and computational tasks. Below are some key advantages that help teams scale, stay resilient, and work more efficiently:
Scalability and Resource Sharing: Distributed architectures let organizations add more machines as workloads grow rather than relying on one large server. The system avoids bottlenecks and improves throughput by splitting data and tasks across multiple nodes.
Fault Tolerance and Redundancy: When critical data and tasks are replicated across multiple nodes, the system can keep running even if one node fails. This design reduces downtime and preserves user access.
Flexible and Modular Design: Distributed systems often divide tasks into smaller, independent modules. Each node handles specific duties, making updating or replacing components easier without disrupting the entire environment.
Balancing Consistency and Availability (CAP Theorem):** It’s tough for distributed systems to be fully consistent and always available at once, especially when network issues occur. The exact trade-off depends on how critical immediate consistency is for each use case.
Improved Performance and Throughput: By running tasks in parallel, distributed systems can process more operations in less time. This is essential for big data analysis or real-time vector searches.
Challenges and Considerations
While distributed systems offer many advantages, they also introduce unique complexities. Below are some common obstacles and factors to keep in mind when building and maintaining distributed infrastructures:
Network Latency and Bandwidth Limits: Tasks that span distant servers can slow down if network connections are weak or overloaded. When bandwidth is limited, large data transfers might face bottlenecks. Placing nodes closer to users or caching data can help reduce latency.
Data Consistency and Partition Tolerance: Keeping everything in sync can be challenging when data is stored on multiple nodes. Network failures or node outages introduce conflicts that require careful handling. Some systems favor quick updates, while others prioritize strict accuracy.
Security and Data Privacy: Data moves between machines, increasing the risk of leaks or unauthorized access. Encryption and strict access controls help safeguard sensitive information. Regular audits and compliance checks ensure that user data stays protected.
Managing Distributed Transaction: A single transaction may involve several services or nodes, complicating coordination. Protocols like two-phase commit or transaction managers track these steps. Careful rollback strategies prevent partial failures from corrupting data.
Introducing Milvus: A Distributed, Cloud-Native Vector Database
Milvus is designed from the ground up as a cloud-native, distributed system for managing high-dimensional vector data. By splitting data and processing across multiple nodes, Milvus delivers the core benefits of distributed computing—scalability, fault tolerance, and parallel execution—making it well-suited for AI model training, real-time recommendation systems, and complex analytics.
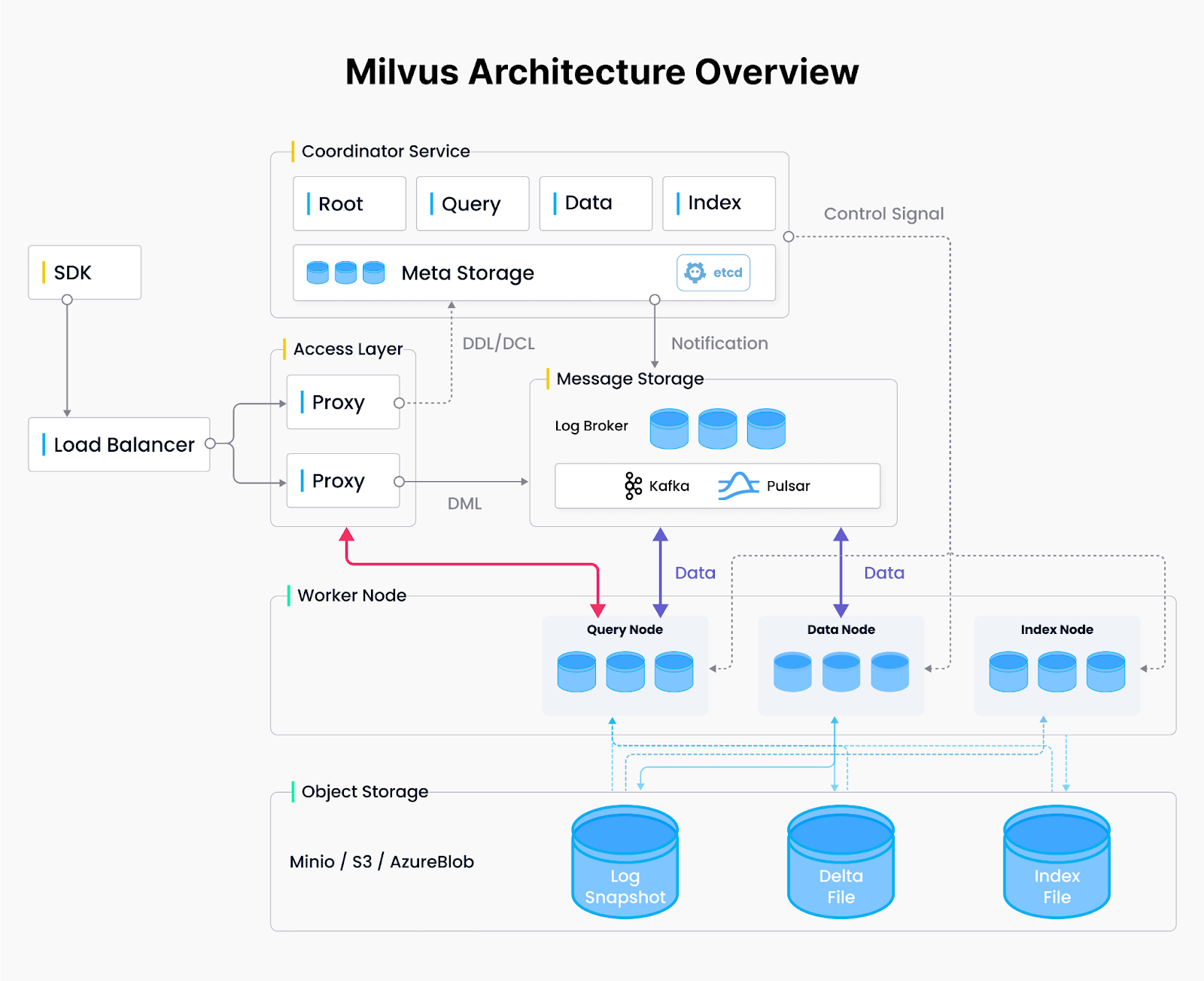 Milvus Architecture.png
Milvus Architecture.png
Figure: Milvus Architecture
Milvus Distributed Architecture: Four-Layer Design
Milvus is a widely used vector database that adopts a distributed system architecture comprising four layers to dynamically allocate resources wherever they’re most needed—whether it’s more compute power for large-scale indexing or additional memory to handle complex queries in parallel.
Access Layer: Stateless access nodes handle incoming requests, acting as the entry point to the system.
Coordination Layer: Coordinates node assignments and resource management, spinning up or down workers as needed.
Worker Layer: Performs the core tasks of querying, data ingestion, and index building on scalable, stateless nodes.
Storage Layer: Holds vector data and system metadata for node fault tolerance and persistency.
Scalability and Consistency in Milvus Distributed Architecture
Milvus applies distributed computing principles to handle massive vector datasets while maintaining data consistency. Below are key design features that help it scale horizontally, minimize bottlenecks, and offer adjustable consistency levels:
Horizontal Scaling: Milvus segments large datasets into manageable chunks. Each segment is indexed independently, so as your data grows, you can add more nodes without overhauling existing infrastructure.
Independent Nodes for Query, Data, and Index: To scale specific functions, queries, data ingestion, and indexing run independently on separate node types. This separation helps avoid bottlenecks and ensures the system can handle billions of vectors.
Tunable Consistency and Sharding: Data is sharded across multiple nodes for concurrent writes, while Milvus’s adjustable consistency levels let you balance performance and accuracy based on your application needs.
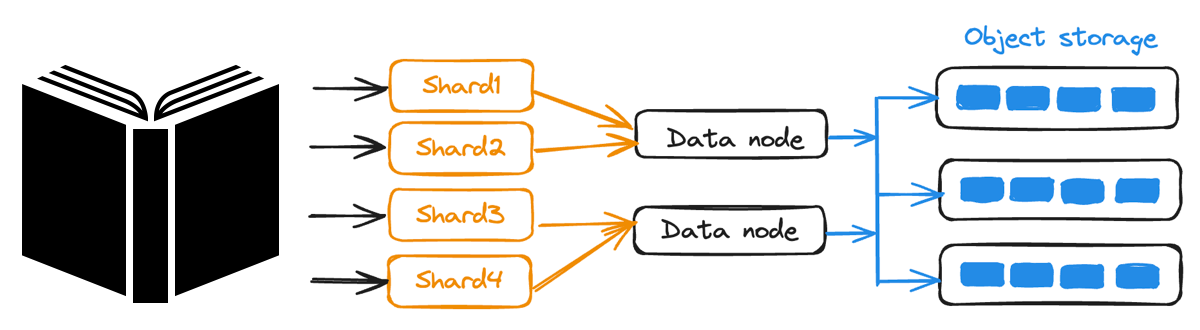 Data Sharding in Milvus
Data Sharding in Milvus
Figure: Data Sharding in Milvus
Multiple Deployment Modes for Different Needs
Milvus offers several deployment options to accommodate different data scales and performance requirements. Whether testing on a single machine or running a large-scale production system, these modes let you match resources and complexity to your project’s needs. Below is an illustration of the level of data scaling for each vector database. You can see that Milvus distributed is designed to handle data scales of tens of millions and beyond.
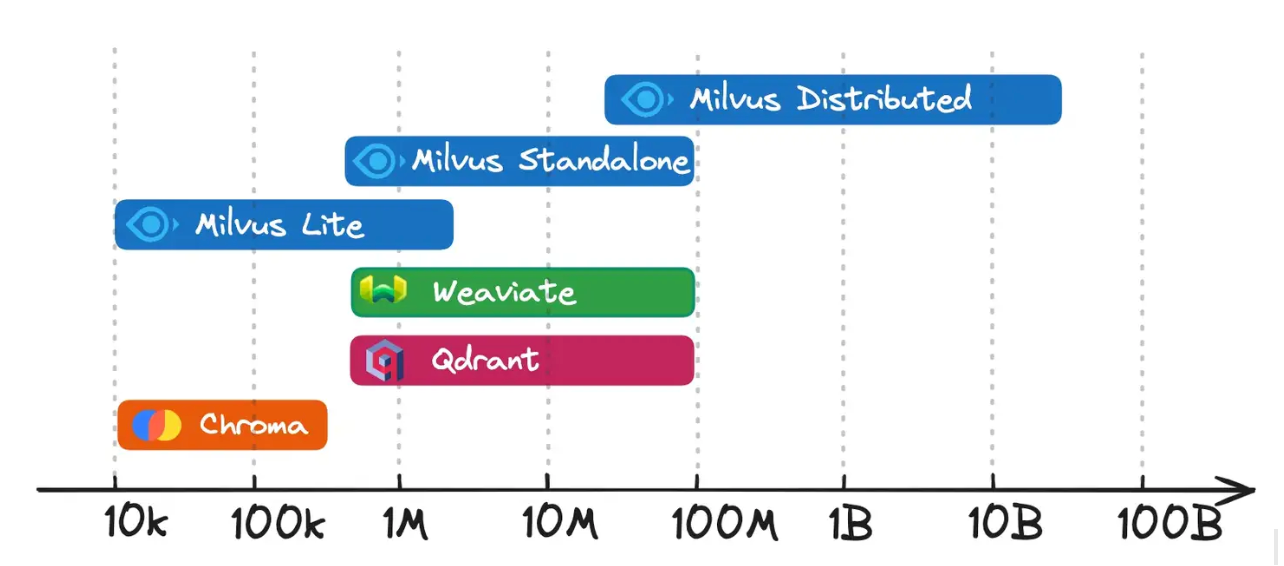 Milvus Deployment Modes
Milvus Deployment Modes
Figure: Milvus Deployment Modes
Milvus Lite: A lightweight Python library that delivers core Milvus functionalities without needing a separate server process. It’s ideal for small-scale experiments, rapid prototyping, or quick demos in local environments. Milvus Lite lets you get started fast with minimal setup if you’re building a proof of concept or testing new features in a notebook.
Milvus Distributed: A fully multi-node architecture designed for enterprise-scale demands. By separating tasks among access nodes, coordinators, workers, and storage layers, it handles billions (or even tens of billions) of vectors with high availability and fault tolerance. This model is the go-to choice for organizations that expect their data to grow rapidly, require robust performance under concurrent queries, and want the flexibility to add or remove nodes based on workload.
Milvus Standalone: A single-node deployment bundling all Milvus components into one environment, often distributed via a Docker image. This makes installation and maintenance straightforward while providing enough capacity for moderate data volumes. Teams looking to run production workloads that don’t require massive scalability or intricate failover mechanisms will find this option both cost-effective and reliable.
To learn more about the Milvus deployment, read our guide: How to Choose the Right Milvus Deployment Mode for Your AI Applications.
Conclusion
Distributed computing has reshaped how organizations handle data and scale their applications, moving away from monolithic servers toward flexible, fault-tolerant clusters of interconnected nodes. By splitting tasks and data across multiple machines, teams achieve faster processing, higher availability, and more efficient resource use. Modern solutions, like Zilliz, apply these principles to deliver a cloud-native vector database that can handle billions of vectors in parallel. As data volumes continue to rise and use cases grow more complex, adopting a distributed approach—whether for analytics, machine learning, or real-time recommendations—remains a key strategy for staying competitive in today’s data-driven world.
FAQs on Distributed Computing
Why choose a distributed system over a single, powerful server?With a distributed system, you can add more machines as workloads grow instead of upgrading a single server. This flexibility boosts performance, cuts costs, and reduces the impact of any single point of failure.
How does data stay consistent in a distributed environment?Distributed systems use protocols and algorithms (like consensus mechanisms) to keep data in sync across multiple nodes. The exact approach varies by system, but the goal is to ensure updates don’t conflict and each node has the correct data view.
Is it challenging to maintain distributed infrastructures?While distributed systems introduce more moving parts—such as network communication, node coordination, and replication—proper tooling and best practices can mitigate complexity. Tools like Kubernetes and monitoring platforms simplify orchestration and observability.
Where does Milvus fit into distributed computing?Milvus is a cloud-native, distributed vector database designed for large-scale similarity searches. By splitting data into segments and leveraging parallel indexing, Milvus can handle billions of vectors across multiple nodes without sacrificing speed or reliability.
What if my data needs to be collected or traffic suddenly spikes?Distributed systems are ideal for handling sudden changes in demand. You can spin up additional nodes or resources quickly, preventing overload on any machine and maintaining consistent performance even during peak usage times.
Related Resources
- From Single Servers to Distributed Systems: The Evolution
- How does Distributed Computing Work?
- Types of Distributed Computing Architectures
- Use Cases of Distributed Computing
- Benefits of Distributed Systems
- Challenges and Considerations
- Introducing Milvus: A Distributed, Cloud-Native Vector Database
- Conclusion
- FAQs on Distributed Computing
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free