




Vector Databases Are the Base of RAG Retrieval
Why Will RAG Stay Despite LLMs’ Advancements?
Implementing a chatbot powered by Retrieval Augmented Generation (RAG) technology is a game-changer for businesses looking to enhance their customer support. This approach combines the conversational abilities of large language models with knowledge stored in rag database from diverse fields, such as legal advising, customer support bots, educational assistance, healthcare, and more.
A standard Retrieval Augmented Generation framework consists of two core systems: the Retriever and the Generator. The Retriever segments data (like documents), encodes data into vector embeddings, creates indices (Chunks Vectors), and retrieves the semantically relevant results by conducting a semantic search with the vector embeddings. The Generator, on the other hand, uses the context gleaned from the retrieval process to prompt the large language models (LLM), which in turn generates precise responses.
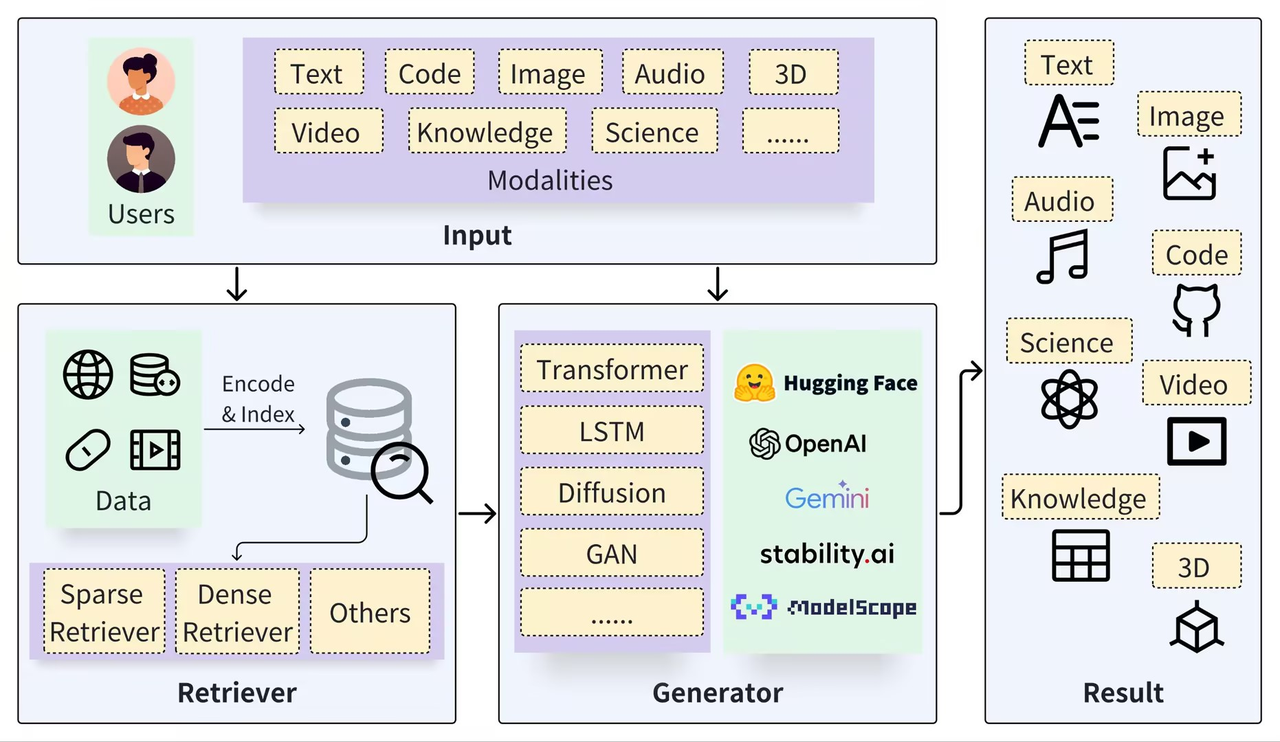
A generic RAG architecture. The user queries, spanning different modalities, serve as input to both the retriever and the generator. The retriever extracts relevant information from data sources. The generator interacts with the retrieval results and ultimately produces outcomes of various modalities. Source: https://arxiv.org/pdf/2402.19473
The effectiveness of Retrieval Augmented Generation systems stems from its synergistic combination of retrieval systems and generative models. Retrieval systems deliver precise, relevant information, facts and data, while generative models craft flexible, contextually enriched responses. This dual approach allows RAG to handle complex inquiries and produce rich, informative answers effectively, proving invaluable in systems requiring nuanced natural language processing, understanding and generation.
Retrieval Augmented Generation technology is advantageous over traditional large language models, including:
Reduction of "Hallucination" Issues: Retrieval Augmented Generation leverages external relevant data to aid LLMs in generating more accurate responses, enhancing the reliability and traceability of the output.
Enhanced Data Privacy and Security: RAG can securely manage private data as an external knowledge base extension, preventing potential data breaches after model training.
Real-time Information Retrieval: RAG facilitates the real-time acquisition of up-to-date, domain-specific relevant information, addressing the challenge of out-of-date information.
While ongoing advancements in LLMs also address these issues through strategies like fine-tuning on private datasets and providing longer-text windows training data, RAG remains a robust, reliable, and cost-effective solution in broader GenAI applications due to its:
Transparency and Operability: Unlike the opaque processes of fine-tuning and long-text management, RAG offers clearer, more interconnected module relationships, improving tunability and interpretability.
Cost Efficiency and Quick Response: RAG requires less training time and incurs lower costs than fine-tuned models. It also outpaces long-context processing LLMs in response speed and operational costs.
Private Data Management: By separating the knowledge base from LLMs, RAG secures a practical implementation ground and effectively manages existing and newly acquired enterprise knowledge.
Even though many people predict RAG is on the verge of demise as LLMs continue to evolve and advance, I still believe that RAG technology will stay. RAG is inherently complementary to LLMs, which ensures its prolonged relevance and success across multiple applications.
Vector Databases Are the Base of RAG Retrieval
In real-world production applications, RAG retrieval is often tightly integrated with vector databases, leading to the development of a popular Retrieval Augmented Generation solution known as the CVP stack, comprising ChatGPT, Vector Database, and Prompt-as-code technologies. This innovative solution leverages vector dbs' efficient similarity retrieval capabilities to enhance LLMs' performance. The RAG system can rapidly retrieve relevant knowledge entries within the vector database by transforming user queries into vector embeddings. This approach enables LLMs to access the most up-to-date information stored in the database when responding to user queries, effectively addressing issues such as delays in knowledge updates and the occasional inaccuracies in generated content, often called "hallucinations."
Many other retrieval technologies, including search engines, relational databases, and document databases, are available on the market in addition to popular vector databases and dbs. However, vector databases are the most favored option in RAG implementations due to their superior capabilities in efficiently storing and retrieving vast quantities of vector embeddings. Produced by machine learning models, these vectors represent a wide range of data types, including text, images, videos, and sounds, while capturing intricate semantic details.
Below is a comparative analysis of vector dbs against other technological options in information retrieval, highlighting why vector dbs have become the preferred choice in building RAG applications.
| Category | Search Engines | Relational Databases | Document Databases | Vector Databases |
| Primary Products | Elasticsearch | MySQL | MongoDB | Milvus |
| Implementation Principle | Utilizes inverted indexingfor fast text searches with limited vector search capabilities | Employs standardized data models and SQL for optimal transaction processing, struggles with handling unstructured data | Stores data in JSON format, offering flexible data models and basic full-text search but limited semantic search capabilities | Designed specifically for high-dimensional vectors, uses Approximate Nearest Neighbor (ANN) algorithms for effective semantic similarity searches |
| Use Cases | Ideal for full-text searches and straightforward data analysis | Best for applications demanding high consistency and intricate transaction management | Well-suited for rapid development and environments with frequent data model changes | Optimal for unstructured data-based retrieval like image and semantic text searches |
| Large Vector Dataset Retrieval Efficiency (The higher the better) | Medium | Low | Low | High |
| Multimodal Generalization Capability (The higher the better) | Medium | Low | Low | High |
| Suitability for RAG Retrieval(The higher the better) | Medium | Low | Low | High |
| Total Costs(The lower the better) | High | High | Medium | Low |
Compare vector databases with other information retrieval technologies
As shown in the table above, vector databases are advantageous in the following fields:
Implementation Principle: Vectors encode semantic meanings, and vector dbs decode query semantics using deep learning models, moving beyond simple keyword searches. The precision of semantic understanding has improved with AI advancements, making vector distance a standard measure of semantic similarity in NLP and positioning embeddings as the preferred format for managing diverse data types.
Retrieval Efficiency: High-dimensional vectors allow for advanced indexing and quantization techniques that significantly boost retrieval speed and reduce storage demands. Vector dbs can scale horizontally to manage growing data volumes while maintaining quick response times, essential for RAG systems dealing new data, with extensive relevant data.
Generalization Capability: Unlike traditional databases that mostly handle text, vector dbs store and process various types unstructured data, including images, videos, and audio. This versatility enhances the flexibility and functionality of RAG systems.
Total Ownership Cost: Vector dbs are easier to deploy and integrate with existing machine learning frameworks due to their straightforward setup and comprehensive APIs. This accessibility, coupled with lower overall costs, makes them a favorite among developers of RAG applications.
Enhancing Vector Databases for More Performant RAG Applications
Vector dbs have been a fundamental retrieval technology in RAG systems. However, as developers build increasingly complicated RAG applications and use them in production environments, their demand for higher-quality and more precise answers to user query grows, posing challenges to vector databases.
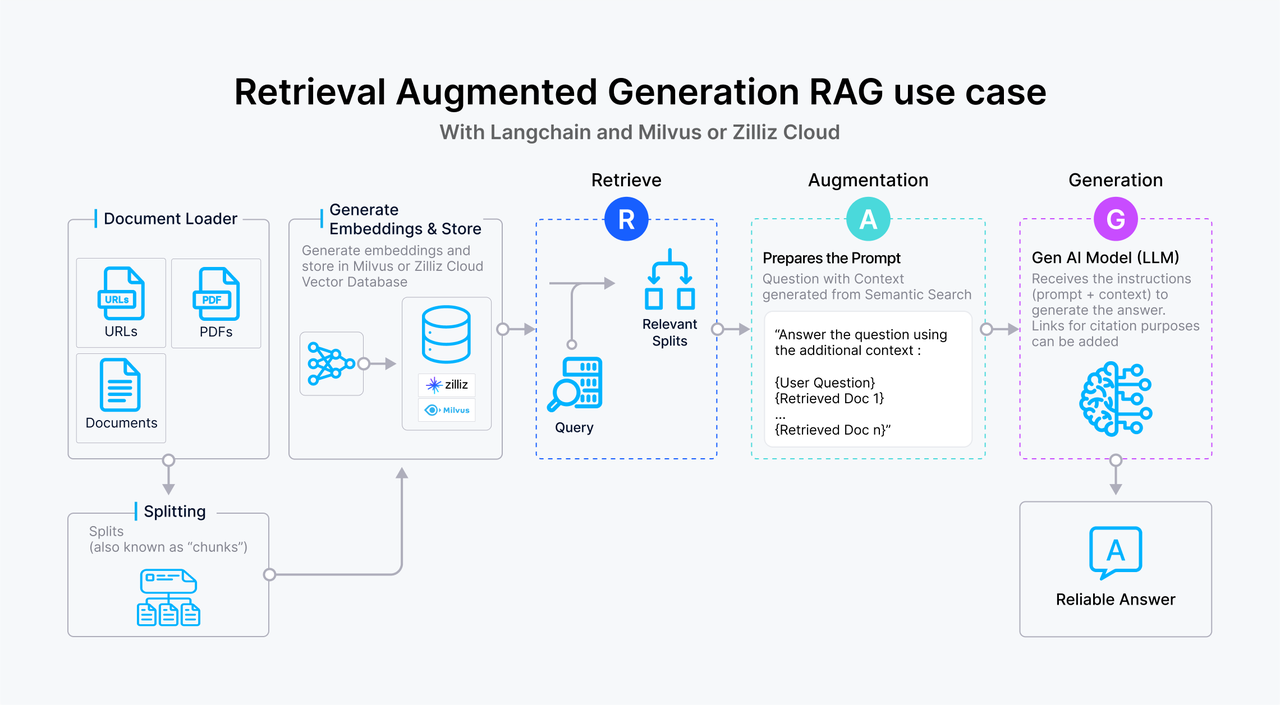 RAG use case.png
RAG use case.png
A standard Retrieval Augmented Generation construction process usually involves several steps: preprocessing data through segmentation, data cleaning, and embedding; building and managing indexes; and using vector search to locate similar segments to improve prompt generation. Most vector dbs handle index building and management and vector data retrieval, with just a few, like Milvus, providing built-in embedding functions. Therefore, the quality of vector data retrieval directly impacts the relevance and effectiveness of the LLM-generated content.
Numerous engineering optimizations emerge to enhance the retrieval quality of vector dbs, including selecting appropriate chunk sizes, deciding on the necessity of overlapping segments, choosing appropriate embedding models, adding content tags, integrating lexicon-based retrieval for a hybrid semantic search approach, and selecting rerankers. We could integrate many of these tasks within vector dbs.
Specifically, vector databases should improve the following areas:
High Precision in retrieval: Vector dbs must excel in accurately retrieving the most relevant documents or data snippets based on user queries through vector similarity searches. This entails processing and interpreting intricate semantic relationships within high-dimensional vector spaces to ensure that the retrieved content is precisely aligned with the user's query.
Rapid Response: To ensure an optimal user experience, vector dbs must deliver retrievals within milliseconds. This demands the ability to swiftly access and extract information from extensive datasets. As data volumes increase and query complexities grow, these databases need to scale flexibly, handling larger datasets and more sophisticated queries while consistently maintaining reliable recall performance.
Multimodal Data Handling: Given the broadening range of use cases, vector dbs must not only manage textual data but also handle images, videos, and other types of multimodal data. This requires support for embeddings from diverse data types and the ability to efficiently retrieve information based on varied modal queries.
Interpretability and Debuggability: It is also essential for vector dbs to offer robust diagnostic and optimization tools to address issues when results are not retrieved effectively.
Wrapping Up
As the demand for Retrieval Augmented Generation (RAG) applications continues to rise, developers are increasingly utilizing RAG technology for a variety of purposes most notably for contextually relevant information gathering. This growing adoption is poised to change numerous industries by dramatically improving the efficiency factual accuracy of information retrieval and knowledge acquisition, ultimately reshaping how organizations access and use data.
Vector dbs, while still relatively underutilized, hold immense potential as the foundational infrastructure for RAG systems. Among these, the Milvus vector database stands out, actively addressing and overcoming the challenges associated with developing and enhancing RAG applications. By leveraging insights from Generative AI developers, Milvus is continuously refining its capabilities to better serve the needs of the artificial intelligence industry.
In my upcoming post, I will dive into the open-source Milvus vector database, highlighting its latest features and explaining why it is the ideal choice for building enterprise-ready RAG applications. Stay tuned for more insights.

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.