A Review of Hybrid Search in Milvus

Milvus 2.4 extended its hybrid search capabilities with the introduction of multi-vector columns within a single collection. This upgrade enables more advanced and flexible data searches by allowing simultaneous queries across multiple vector types and fields. The search results from each field are then integrated and re-ranked using multiple reranking algorithms to deliver more accurate outcomes.
Why is this capability important, and what benefits does it offer? What are the design strategies behind this feature? In this post, we will explore these questions. We will also provide a practical example comparing the results of single-vector and hybrid searches, demonstrating how this powerful new feature can yield more accurate results.
What is Hybrid Search?
Let's start with the basics: what is hybrid search in Milvus?
Milvus supports the creation of up to 10 vector fields for the same dataset within a single collection. Based on this support, hybrid search allows users to search across multiple vector columns simultaneously. This capability allows for combining multimodal search, hybrid sparse and dense search, and hybrid dense and full-text search, offering versatile and flexible search functionality.
These vectors in different columns represent diverse facets of data, originating from different embedding models or undergoing distinct processing methods. The results of hybrid searches are integrated using various re-ranking strategies.
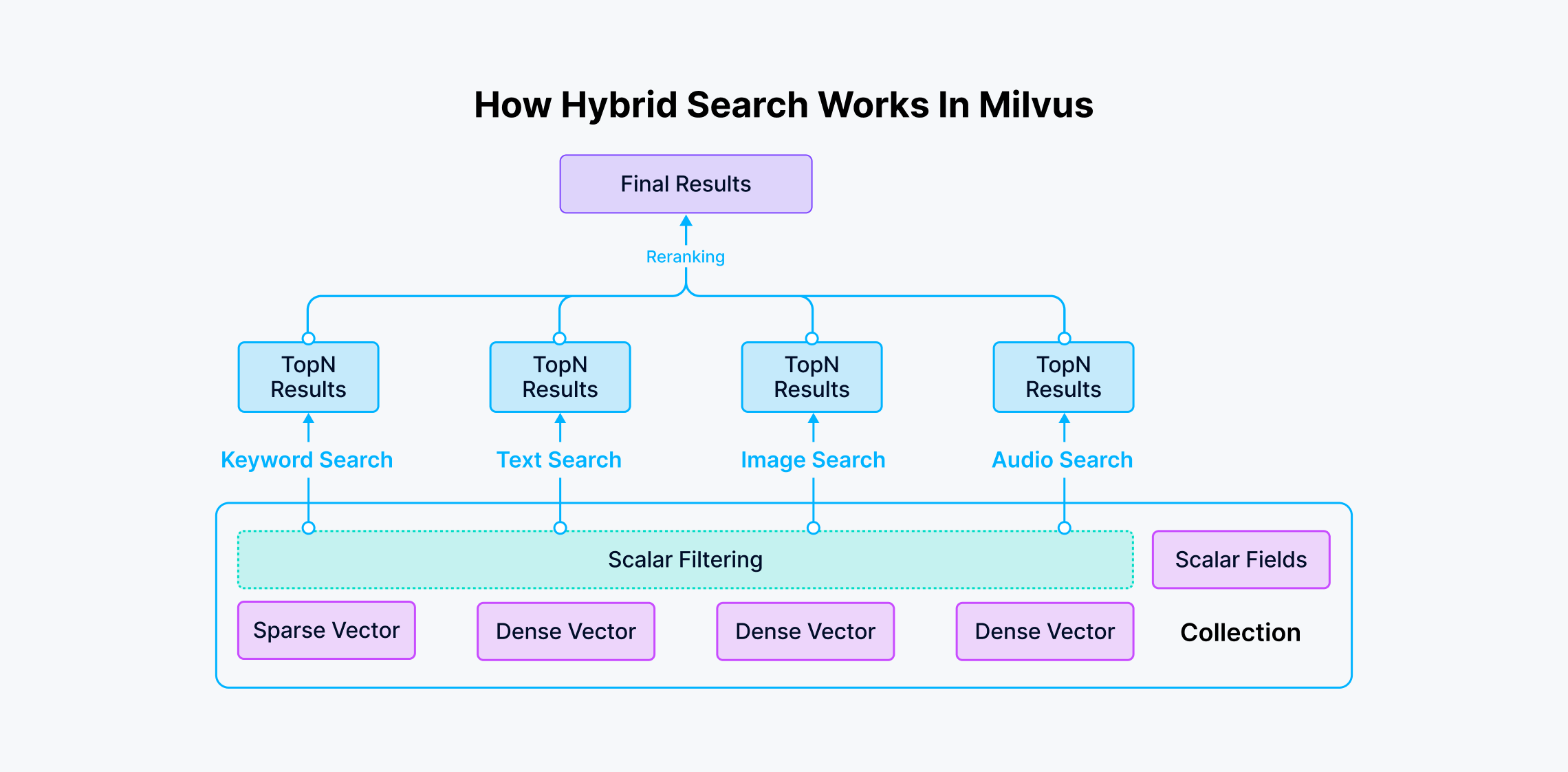 how hybrid search works
how hybrid search works
How Hybrid Search Works in Milvus
This feature enables different columns to:
Represent multiple perspectives of information. For instance, in e-commerce, product images include front, side, and top views. Different views can be represented with different types or dimensions of vectors.
Utilize various types of vector embeddings. This includes dense embeddings from models like BERT and Transformers and sparse embeddings from algorithms like BM25, BGE-M3, and SPLADE.
Support the fusion of multimodal vectors from various unstructured data types such as images, videos, audio, and text files. For example, in criminal investigations, suspects can be represented through biometric modalities such as fingerprints, voiceprints, and facial recognition, aiding in identifying individuals across different modalities.
Support the fusion of vector search and full-text search.
Why We Improved Hybrid Search
OpenAI's recent announcement of its multimodal model GPT-4o has reignited discussions about the future of AI. Handling multimodal data is increasingly necessary for achieving Artificial General Intelligence (AGI). Its emergence also underscores the notion that "everything can be vectorized." Vectors, the AI era's encoding method, are the linchpin connecting disparate modalities. The information they encapsulate is growing more diverse and intricate, placing heightened demands on vector databases for storing and retrieving vector data.
Therefore, the evolution toward hybrid search is pivotal. That's why Milvus introduces support for hybrid search in its latest releases to meet these escalating demands. This strategic enhancement allows Milvus to accommodate complex and multimodal data representations and propels AI systems' capabilities in understanding and processing increasingly intricate datasets.
With this new feature, Milvus empowers developers to explore new possibilities in AI-driven applications, further bridging the gap between data complexity and actionable insights.
How We Designed Hybrid Search in Milvus
Supporting vector search across multiple vector columns required an extensive restructuring of Milvus’s design. For instance, we lifted the storage and writing limitations to ensure system compatibility and stability and introduced advanced search methods for multiple vector columns to handle complex queries.
How Does Hybrid Search Work?
Previously, Milvus allowed only one vector column per collection in the write path. We removed this limitation and introduced a default of four vector columns per collection, which can be extended to a maximum of ten. Each vector column within a collection can support different metric and index types.
Important Note: For system compatibility, you can only query a collection when indexes for all vector columns are created and loaded into memory.
We implemented multi-route vector retrieval and a hybrid re-ranking strategy to perform searches across multiple vector columns for the read path. The process is as follows:
Retrieval: We define inner parameters to control retrieved results for each vector search route (each column). This step supports intermediate parameters like filter and limit but not output parameters like
output_fieldandgroup_by_field.Reranking: After obtaining results from each retrieval route, the next step is to merge these results in a reranking process. Milvus supports two classic reranking strategies: Ranked Retrieval Fusion (RRF) and WeightedRanker. In addition, Milvus also allows users to leverage reranking models on the client side to reorder results.
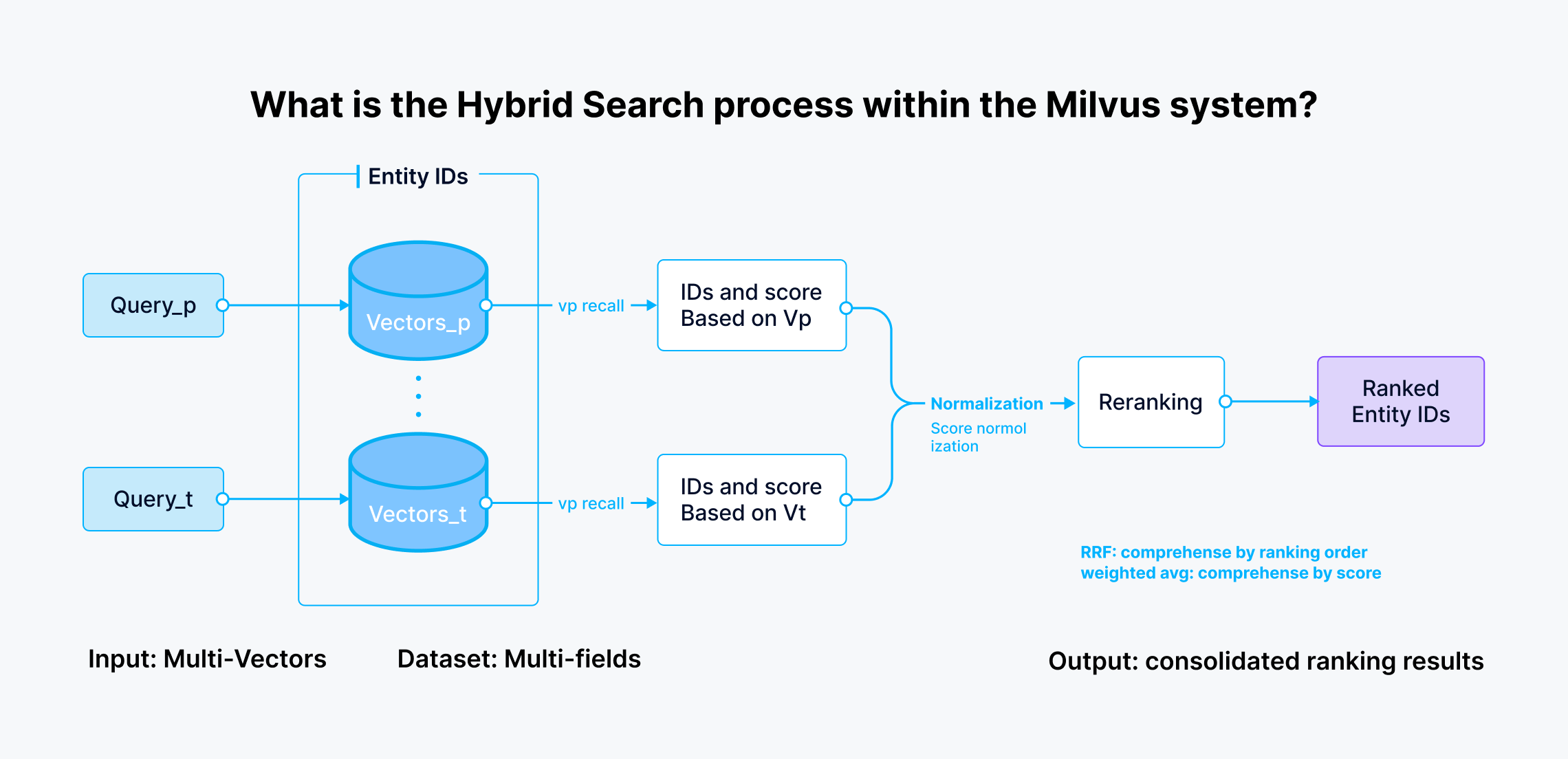 what is the hybrid search process within Milvus
what is the hybrid search process within Milvus
What is the hybrid search process within the Milvus system?
This architecture ensures that Milvus can effectively handle the complexities of storing and retrieving information in environments where multiple vector columns are essential.
Reranking Strategies
Currently, Milvus supports the following reranking strategies:
Ranked Retrieval Fusion (RRF): This strategy combines results based on their ranks across different vector columns.
WeightedRanker: This approach merges results by calculating a weighted average of scores (or vector distances) from different vector searches. It assigns weights based on the significance of each vector field.
The following graphic illustrates how the reranking process works in Milvus.
 how reranking works
how reranking works
How reranking works in Milvus
Ranked Retrieval Fusion (RRF)
RRF is a data fusion algorithm that combines retrieval results based on the reciprocal of their ranks. It balances the influence of each vector field, especially when there is no clear precedence of importance. This strategy is used when you want to take equal consideration for all vector fields or when the relative importance of each field is uncertain.
RRF’s basic process is as follows:
Collect Rankings During Retrieval: Retrievers across multiple vector fields retrieve and sort results.
Rank Fusion: The RRF algorithm weighs and combines the ranks from each retriever. The formula is as follows:
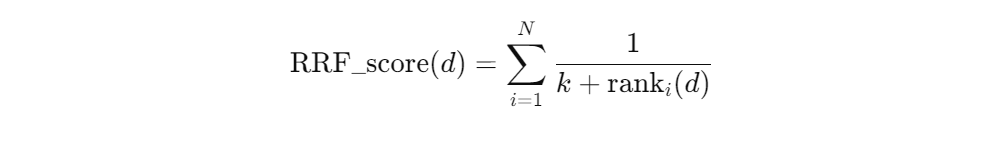 RRF formula
RRF formula
Here, 𝑁 represents the number of different retrieval routes, rank𝑖(𝑑) is the rank position of retrieved document 𝑑 by the 𝑖th retriever, and 𝑘 is a smoothing parameter, typically set to 60.
- Comprehensive Ranking: Re-rank the retrieved results based on the combined scores to produce the final results.
WeightedRanker
The WeightedRanker strategy assigns different weights to results from each vector retrieval route based on the significance of each vector field. This reranking strategy is applied when the significance of each vector field varies, allowing you to emphasize certain vector fields over others by assigning them higher weights. For example, in a multimodal search, the text description might be considered more important than the color distribution in images.
WeightedRanker’s basic process is as follows:
Collect Scores During Retrieval: Gather results and their scores from different vector retrieval routes.
Score Normalization: Normalize the scores from each route to a [0,1] range, where values closer to 1 indicate higher relevance. This normalization is crucial due to score distributions varying with different metric types. For instance, the distance for IP ranges from [-∞,+∞], while the distance for L2 ranges from [0,+∞]. Milvus employs the arctan function, transforming values to the [0,1] range to provide a standardized basis for different metric types.
Weight Allocation: Assign a weight
w𝑖to each vector retrieval route. Users specify the weights, which reflect the data source's reliability, accuracy, or other pertinent metrics. Each weight ranges from [0,1].Score Fusion: Calculate a weighted average of the normalized scores to derive the final score. The results are then ranked based on these highest to lowest scores to generate the final sorted results.
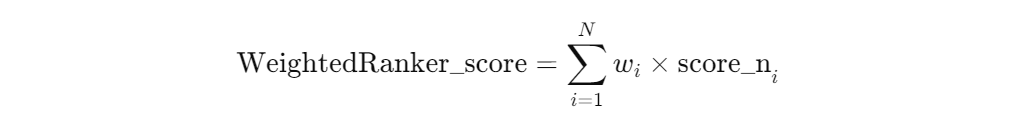 weightedranker fomula
weightedranker fomula
Comparing Hybrid Search and Single Vector Search with an Example
In this section, we will compare image search results using single-vector and hybrid search respectively, demonstrating how hybrid search can improve the quality of search results. For more details, see the full code snippets in this notebook.
The Dataset
We downloaded images containing traffic lights from public sources as our dataset.
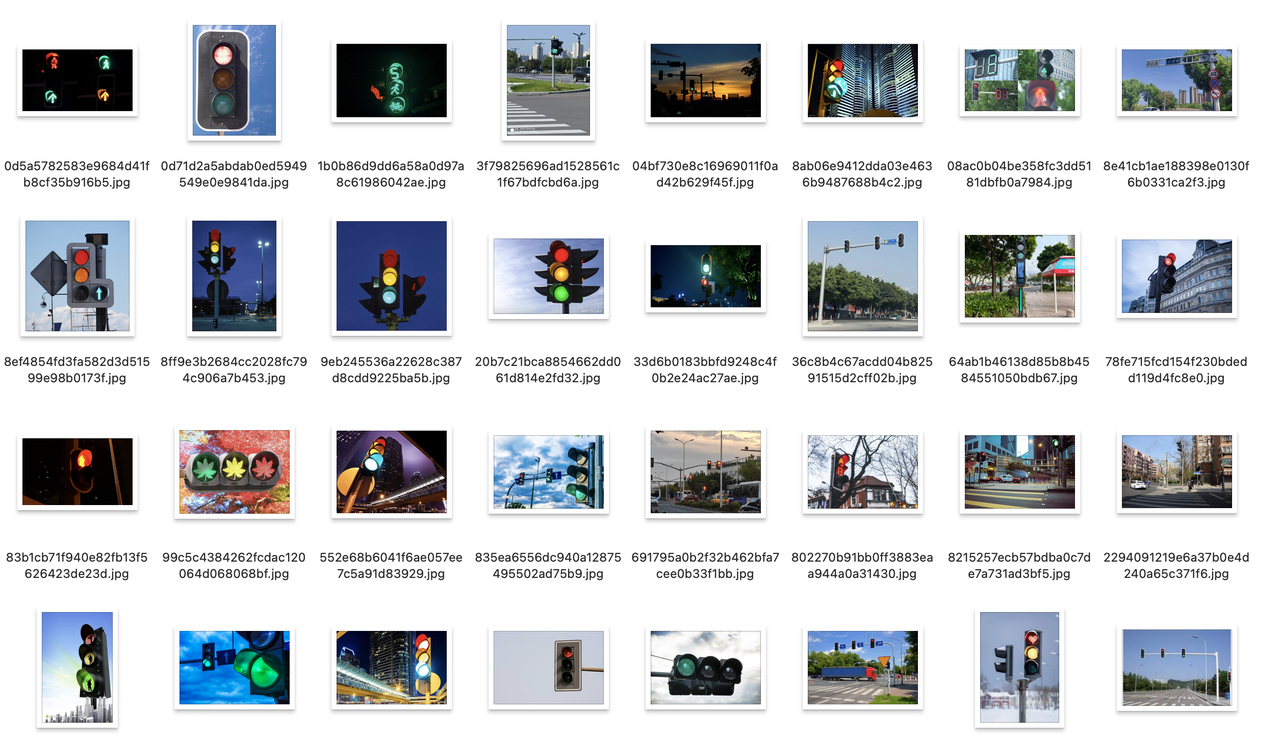 the dataset
the dataset
Query Image
In this demo, the image below is the query image we want to find within the dataset.
 query image
query image
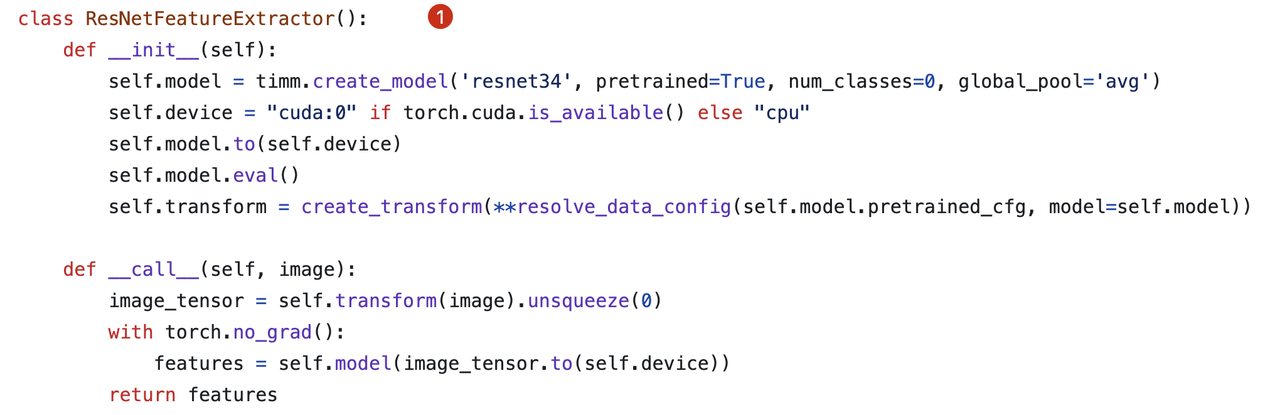
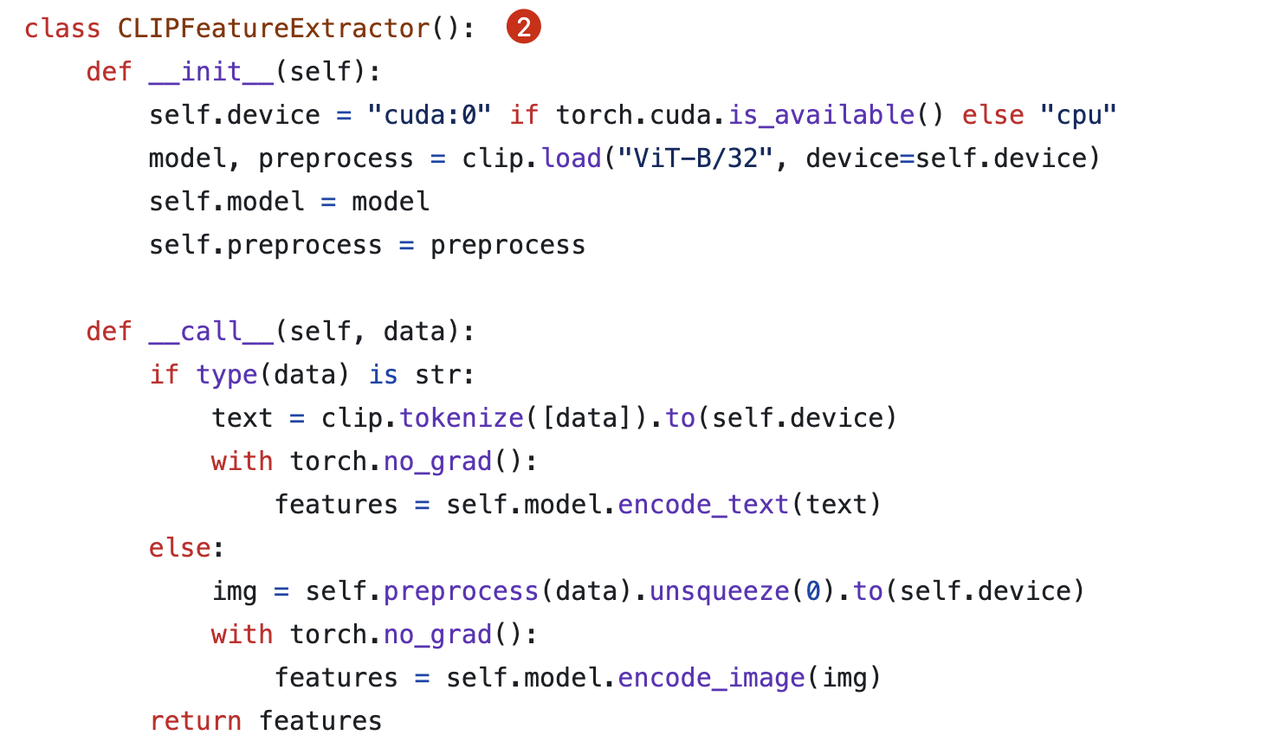
Feature Extraction with ResNet and CLIP
We must create a collection with multiple vector columns before performing feature extraction and inserting images into Milvus. In the code snippet below, we created two vector columns for storing image feature vectors extracted using different embedding models.
 Create a collection with multiple vector columns
Create a collection with multiple vector columns
For this demo, we use ResNet and CLIP as our embedding models.
- ResNet (Residual Network): A popular model for image recognition and classification.
 resnet.png
resnet.png
- CLIP (Contrastive Language–Image Pre-training): A text-image bimodal embedding model that bridges the gap between visual and textual data. We use it to extract features from captions for image search.
 clip
clip
Single-Vector Search Results with ResNet Vectors
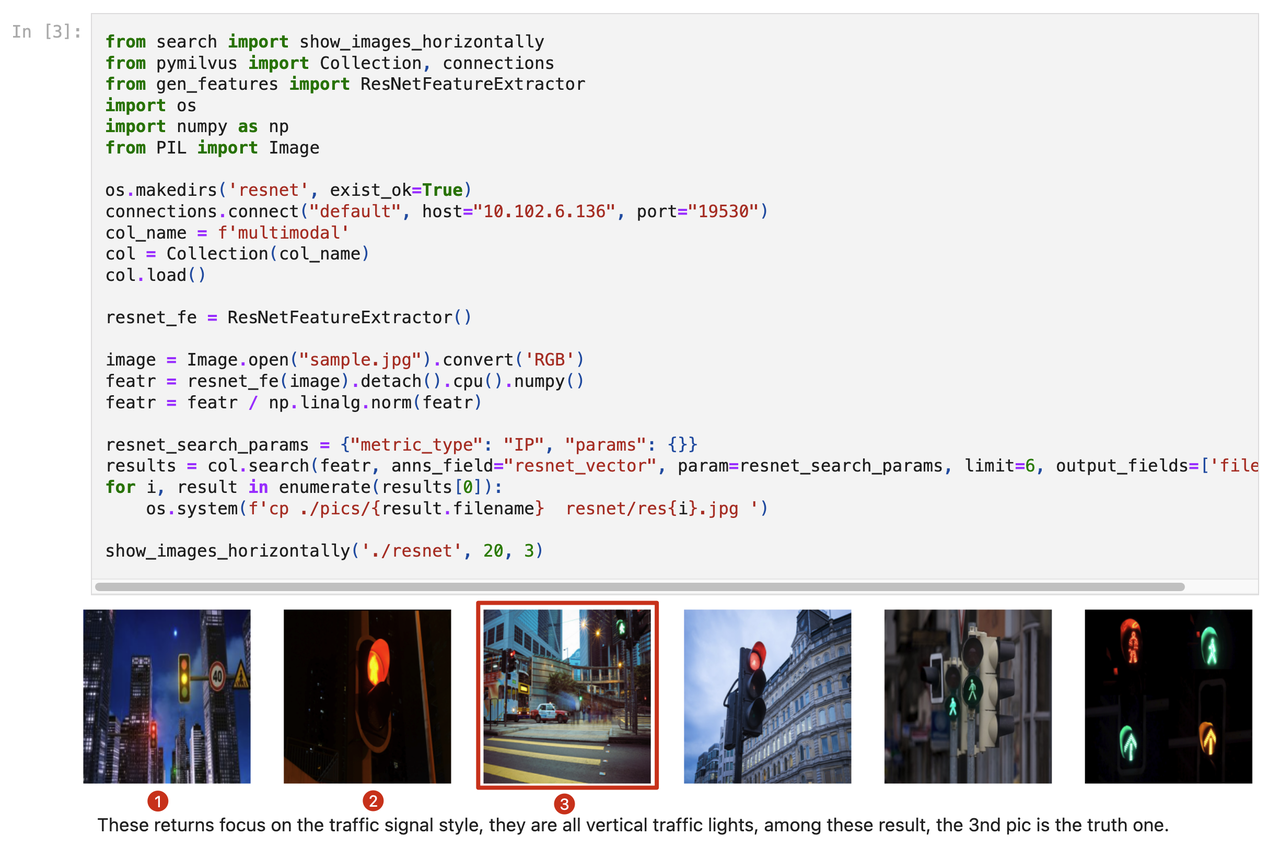
If the dataset contains an identical image to the query in image search, a single-column dense vector search can quickly return the correct result. However, query images often differ from those in the dataset in real-world cases due to varying angles or environmental backgrounds, affecting vector search results. In this example, we use specific features from the query image, specifically focusing on the traffic light, to perform the image search.
 specific features of the query image - the traffic light
specific features of the query image - the traffic light
As you can see from the below results, all the returned images mainly highlight the traffic light object. However, the query image (No.3) itself is not ranked as the most similar. If we limit the search results to only the top two images, the query image will not appear in the results at all.
 search results - resnet.png
search results - resnet.png
Single-Vector Search Results with CLIP Vectors
Next, let’s examine another single-vector search. Due to CLIP's multimodal understanding capability, we can search for images using text input. Here, the search input is "images with buildings in the background."
 search results - clip
search results - clip
The results indicate that the returned images focus on the background element of buildings. However, the query image still does not appear to be the top match.
Hybrid Search Results
The results from the previous two single-route vector searches were not ideal, so we performed a hybrid search across multiple vector columns. In this hybrid search, the results from the two AnnSearchRequest routes are fused using a weighted average method. The weights for the ResNet and CLIP columns were set to 0.7 and 0.8, respectively.
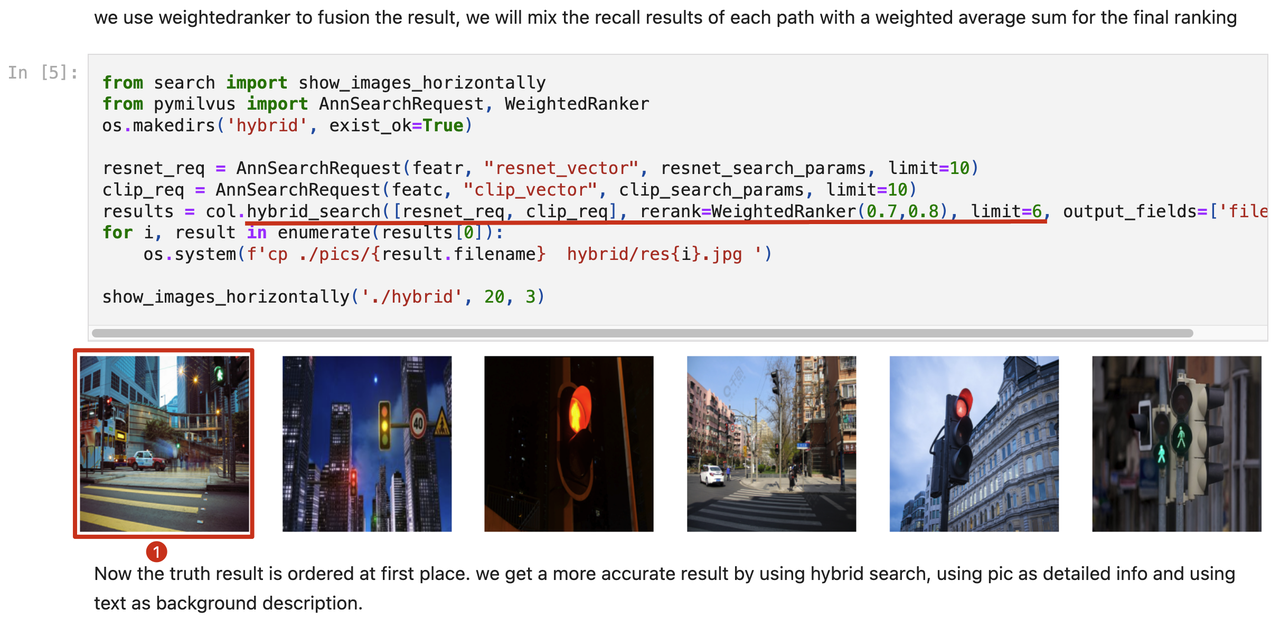 hybrid search results
hybrid search results
As you can see from the results above, the query image was returned as the most similar (Top 1) image this time.
This example illustrates how hybrid search effectively integrates multimodal inputs from images and text. Compared to single-vector searches, hybrid search demonstrates substantial improvement in final results.
Wrapping Up
Hybrid Search is a core feature in Milvus that enhances data search capabilities by enabling simultaneous queries across multiple vector fields. This feature combines hybrid sparse and dense search, multimodal search, and hybrid dense and full-text search; all these search results are integrated and reranked using efficient re-ranking strategies for a more accurate and relevant final result.
Moving forward, we will focus on expanding Hybrid Search into various domains. For instance, it can be extended to leverage time-based reranking for use cases like recommending trending social topics for Twitter or TikTok. We also plan to introduce more robust fusion algorithms and reranking models to deliver a more refined search experience.
The potential of hybrid search goes beyond what's covered here. Stay tuned for more updates from us.
 Ken Zhang
Ken ZhangKen Zhang is a Senior Product Manager at Zilliz, leading the development of the Milvus vector database by setting its strategic direction and key features. Prior to Zilliz, he served as a kernel engineer at SAP HANA and enhanced his product management skills at PingCAP. Ken holds a master's degree from Fudan University and has over eight years of experience specializing in database development and big data infrastructure management.
- What is Hybrid Search?
- Why We Improved Hybrid Search
- How We Designed Hybrid Search in Milvus
- Comparing Hybrid Search and Single Vector Search with an Example
- Wrapping Up
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

How to Use Anthropic MCP Server with Milvus
Discover how Model Context Protocol (MCP) pairs with Milvus to eliminate AI integration hassles, enabling smarter agents with seamless data access and flexibility.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
In this article, we’ll explore how DeepRAG works, unpack its key components, and show how vector databases like Milvus and Zilliz Cloud can further enhance its retrieval capabilities.
Elasticsearch Was Great, But Vector Databases Are the Future
Purpose-built vector databases outperform dual-system setups by unifying Sparse-BM25 and semantic search in a single, efficient implementation.