




Deep Reinforcement Learning (DRL) verstehen: Ein umfassender Leitfaden
Kurze Antwort: Deep Reinforcement Learning (DRL) ist ein Bereich der KI, in dem ein Agent lernt, Entscheidungen zu treffen, indem er mit einer Umgebung interagiert und sich im Laufe der Zeit auf Grundlage von Feedback oder „Belohnungen“ verbessert. DRL kombiniert Reinforcement Learning (RL), eine Lernmethode durch Versuch und Irrtum, mit Deep Learning, wodurch der Agent komplexe Daten wie Bilder oder Sensormesswerte verarbeiten kann. DRL kann tiefe neuronale Netze nutzen, um Agenten beizubringen, komplizierte Aufgaben mit hochdimensionalen Eingaben zu bewältigen. Es wird häufig in Anwendungen wie Robotik und Spielen eingesetzt, wo traditionelle Lernmethoden aufgrund der Komplexität und Variabilität der Umgebung an ihre Grenzen stoßen.
Deep Reinforcement Learning (DRL) verstehen: Ein umfassender Leitfaden
Als AlphaGo im Jahr 2016 den Weltmeister Lee Sedol in Go besiegte — einem Spiel mit mehr möglichen Zügen als Atomen im Universum — markierte dies einen Wendepunkt in der Geschäftstechnologie. Das Geheimnis hinter diesem Sieg? Deep Reinforcement Learning — eine Methode, die Computer darauf trainiert, sich durch Übung zu verbessern, ganz wie ein Tennisspieler, der nach Jahren auf dem Platz seinen Aufschlag perfektioniert. Während traditionelle Computerprogramme mit unerwarteten Veränderungen Schwierigkeiten haben, glänzt diese Technologie in Situationen, die sich ständig verändern — von der Steuerung von Robotern in belebten Lagerhallen bis hin zu schnellen Entscheidungen im Aktienhandel. Dieser neue Ansatz des maschinellen Lernens eröffnet Unternehmen neue Möglichkeiten und bewältigt Probleme, die früher zu komplex waren, als dass normale Software sie lösen könnte.
Dieser Leitfaden bietet eine eingehende Untersuchung von Deep Reinforcement Learning, hebt zentrale Konzepte, seine verschiedenen Anwendungen, seine Vorteile und die Herausforderungen hervor, die bei seiner Implementierung auftreten können.
Was ist Deep Reinforcement Learning?
Deep Reinforcement Learning (DRL) kombiniert zwei effektive KI-Techniken, Reinforcement Learning (RL) und Deep Learning, und ermöglicht es KI-Agenten, durch Versuch und Irrtum in komplexen Umgebungen optimale Handlungen zu erlernen. Beim RL interagiert ein Agent mit seiner Umgebung und passt sein Verhalten auf Grundlage von Belohnungen und Lernstrategien an, um langfristige Belohnungen zu maximieren. Deep Learning ergänzt die Fähigkeit, detaillierte Zustandsrepräsentationen mithilfe von neuronalen Netzen zu verarbeiten.
Beispielsweise bewegt sich ein Roboter, der durch ein Labyrinth navigiert, anfangs zufällig, lernt aber mit der Zeit durch Feedback, das Ziel effizient zu erreichen. DRL hilft Agenten, sich an dynamische Umgebungen anzupassen und komplexe Probleme ohne detaillierte Anweisungen zu lösen. Es ist nützlich in Videospielen, selbstfahrenden Autos und persönlichen Empfehlungen. Durch die Kombination von Reinforcement Learning und Deep Learning können DRL-Agenten komplizierte Aufgaben der realen Welt effektiv bewältigen.
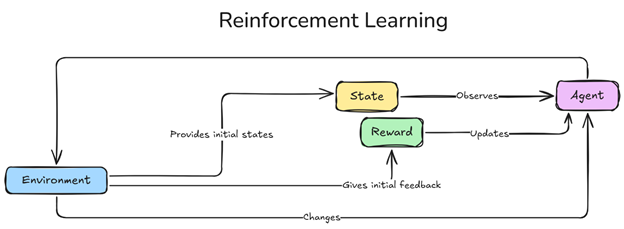 Figure 1 Reinforcement Learning Framework.png
Figure 1 Reinforcement Learning Framework.png
Wie Deep Reinforcement Learning funktioniert
Um zu verstehen, wie DRL funktioniert, ist es wichtig, seine Schlüsselkomponenten zu kennen:
Agent
Umgebung
Zustand
Handlungen und Belohnungen
Policy
Agent
Der Agent ist der Entscheidungsträger, der damit beauftragt ist, sich in der Umgebung zurechtzufinden und Entscheidungen zu treffen, um die kumulativen Belohnungen im Laufe der Zeit zu maximieren. Durch wiederholte Interaktionen (Lernepisoden) verfeinert der Agent seine Strategie auf Grundlage von Feedback und passt sein Verhalten an, um langfristigen Erfolg zu erzielen. Ähnlich wie ein Spieler in einem Spiel werden die Handlungen des Agenten von einer Policy geleitet — einem Regelwerk, das im Laufe der Zeit erlernt wird, um die Leistung zu verbessern und optimale Ergebnisse zu erreichen.
Umgebung
Die Umgebung ist der strukturierte Raum, in dem der Agent agiert, und definiert mögliche Zustände, Handlungen und Belohnungen. Sie reagiert auf jede Handlung des Agenten und liefert Feedback, das die zukünftigen Entscheidungen des Agenten beeinflusst und seinen Lernprozess prägt.
Zustand
Der Zustand stellt eine Momentaufnahme der Umgebung zu einem bestimmten Zeitpunkt dar und enthält Informationen, die für die Entscheidungsfindung des Agenten wichtig sind. Beispielsweise könnte ein Zustand die Position eines Agenten und Hindernisse in einem Labyrinth oder die Geschwindigkeit eines Fahrzeugs und seine Nähe zu anderen Autos umfassen. Jeder Zustand hilft dem Agenten, seine Situation einzuschätzen und die vorteilhafteste Aktion auszuwählen.
Aktionen und Belohnungen
Aktionen stellen die Entscheidungen eines Agenten in jedem Zustand dar und lenken seinen Weg durch die Umgebung. Aktionen können sein:
Diskrete Aktionen: Begrenzte Optionen, wie sich in Rasterumgebungen nach oben, unten, links oder rechts zu bewegen, erleichtern es Agenten, zu erkunden und Strategien zu entwickeln.
Kontinuierliche Aktionen: Diese umfassen einen Wertebereich, wie das Anpassen von Geschwindigkeit oder Winkel, und erfordern fortgeschrittene Modelle, um die erhöhte Komplexität zu bewältigen.
Der Agent zielt darauf ab, im Laufe der Zeit optimale Aktionen auszuführen und Belohnungen zu maximieren.
Belohnungen liefern Feedback, um das Lernen des Agenten zu leiten. Positive Belohnungen signalisieren erfolgreiche Aktionen, während negative Belohnungen Fehler bestrafen. Belohnungen können umfassen:
Unmittelbare Belohnungen: Diese werden direkt nach einer Aktion vergeben, wie das Erzielen von Punkten für das Schlagen einer gegnerischen Figur im Schach.
Verzögerte Belohnungen: Verdient nach dem Abschließen einer Abfolge von Aktionen, wie dem Navigieren durch ein Labyrinth.
Es ist wichtig, die Belohnungsstruktur zu gestalten, bekannt als Reward Shaping. Beispielsweise können Zwischenbelohnungen entlang eines komplexen Pfads das Lernen beschleunigen und den Agenten motivieren, bestimmte Schritte in Richtung des endgültigen Ziels zu unternehmen.
 Figure- Reinforcement Learning architecture.png
Figure- Reinforcement Learning architecture.png
Abbildung: Reinforcement-Learning-Architektur
Der Lernprozess
Der Lern- oder Trainingsprozess des Deep Reinforcement Learning ist ein iterativer Zyklus aus Interaktion, Feedback und Verbesserung, der Folgendes umfasst:
Exploration
Exploitation
Tiefe neuronale Netze
Backpropagation
Exploration
Anfangs kennt der Agent die Umgebung nicht. Er beginnt damit, zufällig zu erkunden, verschiedene Aktionen auszuprobieren und die Konsequenzen zu beobachten. Diese Explorationsphase ist wichtig, um Umgebungsinformationen zu sammeln und lohnende Aktionen zu entdecken.
Exploitation
Während der Agent erkundet und Erfahrungen sammelt, beginnt er, Aktionen zu identifizieren, die zu positiven Belohnungen führen. Dann nutzt er dieses Wissen aus und wählt diese Aktionen häufiger, um seine Belohnungen zu maximieren.
Tiefe neuronale Netze
Der Agent verwendet tiefe neuronale Netze, um die Strategie und die Wertfunktion des Agenten anzunähern.
Policy Network: Dieses Netzwerk nimmt den aktuellen Zustand als Eingabe und gibt die Wahrscheinlichkeit aus, verschiedene Aktionen auszuführen.
Value Network: Dieses Netzwerk schätzt den langfristigen Wert, sich in einem bestimmten Zustand zu befinden, und hilft dem Agenten, Entscheidungen zu treffen, die zu höheren kumulativen Belohnungen führen. Diese neuronalen Netze ermöglichen es dem Agenten, komplexe Umgebungsmuster und -beziehungen zu lernen, und helfen dabei, intelligentere Entscheidungen zu treffen.
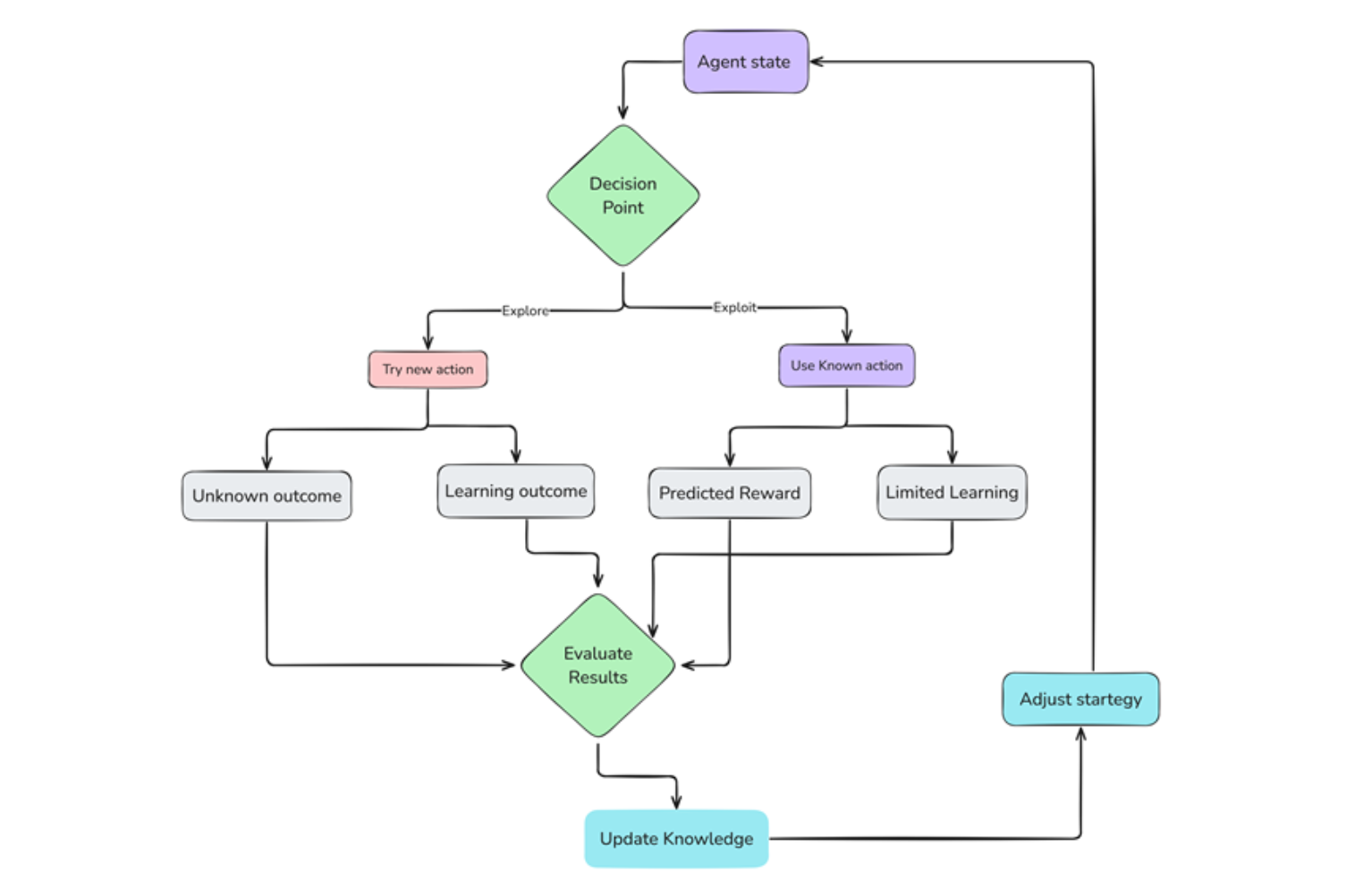 Exploration vs Exploitation Process .png
Exploration vs Exploitation Process .png
Abbildung 3 Explorations- vs. Exploitationsprozess
Backpropagation
Backpropagation, kurz für „Rückwärtsausbreitung von Fehlern“, ist ein zentraler Algorithmus beim Training neuronaler Netze. Er passt die Gewichte in einem neuronalen Netz an, um den Fehler in den Vorhersagen zu minimieren.
Backpropagation hilft Agenten, ihre Entscheidungsmodelle durch Lernen aus Feedback zu verbessern. Wenn ein Agent eine Aktion ausführt, erhält er Feedback dazu, wie gut oder schlecht diese Aktion war (in Form einer Belohnung). Backpropagation passt dann die Gewichte des neuronalen Netzwerks an und reduziert den Fehler zwischen vorhergesagten Ergebnissen und tatsächlichen Belohnungen. Durch wiederholtes Anwenden von Backpropagation lernt das neuronale Netzwerk, die Wert- oder Policy-Funktionen besser anzunähern, was zu genaueren Entscheidungen führt. Dieser Prozess ermöglicht es dem Agenten, sein Verständnis der Umgebung schrittweise zu verbessern und im Laufe der Zeit zunehmend optimale Entscheidungen zu treffen, was für die Bewältigung komplexer Aufgaben in dynamischen, hochdimensionalen Umgebungen unerlässlich ist.
Beliebte Algorithmen im Deep Reinforcement Learning
DRL verwendet eine Vielzahl von Algorithmen, die jeweils darauf ausgelegt sind, unterschiedliche Herausforderungen im Lernprozess zu bewältigen. Hier sind einige der am häufigsten verwendeten Methoden:
Q-Learning: Q-Learning ist einer der grundlegenden Reinforcement-Learning-Algorithmen. Es schätzt den Wert von Zustands-Aktions-Paaren, die als Q-Werte bezeichnet werden, und hilft dem Agenten zu bestimmen, welche Aktionen in bestimmten Zuständen vorzuziehen sind. Der Algorithmus aktualisiert diese Q-Werte auf der Grundlage unmittelbarer Belohnungen und erwarteter zukünftiger Belohnungen und verfeinert so schrittweise die Entscheidungen des Agenten zugunsten von Aktionen mit höherem langfristigem Wert.
Deep Q-Networks (DQN): DQN erweitert Q-Learning, indem es neuronale Netzwerke zur Approximation von Q-Werten nutzt. Dieser Ansatz macht DQNs in komplexen Umgebungen wie Game AI, robotischer Navigation und autonomem Fahren effektiv.
Policy Gradients: Im Gegensatz zu wertbasierten Methoden optimieren Policy-Gradient-Algorithmen die Policy eines Agenten direkt, indem sie die Gewichte eines neuronalen Netzwerks auf der Grundlage der erhaltenen Belohnungen anpassen. Dieser Ansatz ermöglicht es dem Agenten, die Leistung zu verbessern, indem die Wahrscheinlichkeit erfolgreicher Aktionen erhöht wird, was besonders wichtig bei Steuerungsaufgaben ist, die präzise Anpassungen erfordern, wie etwa die Manipulation eines Roboterarms.
Actor-Critic Methods: Hybride Ansätze kombinieren die Stärken policy-basierter Methoden, die darauf abzielen, den Wert jeder Aktion in einem gegebenen Zustand zu schätzen, und wertbasierter Methoden, die sich darauf konzentrieren, die optimale Policy direkt zu lernen. In diesem Framework ist der Actor für die Auswahl von Aktionen verantwortlich, während der Critic diese Aktionen bewertet und Feedback liefert. Dieses Feedback ermöglicht kontinuierliche Verbesserungen der Policy.
Vergleich von Deep Reinforcement Learning mit anderen Konzepten
Deep Reinforcement Learning (DRL) wird häufig mit anderen KI-Ansätzen verglichen. Um Unterschiede und Gemeinsamkeiten zu verdeutlichen, betrachten wir die wichtigsten Aspekte:
| Aspekt | Deep Reinforcement Learning (DRL) | Reguläres Reinforcement Learning (RL) | Überwachtes Lernen | Unüberwachtes Lernen | |
| Kernkonzept & Datenverarbeitung | Kombiniert RL mit tiefen neuronalen Netzen; verarbeitet hochdimensionale, komplexe Daten | Konzentriert sich auf RL mit einfacheren Modellen; funktioniert gut in niedrigdimensionalen Umgebungen | Lernt aus beschrifteten Daten mit vordefinierten Ausgaben; stützt sich auf beschriftete Datensätze | Findet Muster in unbeschrifteten Daten; arbeitet mit unbeschrifteten Datensätzen | |
| Lernprozess | Versuch und Irrtum durch Interaktion mit der Umgebung. | Versuch und Irrtum durch Feedback aus der Umgebung. | Lernt Muster aus beschrifteten Eingabe-Ausgabe-Paaren. | Identifiziert Cluster oder Strukturen in Daten. | |
| Ziel | Kumulative Belohnungen über die Zeit maximieren. | Kumulative Belohnungen über die Zeit maximieren. | Ausgaben auf Grundlage von Eingabedaten vorhersagen. | Verborgene Muster oder Gruppierungen in Daten entdecken. | |
| Anwendungen | Komplexe Aufgaben: Spiel-KI, Robotik, autonome Fahrzeuge. | Grundlegende Steuerungssysteme und einfache Entscheidungsaufgaben. | Klassifizierung, Regression, prädiktive Modellierung. | Clustering, Dimensionalitätsreduktion, Anomalieerkennung. |
Vorteile und Herausforderungen des Deep Reinforcement Learning
Deep Reinforcement Learning bietet viele Möglichkeiten, aber es ist wichtig zu wissen, worin es gut ist und wo es möglicherweise an Grenzen stößt. Schauen wir uns einige der wichtigsten Vorteile und Herausforderungen von DRL an.
Vorteile:
Anpassungsfähigkeit: Ein zentraler Vorteil von DRL ist seine Anpassungsfähigkeit. DRL-Agenten können neue und unerwartete Situationen bewältigen, ohne dass zusätzliche Programmierung erforderlich ist. Beispielsweise kann ein DRL-gestütztes autonomes Fahrzeug auf plötzliche Veränderungen der Straße reagieren, etwa auf Hindernisse oder widrige Wetterbedingungen, und sein Verhalten anpassen, um sicher zu navigieren.
Optimale Entscheidungsfindung: DRL ermöglicht außerdem intelligentere, oft effektivere Entscheidungen. Im Gegensatz zu traditionellen regelbasierten Systemen können DRL-Modelle Strategien entdecken, die selbst menschliche Entwickler möglicherweise übersehen würden. Im Finanzwesen wurde DRL beispielsweise erfolgreich eingesetzt, um Trading-Bots zu erstellen, die häufig profitablere Entscheidungen treffen als herkömmliche Systeme.
Automatisierungspotenzial: DRL ermöglicht die Automatisierung von Aufgaben in Bereichen wie Warentransport, medizinischer Versorgung und Kundenbetreuung. In diesen oft komplizierten und sich ständig verändernden Bereichen hilft DRL dabei, Abläufe durch Automatisierung zu vereinfachen.
Herausforderungen:
Stichprobeneffizienz: Eine der größten Herausforderungen bei DRL ist der Bedarf an enormen Mengen an Trainingsdaten. DRL-Modelle benötigen in der Regel umfangreiche Daten, um gut zu funktionieren, deren Erfassung kostspielig und zeitaufwendig sein kann. Techniken wie Experience Replay helfen, indem sie Modellen ermöglichen, aus früheren Daten zu lernen, aber Verbesserungen der Dateneffizienz sind weiterhin erforderlich, um DRL praktikabler zu machen.
Reward Design: Eine weitere Herausforderung liegt in der Gestaltung effektiver Reward-Funktionen. Die Festlegung der richtigen Rewards ist entscheidend, da schlecht gestaltete Rewards zu unbeabsichtigtem und manchmal problematischem Verhalten von Agenten führen können. Daher erfordert Reward Design in DRL eine sorgfältige Planung, um sicherzustellen, dass Agenten auf eine Weise handeln, die mit ihren beabsichtigten Zielen übereinstimmt.
Stabilität und Konvergenz: Schließlich kann das Training von DRL instabil sein. Manchmal bleiben Modelle in weniger als idealen Strategien stecken oder erreichen keine stabile Lösung. Die Verbesserung der Trainingsstabilität ist entscheidend, um DRL-Modelle zuverlässiger zu machen, insbesondere für Anwendungen mit hohen Risiken, bei denen Konsistenz entscheidend ist.
Praxisanwendungen von Deep Reinforcement Learning
Nachdem wir die Funktionsweise von Deep Reinforcement Learning (DRL) untersucht haben, richten wir unseren Fokus nun auf seine praktischen Anwendungen. DRL wird eingesetzt, um reale Probleme in verschiedenen Bereichen zu lösen. Dazu gehören:
Spielen: DRL hat die Entwicklung fortschrittlicher KI-Agenten ermöglicht, die in Spielen wie Chess, Go und Dota 2 herausragende Leistungen erbringen. Für alle, die an praktischer Erkundung interessiert sind, bietet Unity ML-Agents ein zugängliches Toolkit zum Experimentieren mit spielbasiertem Lernen.
Robotik: In der Robotik vermittelt DRL Maschinen Fähigkeiten wie Navigation und das Handhaben von Objekten. DRL erweist sich in Lagerhäusern als äußerst effektiv, da es Robotern ermöglicht, sich an neue Layouts und wechselnde Aufgaben anzupassen, wodurch die Effizienz der Abläufe gesteigert wird.
Autonome Fahrzeuge: In selbstfahrenden Autos spielt DRL eine entscheidende Rolle bei Entscheidungen in Sekundenbruchteilen, etwa bei Spurwechseln, dem Vermeiden von Hindernissen oder der Anpassung der Geschwindigkeit. Waymo nutzt beispielsweise DRL, um seinen Fahrzeugen zu helfen, in komplexen Verkehrssituationen sichere Entscheidungen zu treffen.
Finanzhandel: DRL wird auch im Finanzwesen häufig eingesetzt, um Trading-Bots zu entwickeln, die auf Marktveränderungen reagieren. Mithilfe von Ansätzen wie Deep Q-Learning analysieren DRL-gestützte Trading-Bots historische Trends und Live-Daten, um fundierte Kauf-, Halte- oder Verkaufsentscheidungen zu treffen, und erzielen dabei oft bessere Ergebnisse als manuelle Handelsstrategien.
Personalisierte Empfehlungen: DRL treibt zunehmend fortschrittliche Empfehlungssysteme an. Um maßgeschneiderte Empfehlungen bereitzustellen, analysieren DRL-Algorithmen das Nutzerverhalten und die Präferenzen auf Streaming-Diensten, Online-Shops und Social-Media-Plattformen. Durch die Beobachtung von Nutzeraktionen kann DRL Inhalte oder Produkte empfehlen, die stärker mit individuellen Präferenzen übereinstimmen.
FAQs zu Deep Reinforcement Learning
- Wie lernt ein Agent beim Deep Reinforcement Learning?
Bei DRL lernt ein Agent, indem er in einer Umgebung Aktionen ausführt und Feedback in Form von Belohnungen erhält. Der Agent nutzt Exploration (das Ausprobieren neuer Aktionen), um effektive Strategien zu entdecken, und Exploitation (die Nutzung bekannter Aktionen), um Belohnungen zu maximieren. Tiefe neuronale Netze helfen dem Agenten, aus seinen Erfahrungen zu generalisieren und sich an komplexe Szenarien anzupassen.
- Wie balancieren Deep-Reinforcement-Learning-Modelle Exploration und Exploitation aus?
DRL-Modelle balancieren Exploration (das Ausprobieren neuer Aktionen, um bessere Strategien zu entdecken) und Exploitation (die Nutzung bekannter Aktionen, um Belohnungen zu maximieren) durch Algorithmen wie Epsilon-Greedy oder Thompson Sampling aus. Diese Techniken helfen, ein Gleichgewicht aufrechtzuerhalten, sodass der Agent neue Strategien entdeckt und gleichzeitig bekannte Belohnungen maximiert.
- Wie funktionieren Wertfunktionen beim Deep Reinforcement Learning?
Wertfunktionen schätzen die erwartete Belohnung dafür, sich in einem bestimmten Zustand zu befinden (Zustandswertfunktion) oder in einem gegebenen Zustand eine bestimmte Aktion auszuführen (Aktionswertfunktion). Sie helfen dem Agenten, Zustände und Aktionen zu priorisieren, die zu höheren Belohnungen führen, und leiten so die Entscheidungsfindung.
- Wie kann DRL mit Milvus für KI-Anwendungen verwendet werden?
Milvus kann die hochdimensionalen Zustandsrepräsentationen speichern und verwalten, die von DRL-Agenten erzeugt werden. Es kann als Replay Buffer für vergangene Erfahrungen dienen oder bei der Speicherung von Zustandsrepräsentationen unterstützen und so die Effizienz der Policy-Optimierung und Wertschätzung verbessern.
- Welche ethischen Bedenken gibt es bei der Nutzung von Deep Reinforcement Learning?
Zu den ethischen Bedenken gehören potenzielle Verzerrungen in Trainingsdaten, unbeabsichtigte Verhaltensweisen, die aus schlecht gestalteten Belohnungsfunktionen entstehen, und Fairness-Probleme in sensiblen Anwendungen. Um diese Risiken zu mindern, ist es entscheidend, robuste Tests, Transparenz und erklärbare KI zu implementieren.
Verwandte Ressourcen
Zur weiteren Erkundung sollten Sie diese Ressourcen in Betracht ziehen:
- Was ist Deep Reinforcement Learning?
- Wie Deep Reinforcement Learning funktioniert
- Beliebte Algorithmen im Deep Reinforcement Learning
- Vergleich von Deep Reinforcement Learning mit anderen Konzepten
- Vorteile und Herausforderungen des Deep Reinforcement Learning
- Praxisanwendungen von Deep Reinforcement Learning
- FAQs zu Deep Reinforcement Learning
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren