




**畳み込みニューラルネットワークとは?エンジニアのためのガイド

**畳み込みニューラルネットワークとは?エンジニアのためのガイド
畳み込みニューラルネットワーク](https://zilliz.com/glossary/convolutional-neural-network)(CNN)は、画像や動画、時には音声ファイルなどの視覚データ用に調整された深層学習モデルである。
CNNは、コンピュータ・ビジョン、[画像分析と 処理、物体検出、さらには自然言語処理(NLP)といった分野を変革してきた。
MLP(多層パーセプトロン)](https://machinelearningmastery.com/neural-networks-crash-course/)や完全連結ネットワークのような従来のニューラルネットワークは、画像データを平坦なベクトルとして扱います。これは、視覚データに存在する空間情報を扱う際に制限となり得ます。これは、間違った仮定(帰納的バイアス)のため、精度が低くなる可能性があります。
CNNは、画像データのピクセルの局所的な連結性や内容といった画像構造を保持することで、これらの問題に対処し、パターン認識を効率化する。
この投稿では、CNNの利点を強調し、そのアーキテクチャを説明し、CNNモデルを設計する簡単な例を示す。
CNN を使う主な理由
CNNは生の視覚データから意味のある特徴を抽出することに優れており、従来のニューラルネットワークを凌駕します。CNNを使う理由は以下の通りです:
パラメーターの共有***-CNNは入力の異なる領域にわたって同じパラメーターのセットを共有するため、高次元データの隠れたパターンを効率的に識別するのに役立つ。
CNNはプーリングと畳み込みの技法を使用するため、完全連結ネット ワークに比べてパラメータ数が大幅に削減される。
CNNは人間の視覚システムの階層構造を模倣している。
最先端の性能***-CNNは、物体検出、画像処理、音声認識、画像セグメンテーションなどのタスクにおいて、従来のニューラルネットワークを常に凌駕しています。最近のコンピュータ・ビジョンの進歩により、畳み込み型と非畳み込み型のTransformersも導入されていることに注意。
畳み込みニューラルネットワークの利点と欠点
CNNはコンピュータビジョンのゲームを変えたが、我々は長所と短所の両方を知る必要がある。CNNの長所と短所を掘り下げてみよう:
畳み込みニューラルネットワークの利点:
- パターンと特徴の検出:CNNは画像、ビデオ、音声信号のパターンや特徴を検出するのに優れている。その階層構造により、生データから複雑な特徴を学習することができる。
- 変形に対する不変性:CNNは並進、回転、スケーリングに不変である。つまり、画像内のオブジェクトの位置、向き、サイズが異なっていても認識することができる。
- 自動特徴抽出:CNNはエンド・ツー・エンドの学習が可能で、手動での特徴抽出は不要。ネットワークは生の入力データから直接、関連する特徴を見つけるように学習する。
- スケーラビリティと精度:CNNは大量のデータを扱うことができ、複雑なタスクでも正確である。より多くのデータが与えられると、その性能は通常向上する。
畳み込みニューラルネットワークの欠点:
1.計算コスト:CNNの学習には計算コストがかかり、大量のメモリを必要とする。これは、GPU のような特殊なハードウェアなしでは実装が困難です。
2.過剰適合:十分なデータや適切な正則化技術が与えられなければ、CNNはオーバーフィットする可能性がある。つまり、CNNは訓練データに対してはうまく機能するが、新しい未知のデータに対しては汎化することができない。
3.データ要件:CNNは訓練に大量のラベル付きデータを必要とする。ラベル付きデータが乏しかったり、入手にコストがかかったりするドメインでは、これは大きな制限となり得る。
4.解釈可能性:CNNが何を学習したかを解釈するのは難しい。ディープラーニング・モデルの "ブラックボックス "的性質は、予測の背後にある理由を理解することを困難にし、これは繊細なアプリケーションでは問題となりうる。
これらの長所と短所を理解することは、特定のタスクにCNNを使用するかどうかを決定する際や、CNNベースのソリューションを設計・実装する際に非常に重要である。
CNNにおける一般的な正則化テクニック
デメリットで述べたように、CNNは特に限られたデータを扱うときにオーバーフィッティングを起こしやすい。正則化テクニックは、CNNが訓練データにオーバーフィットするのを防ぐために使われ、それによってモデルは未知のデータに対してより良く汎化することができる。以下はCNNで使われる一般的な正則化テクニックである:
1.ドロップアウト:このテクニックは、学習中にレイヤーの出力特徴をランダムに「ドロップアウト」(ゼロに設定)する。ドロップアウトはネットワークに、どのニューロンにも依存しない、よりロバストな特徴を学習させる。こうすることで、ネットワークはニューロンの特定の重みに影響されにくくなり、結果的に汎化が向上する。テスト時にはすべてのニューロンが使用されるが、トレーニング時に欠落したニューロンを補うため、その出力はスケールダウンされる。
2.L1正則化:ラッソ正則化としても知られるL1正則化は、重みの絶対値に比例するペナルティ項を損失関数に追加します。このテクニックは、いくつかの重みをゼロにすることで、モデルのスパース性を促進します。L1正則化は、あまり重要でない特徴を削除して、よりシンプルなモデルを作成したい場合に有効です。
3.L2正則化:リッジ正則化としても知られるL2正則化は、重みの2乗に比例するペナルティ項を損失関数に加えます。この手法は大きな重みを抑制し、重み値をより均等に分散させます。L2正則化はL1のような疎なモデルにはなりませんが、関連性の低い特徴の影響を減らすのに役立ちます。
L1もL2も重みの数を減らし、ネットワークをより効率的にすることができる。L1とL2(またはElastic Net正則化として知られる両方の組み合わせ)の選択は、問題とデータセットに依存します。
これらの正則化テクニックは、適切に使用されれば、現在ディープラーニングや機械学習における最大の問題の1つを解決する。
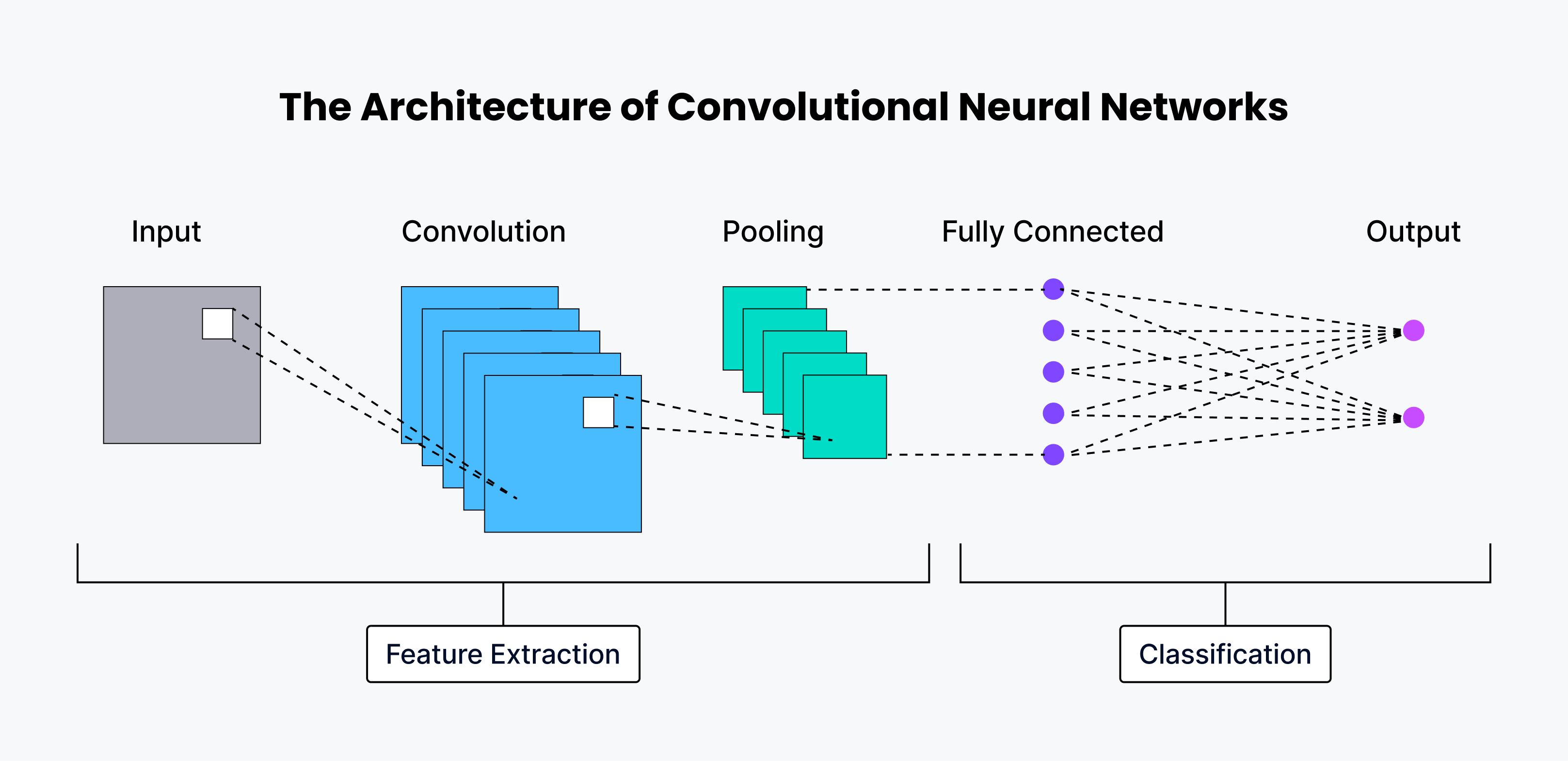
CNN アーキテクチャとその仕組み
CNNには優れた能力があり、そのためこれらのネットワークは、隠れたパターンを発見し、卓越した精度で視覚データを解読する力を与えてくれる。
人間の神経系にはいくつかの層があり、それぞれが固有の機能を果たす。CNNも同様のアーキテクチャを持ち、各層は入力画像から異なる特徴を抽出する。以下は、CNNアーキテクチャに関わるすべての層の詳細な説明である。
最初の数層は畳み込み層で、エッジや形状といった画像の基本的な特徴を抽出する。
次の数層はプーリング層で、特徴マップのサイズを縮小する出力層である。
最後の層は完全連結(FC)層で、画像を与えられたカテゴリの1つに分類する役割を担う。
ほぼすべての最新の純粋な畳み込みアーキテクチャは、最後に1つのグローバルプーリング層があり、その後に1つの完全接続層がある。
コンボリューション層
畳み込み層はCNNの中核であり、入力データから特徴的なパターンを見つけるように設計されている。入力画像を受け取り、フィルタのセットを適用して、特徴マップと呼ばれる出力を生成する。フィルタは重みの小さな行列で、異なるパターンを識別するために入力画像を走査する。フィルターが画像上を移動するとき、ストライド(各ステップでフィルターが移動するピクセル数)で定義されたステップで移動する。時には、入力の周囲に余分なピクセルを追加して出力サイズを制御するためにパディングが使われます。パディングには、有効パディング、ゼロパディング(パディングなし)、同一パディング(出力サイズが入力サイズと等しい)、フルパディング(出力サイズが大きくなる)などの種類があります。畳み込み演算の後、モデルに非線形性を導入するために、非線形活性化関数、典型的にはReLU(Rectified Linear Unit)が適用される。
その他の畳み込み層
先に述べたように、最初の畳み込み層の後に別の畳み込み層が来ることがある。これが起こると、後の層は前の層の受容野内のピクセルを見ることができ るので、CNNは階層的になる。この階層構造により、ネットワーク内の隠れた層は、データが層を流れるにつれて、より複雑な特徴を学習することができる。
例えば、画像中の人間の顔を認識したいとしよう。顔はさまざまな特徴の組み合わせだと考えることができる。目、鼻、口、眉毛などだ。顔の個々の特徴はニューラル・ネットの下位レベルのパターンであり、これらの特徴の組み合わせは上位レベルのパターン、CNNの視覚野における特徴階層である。
最初の畳み込み層では、ネットワークはエッジ、曲線、基本的な形状のような単純な特徴を検出することを学習するかもしれない。これらは顔の特徴の輪郭であったり、顔の異なる部分間のコントラストであったりする。
第2層の画像分類では、これらの基本的な特徴を組み合わせて、より複雑な形状を認識する。例えば、円形(おそらく目)や曲線(おそらく口や眉の輪郭)を検出するかもしれない。
続く層では、ネットワークは前の層からのパターンを組み合わせることで、顔全体の特徴を認識し始めるかもしれない。あるニューロンは目のような構造を検出したときに発火し、別のニューロンは鼻のようなパターンを検出したときに発火するかもしれない。
最後の層では、CNNはこれらすべての顔の特徴を組み合わせて、完全な顔を認識する。この段階では、ネットワークは個々の特徴を検出するだけでなく、これらの特徴が顔の文脈の中で互いにどのように関連しているかを理解している。
最後に畳み込み層が画像を数値に変換し、ニューラルネットワークが入力画像を解釈し、さまざまな抽象度でパターンを抽出できるようにする。この階層的特徴学習は、画像認識タスクにおけるCNNの重要な強みの1つで、顔のような複雑な多成分オブジェクトを理解することができる。
プーリング層
畳み込み層に続いて、我々はしばしばプーリング層を見つける。このプーリング層の目的は、最も重要な特徴を保存しながら、特徴マップのサイ ズを小さくすることである。これは計算の複雑さを軽減し、オーバーフィッティングを抑制するのに役立つ。特徴マップの小さな領域から最大値を取る最大プーリングと、小さな領域から平均値を取る平均プーリングである。
完全連結(FC)層**。
CNNの最終層は、通常、CNNの出力を分類する完全接続層である。この層は伝統的なニューラル・ネットワークの層と似ており、前の層のすべてのニュー ロンに接続する。この層は、畳み込み層によって学習された高レベルの特徴を使用して、最終的な分類または回帰タスクを実行する。
 The-Architecture-of-Convolutional-Neural-Networks.png
The-Architecture-of-Convolutional-Neural-Networks.png
必須用語**
CNNを扱うとき、いくつかの重要な用語を理解することが重要である。エポック(epoch)とは、訓練データセット全体を1回完全に通過することである。ドロップアウト(Dropout)とは、学習プロセス中にニューロンをランダムに削除することで、オーバーフィッティングを防ぐ手法である。ストキャスティック・デプス(Stochastic Depth)は、残差ブロックをランダムに削除することで、学習中のネットワークを短縮するもう1つの手法である。
ストライド-これは畳み込み演算中にフィルターが取るステップサイズとして知られている。
パディング(Padding)-CNNにおけるパディングとは、畳み込み後に画像の空間次元を保持するために、画像の境界の周りにゼロを追加することである。これは画像の縮小を防ぎ、各畳み込み演算後の情報の損失を防ぐために行われる。
エポック(Epoch)*-訓練データセット全体を1回完全に通過すること。
ドロップアウト(正則化)-学習中にニューロンをランダムに削除することで、オーバーフィッティングを防ぐ手法。
ストキャスティック・デプス(Stochastic Depth)-学習時に、残差ブロックをランダムに削除し、スキップ接続によってそれらの変換をバイパスすることで、ネットワークを短縮する。一方、テスト時には、ネットワーク全体を使って予測を行う。その結果、テスト誤差が改善され、学習時間が大幅に短縮される。
畳み込みニューラルネットワークの種類
畳み込みニューラルネットワークの歴史と発展は数十年前に遡り、多くの研究者が貢献してきた。この歴史を理解することで、CNNの現状を理解することができる。
歴史的基礎
福島邦彦は1980年に「ネオコグニトロン」という階層的多層人工ニューラルネットワークの研究でCNNの基礎を築いた。この初期のモデルは、ロバストな視覚パターン認識を学習することができた。
ヤン・ルクンは1989年に「Backpropagation Applied to Handwritten Zip Code Recognition(バックプロパゲーション(https://zilliz.com/glossary/backpropagation)の手書き郵便番号認識への応用)」という論文でもう一つ重要な貢献をした。ルクンは、手書きの郵便番号のパターンを認識するためのニューラルネットワークの学習にバックプロパゲーションを適用した。これはニューラルネットワークの実用化への大きな一歩であった。
LeNet-5:オリジナルのCNNアーキテクチャ
LeCunと彼のチームは1990年代を通じて研究を続け、1998年にLeNet-5を完成させた。LeNet-5はそれ以前の研究の原理を文書認識に応用したものである。LeNet-5はCNNアーキテクチャの元祖であり、将来のすべての研究の基礎となった。
CNNアーキテクチャの進化
LeNet-5 以降、多くの CNN アーキテクチャが開発されてきた。MNISTやCIFAR-10のような新しいデータセットや、ImageNet Large Scale Visual Recognition Challenge (ILSVRC)のようなコンペティションが、この技術革新のほとんどを後押ししてきた。開発された注目すべきCNNアーキテクチャには、以下のようなものがある:
1.AlexNet:AlexNet:Alex Krizhevsky、Ilya Sutskever、Geoffrey Hintonによって開発され、ILSVRC 2012で優勝した。AlexNetはこれまでのCNNよりも深く、広く、ReLU活性化と正則化のためのドロップアウトを使用している。
2.VGGNet:オックスフォード大学のVisual Geometry Groupによって開発されたVGGNetは、そのシンプルさと深さで知られている。ネットワーク全体に小さな3x3の畳み込みフィルターを使用している。
3.GoogLeNet(Inception):Googleによって開発され、より効率的な計算と深いネットワークを可能にする "Inception "モジュールを導入した。
4.ResNet:Microsoft Researchによって開発されたResNetは、スキップ接続を導入し、より深いネットワーク(元の論文では152層まで)の学習を可能にした。
5.ZFNet:AlexNetを改良したZFNet(開発者のZeilerとFergusにちなんで命名)は、アーキテクチャのハイパーパラメータをチューニングすることで、ILSVRC 2013で優勝した。
これらの各アーキテクチャは、CNNで可能なことの限界を押し広げるイノベーションをもたらし、さまざまなコンピュータビジョンタスクの性能を向上させた。
コンボリューション・ニューラル・ネットワークの設計方法
CNNを設計する際には、いくつかの重要な決定事項がある。入力サイズの選択、畳み込み層の数の決定、入力層ごとのフィルタのサイズと数 の選択、プーリング法の選択、完全接続層の数の決定、活性化関数の選択などである。これらの選択はそれぞれ、ネットワークの性能と効率に大きな影響を与える。
1.入力サイズの選択-入力サイズは、CNNの学習対象となる画像のサイズを表す。入力サイズは、ネットワークが分類を目的とするオブジェクトの特徴を抽出できるように、十分に大きくする必要があります。
2.**畳み込み層の数を選択する。畳み込み層の数を増やすと、より複雑な特徴を学習できるようになるが、計算時間が長くなる。
3.フィルタのサイズを選択する*-フィルタのサイズは、畳み込みのストライドとともに、画像から抽出される特徴のサイズを決定する。フィルタの次元が大きいほど、より多くの特徴を抽出することができます。
4.**レイヤーあたりのフィルター数を選択します。
5.プーリング手法の選択*-2つの一般的なプーリング手法は、最大プーリングと平均プーリングです。最大プーリングは特徴マップの小さな領域から最大値を取り出し、平均プーリングは特徴マップの小さな領域から平均値を取り出します。
6.**これは、ネットワークが分類できるクラスの数を決定する。
7.活性化関数の選択*-活性化関数は、画像データセットからより複雑なパターンの学習を可能にする。バイナリ分類では、シグモイド関数を使うのが普通です。多クラス分類の問題文では、FC層はソフトマックス活性化関数を使う。データに非線形性を導入するために、最近ではGeLUやSwish 活性化関数を使うことが多い。
以下は、交通標識を分類するPythonによるCNN実装の簡単な例である。データセットはKaggleのウェブサイトで。
PyTorchを使った簡単なCNNの実装 ## **PyTorchを使った簡単なCNNの実装
PythonでCNNモデルを実装するには、PyTorch、TensorFlow、Kerasなどのフレームワークを使う。これらのフレームワークはCNNに必要な全ての層の実装を提供する。
プロセスは以下のように必要なモジュールをインポートすることから始まる:
# 計算のための依存関係
import pandas as pd
np として numpy をインポート
# 画像を読み込んで表示するための依存関係
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
matplotlib インライン
# 検証セットを作成するための依存関係
from sklearn.model_selection import train_test_split
# モデルを評価するための依存関係
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# PyTorch のライブラリとモジュール
インポートトーチ
from torch.autograd import 変数
from torch.nn import (Linear, ReLU, CrossEntropyLoss、
Sequential, Conv2d, MaxPool2d, Module、
Softmax, BatchNorm2d, Dropout)
from torch.optim import Adam, SGD
これが完了したら、以下のコードでデータセットと画像を読み込みます:
# データセットの読み込み
train = pd.read_csv('Data/train.csv')
# 学習用画像の読み込み
train_img = [].
for img_name in tqdm(train['Path']):
# 画像パスの定義
image_path = 'Data/' + str(img_name)
# 画像を読み込む
img = imread(image_path, as_gray=True)
# 画像のリサイズ
img = resize(img, (28, 28))
# ピクセル値を正規化する
img /= 255.0
# ピクセルのタイプをfloat 32に変換する
img = img.astype('float32')
# 画像をリストに追加
train_img.append(img)
# リストをnumpy配列に変換
train_x = np.array(train_img)
# ターゲットの定義
train_y = train['ClassId'].values
train_x.shape
学習データがロードされたら、sklearnのtrain_test_split()メソッドを使用して学習データと検証データセットを作成する必要があります。
# 検証セットを作成する
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# トレーニングセットと検証セットの形状をチェックする
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
また、以下のようにTorchモデルのデータをリシェイプする必要がある:
# トレーニング画像をTorch形式に変換
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# ターゲットをトーチ形式に変換
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# 検証画像をトーチ形式に変換する
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# ターゲットをトーチフォーマットに変換
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
次に、CNNの異なるレイヤーを以下のように定義する:
クラス Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 2D畳み込みレイヤーを定義
Conv2d(1, 4, kernel_size=3, stride=1, padding=1)、
BatchNorm2d(4)、
ReLU(inplace=True)、
MaxPool2d(kernel_size=2, stride=2)、
# もう1つの2D畳み込み層の定義
Conv2d(4, 4, kernel_size=3, stride=1, padding=1)、
BatchNorm2d(4)、
ReLU(inplace=True)、
MaxPool2d(kernel_size=2, stride=2)、
)
# 予測用の最後の密な層
self.linear_layers = シーケンシャル(
線形(4 * 7 * 7, 43)
)
# フォワードパスの定義
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
x を返す
上のCNNネットワークは2つの畳み込み層と、それに続く2×2の空間次元を持つ最大プーリング層を持つ。
平坦化層は標識の画像の隠れた層をそれぞれのクラスに分類するのに役立つ。
次に、オプティマイザと損失関数を決定し、学習手順を定義しよう。
# モデルの定義
model = Net()
# オプティマイザの定義
オプティマイザ = Adam(model.parameters(), lr=0.07)
# 損失関数の定義
criterion = CrossEntropyLoss()
# GPUが利用可能かチェックする
if torch.cuda.is_available():
model = model.cuda()
基準 = 基準.cuda()
print(model)
def train(epoch):
model.train()
tr_loss = 0
# 学習セットの取得
x_train, y_train = Variable(train_x), Variable(train_y)
# 検証セットの取得
x_val, y_val = Variable(val_x), Variable(val_y)
# データをGPUフォーマットに変換
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# モデルパラメータの勾配をクリア
オプティマイザー.zero_grad()
# 訓練セットと検証セットの予測
output_train = model(x_train)
output_val = model(x_val)
# 訓練と検証の損失を計算する
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# バックプロパゲーションとモデルパラメータの更新
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# 検証損失を表示する
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
最後に、学習データに対して以下のように25エポック学習させます:
# エポック数の定義
n_epochs = 25
# 訓練損失を格納する空のリスト
train_losses = [] # 検証損失を格納する空のリスト
# 検証損失を格納する空のリスト
val_losses = [] # 検証損失を格納する空のリスト
# モデルのトレーニング
for epoch in range(n_epochs):
train(epoch)
最終的に、各モデルはテストデータに対して予測を行うことになる。詳しくはこちらのブログのHow to write CNNs from Scratch in PyTorchを参照してください。
FAQs
CNNとDeep Neural Networksの違いは何ですか?
CNNは画像、音声、動画などの視覚データを処理できるニューラルネットワークの一種であり、ディープニューラルネットワーク(DNN)はデータから複雑なパターンを学習できる人工ニューラルネットワークの一種です。
以下はCNNとDNNの主な違いである。
CNNは画像処理に特化したアーキテクチャを持つ。一方、DNNは特定のアーキテクチャを持たず、様々なタスクに対応できる。
CNNは畳み込み層を使って画像から特徴を学習するが、DNNは異なる層の種類の助けを借りて特徴を学習する。
CNNはDNNに比べて学習が難しく、より多くのデータを必要とし、計算コストが高い。
CNNの3つの層とは?
CNNの3つの層とは、活性化層、畳み込み層、プーリング層、完全接続層である。
この層は画像から特徴を抽出する。重みの小さな行列であるフィルターで画像をスキャンすることで機能する。フィルターは画像を横切って移動し、重みは画像内のピクセルの値と掛け合わされる。最後に、抽出された特徴を含む特徴マップを作成する。
プーリング層**-プーリング層は特徴マップのサイズを縮小します。これを行うために、2つの一般的なプーリング技術は、最大プーリングと平均プーリングです。
完全接続層**-これは、CNNの出力を分類する従来のニューラルネットワークと同じです。完全連結層のニューロンは、画像を一連のクラスに分類する。
ディープラーニングにおける畳み込みニューラルネットワークとは?
畳み込みニューラルネットワークは、画像、スピーチ、動画を処理するディープニューラルネットワークの一種であり、成長するデジタル世界において、構造化/非構造化データの実世界予測を行うために使用することができます。
CNNは、人間の感情、行動、興味、好き嫌いなどを簡単かつ効率的に予測するのに役立ちます。