




Tame High-Cardinality Categorical Data in Agentic SQL Generation with VectorDBs
Agentic workflows and large language models (LLMs) have fundamentally changed how we approach text-to-SQL systems and enable users to query databases using natural language like never before. As these systems evolve, we encounter various novel challenges in translating human intent into accurate SQL queries.
One significant problem is handling high-cardinality categorical data. This article explores how integrating vector databases with agentic text-to-SQL systems can address this challenge. Specifically, we will show how the combination of Waii and Zilliz Cloud (the fully managed Milvus vector database) automatically handles this issue.
The Challenge of High-Cardinality Categorical Data
Categorical data is ubiquitous in databases - think product categories, customer segments, or transaction types. In many cases, the number of unique values (cardinality) in these categories is manageable. For instance, a column for U.S. states will have at most 50 unique values (plus territories). These low-cardinality columns are relatively easy for text-to-SQL systems to handle, as the gap between natural language queries and database values is small.
The challenge arises when we encounter high-cardinality categorical data. Over 60% of databases we have worked with have examples of this situation: Imagine a product catalog with millions of unique product IDs or a financial database with hundreds of thousands of company identifiers.
Databases require precise, rigid lookups for these categories, but natural language queries are often fluid and imprecise. A user might ask for "popular smartphones" or "tech companies that did well recently," but translating these vague terms into specific database values is where traditional text-to-SQL approaches fall short, leaving a wealth of data out of reach.
Why Existing Methods Don't Work
Often, text-to-SQL systems employ one of the following two methods when translating natural language queries involving high-cardinality categorical data:
Preprocessed Database Techniques: This approach relies on traditional database capabilities like text search and regular expressions, combined with input preprocessing. While it can handle simple matches, it's often too inflexible to accurately represent the user's intent, especially with complex or nuanced queries. The rigid nature of these techniques struggles to bridge the gap between natural language variability and precise database values.
LLM-Based Translation: In this method, the system uses an LLM to predict the correct categorical values based on training data or few-shot examples. While LLMs excel at understanding context and natural language, they often produce incorrect results when dealing with high-cardinality data. This is because the LLM lacks knowledge of the complete (and often private) dataset and struggles with accurately recalling millions of unique identifiers that weren't part of its training data.
For high-cardinality data, both methods fall short. The preprocessed database techniques are too inflexible and literal to handle the nuances of natural language queries effectively. LLMs, on the other hand, may understand the query intent but can't reliably map it to the correct values in a large, specific dataset they haven't been trained on. This leaves us with a significant gap in translating natural language queries to accurate SQL for high-cardinality categorical data.
Enter Vector Databases
This is where vector databases come into play. Modern information retrieval uses vector embeddings to conduct semantic searches rather than keyword matches. vector databases are designed to store and efficiently query high-dimensional vector representations of data. In our context, we can leverage them to bridge natural language queries and high-cardinality categorical data.
Here's how it works:
Create Vector Embeddings: Create a vector embedding for each unique value in your high-cardinality column. This embedding captures the semantic meaning of the value by mapping it to a vector in a high-dimensional space.
Index in a VectorDB: Store these embeddings in a vector database like Milvus, which is optimized for fast similarity searches in high-dimensional spaces.
Query Processing: When a user submits a natural language query, use an LLM to understand the intent and generate a preliminary SQL query. For high-cardinality columns, instead of trying to generate specific values, the LLM generates a description or characteristics of the desired values.
Vector Search: Use the embedding of this description to perform a similarity search for the embedding of a massive amount of unique values in the vector database, retrieving the most relevant categorical values.
Refinement: The LLM can then refine these results, filtering out any irrelevant matches based on the full context of the user's query.
SQL Generation: Generate the final SQL query by using the refined list of categorical values to build the appropriate filters and aggregates.
Benefits of Using Vector Search in Text-to-SQL
This vectorDB-enhanced approach offers several advantages:
Scalability: It can handle categories with millions of unique values without significant performance degradation.
Accuracy: By combining LLMs' semantic understanding with vector databases' precise recall, we can more accurately translate user intent to specific database values.
Flexibility: This method can adapt to changes in the database without requiring retraining of the entire system.
Implementation Considerations
It is naturally possible to build the flows required to implement the described approach from scratch, but we believe that combining Waii and Zilliz Cloud offers significant advantages.
Waii is the world's first text-to-SQL API built on agentic workflows. It combines compiler technology with an automatically generated knowledge graph for the most accurate query generation.
Complementing Waii's capabilities, Zilliz Cloud is the vector database underpinning AI workflows. Its ability to scale and deliver accurate results with low latency makes it the natural choice in the AI stack.
The combination gives you a scalable solution out of the box:
Waii for Intelligent Text-to-SQL
Automatic Detection: Waii automatically identifies these high-cardinality columns, eliminating the need for manual configuration.
Smart Embedding Generation: It employs tailored workflows to build and update embeddings for different types of columns, optimizing for both accuracy and resource efficiency.
Adaptive Techniques: Waii automatically selects appropriate techniques for various column types, ensuring optimal performance without requiring deep expertise from the user.
Zilliz Cloud for Vector Semantic Search
Scalability: Zilliz Cloud can handle billions of vectors with ease, making it ideal for high-cardinality data scenarios.
Lightning-Fast Queries: Its optimized indexing ensures rapid similarity searches, critical for maintaining low latency in production environments.
Security and Access Control: Zilliz Cloud provides enterprise-grade data security and privacy compliance through secure networking options and encryption protocols. This ensures data safety during both transfer and when at rest. Additionally, Zilliz Cloud offers sophisticated identity control and access management, including Role-Based Access Control (RBAC) and OAuth 2.0 for secure, centralized Single Sign-On (SSO) capabilities.
Integration of Waii and Zilliz Cloud
Seamless Workflow: The combination of Waii's automatic preprocessing and Zilliz's powerful vector storage creates a smooth, end-to-end solution for handling high-cardinality data in text-to-SQL systems.
Production-Ready: This pairing is designed for real-world, large-scale challenges, making it suitable for production deployments across various industries.
By leveraging Waii's automatic detection and embedding generation with Zilliz, you can implement a robust solution for handling high-cardinality categorical data in your text-to-SQL system without custom code for metadata management or embedding generation.
A Practical Example
Let's consider a global event management platform with millions of events. The database schema includes:
CREATE TABLE events (
event_id INT PRIMARY KEY,
event_name VARCHAR(255),
event_date DATE,
category VARCHAR(100),
total_spent DECIMAL(10, 2)
);
The event_name is a high-cardinality categorical column, with millions of unique, descriptive names like "Global AI Ethics Summit 2024", "Sustainable Living Expo: Greening Our Future", or "5th Annual Quantum Computing Breakthrough Conference".
An analyst might ask: "How much money was spent on AI events last month?"
Here's how different approaches might handle this:
Traditional Keyword Matching
In this approach we use the term provided by the user and plug it into the query as a search term. We use case insensitive full text search here, but generating equality filters is also common in this scenario.
SELECT SUM(total_spent)
FROM events
WHERE event_name ILIKE '%AI%'
AND event_date >=
DATE_TRUNC('month', CURRENT_DATE - INTERVAL '1 month')
AND event_date <
DATE_TRUNC('month', CURRENT_DATE);
Problem: This approach misses events like "Machine Learning Symposium" or "Neural Network Workshop" which are AI-related but don't contain "AI" in the name. It might also incorrectly include events like "HAIR styling convention".
Naive LLM Approach
In this approach, the LLM generates multiple terms that might be relevant for search and constructs a filter out of it. This can optionally be done with sample values from the column and with additional context about the database. It would typically produce something like:
SELECT SUM(total_spent)
FROM events
WHERE (event_name ILIKE '%AI%'
OR event_name ILIKE '%Artificial Intelligence%'
OR event_name ILIKE '%Machine Learning%'
OR event_name ILIKE '%Neural Network%')
AND event_date >=
DATE_TRUNC('month', CURRENT_DATE - INTERVAL '1 month')
AND event_date <
DATE_TRUNC('month', CURRENT_DATE);
Problem: While this catches more AI-related events, it's still limited to a predefined list of terms and might miss events with more specific or novel AI-related names. The problem of finding unrelated events also still exists.
Vector DB + LLM Approach
The following diagram depicts the overall flow. The left side is the preprocessing that's done on the events table, the right side shows the flow of generating the query.
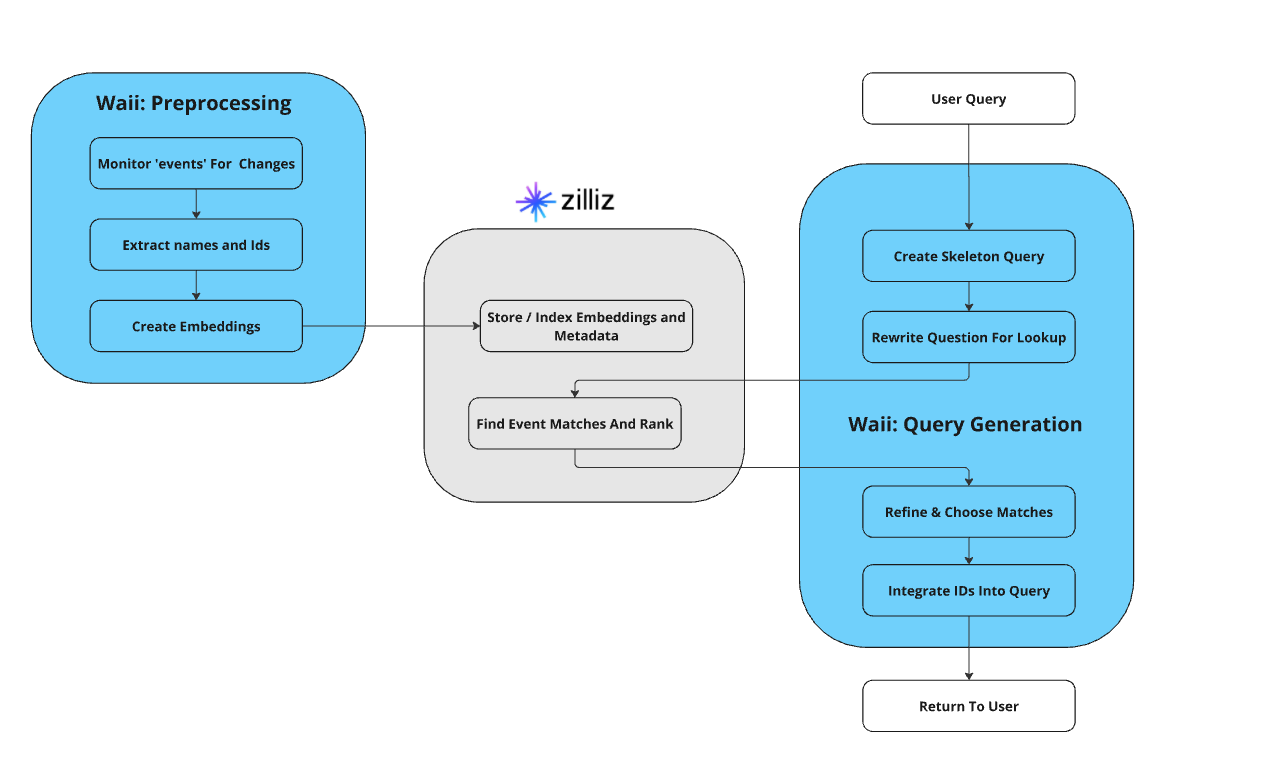 Figure- How the integration of Zilliz Cloud and Waii works
Figure- How the integration of Zilliz Cloud and Waii works
The query generation flow is:
Waii interprets the query and rewrites a description: "Events related to artificial intelligence, machine learning, neural networks, and other AI technologies."
This description is used to query Zilliz Cloud, returning a list of relevant event IDs based on semantic similarity.
Waii refines this list, filtering out any non-AI events that might have been inadvertently included.
Waii uses an agentic workflow incorporates these event IDs into the final SQL query:
SELECT SUM(total_spent)
FROM events
WHERE event_id IN (1234, 5678, 9101, 1121, 3141, 5161, 7181, 9202, 1222, 3242)
AND event_date >=
DATE_TRUNC('month', CURRENT_DATE - INTERVAL '1 month')
AND event_date <
DATE_TRUNC('month', CURRENT_DATE);
This approach can accurately identify AI-related events, even if they use specialized terminology or don't contain obvious keywords. It can capture events like "3rd Symposium on Generative Adversarial Networks" or "Workshop on Ethical Considerations in Reinforcement Learning", which the other approaches might miss.
By leveraging vector similarity search, we can more accurately interpret the user's intent and match it to the high-cardinality event names in our database, providing more comprehensive and accurate results.
Conclusion
As data volumes continue to grow and user expectations for intuitive data interactions increase, handling high-cardinality categorical data in text-to-SQL systems will only become more commonplace. By leveraging the power of Zilliz Cloud in conjunction with Waii, we can create more robust, scalable, and accurate systems.
We've seen promising results with this approach, and we believe it is beneficial for others facing similar challenges. Please feel free to reach out and let us know if you have tried this or similar approaches and share your insights.
 Jiang Chen
Jiang ChenJiang is currently Director of Technical GTM at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.
 Gunther Hagleitner
Gunther HagleitnerGunther Hagleitner is the current CEO and co-founder of Waii. He is a seasoned product and engineering leader with a 20+ year track record in SQL and analytics. Previously, as SVP at Cribl and CVP at Cloudera, he focused on simplifying data through innovation and open-source. Gunther excels at both scaling products and teams as well as new product introductions. He is passionate about creating user-centric solutions that solve real-world problems.
Keep Reading

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.