




Change Data Capture: Keeping Your Systems Synchronized in Real-Time
Change Data Capture: Keeping Your Systems Synchronized in Real-Time
What is Change Data Capture (CDC)?
Change Data Capture (CDC) is a method used to identify and track changes in data as they happen within a database. Instead of manually monitoring or repeatedly querying for updates, CDC automatically captures inserts, updates, and deletions in real-time or near-real-time. CDC techniques, such as transaction logs and database triggers, facilitate organizations to maintain data consistency and integrity across various systems and deployment environments. This ensures downstream systems and applications—whether powering traditional analytics or vector-based AI models—always have the latest data.
For example, in a vector database, the CDC tracks real-time updates to embeddings for tasks like semantic search or fraud detection, where the latest data is required for accurate results.
Evolution of Data Integration: The Role of CDC
In the past, batch processing was the primary approach for data integration. However, it caused delays as data updates were processed in bulk at scheduled intervals, often hours or days after changes occurred. This limitation made it unsuitable for applications like real-time semantic search for AI-powered chatbots or recommendation systems, which rely on vector databases to analyze high-dimensional data.
CDC solves this problem by capturing changes as they happen and updating systems in real time. This technique allows businesses to synchronize their databases, power real-time dashboards, and build responsive applications. CDC’s rise coincided with the growth of modern distributed systems and cloud-native architectures, where timely data replication and integration are critical. Instead of working with stale data from periodic updates, organizations can now capture and act on changes as they occur. This shift has made the CDC a vital component of modern data strategies by helping businesses stay responsive and competitive in real time.
How Change Data Capture Works?
Imagine tracking a customer’s interactions on an e-commerce platform. Each interaction, such as browsing, adding to the cart, or purchasing, generates new data. CDC streams this changed data to a vector database like Milvus in real time, where their vector representations, also known as vector embeddings, can be updated for tasks like personalized recommendations or fraud prevention.
Let’s break it into key components and mechanisms to understand how CDC works.
Key Components of CDC
To make the CDC functional, several components work together. The diagram below illustrates the CDC process.
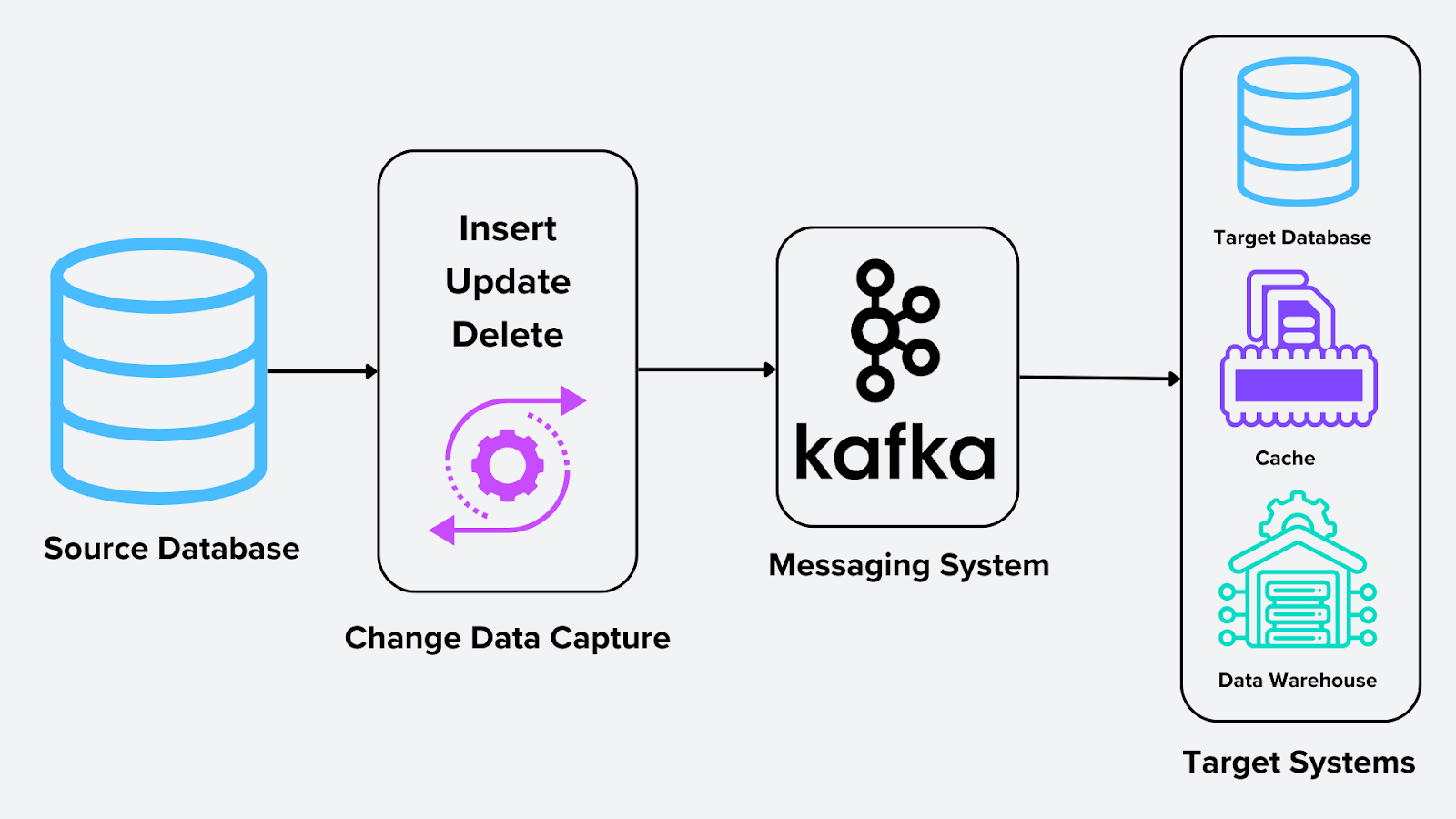 Figure- Change Data Capture Process .png
Figure- Change Data Capture Process .png
Figure: Change Data Capture Process
Source: The system where changes originate, which could be relational databases, NoSQL systems, or vector databases. In the case of vector database like Milvus, the source could be embeddings generated from deep learning models or image recognition models.
CDC Engine: The core process that captures and formats changes. For vector databases, this could mean updating embeddings stored in Milvus using tools like Milvus-CDC or Confluent Kafka Connect.
Messaging System: A messaging system like Apache Kafka serves as the backbone for distributing changes in real-time. It acts as an intermediary that stores and streams captured changes to one or multiple target systems. This ensures scalability and reliability in the data pipeline.
Target Systems: The destinations where the processed data changes are sent. Examples include:
Data Warehouses (e.g., Snowflake, BigQuery) for analytics.
Caches for faster query responses.
Databases for replication and synchronization across systems.
Overview of CDC Mechanisms
There are three primary ways the CDC can capture changes from a database. In the examples below, we’ll use SQL databases to demonstrate.
1. Log-Based CDC
This method relies on the database’s transaction log, a system-level feature that records all database changes (inserts, updates, and deletions). The CDC engine reads these logs and extracts the relevant changes for downstream use. In vector databases, this could mean capturing updates to embedding vectors as they are inserted or modified in Milvus.
How it works:
The transaction log is the single truth source for all database operations.
The CDC tool monitors the log and continuously identifies and captures changes without affecting the primary database.
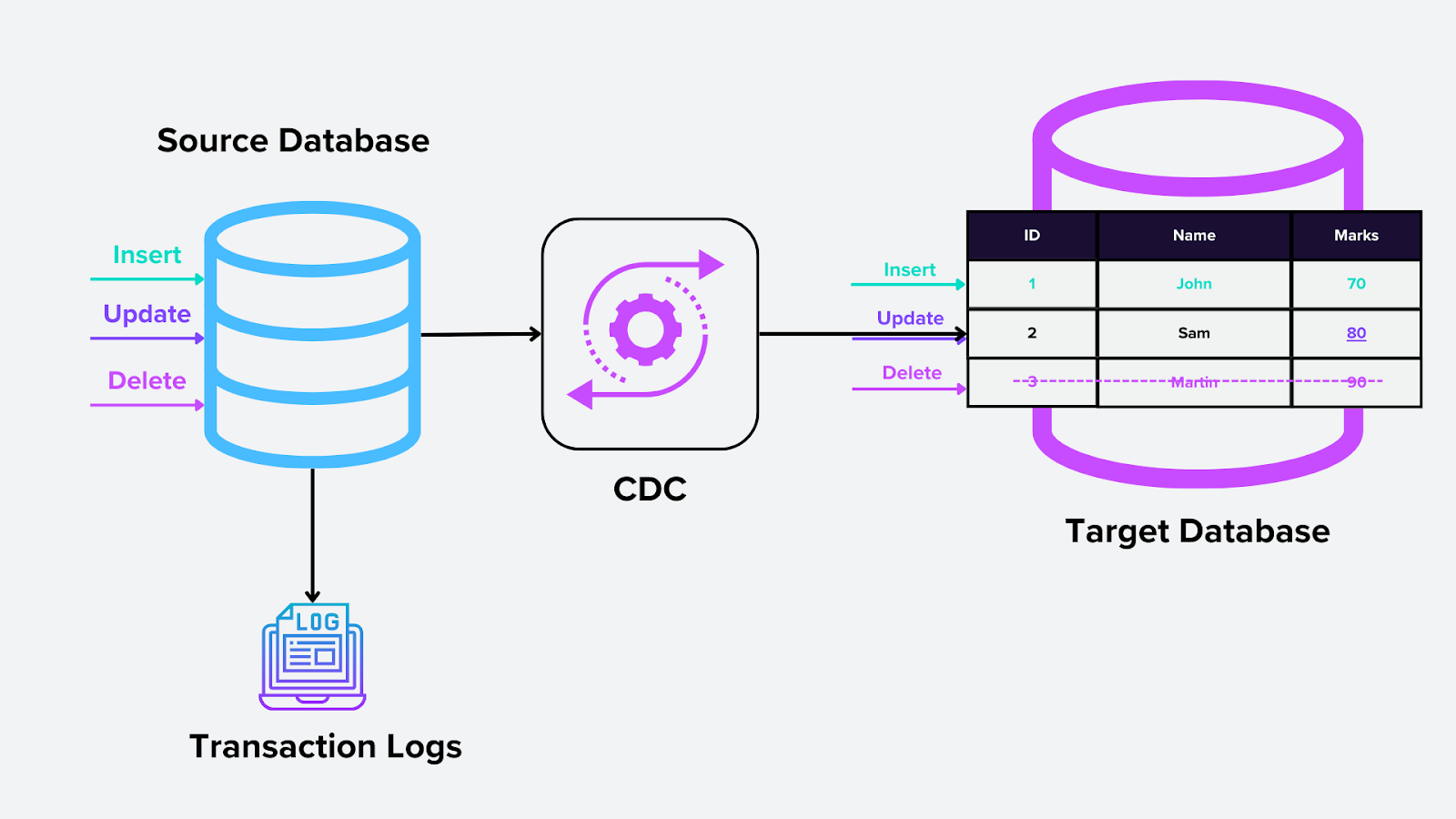 Figure- Log-based CDC.png
Figure- Log-based CDC.png
Figure: Log-based CDC
Pros:
High Performance: Minimal impact on the database since it reads directly from logs.
Comprehensive: Captures all changes, including triggers, stored procedures, or other indirect methods.
Scalable: Works well with high-transaction systems.
Cons:
Complexity: Requires deep integration with the database’s internal log structure, which can vary by database type.
Compatibility: Not all databases expose transaction logs for external access.
2. Trigger-Based CDC
This approach uses database triggers, which are custom logic that executes automatically when a specific change (e.g., insert, update, or delete) occurs in a table. For example, triggers could automatically update a Milvus vector index when new embeddings are added.
How it works:
Triggers are added to tables of interest in the database.
When changes occur, the trigger captures them and sends the information to a specified location or table for downstream processing.
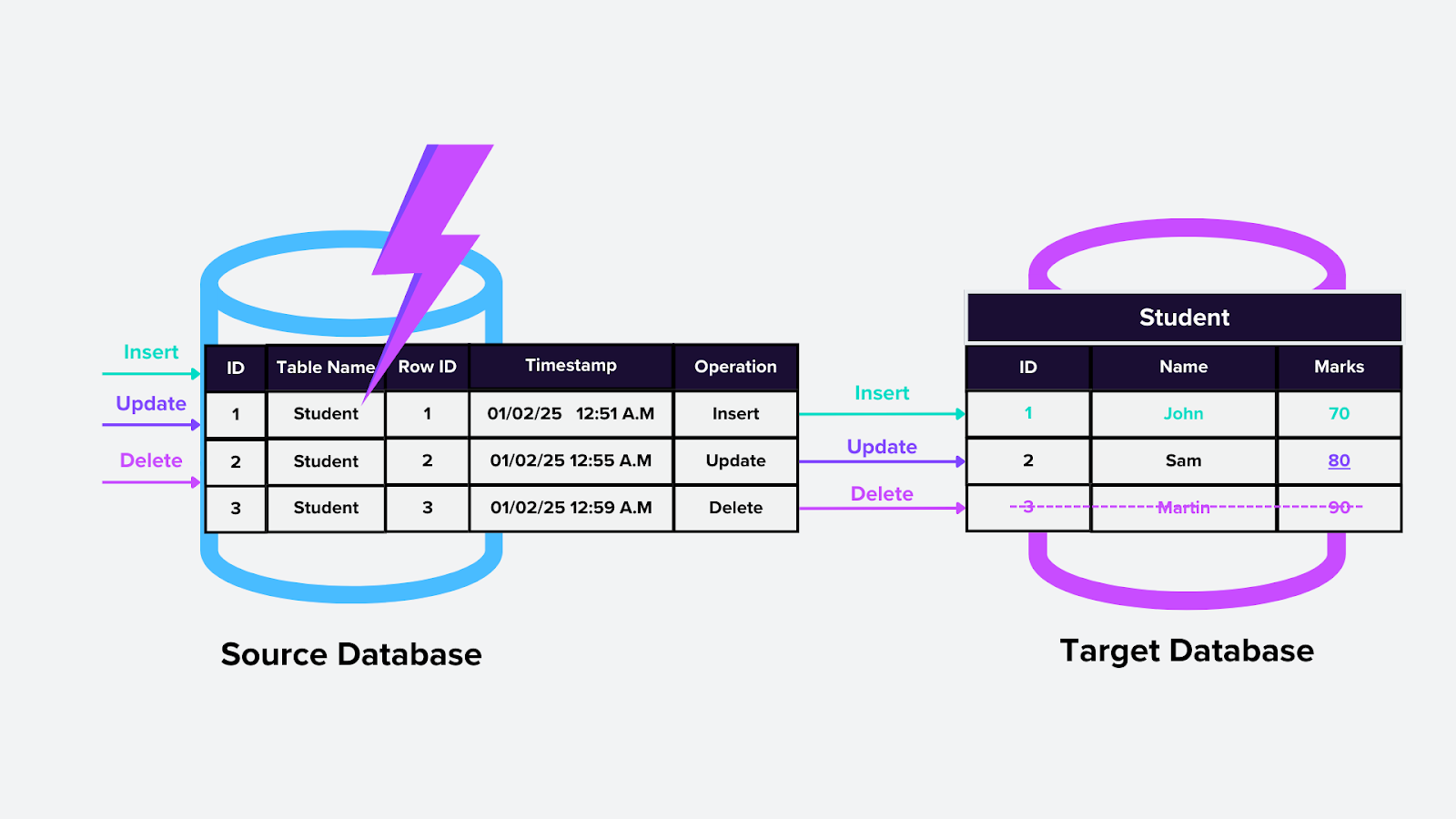 Figure- Trigger-based CDC.png
Figure- Trigger-based CDC.png
Figure: Trigger-based CDC
Pros:
Flexible: Can be customized to track changes for specific use cases.
Widely Supported: Almost all relational databases support triggers.
Cons:
Performance Impact: Triggers add overhead to the database, especially for high-frequency transactions.
Maintenance Challenges: Managing and updating triggers across multiple tables can become difficult.
Error Prone: Poorly written triggers can cause performance bottlenecks or fail to capture edge cases.
3. Query-Based CDC
This method involves running periodic queries against the database to detect changes. The queries typically compare timestamps or versions to identify newly modified records, such as polling a vector database for updated embeddings.
How it works:
The CDC engine runs queries at scheduled intervals and identifies changes based on specific criteria (e.g., last modified date).
Detected changes are then sent downstream.
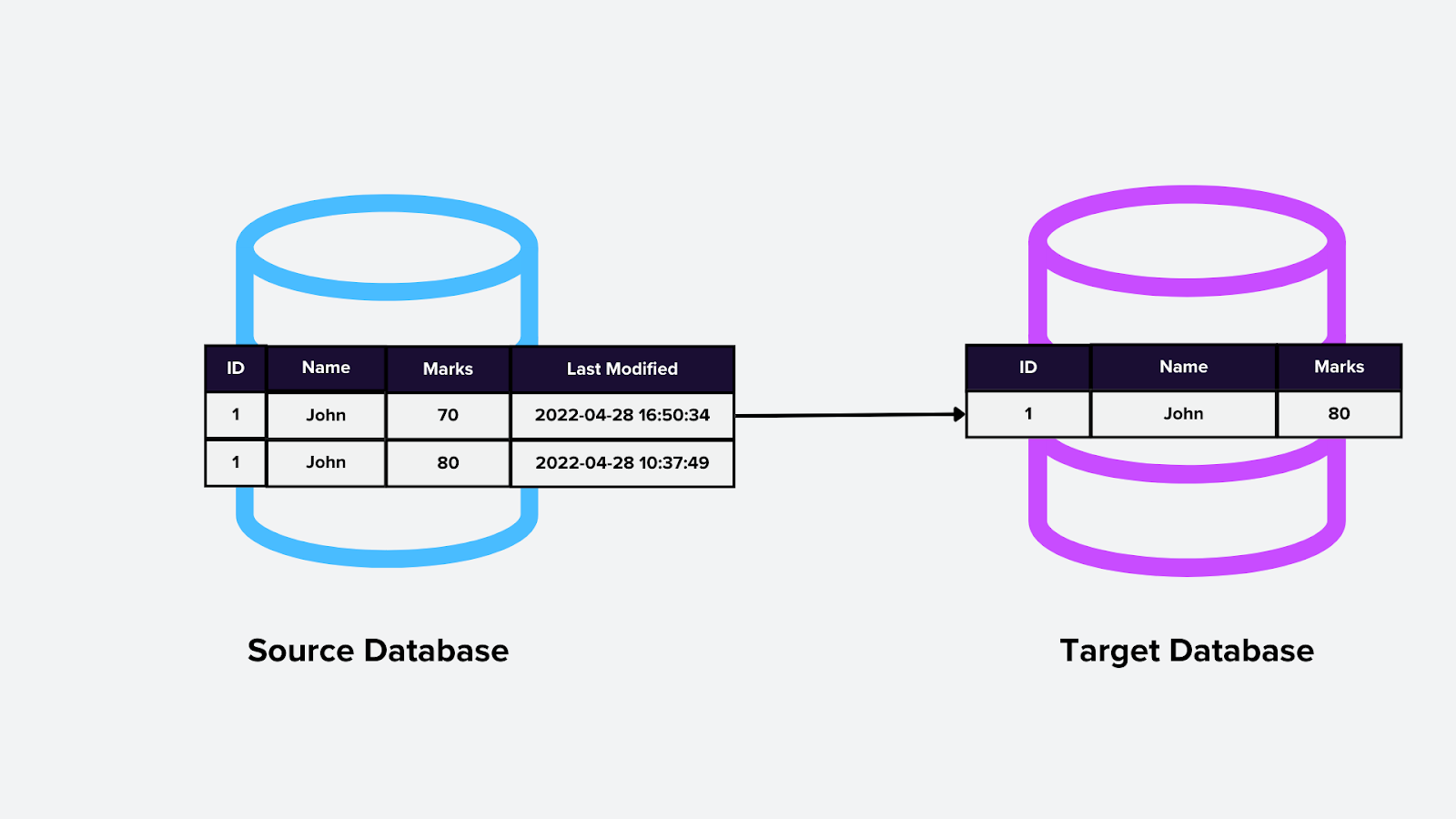 Figure- Query-based CDC.png
Figure- Query-based CDC.png
Figure: Query-based CDC
Pros:
Simple Setup: Requires no deep database integration or modification.
Database Agnostic: Works with nearly any database that supports querying.
Cons:
Latency: Not real-time, as it depends on the query schedule.
Performance Overhead: Frequent queries can strain the database.
Limited Accuracy: May miss changes if data modifications occur between query intervals.
Comparison of CDC Mechanisms
The table below provides quick insights into different CDC mechanisms and their use cases:
| Mechanism | Real-Time | Performance Impact | Ease of Setup | Use Case Suitability |
| Log-Based | Yes | Low | Medium | High-volume transactional systems |
| Trigger-Based | Yes | Medium-High | Low-Medium | Use cases requiring custom change logic |
| Query-Based | No | High | High | Simple setups with low-frequency changes |
Table: Comparison of CDC Mechanisms
CDC with Milvus: Real-Time Data Integration for Vector Databases
Milvus, an open-source vector database (developed by Zilliz engineers) built for managing unstructured data such as vector embeddings from machine learning models, has its own CDC tool, Milvus-CDC, which is explicitly designed to handle data replication and synchronization tasks within Milvus instances. Milvus-CDC captures incremental data changes for seamless synchronization between source and target Milvus instances. This supports tasks such as incremental backup, disaster recovery, and persistent data replication while maintaining data integrity and consistency. Milvus-CDC includes two main components: The HTTP Server, which manages user requests, executes tasks, and maintains task metadata and Corelib, which handles task synchronization, with a reader that extracts data from the source Milvus instance and message queue and a writer that processes these changes and sends them to the target Milvus instance.
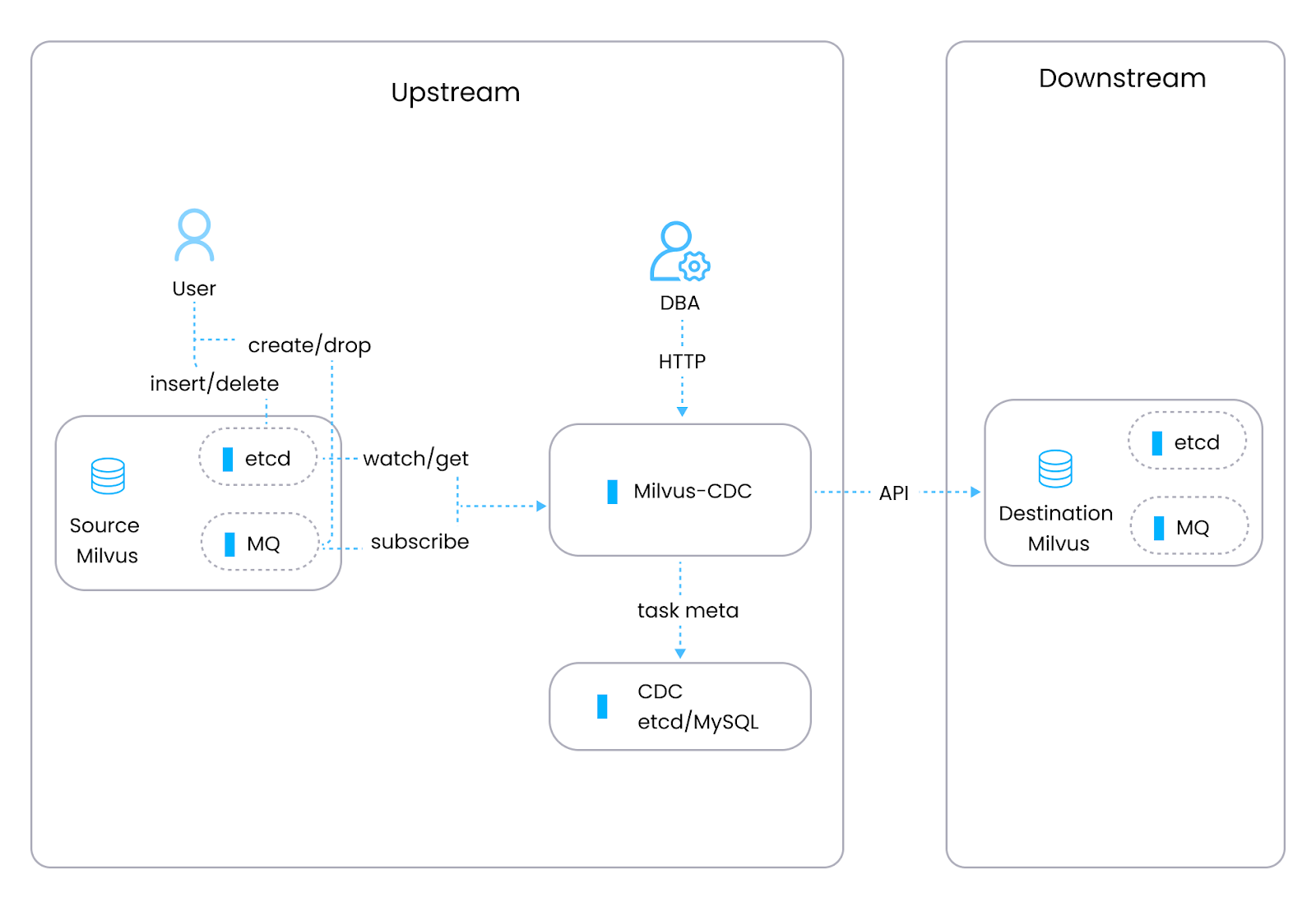 Figure- The Milvus-CDC architecture.png
Figure- The Milvus-CDC architecture.png
Figure: The Milvus-CDC architecture
Milvus-CDC: Key Features
Sequential Data Synchronization: Ensures changes are applied to preserve data consistency across Milvus instances.
Incremental Data Replication: Captures and replicates changes, such as insertions and deletions, from the source Milvus to the target instance.
Task Management: Users can create, manage, and delete CDC tasks using OpenAPI to integrate with various workflows.
Integration with Future Systems: Plans are in place to expand support for integration with stream processing systems.
CDC on Milvus Using Kafka
While Milvus-CDC is tailored explicitly for Milvus, integrating Milvus with Apache Kafka offers another approach to CDC. Kafka is a central hub that captures and propagates data changes from various sources using CDC tools like Kafka Sink connector. These changes are then ingested into Milvus to keep the vector database up to date with the latest embeddings or feature vectors.
To connect Kafka with Milvus, you can follow this guide: Connect Kafka with Milvus.
Role of CDC in Distributed Databases and Cloud-Native Applications
As organizations adopt distributed databases and cloud-native applications to handle large-scale, geographically distributed workloads, CDC plays a critical role in seamless data synchronization across these complex systems.
Data Synchronization Across Distributed Systems: In distributed databases, data is often spread across multiple nodes or regions to improve performance and scalability. CDC immediately propagates those changes made on one node to others to maintain consistency across the system.
Real-Time Data Sharing in Cloud-Native Architectures: Cloud-native applications often rely on microservices, each with its data storage. CDC enables these services to share real-time updates without relying on heavy batch processes to support event-driven architectures.
Replication for High Availability and Disaster Recovery: Distributed systems often use data replication for high availability. CDC captures and replicates changes to backup nodes or failover systems.
Streamlining Data Pipelines: In environments where multiple systems depend on shared datasets, CDC provides a mechanism to feed real-time changes into analytics platforms, data lakes, or message queues.
Applications of CDC in Vector Database
Here are specific use cases of CDC, especially in AI applications working with a vector database:
Semantic Search: CDC updates the vector database with the latest embeddings, which allows semantic search systems to provide accurate and relevant results. For example, an enterprise search engine can deliver precise answers based on real-time updates to document or query embeddings.
Recommendation Systems: Vector databases use embeddings to generate personalized recommendations. CDC streams real-time changes, such as new user behaviours or product updates, so recommendation systems adapt quickly to evolving data.
Fraud Detection: In financial systems, embeddings from transactional data are continuously updated in a vector database. CDC ensures that these updates are streamed in real-time to instantly detect unusual activity and flag potential fraud.
Image and Video Recognition: For applications like tagging or finding visually similar content, CDC keeps vector embeddings generated from images or videos up to date in the database. This enables accurate and fast results for real-time use cases, such as social media moderation or e-commerce visual search.
Chatbots and Virtual Assistants: CDC helps RAG-based LLM chatbots to provide real-time, accurate responses. For instance, embeddings representing live user interactions or updated knowledge bases are captured and updated instantly, which improves chatbot performance.
Anomaly Detection: The CDC is helpful in cybersecurity, where unusual patterns in network traffic or system logs need immediate attention.
Benefits of CDC
CDC provides significant advantages for modern data architectures to operate efficiently and make informed decisions. Here are the key benefits:
Real-Time Insights: CDC provides the freshest data to support quick decision-making. Hence, businesses can monitor performance and trends instantly.
Reduced Data Latency: Eliminates delays caused by traditional batch processing. As changes are reflected across systems almost immediately, they Improve responsiveness in applications that depend on synchronized data.
Scalability in Large Systems: It handles high volumes of data changes, making it suitable for large-scale databases and distributed environments.
Seamless Data Replication and Migration: This feature facilitates real-time data replication between systems for high availability, disaster recovery, and load balancing. It also simplifies database migrations using synchronized data during transitions with minimal downtime.
Support for Event-Driven Architectures: Powers event-driven applications by triggering downstream workflows or processes based on data changes. Hence, it enhances automation and responsiveness in business operations.
Data Accuracy and Consistency: All connected systems have consistent and accurate data, reducing errors and inconsistencies. Hence, it provides a reliable foundation for building robust data-driven solutions.
Challenges of Implementing CDC
Implementing CDC can be complex, and organizations must address several challenges for efficient and reliable operations. The key hurdles include:
Performance Overheads: Capturing and processing real-time changes can place an additional load on the database that impacts the performance of primary applications. Also, Resource-intensive methods like triggers or frequent queries can degrade database response times. Balancing speed with accuracy and reliability demands optimized pipeline design.
Handling Schema Changes: Changes to the database schema, such as adding columns, modifying data types, or altering table structures, can disrupt CDC pipelines.
Network and Storage Considerations: Continuous data streaming in CDC requires sufficient storage capacity and efficient compression techniques to avoid spiralling costs. The increases in network traffic may strain bandwidth, especially in geographically distributed systems.
Data Integrity in the CDC Pipeline: Failures or inconsistencies in the pipeline can compromise the accuracy of downstream systems. Handling out-of-order events and resolving conflicts in distributed environments can add complexity.
Tool Compatibility and Vendor Lock-In: Some CDC solutions are tied to specific databases or technologies, limiting flexibility in heterogeneous environments. Switching tools or upgrading systems may require reengineering CDC processes.
Security and Compliance Risks: Streaming sensitive data in real-time requires robust encryption and access controls to prevent unauthorized access. Compliance with data protection regulations like GDPR or CCPA can complicate CDC implementation.
Tools and Frameworks for CDC
Several tools and frameworks are available to implement CDC, each having unique features tailored to specific use cases. Here’s a list of popular options:
Debezium**: An open-source CDC platform built on Apache Kafka, Debezium supports various databases, such as MySQL, PostgreSQL, MongoDB, and SQL Server. It is ideal for real-time data streaming and integration with event-driven architectures.
Oracle GoldenGate: A robust and enterprise-grade CDC solution from Oracle, GoldenGate supports high-performance data replication and real-time integration across heterogeneous databases. It is widely used for disaster recovery and migration.
AWS Database Migration Service (DMS): ****A fully managed service from Amazon that supports CDC for various databases, both on-premises and in the cloud. It simplifies data migration and replication without requiring significant overhead.
Qlik Replicate: Formerly known as Attunity Replicate, Qlik Replicate supports CDC for a wide range of databases and file systems. It is designed for fast, scalable data replication and integration into analytics platforms.
Confluent Kafka Connect: Part of the Confluent ecosystem, Kafka Connect offers CDC capabilities for streaming data changes into Kafka topics. It also seamlessly integrates with the Kafka platform for real-time event processing.
Conclusion
CDC plays a vital role in modern data systems through real-time updates and integration across platforms. By addressing the limitations of batch processing, CDC supports real-time analytics, event-driven architectures, and seamless data synchronization. Tools like Apache Kafka further enhance CDC by streamlining changes in downstream systems, including vector databases like Milvus. This helps businesses handle unstructured data, scale operations, and build responsive applications.
Related Resources
- What is Change Data Capture (CDC)?
- Evolution of Data Integration: The Role of CDC
- How Change Data Capture Works?
- CDC with Milvus: Real-Time Data Integration for Vector Databases
- Role of CDC in Distributed Databases and Cloud-Native Applications
- Applications of CDC in Vector Database
- Benefits of CDC
- Challenges of Implementing CDC
- Tools and Frameworks for CDC
- Conclusion
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free