




Building a RAG Application with Milvus and Databricks DBRX
Introduction
Large Language Models (LLMs) keep developing quickly, and new models are being released regularly with improved capabilities compared to the previous versions. In March 2024, Databricks, a leading data platform, released its first open-source model, DBRX, a new state-of-the-art model with a fine-grained mixture-of-experts (MoE) architecture. This transformer-based decoder-only model has outperformed several benchmarks like MMLU, Programming (HumanEval), and Math (GSM8K).
Integrating DBRX into real-world applications has opened new avenues for building powerful GenAI apps, such as Retrieval Augmented Generation (RAG) systems. These systems combine the contextual understanding of LLMs with efficient information retrieval mechanisms to deliver highly accurate and contextually relevant responses, even for complex queries.
In this tutorial, we will explore how to build a robust RAG application by combining the capabilities of Milvus, a scalable vector database optimized for similarity search, and DBRX. Milvus enables efficient handling and querying of large-scale embeddings, while DBRX provides cutting-edge natural language processing (NLP) capabilities. Together, they create a synergy ideal for applications such as knowledge management, customer support, and personalized recommendations.
Jump to what you find most interesting:
Understanding RAG
Introducing Milvus
Introducing Databricks DBRX
Introducing the MoE architecture
Build RAG with Milvus and DBRX: A Step-by-step Guide
Understanding Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a hybrid approach that enhances the performance of LLMs by integrating external information retrieval systems. Traditional LLMs rely solely on their pre-trained knowledge and fine-tuning to generate responses, which can limit their effectiveness when faced with queries that require up-to-date or domain-specific information. RAG addresses this limitation by incorporating a retrieval mechanism that fetches relevant context or data from an external source, such as a vector database or a document repository, during inference.
A RAG system typically consists of two key components:
Retriever: This component is responsible for fetching relevant information from a large corpus or database based on the query or input. By converting textual data into embeddings, the retriever enables semantic search, leveraging vector databases, such as Milvus or Zilliz, as knowledge base storage systems and efficiently identifies the most relevant pieces of information.
Generator: Using the retrieved context as input, the LLM generates a response that is both informed by the external data and coherent with the input query. This ensures that the responses are not only accurate but also grounded in the most relevant and up-to-date information.
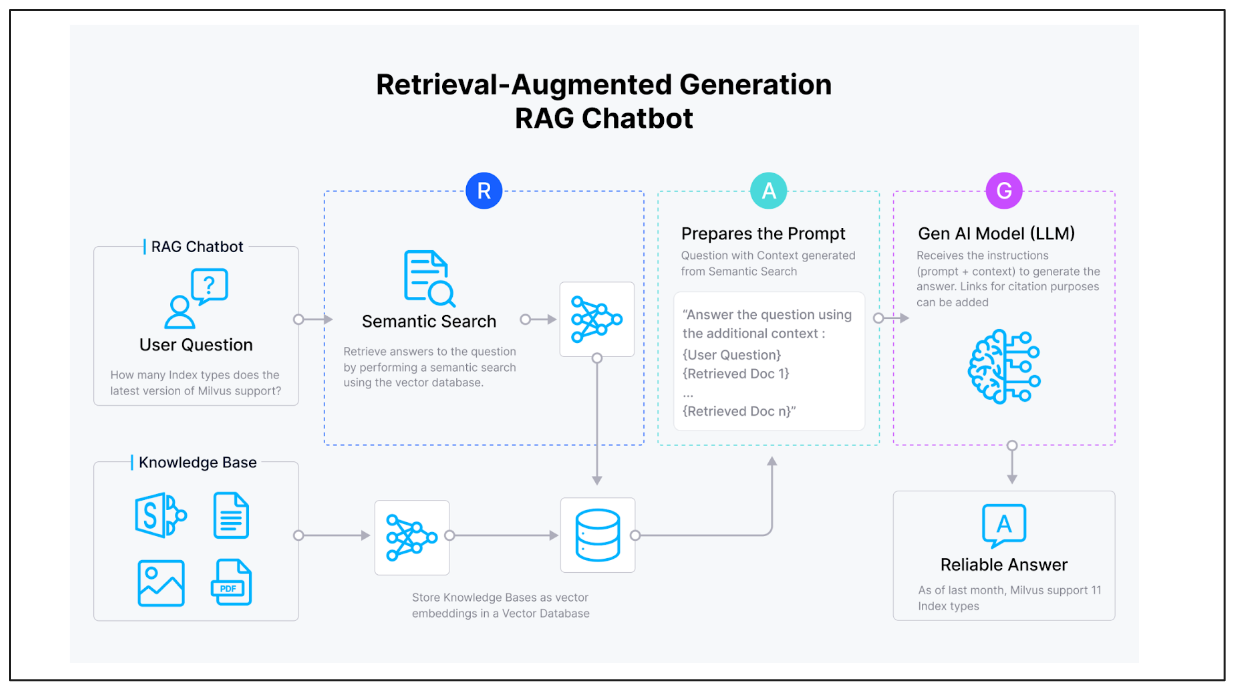 RAG architecture
RAG architecture
Figure 1: RAG Architecture
By combining retrieval and generation, RAG systems can produce responses that are more accurate, contextually aware, and factually grounded, making them highly valuable in use cases such as:
Knowledge Base Querying: Providing detailed and accurate answers from large, unstructured datasets.
Customer Support: Delivering personalized and precise responses by referencing specific knowledge bases.
Content Creation: Assisting with creative or technical writing by sourcing contextually relevant information.
Scientific Research: Summarizing research findings or answering domain-specific queries by pulling from academic papers or databases.
Milvus Vector Database
Milvus is an open-source vector database designed for managing, storing, and querying large-scale vector embeddings efficiently. It is widely used in applications that require similarity search and semantic retrieval, such as Retrieval-Augmented Generation (RAG) pipelines, recommendation systems, chatbots, semantic search engines etc.
Why is Milvus Ideal for RAG Systems?
In RAG systems, a vector database like Milvus acts as the backbone of the retriever component. Here's how it fits into the architecture:
Efficient Storage: Milvus can store billion-scale high-dimensional embeddings generated from textual or multimodal data, enabling compact and efficient representation of vast knowledge bases.
Fast Retrieval: When a query is input into the system, Milvus performs a semantic search to retrieve the most relevant embeddings, which are then used to provide context for the generator model.
Scalability: Milvus ensures that even as the size of the knowledge base grows, the retrieval process remains performant, allowing RAG systems to scale to enterprise demands.
Introducing DBRX
DBRX is Databricks' new LLM released in March 2024, as the company’s first open-source contribution to the growing ecosystem of advanced AI technologies. It comes in two versions: the base model (DBRX Base) and the fine-tuned model (DBRX Instruct). Built on a transformer-based, decoder-only architecture, DBRX employs a fine-grained mixture-of-experts (MoE) design that sets it apart from many existing models. This innovative architecture enables DBRX to dynamically allocate computational resources to different tasks or queries, making it highly efficient and adaptable to various use cases. Before we deep dive into DBRX, let’s learn some basics of the Mixture of Expert (MoE) architecture.
Mixture of Experts (MoE) Architecture
The mixture of experts is a neural network architecture that divides computational workloads across multiple specialized sub-models, or "experts." Unlike traditional models that activate all layers and parameters uniformly during inference, MoE dynamically selects and activates only a subset of experts most relevant to a given input. This selective activation introduces both efficiency and specialization.
The MoE architecture comes with the below key components:
Expert Networks: Multiple neural network modules, each trained to specialize in different types of inputs or tasks. These experts develop unique capabilities for processing specific data domains or solving particular problem types.
Router Mechanism: A sophisticated gating mechanism dynamically selects and activates the most appropriate experts for a given input. This routing system uses learnable parameters to determine which experts are most relevant for a given task.
Sparse Activation: Activate only a subset of experts to be activated for each input, dramatically reducing computational complexity while maintaining high performance. This approach ensures that not all model parameters are engaged simultaneously.
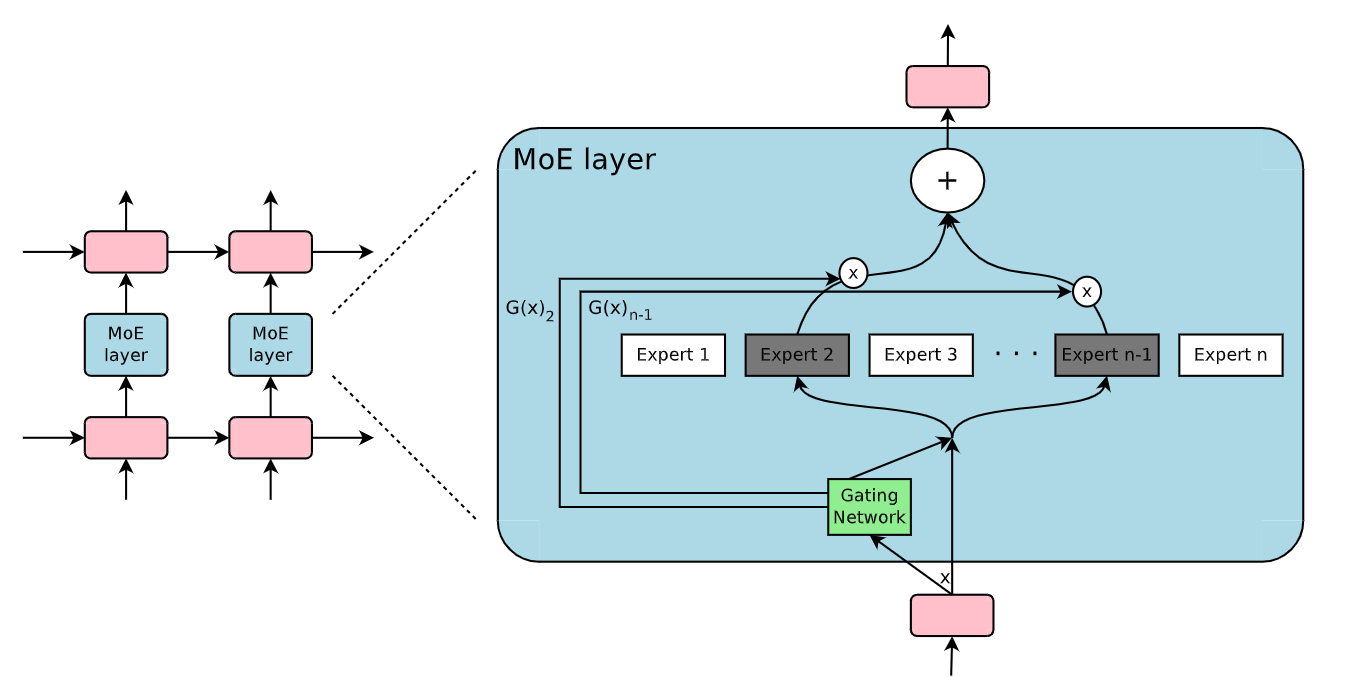 Figure 2: Mixture of Experts (MoE) layer
Figure 2: Mixture of Experts (MoE) layer
Figure 2: Mixture of Experts (MoE) layer | Source
The MoE architecture has various advantages, including:
Computational Efficiency: Activates only a subset of experts for each input, reducing overall computational requirements.
Deep Specialization: Allows individual expert networks to develop highly focused capabilities.
Scalable Architecture: Enables easier expansion of model capabilities by adding more experts.
Dynamic Resource Allocation: Intelligently routes inputs to the most appropriate computational resources.
DBRX key benefits
DBRX has achieved great results in key benchmarks:
MMLU (Massive Multitask Language Understanding): Demonstrates its broad general knowledge and reasoning abilities.
Programming Tasks (HumanEval): Excels in generating and understanding code, making it ideal for software development support.
Math Tasks (GSM8K): Shows strong aptitude in solving complex mathematical problems.
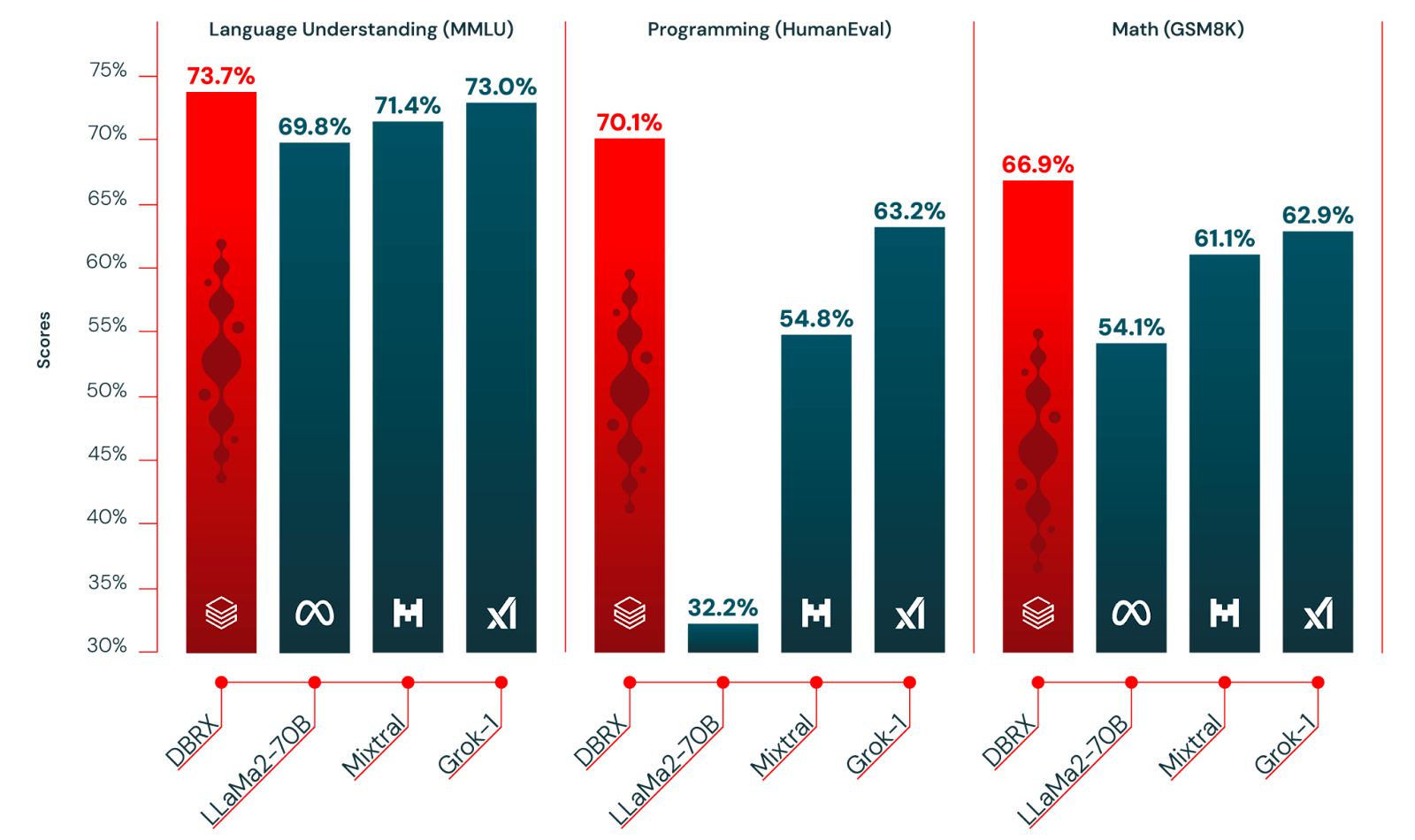 Figure 3: DBRX Benchmarks
Figure 3: DBRX Benchmarks
Figure 3: DBRX Benchmarks (Source)
Scalability and Efficiency:
DBRX is optimized for both large-scale deployments and resource-constrained environments, thanks to its MoE design which ensures high speed in terms of tokens processed per second.
Its scalability ensures suitability for a wide range of applications, from enterprise-grade systems to smaller, domain-specific setups.
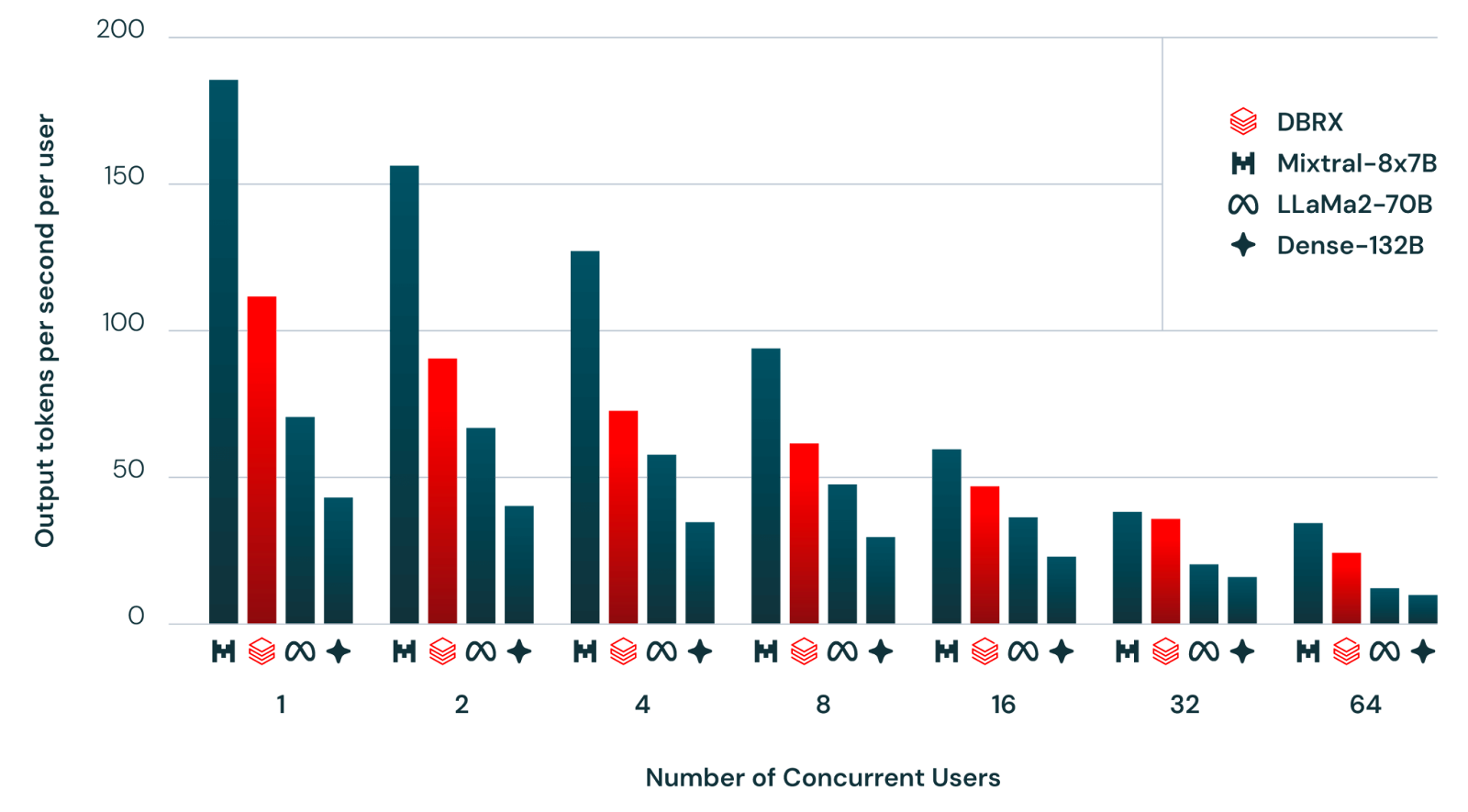 Figure 4: DBRX Inference
Figure 4: DBRX Inference
Figure 4: DBRX Inference (Source)
Open-Source Accessibility:
As an open-source model, DBRX empowers developers and organizations to experiment, adapt, and innovate without being tied to proprietary ecosystems.
The transparency of its development encourages a community-driven approach to model improvement and integration.
DBRX in RAG Systems
DBRX is well-suited for Retrieval-Augmented Generation (RAG) systems due to its ability to generate contextually accurate and coherent responses based on retrieved information. Key advantages include:
Contextual Adaptability: DBRX seamlessly integrates retrieved context into its generative outputs, ensuring that responses are highly relevant and specific to the query.
Domain-Specific Fine-Tuning: While DBRX performs exceptionally well out-of-the-box, it can also be fine-tuned with domain-specific data to further enhance its accuracy and relevance for specialized applications.
Efficiency in Complex Tasks:.With its MoE architecture, DBRX can handle complex, multi-faceted queries by efficiently leveraging its specialized experts, making it ideal for demanding RAG systems.
RAG Application with Milvus and DBRX
This notebook tutorial demonstrates how to implement a Retrieval-Augmented Generation (RAG) pipeline using Milvus as a vector store, DBRX as the language model, and LangChain as the framework. Given the model's size, this implementation leverages a Databricks workspace serving endpoint. Alternatively, the model can be downloaded via Ollama or the Hugging Face Transformers library, though this requires a high-performance GPU.
Step 1: Load the Data
The data source for this tutorial is the official Databricks DBRX release blog. The document is loaded and split into manageable chunks using a recursive text-splitting method.
# Load and split the documents
loader = WebBaseLoader("https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
Step 2: Load Embeddings
Next, we utilize open-source embeddings from Hugging Face to encode the document content for retrieval purposes.
# Load embeddings
embeddings = HuggingFaceBgeEmbeddings(
model_name = "BAAI/bge-small-en-v1.5")
Step 3: Create Milvus Retriever
Milvus is configured as the vector store, enabling efficient similarity searches. Once set up, the retriever is tested with a sample query.
# Create Milvus Retriever
vectorstore = Milvus.from_documents(documents=docs,
embedding=embeddings,
collection_name='my_collection',
connection_args={
"uri": "./milvus_demo.db"}
)
retriever = vectorstore.as_retriever()
# Test retriever
query = "What is DBRX?"
vectorstore.similarity_search(query, k=1)
```
Output:
[Document(metadata={'description': '', 'language': 'en-US', 'pk': 454492864071335939, 'source': 'https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm', 'title': 'Introducing DBRX: A New State-of-the-Art Open LLM | Databricks Blog'}, page_content='and GPT-3.5 Turbo on RAG tasks.Training mixture-of-experts models is hard. We had to overcome a variety of scientific and performance challenges to build a pipeline robust enough
```
Step 4: Implement RAG Pipeline
The RAG pipeline integrates the Databricks DBRX model for question-answering tasks. To use the model outside of a Databricks workspace, you need to set the Databricks Host URL and Token. The pipeline also includes a prompt template for concise and context-specific responses.
# Load environment variables
DATABRICKS_HOST = userdata.get('DATABRICKS_HOST')
DATABRICKS_TOKEN = userdata.get('DATABRICKS_TOKEN')
# Set RAG pipeline with Databricks DBRX
llm = ChatDatabricks(endpoint="dbrx-instruct",
max_tokens=200)
PROMPT_TEMPLATE = """
Human: You are an AI assistant,that provides answers to questions related to Databricks.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use only reliable Databricks information.
Assistant:"""
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
Finally, the RAG chain is constructed to handle the retrieval and generation process. The chain processes queries using the retriever, formats the results, and generates answers using the DBRX model.
# Define the RAG (Retrieval-Augmented Generation) chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
res = rag_chain.invoke(query)
res
```
Output:
'DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with a total of 132B parameters, out of which 36B parameters are active for any given input. DBRX was pretrained on 12T tokens of text and code data, and it uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA). It also uses the GPT-4 tokenizer. DBRX is known for its efficiency, with inference being up to 2x faster than LLaMA2-70B, and it is about 40% of the size of Grok-1 in terms of both total and active parameter-counts. It surpasses GPT-3.5 and is competitive with Gemini 1.0 Pro, and it is especially capable as a code model, surpassing specialized models like CodeLLaMA-70B on programming tasks.'
```
This tutorial can be found in the following notebook.
Conclusion
The combination of DBRX's innovative Mixture of Experts (MoE) architecture and Milvus's scalable vector database establishes a robust foundation for building intelligent, context-aware AI systems. The fine-grained MoE design of DBRX allows it to dynamically adapt to diverse tasks, ensuring computational efficiency and exceptional performance across a variety of use cases. This capability is especially vital in Retrieval Augmented Generation (RAG) systems, where the ability to generate contextually accurate and domain-specific responses is paramount.
Milvus complements this architecture by enabling RAG systems to easily handle massive knowledge bases. This combination empowers applications in areas such as knowledge management, customer support, content creation, and scientific research, delivering relevant results grounded in the most accurate and up-to-date information. For developers and organizations, this represents a technological advancement and an opportunity to build more intelligent, responsive, and context-aware systems.
Related Resources

Keep Reading

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.