




Что такое контекстное окно в ИИ?

Что такое контекстное окно в ИИ?
В ИИ контекстное окно определяет, какой объем текста модель может обработать за один раз, измеряемый в токенах. Понимание контекстного окна крайне важно, поскольку оно влияет на способность ИИ-модели генерировать точные и связные ответы. В этом руководстве мы рассмотрим, что такое контекстное окно, его важность в ИИ-моделях и сложности управления более крупными контекстными окнами.
Понимание токенов
Прежде чем обсуждать контекстное окно, давайте сначала разберем понятие токенов.
Токены — это наименьшие единицы данных, которые ИИ-модели используют для обработки текста и обучения на нем. По сути, это части предложения — например, отдельные слова или знаки препинания, — которые компьютер использует, чтобы понимать и обрабатывать язык. Когда компьютер читает предложение, он разбивает его на более мелкие части (токены), чтобы понять его смысл. Например, в предложении "It's sunny!" токенами будут "It's", "sunny" и "!". Этот процесс, называемый токенизацией, помогает компьютеру анализировать текст для таких задач, как перевод языков, обнаружение спама или ответы на вопросы.
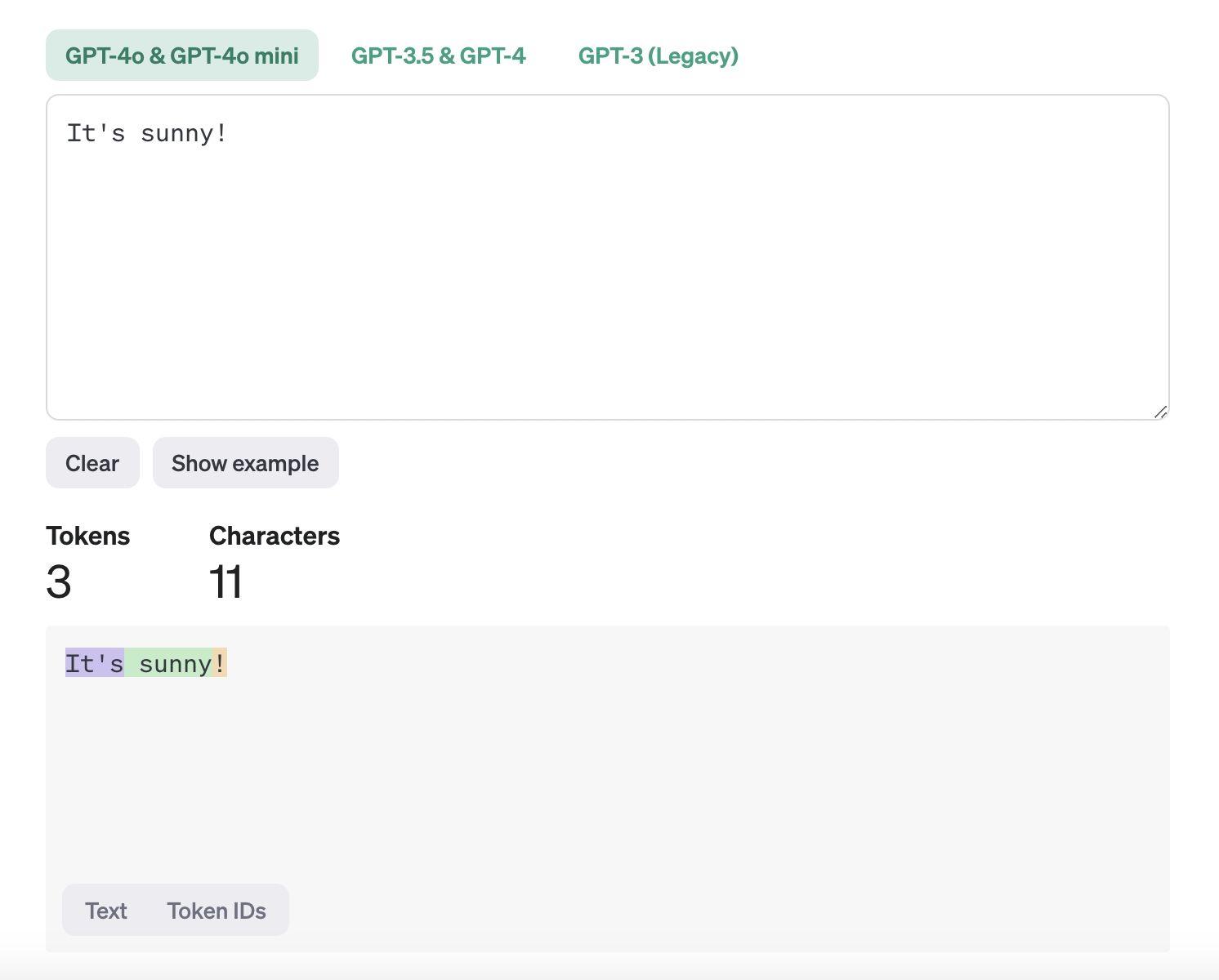 Что такое токены.jpeg
Что такое токены.jpeg
Что такое контекстное окно в ИИ?
Контекстное окно — это фундаментальное понятие в ИИ, особенно в больших языковых моделях (LLM). Оно означает максимальный объем текста, измеряемый в токенах, который ИИ-модель может запомнить и использовать во время разговора при генерации ответа.
Представьте контекстное окно как объем кратковременной памяти модели. Например, если у модели вроде ChatGPT контекстное окно составляет 4 096 токенов, она может "помнить" информацию из последних 4 096 токенов (слов или знаков препинания), которые она обработала. Это похоже на то, как человек может удерживать в памяти только определенный объем информации во время чтения или слушания. Когда этот лимит токенов достигается, самая ранняя информация начинает "исчезать" по мере поступления новой информации, что влияет на способность модели обращаться к более ранним частям разговора. Это понятие крайне важно для определения того, насколько хорошо модель может сохранять контекст в длинных обсуждениях или документах.
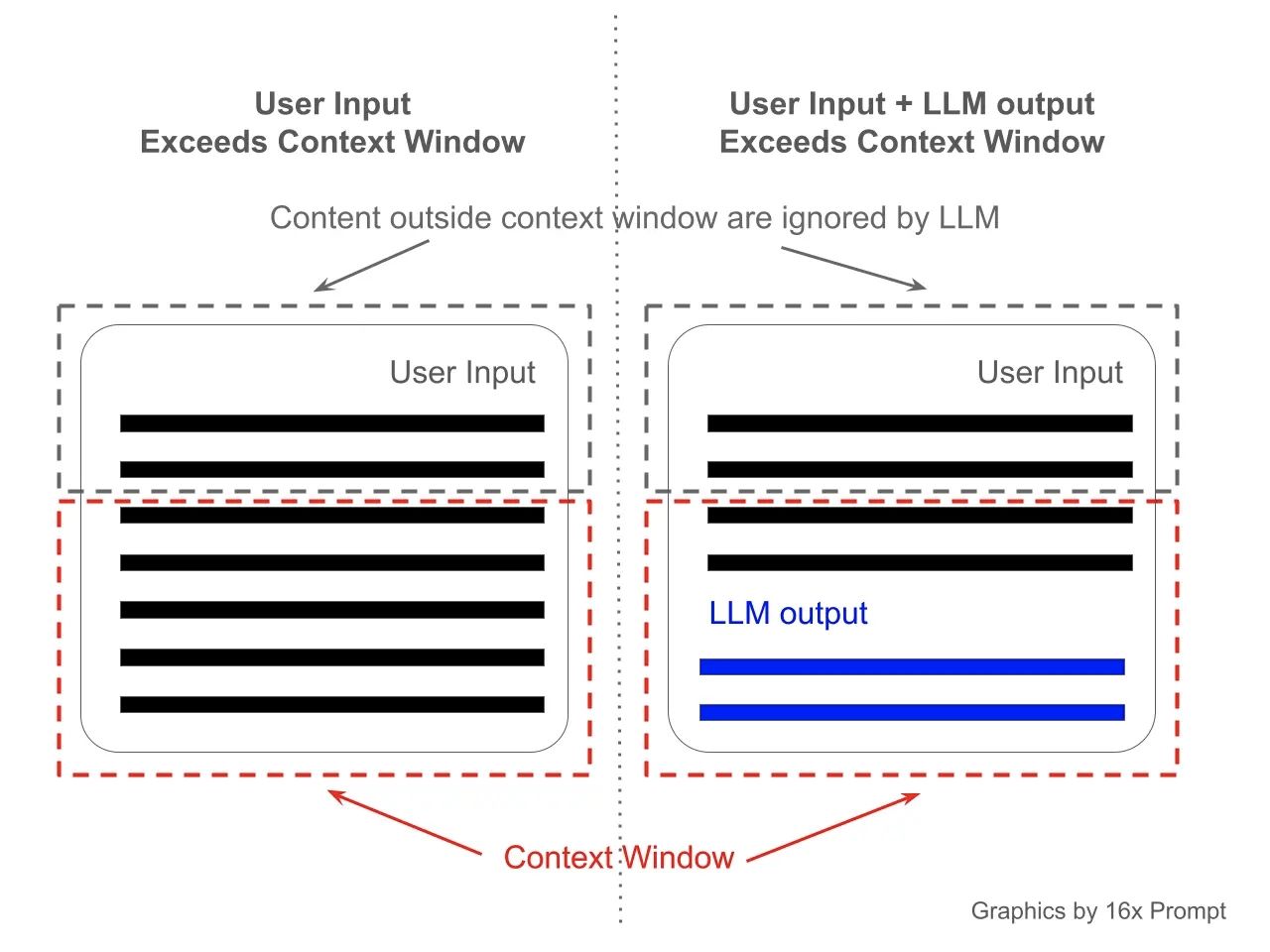 Визуализация контекстного окна, credit 16x Prompt.jpeg
Визуализация контекстного окна, credit 16x Prompt.jpeg
Контекстное окно применяется не только к вводу или текущей истории разговора, но и к ответам, сгенерированным моделью. Например, если сам ответ содержит 500 токенов, это количество вычитается из общего числа токенов, доступных для обработки истории разговора. Следовательно, если лимит токенов почти достигнут, самые ранние 500 токенов разговора могут не учитываться при дальнейшей обработке.
Лимиты токенов в рамках контекстного окна
Размер контекстного окна, или лимит токенов, — это общее количество токенов, которое модель может учитывать одновременно. Если разговор превышает этот лимит, сохраняются только самые последние токены, а более старые токены отбрасываются. Например, продвинутая модель OpenAI GPT-4o предлагает гораздо более крупное контекстное окно — до 128 000 токенов, что позволяет шире и глубже взаимодействовать с текстом.
 Контекстное окно GPT-4o и лимит выходных токенов.jpeg
Контекстное окно GPT-4o и лимит выходных токенов.jpeg
Лимиты выходных и входных токенов
Помимо контекстного окна, ИИ-модели имеют определенные лимиты токенов для выходных данных и входных данных:
- Лимит выходных токенов: Это максимальное количество токенов, которое модель может сгенерировать в одном ответе. Например, у OpenAI GPT-4o-mini лимит выходных токенов составляет 16 348 токенов. Если сгенерированный ответ достигает этого лимита, модель прекращает генерацию токенов, что потенциально может обрезать ответ.
 Лимит выходных токенов GPT-4o-mini .jpeg
Лимит выходных токенов GPT-4o-mini .jpeg
- Ограничение входных токенов: Это определяет, сколько токенов из входных данных может быть обработано за один раз. Превышение этого ограничения означает, что модель должна сегментировать входные данные на более мелкие части, что может повлиять на связность и точность ответа.
Балансировка ограничений токенов
Объем ограничения токенов существенно влияет на производительность модели, определяя ее способность эффективно разбирать и интерпретировать сложную информацию. Балансировка количества токенов с вычислительной мощностью модели имеет важное значение, поскольку более широкие возможности обработки позволяют эффективнее работать со сложными идеями, хотя и с необходимыми компромиссами в стратегиях токенизации и обработки.
Важность больших контекстных окон в моделях ИИ
 Визуальное представление важности больших контекстных окон в ИИ..jpeg
Визуальное представление важности больших контекстных окон в ИИ..jpeg
Большие контекстные окна значительно повышают способность ИИ понимать и анализировать обширные документы, делая их незаменимыми в таких областях, как юридические и медицинские исследования. Например, в юридических исследованиях ИИ может эффективно извлекать релевантную информацию из больших наборов данных, быстро предоставляя ценные аналитические сведения. Аналогично, в медицинских исследованиях большие контекстные окна облегчают суммаризацию сложных научных статей, помогая исследователям оперативно получать выводы.
Увеличенная способность обрабатывать более одного миллиона токенов позволяет моделям ИИ эффективно выполнять разнообразные задачи — от обработки данных до генерации кода. Claude 3.5 Sonnet, например, имеет размер контекстного окна 200 000 токенов, что позволяет ему справляться со сложными инструкциями и задачами, требующими учета нюансов, с поразительной точностью. Эта возможность подчеркивает критически важную роль больших контекстных окон в повышении производительности ИИ.
Однако сами большие контекстные окна в моделях ИИ имеют компромиссы. Они могут приводить к более высоким операционным затратам и требуют надежных стратегий работы с данными для обеспечения эффективного использования релевантных обучающих данных. Кроме того, управление большим контекстным окном может привести к информационной перегрузке, снижая эффективность модели в выявлении ключевых моментов. Поэтому для раскрытия полного потенциала больших контекстных окон при одновременном смягчении связанных с ними проблем необходим сбалансированный подход.
В следующем разделе мы рассмотрим проблемы, связанные с расширением контекстных окон.
Проблемы расширения контекстных окон в моделях ИИ
Расширение контекстных окон в моделях ИИ вводит различные компромиссы, требующие тщательного рассмотрения. Возможность более длинных входных и выходных данных может повысить содержательность генерируемых ответов, но также увеличивает сложность обработки. Баланс между более длинными контекстными окнами и эффективной обработкой имеет решающее значение для смягчения потенциальных недостатков в производительности ИИ.
Вычислительные ресурсы
По мере роста размеров контекстных окон потребность в вычислительной мощностиности существенно возрастает, что приводит к более медленному времени инференса. Сложность масштабирования при увеличении контекстных окон возникает из-за квадратичного роста параметров, что создает значительные проблемы. Когда длина текстовых последовательностей удваивается, потребности в памяти и вычислениях увеличиваются в четыре раза, подчеркивая повышенные требования больших контекстных окон.
Для решения этих проблем были внедрены такие методы, как ring attention, чтобы повысить эффективность моделей, работающих с расширенными контекстными окнами. Однако теория «зоны ближайшего развития» предполагает, что перегрузка языковых моделей информацией сверх их текущих возможностей может снизить их эффективность. Таким образом, необходимо тщательно продумывать управление вычислительными ресурсами.
Стоимостные последствия
Более длинные контекстные окна могут приводить к значительным вычислительным и финансовым затратам, которыми организациям необходимо эффективно управлять. Расширение контекстного окна с 4K до 8K токенов может привести к экспоненциальному росту операционных расходов. Поэтому организации должны взвешивать преимущества улучшенной производительности AI-моделей по сравнению с увеличенными затратами на более длинные контекстные окна.
Эффективные стратегии управления затратами крайне важны для организаций, рассматривающих расширение контекстных окон в AI-моделях. Внедрение этих стратегий помогает организациям сбалансировать расширенные возможности AI с сопутствующими финансовыми последствиями, обеспечивая устойчивые и эффективные AI-операции.
Управление данными
Управление большими объемами обучающих данных представляет значительные сложности для AI-моделей, особенно при оптимизации производительности без перегрузки системы. Исследования показывают, что предоставление целенаправленного набора релевантных документов обеспечивает лучшую производительность языковых моделей, чем их перегрузка чрезмерным объемом нефильтрованной информации. Такой подход гарантирует, что AI сможет эффективно обрабатывать данные и отвечать, сохраняя релевантность своих выводов.
Фильтрация и управление контекстом обучающих данных необходимы для обеспечения точных ответов и эффективной производительности модели. Стратегический отбор и организация релевантных данных позволяют AI-моделям выдавать контекстуально уместные и содержательные результаты даже при более крупных контекстных окнах.
RAG: Улучшение AI-моделей с помощью внешней базы знаний для расширенной памяти
Более крупные контекстные окна имеют решающее значение в AI-моделях для улучшенного понимания и выполнения сложных задач. Они позволяют моделям сохранять и использовать более обширную информацию, повышая непрерывность и релевантность ответов. Это особенно полезно при выполнении сложных задач. Однако поддержание большого контекстного окна может увеличить вычислительные требования, затраты и сложность управления данными.
Чтобы наделить AI-модели возможностями долгосрочной памяти и одновременно решить эти проблемы, исследователи изучали инновационные подходы, такие как Retrieval-Augmented Generation (RAG). Эта техника улучшает результаты AI-моделей, подключая их к внешней базе знаний, размещенной в vector database. Тем самым она предоставляет моделям более широкий контекстуальный фон без накладных расходов, связанных с крупными внутренними контекстными окнами. Эта внешняя база знаний действует как расширенная память, помогая моделям динамически получать доступ к огромному пулу информации, что крайне важно для обработки сложных запросов и повышения глубины и точности ответов.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) объединяет генеративную мощь языковых моделей с динамическим извлечением внешних документов. Этот подход расширяет потенциал LLM, обеспечивая доступ к более широкому спектру информации и ее интеграцию, тем самым повышая релевантность и точность генерируемых ответов.
Стандартная система RAG обычно объединяет модель эмбеддингов, векторную базу данных, такую как Milvus, или ее управляемую версию Zilliz Cloud, и LLM (или мультимодальную модель), где модель эмбеддинговпреобразует текст в векторные эмбеддинги, векторная база данных хранит и извлекает контекстную информацию для пользовательских запросов, а LLM генерирует ответы на основе извлеченного контекста.
 Рисунок — рабочий процесс RAG.png
Рисунок — рабочий процесс RAG.png
Использование RAG позволяет моделям ИИ динамически извлекать релевантные документы или точки данных в процессе генерации, обеспечивая содержательно насыщенные результаты, соответствующие намерениям пользователя. Этот метод особенно полезен в сценариях, требующих подробной и точной информации, таких как юридические исследования или научный анализ.
Сравнение размеров контекстного окна популярных моделей
 Сравнительная диаграмма размеров контекстного окна популярных моделей ИИ
Сравнительная диаграмма размеров контекстного окна популярных моделей ИИ
Разные LLM имеют различные размеры контекстного окна, адаптированные под разные требования и задачи. GPT-4o, например, имеет размер контекстного окна 128 000 токенов, что значительно повышает его способность обрабатывать обширные входные данные и генерировать контекстуально релевантные ответы. Между тем Gemini 1.5 Pro может использовать контекстное окно более чем на 2 миллиона токенов, предлагая существенные преимущества при работе с большими наборами данных.
Claude 3.5 Sonnet и Llama 3.2 также демонстрируют разные размеры контекстного окна, каждый со своими сильными сторонами и ограничениями. Claude 3.5 Sonnet имеет размер контекстного окна 200 000 токенов, что позволяет ему управлять обширной информацией в рамках одного взаимодействия. В отличие от него, Llama 3.2 поддерживает контекстное окно на 128 000 токенов.
| Модель | Контекстное окно | Максимум выходных токенов |
|---|---|---|
| GPT-4o | 128 000 токенов | 16 384 токена |
| GPT-4-turbo | 128 000 токенов | 4 096 токенов |
| GPT-4 | 8 192 токена | 8 192 токена |
| Gemini 1.5 Pro | 2 097 152 токена | 8 192 токена |
| Claude 3.5 Sonnet | 200 000 токенов | 8192 токена |
| Llama 3.2 | 128 000 токенов | 2048 токенов |
Резюме
В заключение, освоение контекстного окна имеет важнейшее значение для развития возможностей ИИ. Более крупные контекстные окна повышают способность ИИ обрабатывать и анализировать обширные документы, что делает их бесценными в таких областях, как юридические и медицинские исследования. Однако расширение контекстных окон связано с трудностями, включая повышенные вычислительные требования, более высокие затраты и сложные требования к управлению данными.
Внедряя такие методы, как Retrieval-Augmented Generation (RAG) и векторные базы данных, модели ИИ могут оптимизировать использование длинных контекстных окон с помощью внешней базы знаний на основе векторных баз данных, обеспечивая контекстуально релевантные и точные ответы. Заглядывая в будущее, баланс между размером контекстного окна и эффективностью, а также исследование инновационных стратегий будут иметь решающее значение для разработки передовых приложений ИИ, способных эффективно справляться со сложными задачами. Путь к освоению контекстных окон продолжается, а возможности безграничны.
Часто задаваемые вопросы
Что такое контекстное окно в ИИ?
Контекстное окно в ИИ — это диапазон текста вокруг целевого токена, который модель использует для генерации ответов и который определяет объем информации, обрабатываемой ею за один раз. Понимание этой концепции крайне важно для оптимизации взаимодействий с ИИ.
Почему большие контекстные окна важны?
Большие контекстные окна имеют решающее значение, поскольку они значительно улучшают понимание модели ИИ и ее способность анализировать обширные документы, что приводит к более связным и контекстуально релевантным ответам. Это усовершенствование в конечном итоге повышает общее качество взаимодействия.
Как ограничения на токены влияют на модели ИИ?
Ограничения токенов критически влияют на модели ИИ, определяя максимальный размер входных данных, которые они могут обрабатывать. Превышение этих ограничений приводит к неполным или неточным результатам, что требует сегментации текста на более мелкие части.
Каковы проблемы расширения контекстных окон?
Расширение контекстных окон создает значительные проблемы, включая повышенные вычислительные требования и увеличение операционных затрат. Кроме того, оно усложняет управление данными, требуя тщательного рассмотрения перед внедрением.
Как можно улучшить модели ИИ с помощью длинных контекстных окон?
Модели ИИ можно улучшить с помощью длинных контекстных окон, используя такие методы, как Retrieval-Augmented Generation (RAG) и интеграция векторных баз данных, которые помогают обеспечивать контекстуально релевантные и точные ответы. Этот подход значительно повышает производительность модели при работе с обширной информацией.
Дополнительные ресурсы
- Понимание токенов
- Что такое контекстное окно в ИИ?
- Важность больших контекстных окон в моделях ИИ
- Проблемы расширения контекстных окон в моделях ИИ
- RAG: Улучшение AI-моделей с помощью внешней базы знаний для расширенной памяти
- Сравнение размеров контекстного окна популярных моделей
- Резюме
- Часто задаваемые вопросы
- Дополнительные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно