




검색 증강 세대(RAG) 애플리케이션 구현 모범 사례
검색 증강 생성(RAG)은 LLM의 응답을 개선하고 LLM 환각을 해결하는 데 매우 효과적인 것으로 입증된 방법입니다. 간단히 말해, RAG는 LLM이 보다 정확하고 상황에 맞는 응답을 생성하는 데 도움이 되는 컨텍스트를 제공합니다. 컨텍스트는 내부 문서, 벡터 데이터베이스, CSV 파일, JSON 파일 등 어디에서든 가져올 수 있습니다.
RAG는 함께 작동하는 여러 구성 요소로 구성된 새로운 접근 방식입니다. 이러한 구성 요소에는 쿼리 처리, 컨텍스트 청킹, 컨텍스트 검색, 컨텍스트 재순위 지정, 그리고 응답을 생성하는 LLM 자체가 포함됩니다. 각 구성 요소는 RAG 애플리케이션에서 생성되는 최종 응답의 품질에 영향을 미칩니다. 문제는 각 구성 요소에서 가장 최적의 RAG 성능을 이끌어내는 최적의 방법 조합을 찾기가 어렵다는 것입니다.
이 문서에서는 [이 논문에 따라 모든 RAG 구성 요소에서 일반적으로 사용되는 몇 가지 기법을 살펴보고 각 구성 요소에 대한 최상의 접근 방식을 평가한 다음 가장 최적의 RAG 생성 응답으로 이어지는 최상의 조합을 찾아보겠습니다. 이제 더 이상 고민하지 않고 RAG 구성 요소에 대한 소개부터 시작하겠습니다.
RAG 구성 요소
앞서 언급했듯이 RAG는 학습 데이터를 넘어서는 질문을 하거나 전문 지식이 필요할 때 흔히 발생하는 LLM의 착각 문제를 완화할 수 있는 강력한 방법입니다. 예를 들어, 내부 데이터에 대해 LLM에게 질문하면 부정확한 답변을 얻을 가능성이 높습니다. RAG는 LLM에게 쿼리에 대한 답변을 제공하는 데 도움이 될 수 있는 컨텍스트를 제공함으로써 이 문제를 해결합니다.
RAG는 워크플로우를 형성하는 일련의 구성 요소로 이루어져 있습니다. 일반적인 RAG 구성 요소는 다음과 같습니다:
쿼리 분류: 쿼리가 컨텍스트 검색이 필요한지 아니면 LLM에서 직접 처리할 수 있는지를 결정합니다.
컨텍스트 검색: 쿼리와 가장 관련성이 높은 컨텍스트에서 상위 k개의 후보를 가져옵니다.
컨텍스트 재순위 지정**: 검색 컴포넌트에서 가져온 상위 k개의 후보를 가장 유사한 것부터 정렬합니다.
컨텍스트 재포장: 더 나은 응답 생성을 위해 가장 관련성이 높은 컨텍스트를 보다 구조화된 형식으로 정리합니다.
컨텍스트 요약: 더 나은 응답 생성을 위해 관련 컨텍스트에서 핵심 정보를 추출합니다.
응답 생성: 쿼리 및 관련 컨텍스트를 기반으로 응답을 생성합니다.
그림- RAG 구성 요소..png](https://assets.zilliz.com/Figure_RAG_Components_d88965cf8b.png)
Figure: RAG Components. Source
이러한 RAG 컴포넌트는 응답 생성 과정에서(즉, 모든 컨텍스트를 이미 저장하고 가져올 준비가 된 경우) 유용하지만, RAG 메서드를 구현하기 전에 몇 가지 다른 요소들을 고려해야 합니다.
컨텍스트 문서를 벡터 임베딩으로 변환하여 RAG 접근 방식에서 유용하게 사용하려면 컨텍스트 문서를 벡터 임베딩으로 변환해야 합니다. 따라서 입력 문서를 임베딩으로 표현하기 위한 가장 적합한 임베딩 모델과 전략을 선택하는 것이 매우 중요합니다.
임베딩은 입력 문서의 의미론적으로 풍부한 표현을 포함합니다. 그러나 컨텍스트로 사용되는 문서가 너무 길면 적절한 응답을 생성할 때 LLM에 혼란을 줄 수 있습니다. 이 문제를 해결하기 위한 일반적인 접근 방식은 입력 문서를 여러 개의 청크로 분할한 다음 각 청크를 임베딩으로 변환하는 청킹 방법을 적용하는 것입니다. 너무 짧은 청크는 정보가 불충분할 가능성이 높으므로 최적의 청크 방법과 크기를 선택하는 것이 중요합니다.
그림- RAG 워크플로우.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
_그림: RAG 워크플로우 _그림
각 청크를 임베딩으로 변환한 후에는 이러한 임베딩을 위한 적절한 저장 공간을 고려해야 합니다. 많은 임베딩을 처리하지 않는다면 디바이스의 로컬 메모리에 직접 저장할 수 있습니다. 하지만 실제로는 수백, 수백만 개의 임베딩을 처리하는 것이 일반적입니다. 이 경우 [밀버스 또는 관리형 서비스인 질리즈 클라우드와 같은 벡터 데이터베이스가 필요하며, 올바른 벡터 데이터베이스를 선택하는 것이 RAG 애플리케이션의 성공에 매우 중요합니다.
마지막으로 고려해야 할 사항은 LLM 자체입니다. 해당되는 경우 특정 요구 사항을 보다 정확하게 타겟팅하기 위해 LLM을 미세 조정할 수 있습니다. 그러나 대부분의 경우, 특히 많은 매개변수가 있는 고성능 LLM을 사용하는 경우 미세 조정은 비용이 많이 들고 불필요한 작업입니다.
다음 섹션에서는 각 RAG 컴포넌트에 대한 최상의 접근 방식에 대해 설명합니다. 그 다음에는 이러한 최상의 접근 방식을 조합하여 성능과 효율성의 균형을 맞추는 RAG 배포를 위한 몇 가지 전략을 제안합니다.
쿼리 분류
이전 섹션에서 언급했듯이 RAG는 특히 내부 데이터의 전문 지식이 필요할 때 LLM이 정확하고 상황에 맞는 응답을 생성하도록 하는 데 유용합니다. 그러나 RAG는 응답 생성 프로세스의 런타임을 증가시키기도 합니다. 문제는 모든 쿼리에 검색 프로세스가 필요한 것은 아니며, 많은 쿼리는 LLM에서 직접 처리할 수 있다는 것입니다. 따라서 쿼리에 컨텍스트 검색 프로세스가 필요하지 않은 경우 이를 건너뛰는 것이 더 유리할 수 있습니다.
쿼리 분류 모델을 구현하여 응답 생성 프로세스 전에 쿼리에 컨텍스트 검색이 필요한지 여부를 결정할 수 있습니다. 이러한 분류 모델은 일반적으로 쿼리에 검색이 필요한지 여부를 예측하는 것을 주요 목표로 하는 BERT와 같은 지도 모델로 구성됩니다. 그러나 다른 지도 모델과 마찬가지로 추론에 사용하기 전에 모델을 학습시켜야 합니다. 모델을 훈련하려면 프롬프트의 검색 필요 여부를 포함하여 예제 프롬프트와 그에 해당하는 이진 레이블의 데이터 세트를 생성해야 합니다.
그림-질의 분류 데이터 세트 예시..png](https://assets.zilliz.com/Figure_Query_classification_dataset_example_157161163d.png)
그림: 쿼리 분류 데이터세트 예제. Source
논문](https://arxiv.org/pdf/2407.01219)에서는 쿼리 분류를 위해 BERT 기반 다국어 모델을 사용하고 있습니다. 학습 데이터에는 번역, 요약, 재작성, 문맥 내 학습 등과 같은 총 15가지 유형의 프롬프트가 포함되어 있습니다. 프롬프트에는 두 가지 레이블이 있습니다: "프롬프트가 전적으로 사용자가 제공한 정보에 기반하고 검색이 필요하지 않은 경우 '충분'으로, 프롬프트 정보가 불완전하고 전문 정보가 필요하며 검색 프로세스가 필요한 경우 '불충분'으로 표시됩니다. 이 접근 방식을 사용하여 이 모델은 정확도와 F1 점수 모두에서 95%를 달성했습니다.
이 쿼리 분류 단계는 LLM에서 직접 처리할 수 있는 쿼리에 대한 불필요한 검색을 피함으로써 RAG 프로세스의 효율성을 크게 향상시킬 수 있습니다. 필터 역할을 하여 추가 컨텍스트가 필요한 쿼리만 시간이 더 많이 소요되는 검색 프로세스를 거치지 않도록 합니다.
그림- 쿼리 분류기 결과..png](https://assets.zilliz.com/Figure_Query_classifier_result_3aaa0173d7.png)
그림: 쿼리 분류기 결과. Source
청킹 기법 ## 청킹 기법
청킹은 긴 입력 문서를 작은 세그먼트로 분할하는 프로세스를 말합니다. 이 프로세스는 LLM에 보다 세분화된 컨텍스트를 제공하는 데 매우 유용합니다. 청킹에는 토큰 수준 및 문장 수준 접근 방식을 비롯한 여러 가지 방법이 있습니다. 문장 수준의 청킹은 종종 단순성과 문맥의 의미적 보존 사이의 균형을 잘 유지합니다. 청킹 방법을 선택할 때는 너무 짧은 청크는 LLM에 유용한 컨텍스트를 제공하지 못할 수 있으므로 청크 크기에 주의를 기울여야 합니다.
그림- 긴 문서를 작은 청크로 나누기.png](https://assets.zilliz.com/Figure_Splitting_a_long_document_into_smaller_chunks_0929fcee85.png)
그림: 긴 문서를 작은 덩어리로 나누기_그림: 긴 문서를 작은 덩어리로 나누기
최적의 청크 크기를 찾기 위해 Lyft 2021 문서에 대한 평가가 수행되었습니다. 문서의 처음 60페이지를 코퍼스로 선택하고 여러 크기로 청크화했습니다. 그런 다음 LLM을 사용하여 이 60페이지를 기반으로 170개의 쿼리를 생성했습니다. 임베딩에는 text-embedding-ada-002 모델이 사용되었고, 선택한 쿼리를 기반으로 응답을 생성하기 위한 LLM으로는 Zephyr 7B 모델이 사용되었습니다.
다양한 청크 크기에 대한 모델의 성능을 평가하기 위해 GPT-3.5 Turbo를 사용했습니다. 응답 품질을 평가하기 위해 충실도와 관련성이라는 두 가지 메트릭이 사용되었습니다. 충실도는 응답이 허위인지 또는 검색된 컨텍스트와 일치하는지 여부를 측정하고, 관련성은 검색된 컨텍스트와 응답이 쿼리와 일치하는지 여부를 측정합니다.
그림- 다양한 청크 크기 비교. .png](https://assets.zilliz.com/Figure_Comparison_of_different_chunk_sizes_4156be62c9.png)
그림: 다양한 청크 크기 비교. Source
결과에 따르면 LLM에서 관련성이 높은 응답을 생성하려면 최대 청크 크기가 512 토큰인 것이 선호됩니다. 256개 토큰과 같이 더 짧은 청크 크기도 성능이 우수하며 RAG 애플리케이션의 전반적인 런타임을 개선할 수 있습니다. small2big 및 슬라이딩 윈도우와 같은 고급 청킹 기술을 사용하여 다양한 청크 크기의 이점을 결합할 수 있습니다.
Small2big은 청크 블록 관계를 구성하는 청킹 접근 방식입니다. 작은 크기의 청크는 쿼리를 일치시키는 데 사용되며, 작은 청크의 정보를 포함하는 더 큰 청크는 LLM의 최종 컨텍스트로 사용됩니다. 슬라이딩 윈도우는 청크 간에 토큰 중첩을 제공하여 컨텍스트 정보를 보존하는 청킹 방식입니다.
그림- 다양한 청킹 기법 비교..png](https://assets.zilliz.com/Figure_Comparison_of_different_chunking_techniques_2ac7bcdb48.png)
그림: 다양한 청킹 기법 비교. Source
실험 결과, 청크 크기가 175개로 작을 때, 청크 크기가 512개로 클 때, 청크가 20개로 겹칠 때 두 청크 기법 모두 LLM 응답의 충실도와 관련성 점수를 향상시키는 것으로 나타났습니다.
다음으로, 각 청크를 벡터 임베딩으로 표현하기 위한 최적의 임베딩 모델을 찾는 것이 중요합니다. 이를 위해 네임스페이스-Pt/msmarco에 대한 테스트가 수행되었습니다. 그 결과 LLM Embedder와 bge-large-en 모델 모두 가장 우수한 성능을 보였습니다. 그러나 LLM Embedder가 bge-large-en보다 3배 더 작기 때문에 실험의 기본 임베딩으로 선택했습니다.
그림- 네임스페이스의 다양한 임베딩 모델에 대한 결과-Pt:msmarco. .png](https://assets.zilliz.com/Figure_Results_for_different_embedding_models_on_namespace_Pt_msmarco_5e4b6f5e16.png)
그림: 네임스페이스의 다양한 임베딩 모델에 대한 결과 -Ptmsmarco. Source
벡터 데이터베이스
벡터 데이터베이스는 RAG 애플리케이션에서 특히 관련 컨텍스트를 저장하고 검색하는 데 중요한 역할을 합니다. 일반적인 실제 RAG 애플리케이션에서는 방대한 양의 문서를 다루기 때문에 저장해야 할 컨텍스트 임베딩이 엄청나게 많습니다. 이러한 경우 이러한 임베딩을 로컬 메모리에 저장하는 것만으로는 충분하지 않으며, 대량의 임베딩 모음에서 관련 컨텍스트를 검색하는 연산을 수행하는 데 상당한 시간이 소요됩니다.
벡터 데이터베이스는 이러한 문제를 해결하기 위해 고안되었습니다. 벡터 데이터베이스를 사용하면 수백만에서 수십억 개의 벡터 임베딩을 저장하고 순식간에 컨텍스트 검색을 수행할 수 있습니다. 사용 사례에 가장 적합한 벡터 데이터베이스를 선택할 때는 인덱스 유형 지원, 수십억 개 규모의 벡터 지원, 하이브리드 검색 지원, 클라우드 네이티브 기능 등 여러 가지 요소를 고려해야 합니다.
이러한 기준 중 Milvus는 Weaviate, Chroma, Faiss, Qdrant 등과 같은 경쟁사에 비해 최고의 오픈 소스 벡터 데이터베이스로 돋보입니다.
 다양한 벡터 데이터베이스 비교..png
다양한 벡터 데이터베이스 비교..png
다양한 벡터 데이터베이스 비교. Source._
인덱스 유형 지원](https://zilliz.com/learn/vector-index) 측면에서 Milvus는 역파일 인덱스(IVF-FLAT), [계층적 탐색 가능한 작은 세계](HNSW 등 검색 프로세스 속도를 높이기 위해 설계된 인덱스 유형과 같은 다양한 요구에 맞는 여러 인덱싱 방법을 제공합니다. 컨텍스트를 저장하는 데 필요한 메모리를 압축하기 위해 임베딩의 인덱싱 프로세스 중에 제품 정량화(PQ)를 구현할 수도 있습니다.
밀버스는 하이브리드 검색 접근 방식도 지원합니다. 이 접근 방식을 사용하면 컨텍스트 검색 프로세스 중에 서로 다른 두 가지 방법을 결합할 수 있습니다. 예를 들어, 밀도 임베딩과 스파스 임베딩을 결합하여 관련성 있는 컨텍스트를 검색함으로써 검색된 컨텍스트와 쿼리의 관련성을 높일 수 있습니다. 이는 결과적으로 LLM에서 생성되는 응답도 향상시킵니다. 또한 원하는 경우 고밀도 임베딩과 메타데이터 필터링을 결합할 수도 있습니다.
수십억 개의 임베딩을 저장하기 위해 GCP나 AWS 등 클라우드에서 Milvus를 사용하려면 [관리형 서비스: 질리즈 클라우드를 선택하면 됩니다.
질리즈 클라우드를 사용하면 용량과 성능 모두에 최적화된 클러스터 유닛(CU)을 생성하여 대규모 임베딩을 저장할 수 있습니다. 예를 들어, 13억 개의 128차원 벡터를 지원하는 256개의 성능 최적화 CU 또는 30억 개의 128차원 벡터를 지원하는 128개의 용량 최적화 CU를 생성할 수 있습니다.
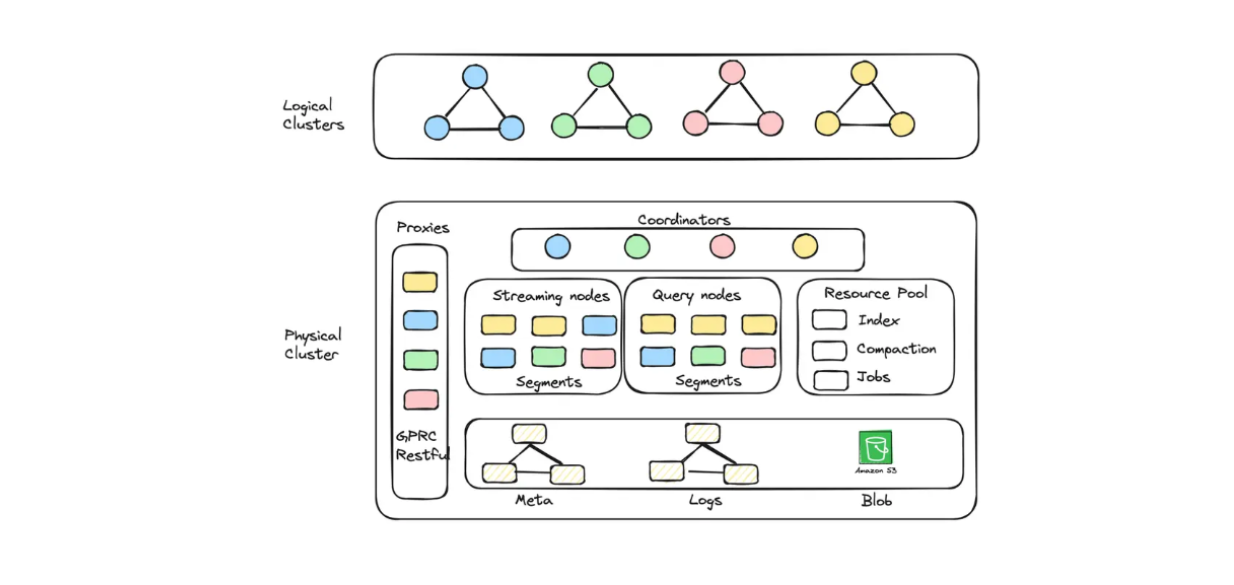 질리즈 클라우드 서버리스에 구현된 논리적 클러스터 및 오토 스케일링 다이어그램..png
질리즈 클라우드 서버리스에 구현된 논리적 클러스터 및 오토 스케일링 다이어그램..png
질리즈 클라우드 서버리스에서 구현된 논리적 클러스터 및 오토 스케일링 다이어그램._ _질리즈 클라우드 서버리스에서 구현된 논리적 클러스터 및 오토 스케일링 다이어그램
밀버스로 RAG 애플리케이션을 구축하면서 운영 비용도 절감하고 싶다면 [질리즈 클라우드 서버리스]를 선택하시면 됩니다. 이 서비스는 Milvus 내에서 자동 확장 기능을 제공하며, 비즈니스 성장에 따라 비용만 증가합니다. 서버리스 옵션은 유휴 상태가 아닌 서비스를 사용할 때만 비용을 지불하기 때문에 비용 절감에도 적합합니다.
질리즈 클라우드는 최근 새로운 마이그레이션 서비스, 다중 복제본, Fivetran 커넥터와의 새로운 통합, 자동 확장 기능, 프로덕션 준비 기능 등 여러 가지 흥미로운 업데이트를 출시했습니다. 자세한 내용은 아래에서 확인하세요:
질리즈 클라우드 업데이트: 마이그레이션 서비스, 파이브트란 커넥터, 멀티 레플리카 등](https://zilliz.com/blog/zilliz-sep-24-launch)
질리즈 클라우드의 향상된 모니터링 및 가시성](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
파이브트란과 밀버스로 AI 기반 검색 활용하기](https://zilliz.com/blog/unlock-ai-powered-search-with-fivetran-and-milvus)
오픈소스 Milvus에서 Zilliz Cloud로 마이그레이션해야 하는 5가지 이유 ](https://zilliz.com/blog/top-5-reasons-to-migrate-milvus-to-zilliz-cloud)
검색 기술 ## 검색 기법
검색 구성 요소의 주요 목표는 주어진 쿼리에 대해 가장 관련성이 높은 상위 k개의 컨텍스트를 가져오는 것입니다. 그러나 이 구성 요소의 전반적인 품질에 영향을 미칠 수 있는 중요한 문제는 쿼리 자체에서 비롯됩니다. 원본 쿼리는 종종 잘못 작성되거나 표현되어 RAG 애플리케이션이 관련 컨텍스트를 가져오는 데 필요한 의미론적 정보가 부족합니다.
이 문제를 해결하기 위해 일반적으로 적용되는 몇 가지 기술은 다음과 같습니다:
쿼리 재작성**: 명확성과 의미론적 정보를 개선하기 위해 원래 쿼리를 다시 작성하라는 메시지를 LLM에 표시합니다.
쿼리 분해: 원본 쿼리를 하위 쿼리로 분해하고 이러한 하위 쿼리를 기반으로 검색을 수행합니다.
의사 문서 생성](https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings):** 원본 쿼리를 기반으로 가상 문서 또는 합성 문서를 생성한 다음 이 가상 문서를 사용하여 데이터베이스에서 유사한 문서를 검색합니다. 이 접근 방식의 가장 잘 알려진 구현은 HyDE(가상 문서 임베딩)입니다.
실험에 따르면 HyDE와 하이브리드 검색을 결합하는 것이 쿼리 재작성 및 쿼리 분해에 비해 TREC DL19/20에서 가장 좋은 결과를 가져오는 것으로 나타났습니다. 실험에서 언급한 하이브리드 검색은 밀집 임베딩을 얻기 위해 LLM Embedder와 BM25를 결합하여 스파스 임베딩을 얻습니다.
HyDe + 하이브리드 검색의 워크플로는 다음과 같습니다. 먼저, HyDE로 쿼리에 대한 답변을 제공하는 가상의 문서를 생성합니다. 다음으로, 이 가상의 문서를 원래 쿼리와 연결한 후 LLM Embedder와 BM25를 사용해 각각 밀도 및 희소 임베딩으로 변환합니다.
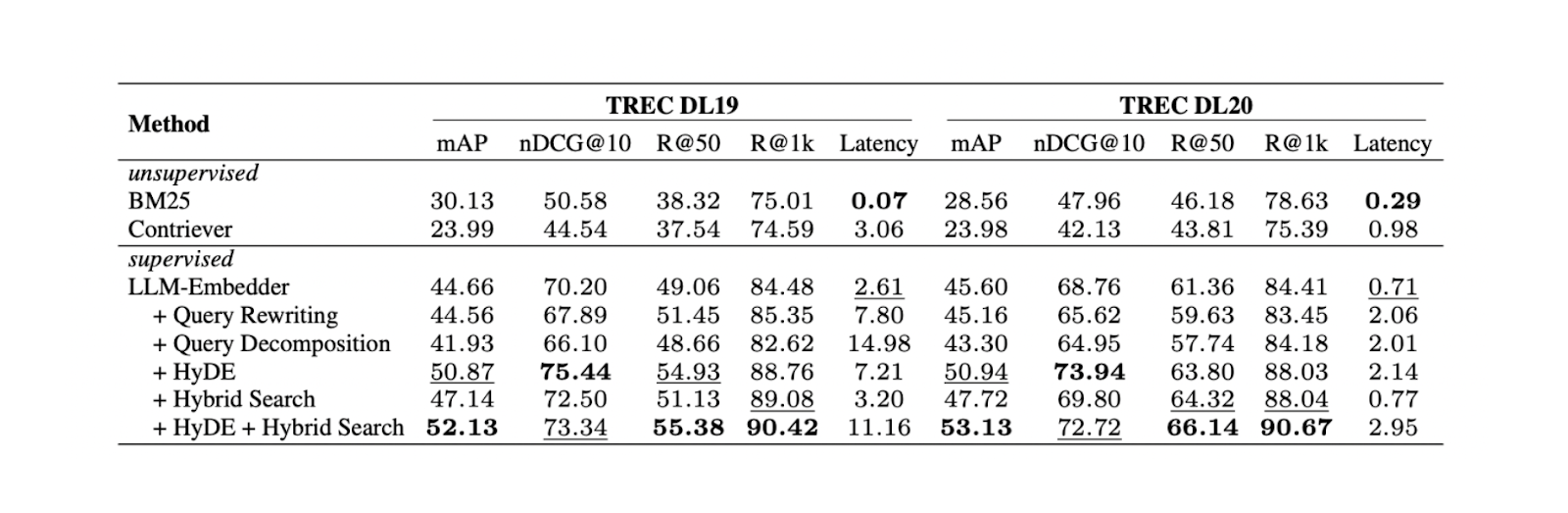 검색 방법별 결과. .png
검색 방법별 결과. .png
다른 검색 방법에 대한 결과. Source
HyDE와 하이브리드 검색을 조합하면 최상의 결과를 얻을 수 있지만, 계산 비용이 더 많이 듭니다. 여러 NLP 데이터 세트에 대한 추가 테스트에 따르면, 하이브리드 검색과 고밀도 임베딩만 사용하는 경우 모두 HyDE + 하이브리드 검색과 비슷한 성능을 보이지만 지연 시간은 거의 10배 더 낮습니다. 따라서 하이브리드 검색을 사용하는 것이 더 권장됩니다.
하이브리드 검색을 사용하기 때문에 검색된 컨텍스트는 밀집 임베딩과 희소 임베딩에서 벡터 검색을 기반으로 합니다. 따라서 이 공식에 따라 고밀도 임베딩과 희소 임베딩 사이의 가중치가 전체 관련성 점수에 미치는 영향을 살펴보는 것도 흥미롭습니다:
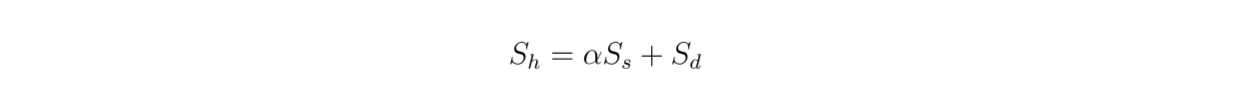 공식.png
공식.png
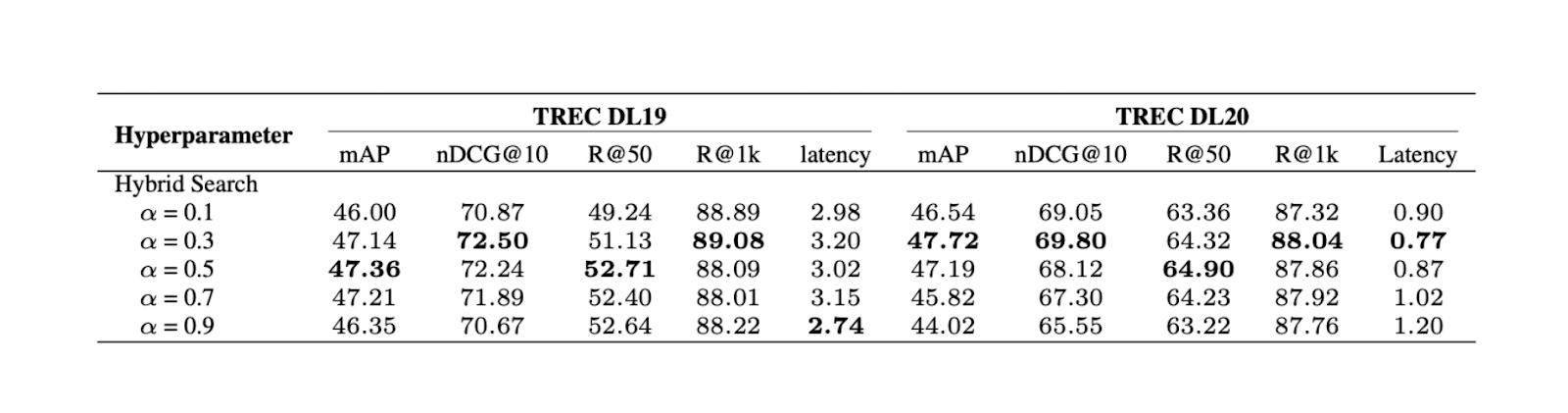 그림- 알파 값이 다른 하이브리드 검색 결과..png
그림- 알파 값이 다른 하이브리드 검색 결과..png
그림: 알파 값이 다른 하이브리드 검색 결과. Source.
실험 결과, 0.3의 가중치 값이 TREC DL19/20에서 가장 좋은 전체 관련성 점수를 산출하는 것으로 나타났습니다.
재랭크 및 재포장 기법
재랭크 기법](https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval)의 주요 목표는 검색 방법에서 가져온 가장 관련성이 높은 상위 k개의 컨텍스트를 다시 정렬하여 가장 유사한 컨텍스트가 목록의 맨 위에 반환되도록 하는 것입니다. 컨텍스트 순위를 재조정하는 데는 두 가지 일반적인 접근 방식이 있습니다:
DLM 재랭크**: 이 방법은 딥러닝 모델을 사용하여 순위를 재조정합니다. 이 모델은 원래 쿼리와 문맥으로 구성된 한 쌍을 입력으로, 'true'(쌍이 서로 관련성이 있는 경우) 또는 'false' 이진 레이블을 출력으로 사용하여 학습됩니다. 그런 다음 모델이 쿼리와 컨텍스트의 쌍을 "true"로 예측할 때 모델이 반환하는 확률에 따라 컨텍스트가 정렬됩니다.
틸드 재랭크**: 이 접근 방식은 원래 쿼리에서 각 용어의 가능성을 사용하여 순위를 재조정합니다. 추론 시간 동안 쿼리 가능성 구성 요소(TILDE-QL)만을 사용하여 더 빠르게 재랭킹하거나, TILDE-QL과 문서 가능성 구성 요소(TILDE-DL)를 결합하여 더 높은 계산 비용으로 재랭킹 결과를 개선할 수 있습니다.
그림- 다양한 재랭크 방법의 결과..png](https://assets.zilliz.com/Figure_Results_of_different_reranking_methods_0174dc1792.png)
그림: 다양한 재랭킹 방법의 결과. Source
MS MARCO Passage 랭킹 데이터 세트에 대한 실험 결과, Llama 27B 모델을 사용한 DLM 리랭크 방식이 가장 우수한 리랭크 성능을 보여줍니다. 그러나 대규모 모델이기 때문에 이 모델을 사용하면 상당한 계산 비용이 발생합니다. 따라서 성능과 계산 효율성 사이의 균형을 제공하는 모노 T5를 사용하는 것이 DLM 리랭킹에 더 권장됩니다.
리랭크 단계 후에는 리랭크된 컨텍스트를 내림차순('포워드') 또는 오름차순('리버스')으로 LLM에 제시하는 방법도 고려해야 합니다. 이 백서에서 수행한 실험에 따르면 '역방향' 구성을 사용하면 최상의 응답 품질이 생성된다는 결론을 내릴 수 있습니다. 가설은 관련성이 높은 문맥을 쿼리에 더 가깝게 배치하면 최적의 결과를 얻을 수 있다는 것입니다.
요약 기법 ## 요약 기법
이전 구성 요소에서 검색된 긴 컨텍스트가 있는 경우, 이를 보다 간결하게 만들고 중복 정보를 제거하고자 할 수 있습니다. 이러한 목표를 달성하기 위해 일반적으로 요약 접근 방식이 구현됩니다.
컨텍스트 요약 기법에는 두 가지가 있습니다: 추출적 요약과 추상적 요약.
추출적 요약은 입력 문서를 더 작은 세그먼트로 나눈 다음 중요도에 따라 순위를 매깁니다. 반면 추상적 방식은 관련 정보만 포함하는 새로운 문맥 요약을 생성합니다.
그림- 서로 다른 요약 방법 비교..png](https://assets.zilliz.com/Figure_Comparison_between_different_summarization_methods_3e8e54c91c.png)
그림: 다양한 요약 방법 간 비교. Source
세 가지 데이터 세트(NQ, TriviaQA, HotpotQA)에 대한 실험 결과, Recomp를 사용한 추상적 요약이 다른 추상적 및 추출적 방법에 비해 가장 우수한 성능을 보였습니다.
최고의 RAG 기법 요약
이제 특정 벤치마크 데이터 세트에 대한 각 RAG 구성 요소에 대한 최상의 접근 방식을 알았으므로, 더 많은 데이터 세트에서 이전 섹션에서 언급한 모든 접근 방식을 추가로 테스트할 수 있습니다. 결과는 각 구성 요소가 RAG 애플리케이션의 전반적인 성능에 기여한다는 것을 보여줍니다. 아래는 다섯 가지 데이터 세트를 기준으로 각 구성 요소의 각 접근 방식에 대한 결과를 요약한 것입니다:
그림-최적의 RAG 사례 검색 결과..png](https://assets.zilliz.com/Figure_Results_of_the_search_for_optimal_RAG_practices_5d8abe4f90.png)
그림: 최적의 RAG 관행 검색 결과. Source
쿼리 분류 구성 요소는 응답의 정확성을 개선하고 전체 런타임 지연 시간을 줄이는 데 도움이 되는 것으로 입증되었습니다. 이 초기 단계는 쿼리에 컨텍스트 검색이 필요한지 아니면 LLM에서 직접 처리할 수 있는지를 결정하여 시스템의 효율성을 최적화하는 데 도움이 됩니다.
검색 구성 요소는 쿼리와 관련하여 관련성 있는 컨텍스트 후보를 확보하는 데 매우 중요합니다. 이 구성 요소의 경우, Milvus 또는 관리형 서비스인 Zilliz Cloud와 같이 확장성과 성능이 뛰어난 벡터 데이터베이스를 사용하는 것이 좋습니다. 또한 하이브리드 검색 또는 고밀도 임베딩 검색이 권장됩니다. 이러한 방법은 포괄적인 컨텍스트 매칭과 계산 효율성 사이에서 균형을 이룹니다.
재랭크 구성 요소는 검색 구성 요소에서 검색된 상위 k개의 컨텍스트를 다시 정렬하여 가장 관련성이 높은 컨텍스트를 얻을 수 있도록 합니다. 성능과 계산 비용의 균형으로 인해 재랭크에는 monoT5 모델이 권장됩니다. 이 단계에서는 컨텍스트 선택을 구체화하여 쿼리와 가장 관련성이 높은 컨텍스트의 우선순위를 지정합니다.
컨텍스트를 다시 패킹하려면 역방향 방법을 사용하는 것이 좋습니다. 이 접근 방식은 가장 관련성이 높은 컨텍스트를 쿼리와 가장 가까운 곳에 배치하여 LLM으로부터 보다 정확하고 일관된 응답을 이끌어낼 수 있습니다.
마지막으로 Recomp를 사용한 추상적 방법이 컨텍스트 요약에 가장 우수한 성능을 보였습니다. 이 기법은 핵심 정보를 보존하면서 긴 문맥을 압축하는 데 도움이 되므로 LLM이 관련성 있는 응답을 더 쉽게 처리하고 생성할 수 있습니다.
LLM 미세 조정
대부분의 경우, 특히 많은 파라미터가 있는 고성능 LLM을 사용하는 경우에는 LLM 미세 조정이 필요하지 않습니다. 하지만 하드웨어 제약이 있어 더 작은 LLM만 사용할 수 있는 경우에는 사용 사례와 관련된 응답을 생성할 때 더 강력하게 만들기 위해 미세 조정이 필요할 수 있습니다. LLM을 미세 조정하기 전에 학습 데이터로 사용할 데이터를 고려해야 합니다.
데이터를 준비하는 동안 프롬프트와 컨텍스트의 학습 데이터를 한 쌍의 입력으로 수집하고 생성된 텍스트의 예를 출력으로 사용할 수 있습니다. 실험에 따르면 학습 중에 관련성 있는 문맥과 무작위로 선택한 문맥을 혼합하여 데이터를 보강하는 것이 가장 좋은 결과를 가져오는 것으로 나타났습니다. 이는 미세 조정 중에 관련성 있는 컨텍스트와 무작위 컨텍스트를 혼합하면 LLM의 견고성을 향상시킬 수 있다는 직관에 따른 것입니다.
결론
이 글에서는 쿼리 분류부터 컨텍스트 요약에 이르기까지 다양한 RAG 구성 요소를 살펴보았습니다. 각 구성 요소에서 최적의 성능을 제공하는 접근 방식에 대해 논의하고 강조했습니다.
이러한 최적화된 구성 요소들은 함께 작동하여 RAG 시스템의 전반적인 성능을 향상시킵니다. 이를 통해 계산 효율성을 유지하면서 생성된 응답의 품질과 관련성을 개선하고 있습니다. 각 구성 요소에 이러한 모범 사례를 구현함으로써 다양한 쿼리와 작업을 처리할 수 있는 보다 강력하고 효과적인 RAG 시스템을 만들 수 있습니다.
더 읽어보기
밀버스로 AI 앱 빌드하기: 튜토리얼 및 노트북](https://zilliz.com/learn/milvus-notebooks)
밀버스, 랭체인, OpenAI로 다국어 RAG를 구축하는 방법](https://zilliz.com/blog/building-multilingual-rag-milvus-langchain-openai)
GraphRAG란? 지식 그래프로 RAG 향상시키기 ](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
RAG 애플리케이션을 평가하는 방법 ](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
계속 읽기

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.