




Как Inkeep и Milvus создали ИИ-помощника на основе RAG для более разумного взаимодействия
Для разработчиков поиск технической документации по различным платформам или сервисам может быть утомительным. Как правило, техническая документация содержит множество разделов и иерархий, в которых бывает сложно ориентироваться. В результате мы часто тратим значительное количество времени на поиск нужных нам ответов. Добавление ИИ-помощника в техническую документацию может стать экономией времени для многих разработчиков, поскольку мы можем просто спросить ИИ о наших запросах, и он предоставит ответы или перенаправит нас на соответствующие страницы и статьи.
На недавнем Unstructured Data Meetup, организованном Zilliz, Роберт Тран, сооснователь и технический директор Inkeep, рассказал о том, как Inkeep и Zilliz создали помощника на базе ИИ для своего сайта документации. Теперь мы можем увидеть этого ИИ-помощника в действии на сайтах документации Zilliz и Milvus.
.В этой статье мы рассмотрим технические детали, представленные Робертом Траном. Итак, без лишних слов, давайте начнем с мотивации интеграции ИИ-помощника в страницы технической документации.
Мотивация внедрения ИИ-ассистента в техническую документацию
Техническая документация - это важный источник информации, который должны предоставлять все платформы, чтобы помочь своим пользователям или разработчикам. Она должна быть интуитивно понятной, исчерпывающей и помогать разработчикам любого уровня опыта в использовании возможностей и функций, доступных на платформах.
Однако по мере того, как платформы вводят множество новых функций, их техническая документация может становиться чрезмерно сложной. Такая сложность может сбить с толку многих разработчиков при навигации по технической документации платформы. Разработчики часто находятся под давлением необходимости быстро получить результат, и время, потраченное на поиск информации в технической документации, может отвлекать их от реальной работы по кодированию и разработке.
Многие платформы предлагают базовые функции поиска в своей технической документации, чтобы помочь разработчикам быстро найти нужный контент, подобно тому, как мы ищем в Google. Пользователи могут ввести ключевые слова, и платформа предоставит список потенциально релевантных страниц для ответа на их вопросы. Однако эти базовые функции поиска часто не понимают контекста запроса пользователя, что приводит к нерелевантным или неполным результатам поиска.
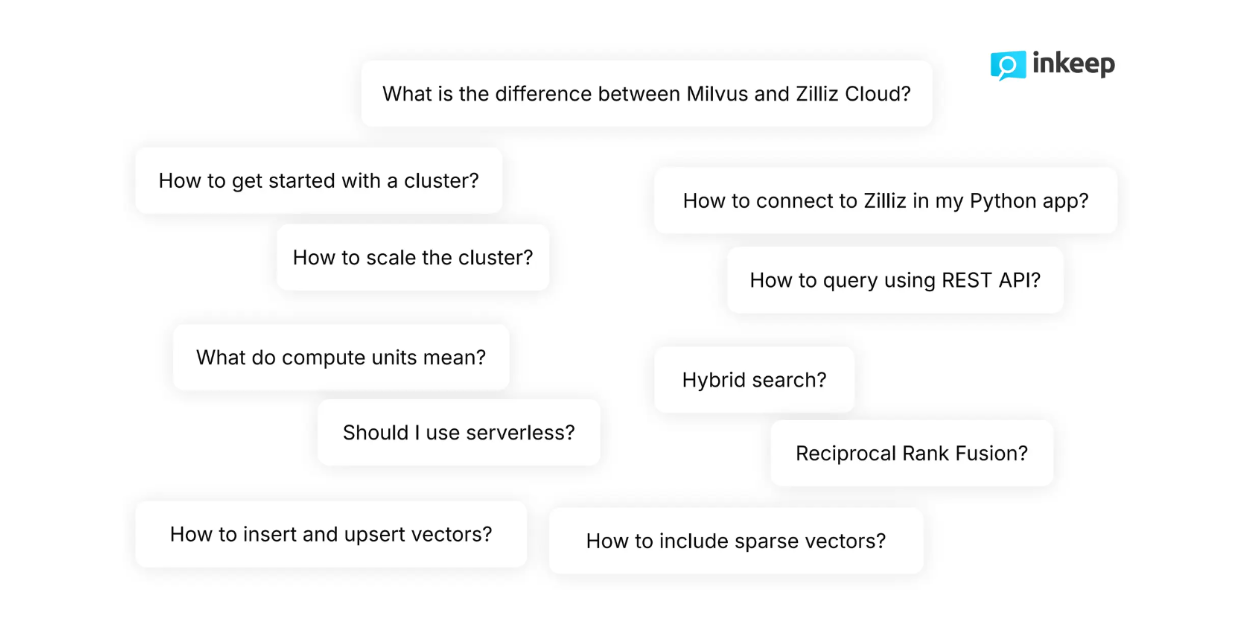 Рисунок - Типичные вопросы, задаваемые разработчиками о Milvus .png
Рисунок - Типичные вопросы, задаваемые разработчиками о Milvus .png
Рисунок: Типичные вопросы, задаваемые разработчиками о Milvus_
Как разработчики, мы знаем, что наши вопросы часто более тонкие и иногда слишком сложные для базовых функций поиска. Например, изучая техническую документацию Zilliz, разработчики обычно задают такие высокотехничные вопросы, как "Как включить разреженные векторы наряду с плотными в процесс поиска?" или "Как динамически масштабировать кластер?". Базовые функции поиска часто не могут удовлетворительно ответить на такие сложные и тонкие вопросы.
Добавление ИИ-ассистента решает эти проблемы. ИИ-помощник способен понять намерения разработчиков и семантический смысл их запросов, что позволяет разработчикам получать необходимую информацию за считанные секунды. Разработчики могут просто ввести свой запрос, и ИИ-ассистент предоставит им ответ или перенаправит их на нужную страницу, вместо того чтобы пролистывать множество контента, что утомительно и отнимает много времени.
Кроме того, ИИ-помощники обычно используют последние достижения в области обработки естественного языка (NLP), такие как большие языковые модели (LLMs, векторный поиск, и Retrieval Augmented Generation (RAG). Именно подход RAG лежит в основе этого ИИ-помощника, позволяя ему понимать нюансы вопросов пользователей и возвращать точные и релевантные ответы за считанные секунды.
В следующем разделе мы обсудим методы, лежащие в основе ИИ-помощника.
Концепция расширенного поиска (RAG)
Retrieval Augmented Generation (RAG) - это метод, который сочетает в себе передовые техники НЛП, такие как векторный поиск и LLM, для генерации точных ответов на запросы пользователей.
 Рисунок- RAG workflow.png
Рисунок- RAG workflow.png
Рисунок: RAG workflow.
В двух словах, рабочий процесс метода RAG довольно прост. Сначала мы, пользователи, задаем запрос. Затем метод RAG подбирает соответствующие документы, которые, возможно, содержат ответ на наш запрос. Затем наш запрос и соответствующие документы объединяются в один связный запрос, после чего отправляются в LLM. Наконец, LLM генерирует ответ на наш запрос, используя предоставленные документы.
Как мы видим, основная концепция RAG заключается в предоставлении LLM релевантного контекста для ответа на наш запрос. У такого подхода есть как минимум два преимущества: во-первых, он снижает риск возникновения у LLM галлюцинаций, то есть генерации неточных и неправдивых ответов. Во-вторых, ответ, сгенерированный LLM, будет более контекстуальным и адаптированным к нашему запросу. Это особенно полезно, когда мы задаем LLM вопросы о содержании внутренних документов.
При реализации RAG необходимо учитывать четыре этапа: получение, индексирование, поиск и генерация.
Всасывание: включает сбор и предварительную обработку данных. Также может быть собрана соответствующая информация и метаданные каждой записи.
Индексирование: включает в себя процесс хранения данных с оптимизированным методом индексирования для быстрого поиска. На этом этапе предварительно обработанные данные преобразуются в векторные вкрапления с помощью модели вкрапления, а затем хранятся в векторной базе данных, например Milvus, с использованием передовых алгоритмов индексирования, таких как FLAT, FAISS или HNSW.
Поиск: включает в себя операции векторного поиска для сопоставления запроса пользователя с хранимыми данными. В этом процессе запрос пользователя сначала преобразуется в векторное вложение с помощью той же модели вложения, которая используется для преобразования хранимых данных. Затем выполняется поиск сходства между запросом пользователя и сохраненными данными, чтобы найти наиболее релевантную информацию в векторной базе данных.
Генерация: включает в себя использование LLM для создания окончательного ответа. Сначала запрос пользователя и наиболее релевантный контекст, полученный на этапе поиска, объединяются в запрос. Затем LLM генерирует ответ на запрос пользователя на основе контекста, представленного в подсказке.
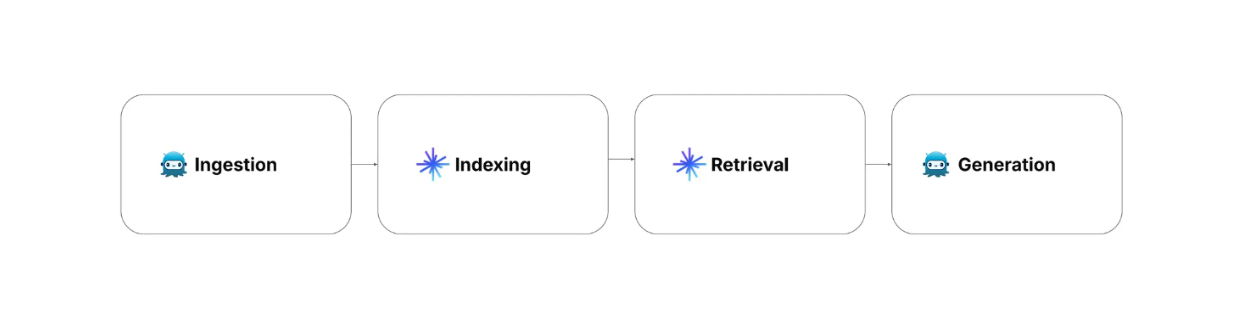 Рисунок - Шаги RAG..png
Рисунок - Шаги RAG..png
Рисунок: Шаги РАГ.
При реализации каждого из вышеупомянутых этапов необходимо учитывать несколько факторов. Например, на этапе ввода данных нам нужно подумать об источнике данных, подходе к их очистке и методе разбивки на части. На этапе индексирования необходимо рассмотреть модель встраивания и векторную базу данных, которые мы хотим использовать, а также алгоритмы индексирования, подходящие для нашего случая использования.
В следующем разделе мы подробно рассмотрим реализацию RAG в Inkeep и Zilliz для создания ИИ-помощника для страниц документации Zilliz и Milvus.
Методы, использованные Inkeep и Zilliz для создания ИИ-помощника
Для создания ИИ-помощника Inkeep и Zilliz используют комбинацию различных методов реализации RAG. Inkeep обрабатывает части ввода и генерации, а Zilliz обеспечивает поддержку Inkeep на этапах индексирования и поиска.
Как уже упоминалось в предыдущем разделе, первым этапом реализации RAG является этап получения информации. На этом этапе Inkeep собирает текстовые данные, связанные с Zilliz и Milvus, из различных источников, таких как техническая [документация] (https://milvus.io/docs), поддержка и часто задаваемые вопросы, а также [репозитории GitHub] (https://github.com/milvus-io/milvus). Затем эти текстовые данные очищаются и разбиваются на части, чтобы каждая часть информации не была ни слишком широкой, ни слишком подробной.
Перед переходом к следующему шагу также собираются метаданные каждой разбитой на части записи. Эти метаданные включают в себя:
Тип источника: взяты ли данные из репозитория GitHub, технической документации, страницы поддержки и FAQ и т. д.
Тип записи: например, версия данных, текст или код. Если это код, то также указывается язык программирования.
Иерархические ссылки: включая дочерние, родительские и родные связи каждой точки данных. Это важно, поскольку данные собираются с веб-сайтов Zilliz.
URL, теги, пути: например, URL, с которых взяты данные. Эти метаданные очень полезны для предоставления ссылок на цитаты или источники в ответах, созданных LLM.
Даты: например, дата публикации каждых данных.
После того как Inkeep собрал данные и их метаданные, следующим шагом будет метод индексирования.
При индексировании предварительно обработанные данные необходимо преобразовать в векторные вкрапления, чтобы обеспечить поиск по сходству на этапе поиска. Для преобразования каждой точки данных в векторное вложение Инкип и Зиллиз используют три различных метода вложения: одну традиционную модель разреженного вложения, одну модель разреженного вложения на основе глубокого обучения и одну модель плотного вложения.
 Рисунок - Разрозненные и плотные вкрапления..png
Рисунок - Разрозненные и плотные вкрапления..png
Рисунок: Разрозненные и плотные вкрапления._
[Разрозненные вкрапления особенно полезны для простых, основанных на ключевых словах и булевых процессах поиска. Поэтому релевантные документы, полученные из разреженного вкрапления, обычно содержат ключевые слова вашего запроса. Между тем, плотное вложение более полезно для улавливания нюансов или семантического значения вашего запроса. Документы, полученные с помощью плотного вложения, могут содержать или не содержать ключевые слова вашего запроса, но их содержание будет очень релевантным.
Существует два различных типа моделей, которые можно использовать для преобразования данных в разреженную вставку: традиционные/статистические модели и модели на основе глубокого обучения. Для ИИ-ассистента Инкип и Зиллиз используют BM25 в качестве традиционной модели и SPLADE/BGE-M3 в качестве модели, основанной на глубоком обучении.
Для преобразования данных в плотные вкрапления существует множество моделей глубокого обучения, например, модели вкраплений от OpenAI, Sentence-Transformers, VoyageAI и др. Для ИИ-ассистента Инкип и Зиллиз используют три различные модели встраивания: MS-MARCO, MPNET и BGE-M3.
После того как все данные преобразуются в разреженные и плотные представления вкраплений, вкрапления хранятся в векторной базе данных для быстрого поиска. Для создания ИИ-ассистента Инкип и Зиллиз используют Milvus в качестве векторной базы данных. Теперь возникает вопрос: зачем нам нужно использовать комбинацию разреженных и плотных вкраплений, если достаточно выбрать одно из них?
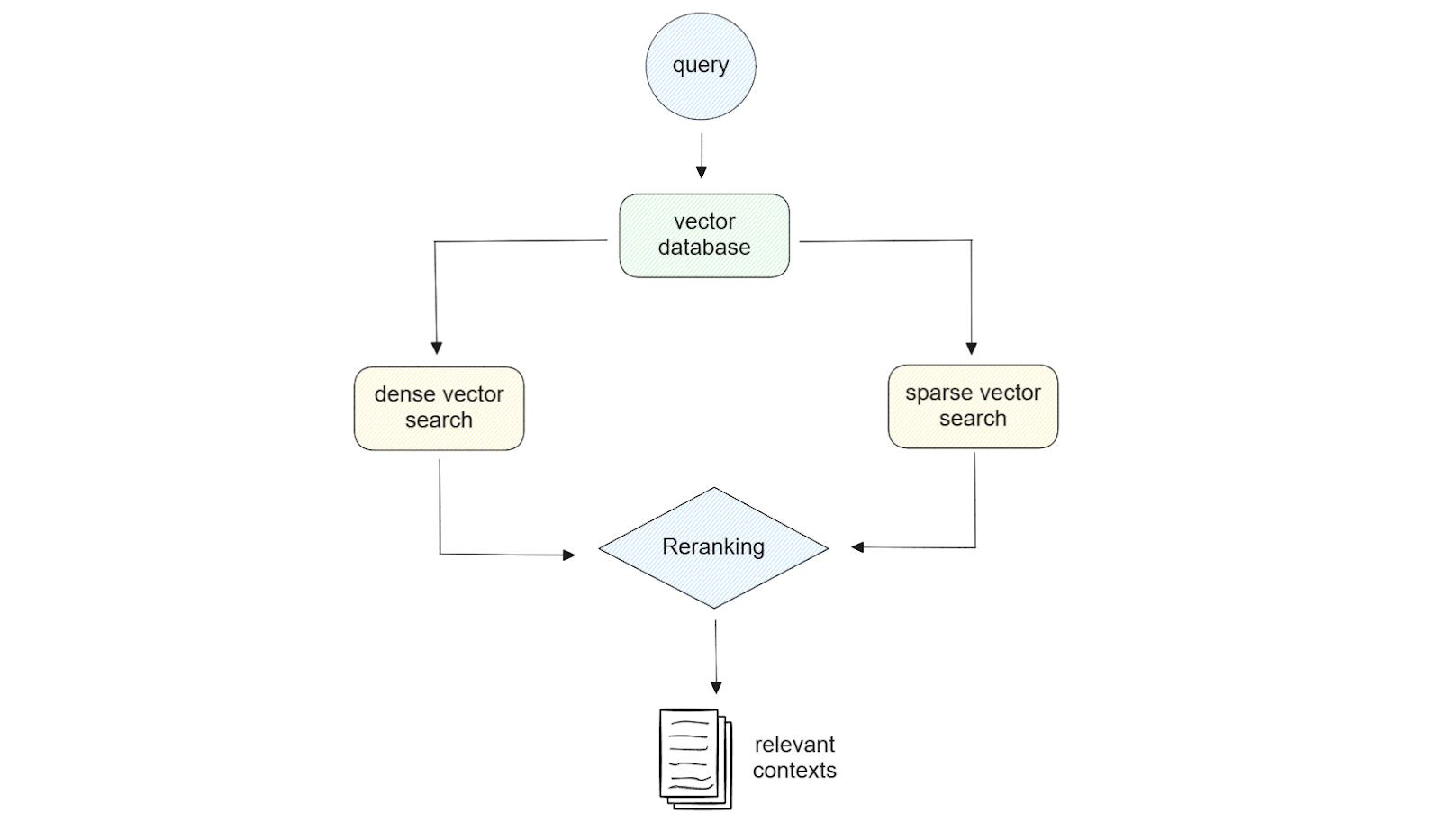 Рисунок-иллюстрация гибридного поиска..png
Рисунок-иллюстрация гибридного поиска..png
Рисунок: Иллюстрация гибридного поиска._
Использование как разреженных, так и плотных вкраплений обеспечивает гибкость на этапе поиска. Например, если наш запрос короткий (менее 5 слов), то достаточно использовать разреженное встраивание. Если же наш запрос длинный, то использование плотного вложения в большинстве случаев обеспечит лучшее качество результата. Кроме того, если мы используем Milvus в качестве базы данных векторов, мы можем использовать возможности гибридного поиска, то есть поиска по сходству с использованием комбинации разреженного и плотного вкрапления. При желании мы можем выполнить поиск по сходству с плотным или разреженным вложением с фильтрацией метаданных.
При реализации гибридного поиска, чтобы найти наиболее релевантный контент для нашего запроса, мы также должны учитывать метод ранжирования. Это связано с тем, что мы получим результаты сходства от двух разных методов, и нам нужен подход, чтобы объединить эти результаты. Для этого Инкип и Зиллиз применили два различных метода ранжирования: взвешенное ранжирование и взаимное ранговое слияние (RRF).
Концепция взвешенного ранжирования проста: мы присваиваем каждому методу определенный вес. Например, мы можем присвоить 60 % веса результату сходства по плотному вкраплению и 40 % по разреженному вкраплению. В то же время в RRF оценки контекстов рассчитываются путем суммирования их взаимных рангов по двум различным методам, часто с дополнительной небольшой константой k, чтобы избежать деления на ноль.
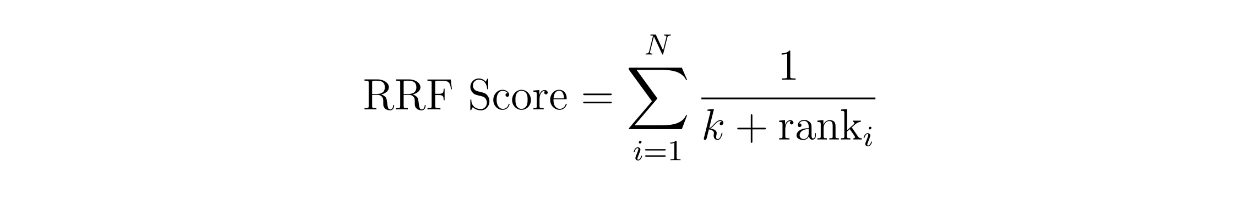 function rrf score.png
function rrf score.png
где N - количество методов, которых должно быть два, поскольку мы реализуем гибридный поиск между разреженным и плотным вложением. Переменная 'rank' - это ранг контекста в методе i, а k - константа.
Используя приведенное выше уравнение RRF, мы можем вычислить RRF-балл для каждого контекста. Контекст с наибольшим показателем RRF будет выбран как наиболее релевантный для запроса.
После того как соответствующий контекст найден, исходный запрос и наиболее релевантный контекст объединяются в одну связную подсказку. Затем этот запрос отправляется в LLM для создания окончательного ответа. Для LLM Inkeep использует модели от OpenAI и Anthropic.
Демонстрация ИИ-ассистента Milvus
В этом разделе мы кратко расскажем о том, как пользоваться ИИ-помощником, созданным Inkeep и Zilliz. Если вы хотите проследить за развитием событий, вы можете ознакомиться с ними на страницах документации Zilliz или Milvus. В этой демонстрации мы будем использовать ИИ-помощник на странице документации Milvus.
Когда вы откроете страницу документации Milvus, вы увидите кнопку "Ask AI" в правом нижнем углу экрана. Нажмите эту кнопку, чтобы перейти к помощнику ИИ.
 screenshot 1.png
screenshot 1.png
Далее появится всплывающее окно, в котором вам будет предложено задать вопрос о том, что вы хотите найти в документации Milvus. Кроме того, вы можете выполнить базовый поиск, нажав на опцию "Поиск" в правом верхнем углу всплывающего окна.
Допустим, мы хотим узнать, как преобразовать наши данные в векторные вкрапления с помощью BGE-M3 и Milvus Python SDK. Мы можем просто ввести наш вопрос, и ИИ-помощник предоставит нам ответ.
 screenshot 2.png
screenshot 2.png
Помимо ответа, ИИ-помощник также предоставит нам ссылки или соответствующие страницы, на которых мы можем найти дополнительную информацию, связанную с полученным ответом.
 скриншот 3.png
скриншот 3.png
Заключение
Интеграция ИИ-помощника в техническую документацию, созданная компаниями Inkeep и Zilliz, демонстрирует, как передовые ИИ-решения могут повысить производительность разработчиков и удобство работы с ними. RAG - основной компонент этого ИИ-помощника, поскольку этот метод помогает LLM давать более точные и контекстуальные ответы на сложные и тонкие запросы.
RAG состоит из четырех ключевых этапов: всасывание, индексирование, поиск и генерация. Векторные базы данных, такие как Milvus, являются ключевым компонентом конвейера RAG, выполняя этапы индексирования и поиска. Методы, используемые на каждом этапе, должны быть тщательно продуманы в зависимости от конкретного случая использования. В этой статье мы также рассмотрели пример того, как Inkeep и Zilliz реализовали различные стратегии на каждом этапе RAG для создания сложного ИИ-помощника.
Чтобы узнать больше о том, как Милвус и Инкип создали этот ИИ-ассистент, посмотрите [повтор выступления Роберта на YouTube] (https://youtu.be/35JdjmiDvWI?list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&t=2879).
Дальнейшее чтение
Читать далее

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.