




Milvus: The Key to RAG Development - Improve Efficiency, Reduce Costs, and Enhance Performance
Introduction
In my previous blog, we looked at how Retrieval Augmented Generation (RAG) addresses the challenges large language models (LLMs) face, such as hallucinations and the need for domain-specific information. We also emphasized its role in ensuring data privacy and enabling real-time information retrieval.
At the heart of a basic RAG framework lie two crucial elements: the Retriever and the Generator. The Retriever, powered by a vector database, provides contextual information for user queries, while the Generator, often driven by LLMs like ChatGPT, crafts final responses based on this context. Understanding these technical aspects will make you feel more informed about the intricacies of RAG.
As developers push the boundaries of RAG applications and transition them into production environments, they need faster, higher-quality, and more precise answers. This underscores the critical importance of robust vector databases in enabling improved retrieval efficiency and quality.
The latest release of Milvus represents a noteworthy advancement in vector database technology, particularly in enhancing RAG performance. This post will jump into Milvus's latest features, highlight its functionalities, and illustrate why it is the premier choice for developing successful RAG applications.
Streamlining RAG Development and Validation Through Integrating with Popular Embedding and Renranking Models
While a basic RAG setup is enough for prototyping or small projects, it falls short for production-ready applications. As developers advance to more complex RAG apps, they incorporate additional technical components into the pipeline, adding to the development complexity. Moreover, the rapid evolution and parameter variations in RAG-related technologies add further hurdles to app building, fine-tuning, and validation. To address these challenges, many RAG developers turn to frameworks or libraries like LangChain, LlamaIndex, and DSPy, which offer extensive functionality for streamlined development and validation.
Milvus is a specialized vector database for efficient data storage and retrieval. In its latest release, Milvus seamlessly integrates mainstream embedding and reranking models, enabling users to easily transform text into searchable vectors and rerank the retrieved results for more accurate answers without adding additional embedding and reranking components to the RAG pipeline. As a result, this integration streamlines the overall RAG development and validation process.
Milvus currently supports a range of popular embedding, including OpenAI Embedding API, sentence transformers, BGE-M3, BM25, SPLADE, and Voyage AI.
| Integrated embedding models | Vector type | API or open-source |
| OpenAI Embedding API | Dense | API |
| sentence transformers | Dense | Open-source |
| BM25 | Sparse | Open-source |
| SPLADE | Sparse | Open-source |
| BGE-M3 | Hybrid | Open-source |
| Voyage AI | Dense | API |
Milvus currently supports the following reranking models: BGE, Cross-encoder, Voyage AI, and Cohere.
| Integrated reranking models | API or Open-sourced |
| BGE rerankers | Open-sourced |
| Cross encoders | Open-sourced |
| Voyage AI rerankers | API |
| Cohere rerankers | API |
We will support more models in the following months. Stay tuned. The Milvus documentation provides detailed guidance on leveraging these pre-trained embedding models.
Enhancing Retrieval Quality and Multimodal Data Retrieval with Hybrid Search
Real-world RAG applications are used in diverse use cases dealing with text and multimodal data like images, videos, and audio. Handling rich information requires a vector database to efficiently store and retrieve embeddings across various data types to cater to multimodal queries.
Milvus steps up to the plate by offering multi-vector support and a hybrid search framework. Users can consolidate multiple vector fields, up to 10, within a single collection. Vectors in these fields can represent different aspects or modalities of data related to the same entity, significantly enriching the information pool.
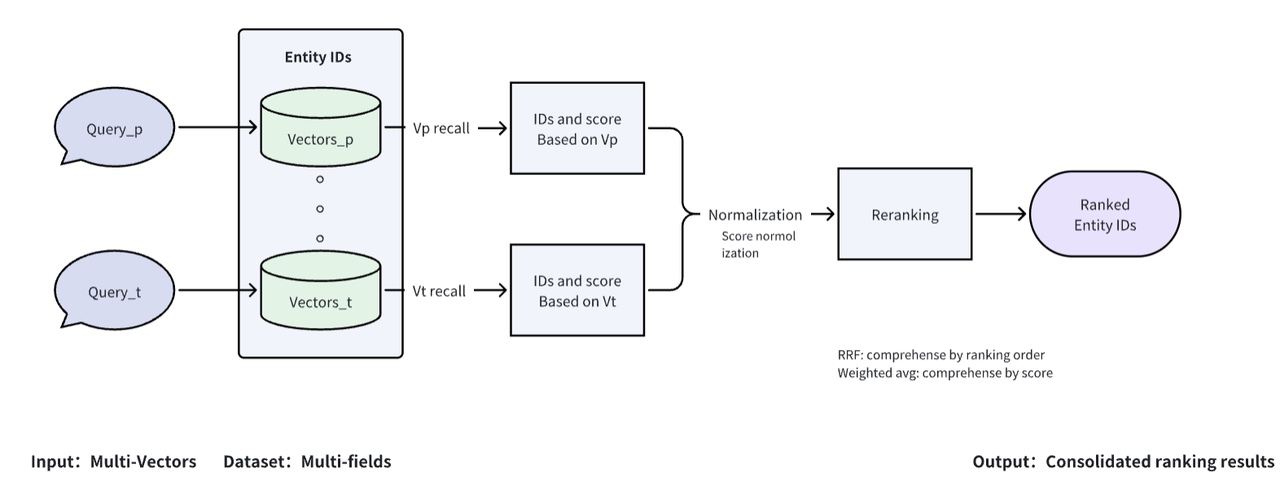 Fig1: How Milvus conducts a hybrid search
Fig1: How Milvus conducts a hybrid search
This hybrid search capability and mixed reranking strategies provide enhanced flexibility in retrieving multimodal and multidimensional information. It proves invaluable in use cases like identifying the most similar individual in a vector library based on attributes such as pictures, voice, and fingerprints.
Moreover, Milvus extends its hybrid search to support sparse vectors widely utilized for out-of-domain knowledge and keyword retrieval. This extension enables mixed retrieval of keywords and vector embeddings, leading to more precise retrieval results and ultimately improving the accuracy of final answer generation in your RAG application.
Improving Retrieval Speed and Accuracy with Upgraded Scalar-Filtered Search
In practical applications, not all data is suitable for vector search. Take, for instance, a chatbot focusing on clothing inventory. Alongside vectors, the data contains numerous attributes like color and size. Filtering such scalar data before or after vector search proves more efficient and quicker than converting it into vectors.
Milvus supports scalar-filtered search, strengthening retrieval precision and speed. Recent upgrades to this feature include:
Grouping Search Function: This function utilizes scalar column aggregation to deliver refined, high-level aggregated data. It streamlines searches, especially in use cases such as searching for a specific number of documents related to a query.
Fuzzy Matching for Scalar Columns: Fuzzy queries for scalar columns now encompass infix and suffix matching, elevating search quality beyond the previously supported prefix matching.
Inverted Index for Accelerated Search Speeds: The introduction of the Inverted Index can increase performance by over tenfold in reverse search use cases.
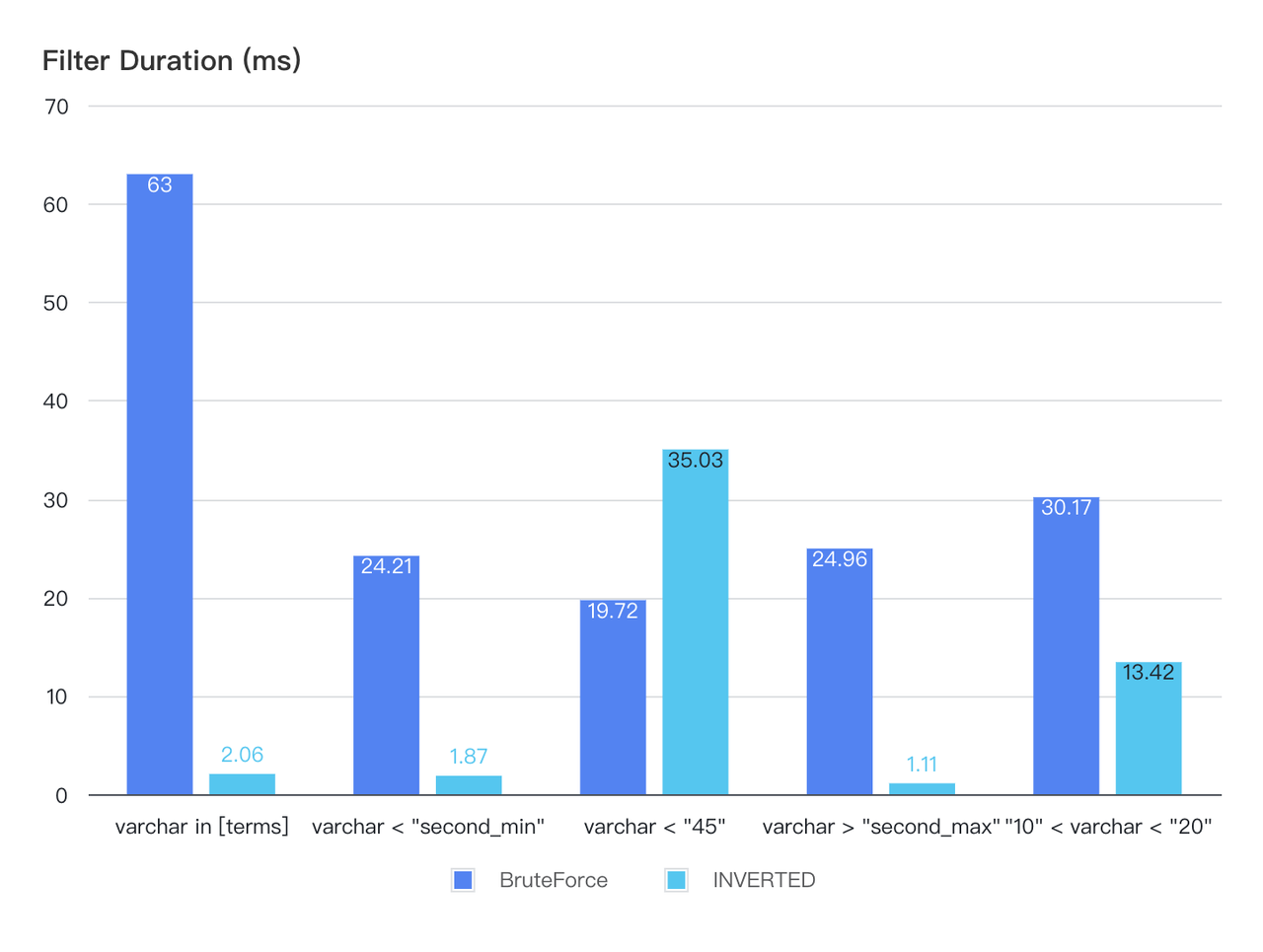 Fig2: The inverted index improves the search speeds by 10x
Fig2: The inverted index improves the search speeds by 10x
These enhancements empower RAG systems to tailor their approaches to specific business requirements. For example, users can efficiently search legal documents based on case dates or filter relevant news reports by geographic location. This multidimensional search approach enhances your RAG application’s precision and efficiency in handling targeted queries.
Offering Cost-Efficient RAG Solutions
Building and maintaining a large knowledge base for your RAG app can be financially costly, mainly because datasets continue to expand. Therefore, cost-effective solutions that facilitate the management of vast amounts of data are needed.
Milvus offers a cost-effective solution as an open-source vector database under the Apache-2.0 license, free from licensing costs. Its suite of high-performance features comes readily available without any additional costs.
Moreover, Milvus integrates Mmap to minimize memory consumption, optimizing resource allocation. Milvus goes the extra mile by introducing tiered cold and hot data storage capabilities tailored to accommodate data with varying access frequencies and latency requirements. Milvus reduces storage costs by strategically placing data across different storage media such as RAM, NVMe, EBS, and S3 and tapping into cloud storage capabilities. Intelligent caching and data-sharding techniques further contribute to resource efficiency during queries, enabling Milvus-powered RAG applications to operate at lower costs without compromising performance.
 Fig3: How the tiered cold and hot data storage approach work
Fig3: How the tiered cold and hot data storage approach work
This approach minimizes the initial investment and ensures ongoing operational efficiency, making Milvus an ideal choice for cost-conscious RAG implementations.
Summary
From its integration with popular embedding models to its capabilities of multimodal data retrieval and upgraded scalar-filtered search, the Milvus vector database helps developers build faster, more accurate, and more versatile RAG applications than ever.
Additionally, Milvus offers a cost-effective solution for building and maintaining large knowledge bases with its open-source soul, high-performance features, and optimized storage strategies. By minimizing memory consumption, implementing tiered data storage, and leveraging intelligent caching and data-sharding techniques, Milvus enables RAG applications to operate efficiently at lower costs without sacrificing performance.
In conclusion, Milvus transforms RAG development by providing developers with the tools to build faster, more accurate, and cost-efficient applications. With Milvus, the possibilities for RAG innovation are endless, and the future of information retrieval is brighter than ever.

Keep Reading

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.