




Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
How much of your organization’s data is actually being used? If you’re like most enterprises, the answer is not much. That’s because over 90% of enterprise-generated data is unstructured—spread across documents, emails, videos, and more. Unlike structured data, which fits into rows and columns, unstructured data lacks a fixed schema, making it harder to process.
Managing unstructured data is challenging due to inconsistent formats and varied sources. It holds tremendous potential for business intelligence (BI), artificial intelligence (AI), and decision-making. Organizations that process unstructured data effectively gain deeper insights, improve automation, and enhance customer experiences.
Extract, Transform, and Load (ETL) is a process that moves data from various sources, transforms it into a usable format, and loads it into a target system. ETL processes were built for structured data, using predefined schemas and rigid transformations. As a result, they struggled with the complexity and variability of unstructured data. Modern ETL tools use advanced techniques like natural language processing (NLP) and machine learning (ML). These capabilities enable unstructured data to be processed, standardized, and stored efficiently in vector databases. This makes the data easier to search, analyze, and use for AI-driven applications such as predictive analytics, chatbots, and knowledge graphs.
This blog explores ETL tools for unstructured data, key challenges, and how to choose the right tool for your use case. It also includes a comparison of different ETL solutions.
What is ETL?
ETL stands for Extract, Transform, and Load. It is a core data integration process that extracts data, transforms it into a consistent and usable format, and loads it into a target system like a data warehouse or vector database.
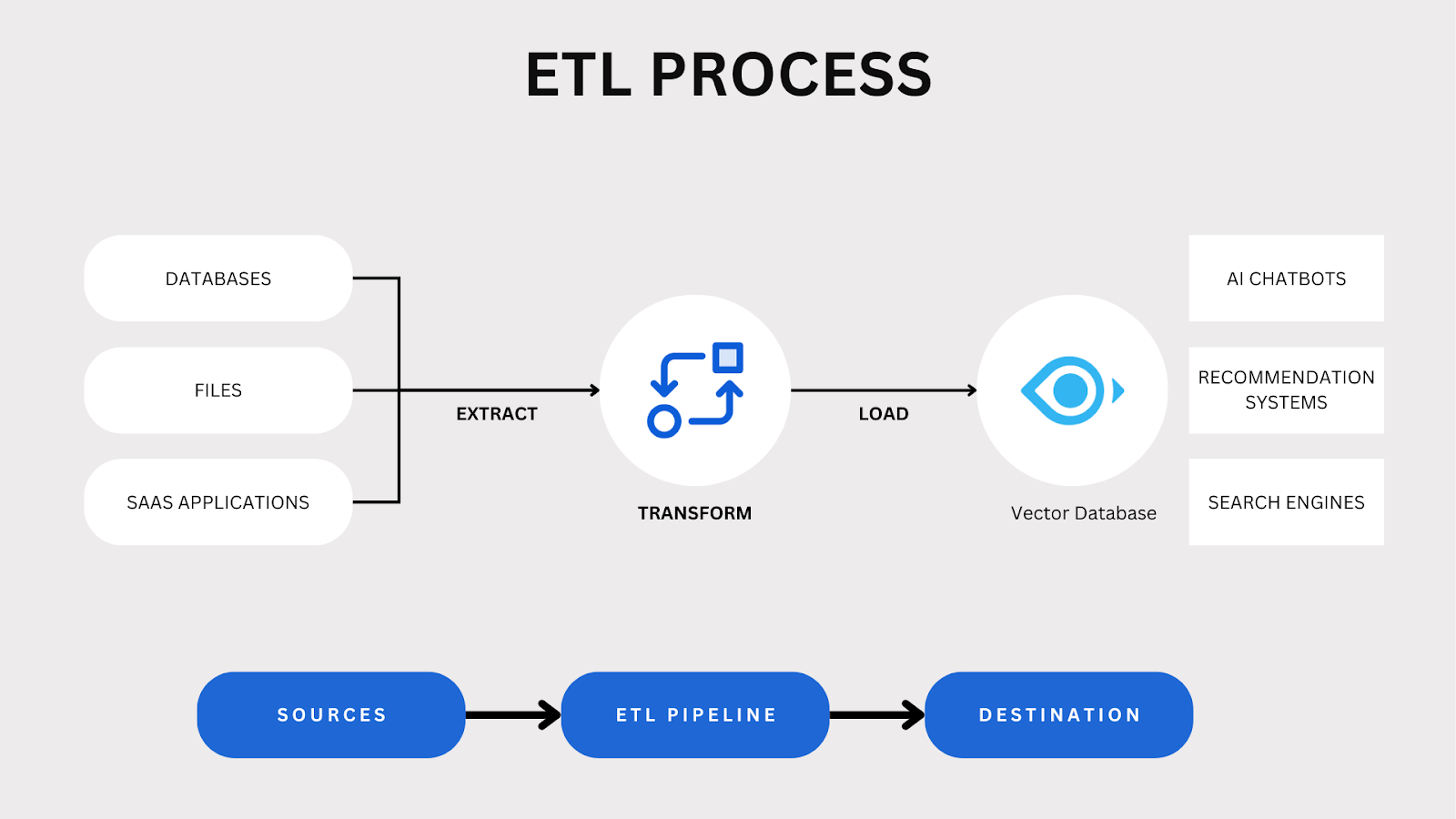
ETL Process Overview
There are several stages of the ETL process:
Extraction: Data is collected from diverse sources, including PDFs, emails, videos, images, and social media feeds. Unstructured content requires specialized techniques such as optical character recognition (OCR) for scanned documents, speech-to-text conversion for audio files, and metadata extraction from images or videos. The goal is to retrieve all relevant information, regardless of its structure.
Transformation: Extracted data is processed to meet business or technical requirements. This includes cleaning, normalization, aggregation, and applying business rules to ensure accuracy and usability.
Loading: Processed data is stored in a system optimized for unstructured content, such as a vector database. These systems enable efficient indexing, retrieval, and analysis of high-dimensional data, making it easier to support decision-making.
ETL helps organizations consolidate data from multiple sources, making it accessible and ready for analysis. With effective ETL strategies, businesses can gain insights, improve efficiency, and stay competitive in a data-driven world.
Popular Unstructured Data ETL Tools
Choosing the right ETL tool for your use case is essential, whether building AI models or setting up a retrieval-augmented generation (RAG) pipeline. Several ETL tools help manage unstructured data integration with your vector database. Below is an overview of notable tools, their key features, and use cases.
1. Airbyte
Airbyte is an open-source data movement infrastructure for building extract and load (EL) data pipelines. It facilitates the movement of unstructured and semi-structured data via data source connectors.
Key features and capabilities:
Extensive Connector Catalog: Offers 550+ pre-built connectors, supporting both structured and unstructured data sources.
AI Integration: Supports generative AI (GenAI) workflows by moving data from hundreds of popular sources into vector databases.
Customization and Extensibility: Provides an open-source platform for building custom connectors with low-code/no-code tools in minutes.
Use cases:
Building retrieval-augmented generation (RAG) pipelines.
Integrating unstructured data into AI and machine learning models.
Consolidating data from multiple sources for comprehensive analysis.
2. Fivetran
Fivetran is a managed data integration service that automates data movement from various sources to data warehouses or vector databases.
Key features and capabilities:
Pre-built Connectors: Offers 650+ no-code connectors, including SaaS applications, databases, and ERPs.
Automated Data Synchronization: Continuously updates data from source to destination without manual intervention.
Transformation Support: Fivetran’s data models immediately turn your raw data into production-ready tables to drive insights.
Built-in Schema Migration: Supports built-in schema migration for seamless data replication.
Use cases:
Centralizing data from multiple databases and software-as-a-service (SaaS) tools like Salesforce and Zendesk.
Maintaining up-to-date analytics databases with minimal effort.
Simplifying ETL processes for structured and unstructured data sources.
3. Unstructured.io
Unstructured is a platform designed to ingest, process, and transform unstructured documents for AI applications such as RAG and model fine-tuning.
Key features and capabilities:
Diverse Data Sources: Supports various file types, including text documents, images, PDFs, and presentations, enabling seamless ingestion from multiple formats.
LLM-Ready: Provide connectors to capture data wherever it lives and transform it into AI-friendly JSON files.
Compatibility: Integrates seamlessly with major vector databases and LLM frameworks.
Use cases:
Preparing unstructured data for AI and machine learning applications.
Enhancing data quality for enterprise analytics.
Integrating unstructured data into generative AI architectures.
4. Vectorize
Vectorize automates data extraction, finds the best vectorization strategy using RAG evaluation, and lets you quickly deploy real-time RAG pipelines for your unstructured data.
Key features and capabilities:
RAG-as-a-Service: Build highly optimized search indexes that ensure your AI applications always have the data they need.
Unstructured data to indexes: Automatically extract text, images, and tables from PDFs, Word Docs, PowerPoints, and more.
Connectivity: Ingest data from your customers' documents, knowledge bases, and SaaS platforms.
Use cases:
Build and maintain automated retrieval-augmented generation (RAG) pipelines
Deploy a robust pipeline capable of managing billion-scale vector data and providing real-time answers.
Turn your unstructured data into optimized search indexes.
5. Unstract
Unstract is a no-code platform that automates document processing workflows at any scale. It leverages cutting-edge AI to surpass the current capabilities of Intelligent Document Processing (IDP) and Robotic Process Automation (RPA).
Key features and capabilities:
Automated Data Structuring: Utilizes large language models (LLMs) to convert unstructured data into structured formats without extensive manual effort.
Versatile Data Handling: Supports various unstructured data types, including text, images, and multimedia.
Unique Extraction Approach: Employs a dual-LLM system where one model acts as the extractor and the other as the challenger; both must agree on the extracted field value before it is finalized.
Use cases:
Streamlining the preparation of unstructured data for business intelligence platforms.
Producing AI-optimized outputs from unstructured documents.
Improving LLM understanding of extracted document data.
Challenges in ETL for Unstructured Data
ETL for unstructured data comes with unique challenges due to the varied and unpredictable nature of the data. Handling diverse formats, ensuring data quality, and maintaining consistency can be complex. Below are some key challenges
Data Variety: Unstructured data comes in formats like text, images, videos, and audio. Handling multiple types requires advanced tools.
Lack of Schema: Unlike structured data, unstructured data lacks a predefined schema, making direct extraction of meaningful information difficult.
Transformation Complexity: Converting unstructured data into structured formats requires complex transformations, often using NLP and machine learning.
Data Quality and Consistency: Unstructured data contains errors and inconsistencies. Ensuring accuracy is challenging due to varied formats and no fixed schema.
Integration Difficulties: Combining unstructured data from multiple sources is complex. Standardizing formats is essential for seamless integration.
Specialized ETL tools and frameworks help address these challenges, making unstructured data more manageable and AI-ready.
Comparison and Recommendations
Selecting the appropriate ETL tool for unstructured data is crucial for efficient data integration and analysis. Below is a comparison of several popular ETL tools for unstructured data, highlighting their key features, use cases, and potential limitations:
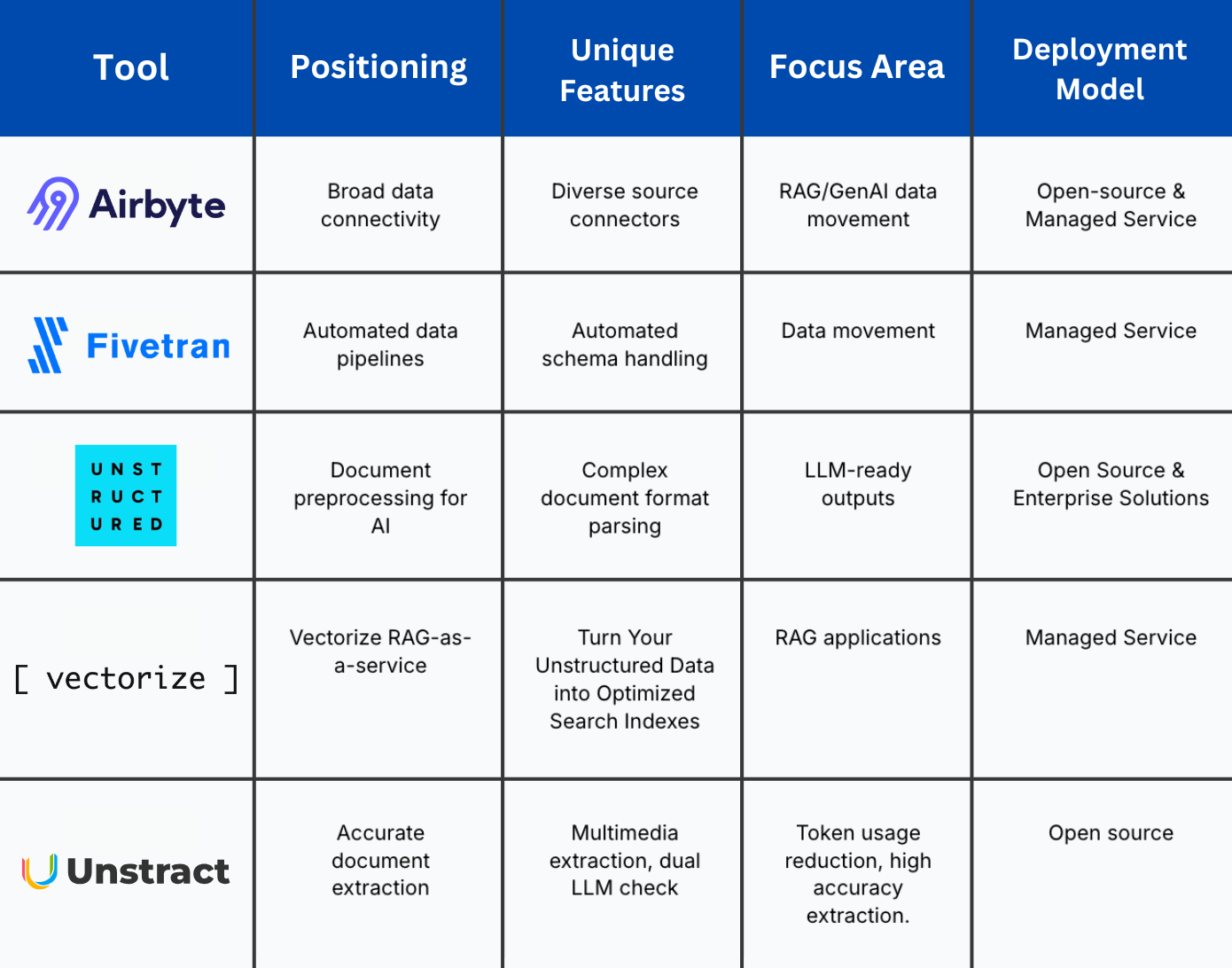 ETL Tool Comparison
ETL Tool Comparison
Recommendations
The ETL tool you choose depends on your goals and technical requirements. Do you need to centralize data from multiple sources, integrate with AI, or prioritize an open-source solution? Below are recommendations based on different use cases:
For AI and Machine Learning Integration: Unstructured.io, VectorETL, and Unstract are well-suited for projects focusing on AI applications, offering robust support for transforming unstructured data into AI-compatible formats.
For Comprehensive Data Centralization: Airbyte and Fivetran provide extensive connectors, making them ideal for consolidating data from multiple sources, both structured and unstructured.
For Organizations Seeking Open-Source Solutions: Airbyte offers a wide range of connectors and customizable features, making it ideal for teams looking to tailor their ETL processes.
For Complex Document Processing Needs: Unstract stands out with its dual-LLM approach, ensuring high accuracy in data extraction from different document types.
Implementation Insights
Starting with Pilot Projects: Select a specific unstructured data source and run a small-scale ETL project using the chosen tool. This helps assess compatibility, efficiency, and tool capabilities before committing to full-scale deployment.
Cross-functional Collaboration: Encourage collaboration between data engineers, analysts, and domain experts. This ensures ETL processes align with business goals and leverage specialized expertise for better data handling and decision-making.
Scaling ETL Processes: As data volumes and complexity grow, ensure the selected ETL tool can scale efficiently. Consider factors like processing speed, connector support, and compatibility with various unstructured data formats.
You can ensure a smoother and more efficient workflow by carefully evaluating ETL tools based on your needs. A pilot project helps validate the right tool, minimizing integration challenges and maximizing the value of unstructured data. If your use case is RAG, selecting a tool with strong chunking, embedding, and vector storage support simplifies implementation.
Unlock the Power of Unstructured Data for AI with Vector Search
Unstructured data—such as text, images, and videos—holds valuable insights that often remain untapped due to its complexity. Integrating vector search into AI workflows unlocks its full potential. Vector search enables the processing and analysis of unstructured data by transforming it into vector embeddings, allowing AI models to detect hidden patterns.
Why Master Unstructured Data for AI with Vector Search?
Unlock Hidden Insights: Unstructured data contains complex information. Vector search reveals patterns and trends that traditional methods often overlook. This helps businesses make data-driven decisions and gain a competitive advantage.
Break Down Data Silos: Organizations store unstructured data across multiple platforms, creating silos. Vector search seamlessly integrates diverse sources for comprehensive analysis. This enables thorough analysis and fosters better insights and data-driven strategies.
Enhance Generative AI Applications: Converting unstructured data into vector embeddings enables more accurate, context-aware searches. This improves AI applications, improving user experiences and highly relevant outputs.
Integrating Milvus/Zilliz Cloud with ETL Tools
Milvus, an open-source vector database, and Zilliz Cloud, its managed service, handle large-scale vector data for AI applications. Zilliz offers multiple vector database integrations, maximizing unstructured data potential. It supports over 1,000 connectors, enabling seamless integration of various unstructured data sources for AI-powered search and analysis.
Airbyte Integration: Milvus provides a connector for Airbyte, allowing seamless ingestion of unstructured data from various sources into the vector database. This simplifies ETL workflows and enhances AI readiness.
Fivetran Integration: With a Milvus connector for Fivetran, organizations can automate the transfer of structured and unstructured data into the vector database. This setup optimizes AI-powered search and analytics.
Unstructured.io Integration: Milvus integrates with Unstructured.io, enabling direct ingestion of transformed unstructured data into the vector database. This ensures AI models can efficiently process and retrieve insights.
Getting Started with Vector Search
Select the Appropriate ETL Tool: Choose an ETL tool that aligns with your data sources and business requirements. Consider factors such as scalability, ease of integration, and support for unstructured data.
Integrate with Milvus/Zilliz Cloud: Utilize the Milvus connectors of the chosen ETL tool. This integration enables the seamless ingestion and storage of vector embeddings derived from unstructured data.
Develop AI Applications: Leverage the vector data stored in Milvus/Zilliz Cloud to build AI applications such as chatbots, recommendation engines, and intelligent search systems. These solutions enable advanced search and analysis, extracting valuable insights from unstructured data to drive innovation and informed decision-making.
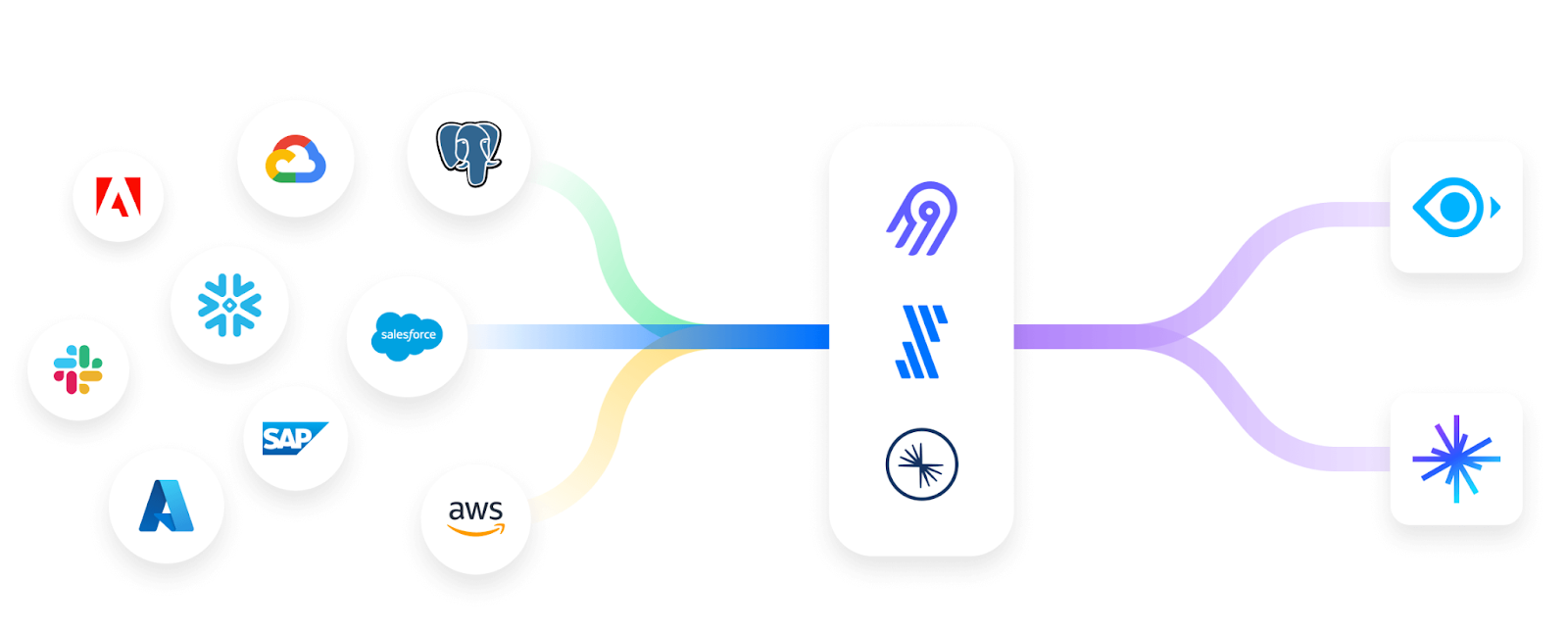
Unstructured Data Sources to Milvus Connectors | Source
Conclusion
Effectively managing unstructured data is crucial for organizations aiming to maximize AI and machine learning potential. ETL tools like Airbyte, Fivetran, Unstructured.io, VectorETL, and Unstract offer robust solutions for processing and integrating unstructured data.
Integrating these ETL tools with vector databases like Milvus enhances AI-driven search and advanced analytics capabilities. Zilliz simplifies this process by enabling seamless ETL integrations, allowing businesses to ingest data from over 1,000 unstructured sources directly into Milvus.
Selecting the right ETL tools and integrations enables businesses to uncover valuable insights, drive innovation, and stay competitive in the AI-driven world.
Related Resources

Keep Reading

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.