




機械学習における分類:知っておくべきことのすべて

機械学習における分類:知っておくべきことのすべて
分類とは何か?
分類は教師ありの機械学習アプローチで、データをあらかじめ定義されたクラスに分類する。入力が与えられると、分類モデルはその入力が属するカテゴリーやラベルを予測する。分類は機械学習における最も一般的なタスクの1つであり、電子メールのスパム検知から医療診断まで、実世界の多くのアプリケーションで使用されている。
例えば、電子メールのデータセットがある場合、分類モデルは各電子メールに "スパム "か "スパムでない "かのラベルを付けるように学習することができる。
分類はどのように機能するのか?
分類では、機械学習モデルがデータセット上で学習され、入力特徴に基づいた定義済みのクラスにデータを分類する。モデルはラベル付きデータセットを使って学習され、各入力は出力ラベルと関連付けられる。モデルは学習中にデータのパターンを学習し、それらのパターンを使って新しい未見のデータのラベルを予測する。
例えば、ある電子メールがスパムかどうかを分類するタスクがあるとする。学習段階において、モデルにはEメールとそのラベル(「スパム」か「スパムでない」か)が与えられます。特定のキーワードの有無や送信者のアドレスなどの特徴を分析し、パターンを特定する。モデルが訓練された後、同じ特徴を分析し、新しいメールが届いたときに「スパム」か「スパムでない」カテゴリーに属するかを予測する。
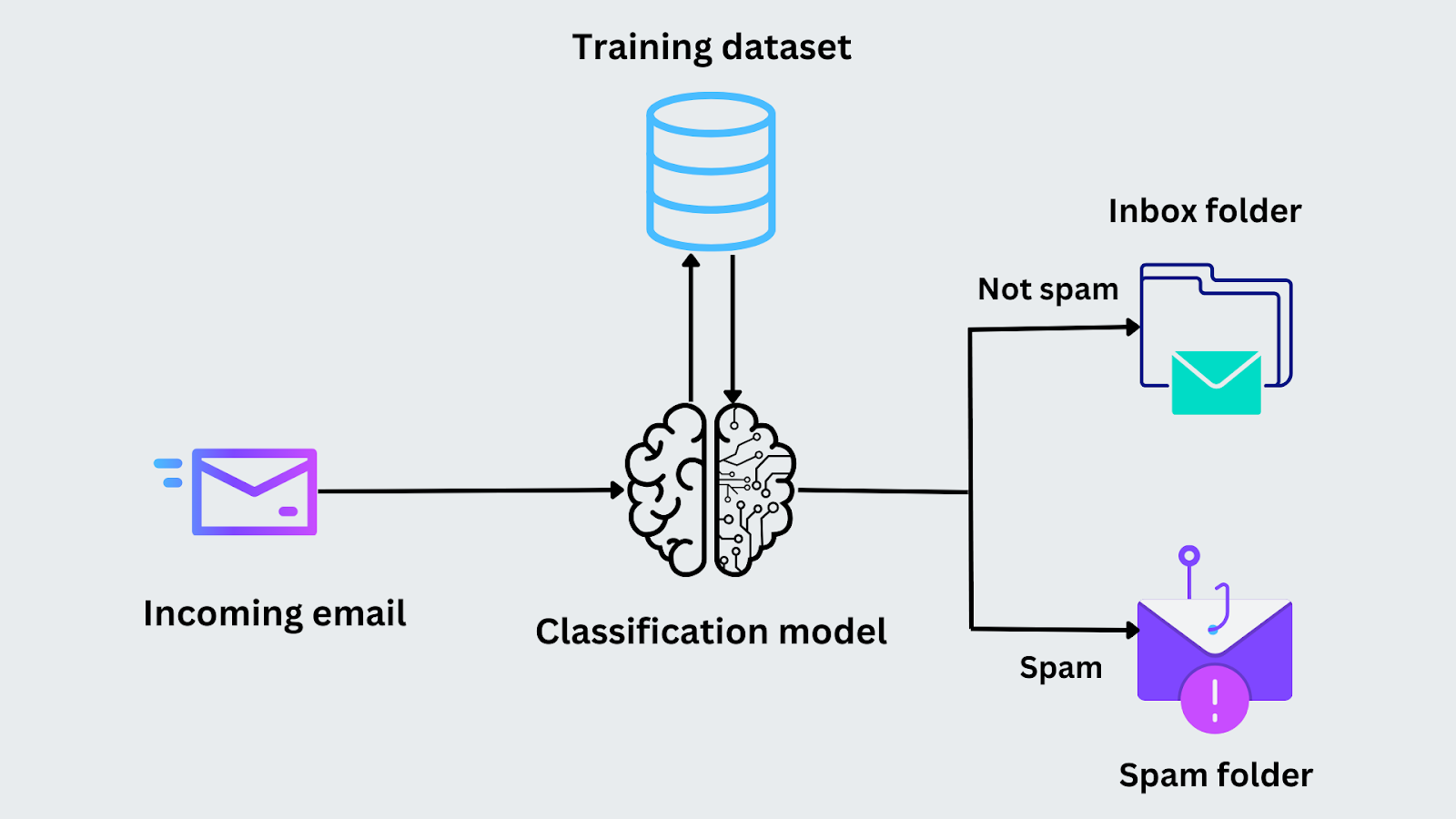 図- 電子メールの分類プロセス.png
図- 電子メールの分類プロセス.png
図:メール分類プロセス
分類の種類
分類の問題は、データの性質とクラスの数によって様々な形になります。以下は最も一般的なタイプである:
バイナリ分類
二値分類は、可能なクラスまたは結果が2つしかない場合です。モデルは入力が2つのカテゴリのどちらに属するかを予測する。典型的な例は、電子メールのスパム検出 です。モデルは受信メールが "スパム "か "スパムでないか "を判断しなければなりません。選択肢は2つだけなので、これはバイナリ分類タスクです。
多クラス分類
多クラス分類では、モデルは2つ以上の可能なカテゴリから1つのラベルを予測します。各入力は正確に1つのクラスに割り当てられる。良い例は画像認識で、モデルは画像を "猫"、"犬"、"鳥 "と分類するかもしれません。二値分類とは異なり、モデルは複数の異なるクラスを扱い、各入力に対して正しいものを識別しなければならない。
マルチラベル分類
マルチラベル分類は、各入力が同時に複数のクラスに属する可能性がある場合である。例えば、写真にタグを付けるとき、「夕日」、「ビーチ」、「人々」と同時にラベルを付けることができる。各タグは異なるクラスを表し、モデルは入力に関連するすべてのラベルを予測するように学習する。これは、同じ入力に複数のラベルを割り当てることができるため、多クラス分類とは異なる。
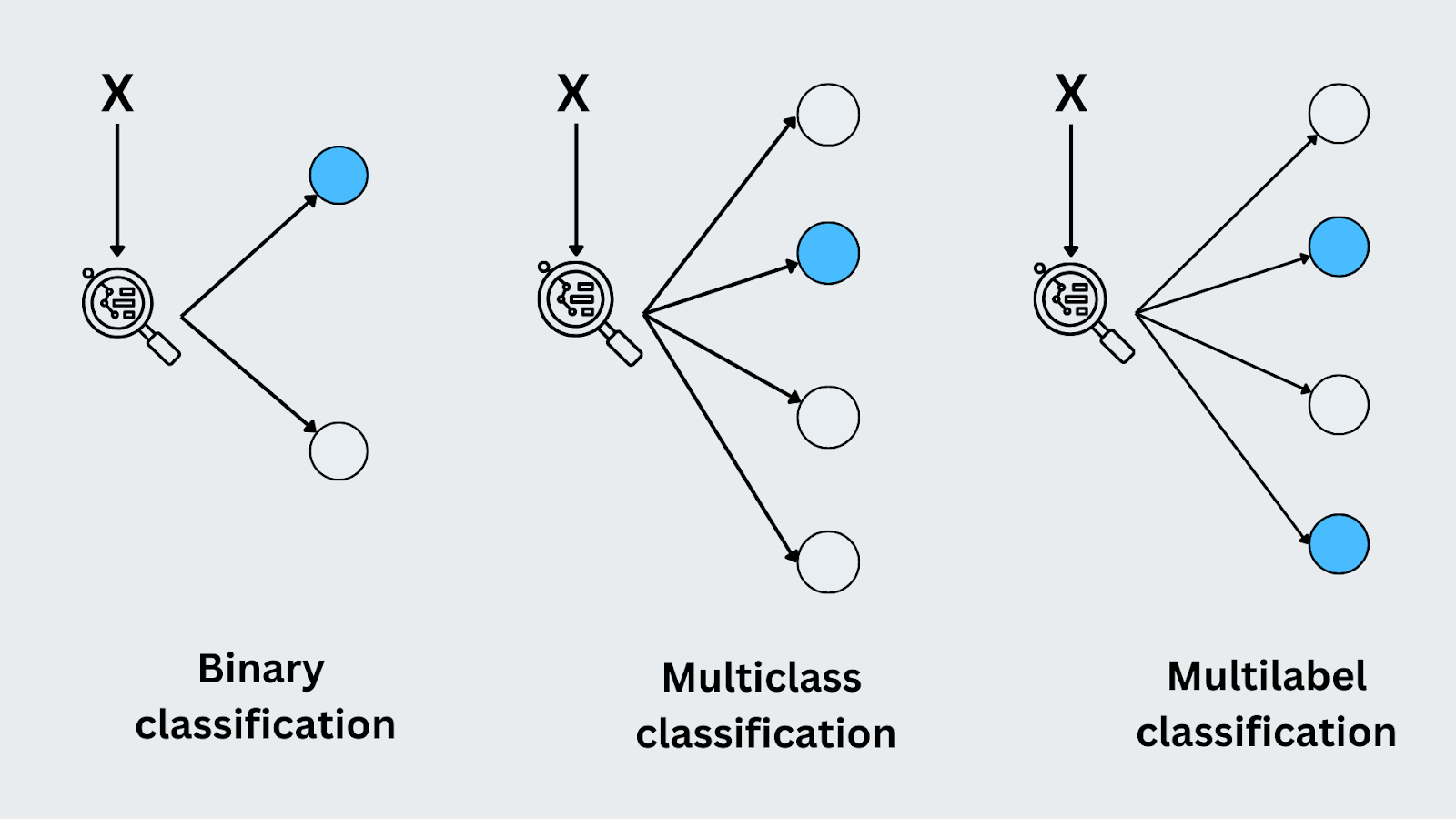 図-分類の種類.png
図-分類の種類.png
図:分類の種類
分類アルゴリズムにおける学習者
機械学習では、分類アルゴリズムは学習データからどのように汎化するかによって分類することができる。これらはレイジー・ラーナーとイージャー・ラーナーである。この2つのタイプの違いは、予測を行うためにデータをいつ、どのように処理するかにある。
レイジー・ラーナー
レイジー・ラーナーは、予測クエリーを受け取るまで汎化を遅らせるアルゴリズムである。学習段階ではモデルを構築せず、代わりに学習データを保存し、新しい入力を分類する必要があるときのみ計算を実行する。
アルゴリズムの例:k-Nearest Neighbors (k-NN)、Case-based Reasoning (CBR)。
熱心な学習者
これとは対照的に、熱心な学習者は訓練段階ですぐに一般的なモデルを構築しようとする。学習データを分析し、基礎となるパターンを学習し、そして学習データを破棄する。一旦モデルが構築されると、新しいデータを素早く予測することができる。
アルゴリズムの例:決定木、ランダムフォレスト、サポートベクターマシン(SVM)、ロジスティック回帰。
| モデル作成|モデルを作成しない。 | ||
| モデルの作成|トレーニング中にモデルは作成されず、データを記憶する。 | 学習中にデータをモデルに汎化する。 | |
| トレーニング時間|トレーニング時間が短い。 | トレーニング時間が長い。データに基づいてモデルを構築する。 | |
| 予測時間|クエリ時にデータを処理するため、予測は遅くなる。 | 予測時間|モデルが事前に構築されているため、より速い予測が可能。 | |
| メモリ要件|データセット全体を保存するため、メモリ要件が高い。 | モデル・パラメータのみを保存。 | |
| アルゴリズム例|k-NN、事例ベース推論、決定木、ロジスティック回帰、ランダムフォレスト |
表:怠惰な学習者と熱心な学習者の比較
分類アルゴリズム
では、よく使われる分類アルゴリズムについて説明しよう。
ロジスティック回帰
ロジスティック回帰は,バイナリ分類タスクでラベルを予測するために確率だけを使う.連続値を予測する線形回帰とは異なり、ロジスティック回帰は、ロジスティック関数(sigmoid)を使用して、出力を0と1の間の範囲にマッピングすることによって、2つのクラスの確率を予測します。これは、イエス/ノーや0/1のシナリオのようなバイナリ結果を持つケースに広く使われています。
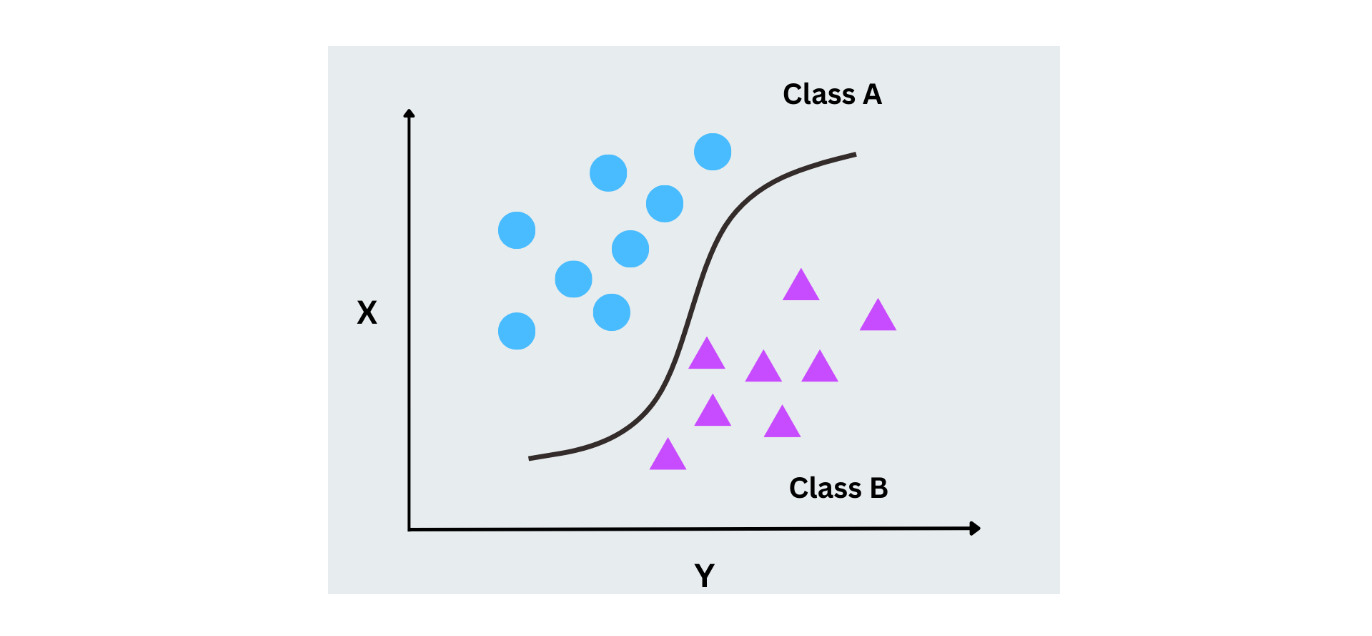 図- ロジスティック回帰の作業.png
図- ロジスティック回帰の作業.png
図- ロジスティック回帰の作業
決定木
決定木は、特徴値に基づいてデータを分割し、可能な決定ごとに枝を作成するモデルである。各ノードは特徴を表し、枝はその特徴の値に基づく決定を表す。このプロセスは、アルゴリズムが予測クラスのリーフ・ノードを決定するまで続きます。決定木は解釈が簡単で、バイナリおよびマルチクラス分類タスクを処理できます。
図- 決定木の構造.png](https://assets.zilliz.com/Figure_Decision_tree_structure_09ec70a8f3.png)
図:決定木の構造
ランダムフォレスト
ランダムフォレストは、複数の木を構築し、それらの予測を組み合わせることで、決定木を改良したものである。フォレスト内の各ツリーは、データと特徴のランダムなサブセットから構築される。最終的な予測は、結果の平均(回帰タスクの場合)または多数決(分類タスクの場合)によって行われる。これにより、オーバーフィッティングを減らし、精度を高めることができます。
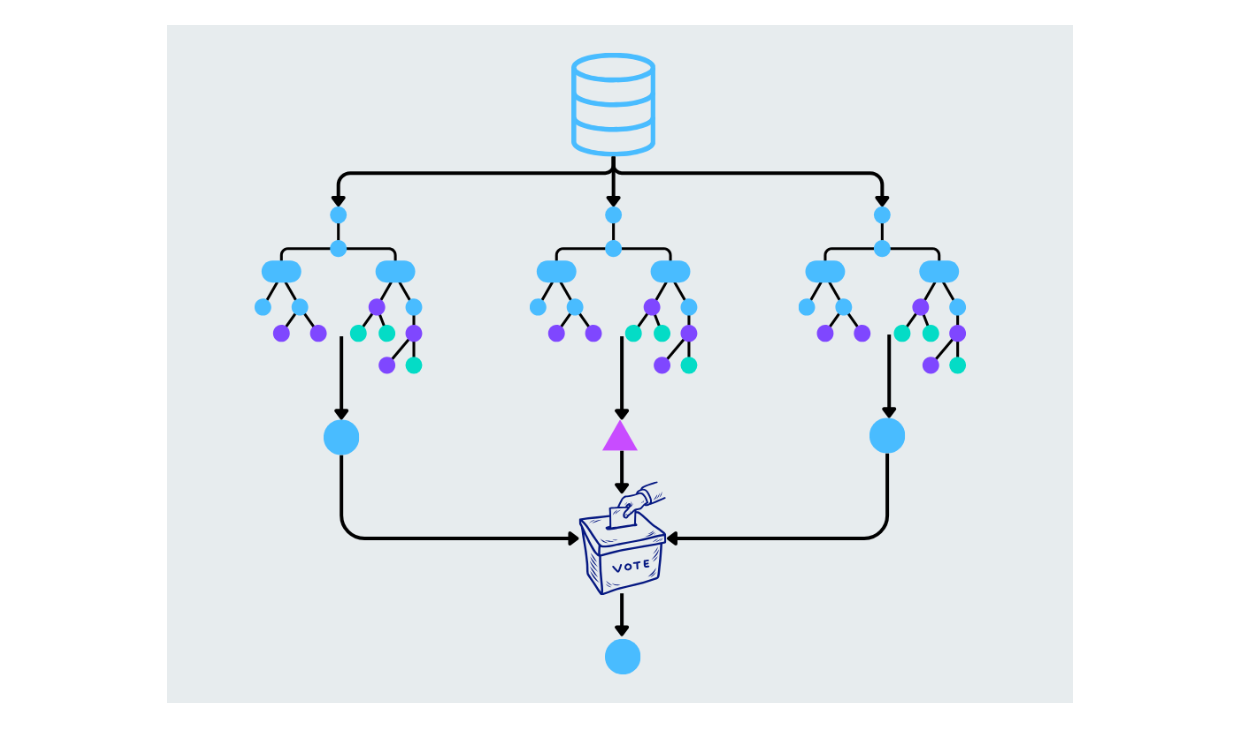{kind=link}
図:ランダムフォレストの作業
サポートベクターマシン(SVM)
サポート・ベクトル・マシンは、異なるクラスのデータ点を分離する最適な超平面を見つけることで機能する。この超平面は2次元の直線であるが、SVMは高次元のデータも扱うことができる。重要なアイデアは、各クラスに最も近いデータ点(サポート・ベクトル)間のマージンを最大化することである。SVMは、特にデータが線形分離可能でない場合に、2値分類問題や多クラス分類問題でうまく機能する。
図- SVMの動作.png](https://assets.zilliz.com/Figure_SVM_working_6267b2fe4a.png)
図- SVMの動作
k-最近傍探索(k-NN)
k-NNアルゴリズム](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)は、k個の最近傍のクラスに基づいてデータ点を分類する。新しいデータ点を導入するとき、アルゴリズムは(ユークリッド距離のような類似度メトリックに基づいて)最も近いk個の点を調べ、新しい点に多数派のクラスを割り当てます。これはシンプルなインスタンスベースの学習アルゴリズムで、小規模なデータセットに有用である。
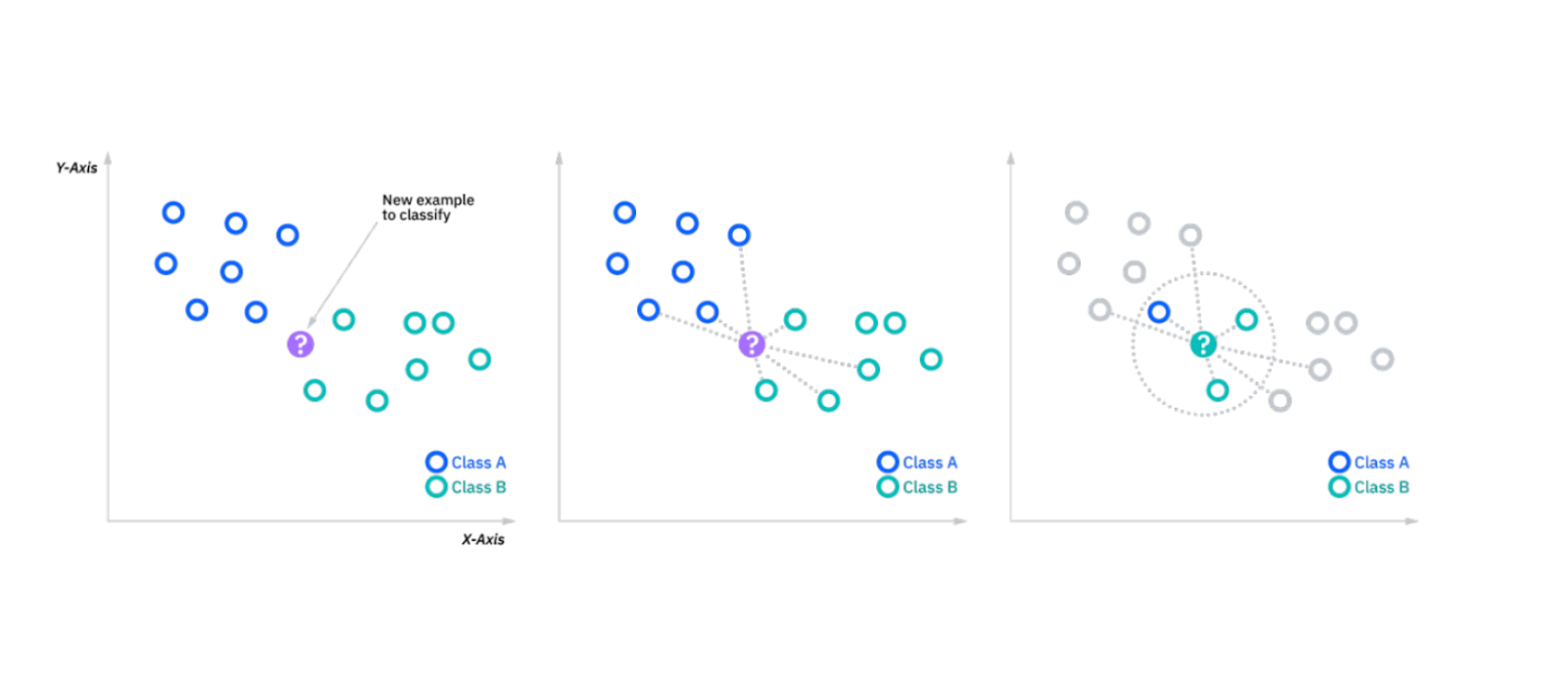 図- kNNアルゴリズムの動作.png
図- kNNアルゴリズムの動作.png
図: kNNアルゴリズムの動作
ナイーブ・ベイズ
ナイーブ・ベイズはベイズの定理に基づいており、データ中の特徴は互いに独立であると仮定している(それゆえ "ナイーブ "という言葉がある)。この仮定にもかかわらず、実世界の様々なタスク、特にデータにカテゴリー的特徴がある場合に優れた性能を発揮する。入力から各クラスの確率を計算し、最も確率の高いクラスを割り当てる。
P(C|X) = P(X|C) .P(C)P(X))
ここで、P(C∣X) は入力が与えられた場合のクラスの事後確率、P(X∣C) はクラスが与えられた場合の入力の尤度、P(C) はクラスの事前確率、P(X) は入力の確率。ナイーブベイズは、観測された特徴量に基づいて、事後確率が最も高いクラスを選択し、分類する。
図-ナイーブベイズアルゴリズムの動作.png](https://assets.zilliz.com/Figure_Naive_Bayes_algorithm_working_ea0a5ca81f.png)
図:ナイーブベイズアルゴリズムの動作
分類における評価指標
精度
精度は最も単純な評価指標で、モデルの予測がどれくらいの頻度で正しいかを測定する。これは、正しく予測されたケースの数をケースの総数で割ることによって決定される。
**式
精度 = (真陽性 + 真陰性)/インスタンス総数
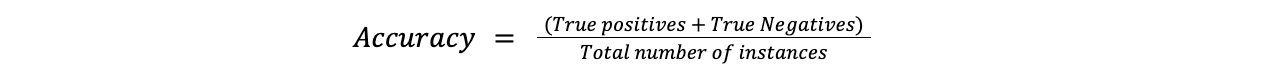{kind=link}
精度
精度は、予測された陽性のインスタンスのいくつが本当に陽性であるかを測定する。精度は、偽陽性が高くつく状況で重要である。例えば、不正検知において正常な取引を不正と予測することは、顧客の不満につながる可能性がある。
**計算式
精度 = 真陽性/(真陽性 + 偽陽性)
{kind=link}
リコール
Recallは、正確に陽性と識別された陽性ケースの比率を測定する。Recallは、陽性インスタンスを見逃すとコストがかかる場合に有用である。例えば、診断(偽陰性)を見逃すことは、病気検出では偽警報よりもはるかに問題である。
**式
Recall = 真陽性/(真陽性 + 偽陰性)
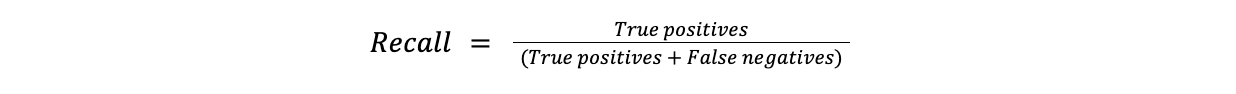{kind=link}
F1スコア
F1-Scoreはprecisionとrecallの調和平均である。精度と想起のバランスをとる必要がある場合、特に一方が他方より重要な場合に有用である。
**計算式
F1Score = 2x(Precision x Recall)/(Precision + Recall)
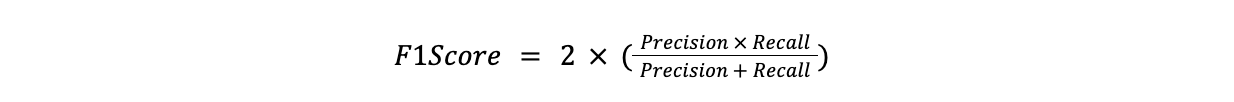 FIスコア.png
FIスコア.png
分類の実際の使用例
分類モデルは、実世界の問題を解決するために、さまざまな業界で広く使用されています。以下はその実例である:
1.医療診断:機械学習モデルは、医師が患者のデータを "病気 "か "病気ではない "かといったように分類するのに役立つ。例えば、医療記録に基づいて患者が糖尿病であるかどうかを予測するためにモデルが使用されます。
2.センチメント分析:* 企業は、顧客のフィードバックを理解するためにセンチメント分析を使用する。例えば、モデルは製品レビューを分析し、肯定的、否定的、または中立的に分類することができる。
3.**銀行や金融機関は、分類モデルを使用して不正取引を検出する。モデルは取引データからパターンを学習し、それぞれを「不正」か「正当」かに分類して、金銭的損失を防ぐ。
4.画像中の物体認識: 物体認識モデルは、製造業やセキュリティなどの業界において、特定の画像アイテムを識別する。例えば、モデルは組立ライン上の製品の写真を分類し、正しく組み立てられたものだけが検査を通過するようにすることができる。
5.顔認識:* 顔認識システムは、セキュリティや認証に使用される。これらのモデルは、スマートフォンのロック解除、デジタル出席システム、または空港のセキュリティ・チェックで一般的に使用されている、人物の身元を識別または確認するために顔の画像を分類します。
6.**音声認識:音声認識モデルは、話し言葉をテキストやコマンドに変換する。例えば、SiriやAlexaのようなバーチャル・アシスタントは、話し言葉をコマンドに分類し、ユーザーが音声を通じてデバイスと対話できるようにします。
7.**機械学習モデルは、X線やMRIスキャンなどの診断テストの解釈を支援する。機械学習モデルは、医療画像を「正常」か「異常」かに分類し、放射線科医がより迅速で正確な診断を下すのを助ける。
8.**Eコマース・プラットフォームは、分類モデルを使って顧客の行動を予測する。これらのモデルは、ユーザーを「買いそう」「買わなさそう」に分類し、パーソナライズされたマーケティングや製品推奨を行う。
9.**商品分類: ** 小売業者は機械学習を使って、「電子機器」、「衣料品」、「家庭用品」などの商品を説明文に基づいて自動的に分類する。これにより、在庫管理が合理化され、顧客の検索体験が向上する。
10.**マルウェアの分類: **サイバーセキュリティにおいて、分類モデルはマルウェアを検出・分類する。このモデルは、ソフトウェアの動作パターンを分析することで、プログラムを「安全なもの」と「悪意のあるもの」に分類し、サイバー脅威からシステムを保護します。
分類における共通の課題
分類モデルを構築する際、モデルの性能に影響を与えるいくつかの課題が発生する可能性がある。ここでは3つのよくある課題を紹介します:
オーバーフィット
オーバーフィッティングとは、モデルが訓練データではうまく機能するが、新しい未知のデータに対して汎化できないことを意味する。これは、モデルが複雑になりすぎて、基本的なパターンではなく、ノイズや訓練セットの特定の詳細を捕捉し始めると起こります。
データの不均衡
データの不均衡とは、あるクラスが他のクラスを著しく上回っている状態のことである。例えば、不正検出では、不正なトランザクションはデータの 1%に過ぎず、モデルは多数派クラスに大きく偏る可能性がある。その結果、少数派のクラスの検出が不十分になることがあります。
データのノイズ
ノイズとは、モデルを混乱させるデータ内のランダムなエラーや無関係な情報のことです。ノイズの多いデータには、誤ったラベル付けをした例、外れ値、分類タスクに寄与しない無関係な特徴などがあります。ノイズが存在すると、モデルの性能が低下し、パターンの検出が難しくなります。
分類と回帰の比較
分類と回帰 はどちらも教師あり学習アルゴリズムの一種であるが、異なる種類のタスクに使われる。以下は、さまざまな側面に基づく分類と回帰の比較である:
| 側面** | 分類 | 回帰 | 目的 |
| 目的|離散的なラベルやカテゴリーを予測する。 | 連続的な数値を予測する。 | ||
| 出力|カテゴリー:"spam "や "not spam "のようなクラス。 | 連続:"価格 "や "温度 "のような値。 | ||
| タスク例|メールを "spam "か "not spam "に分類する。 | 特徴量から住宅価格を予測する。 | ||
| 使用アルゴリズム|ロジスティック回帰、決定木、ランダムフォレストなど。 | 線形回帰、リッジ回帰、多項式回帰など。 | ||
| 評価指標|精度、プレシジョン、リコール、F1スコア、ROC-AUCなど。 | 平均二乗誤差(MSE)、R二乗、平均絶対誤差(MAE)など。 | ||
| 対象変数の性質|対象がカテゴリ型(クラス・ラベルなど)。 | 対象が連続的(例:実数)。 | ||
| 出力の境界|固定のクラス境界を持つ(例:バイナリの場合は0か1)。 | 出力は実数の範囲。 | ||
| 実際の使用例|スパム検出、詐欺検出、病気の分類。 | 売上予測、株価予測、天気予報。 | ||
| バイナリ出力もマルチクラス出力も扱える。 | 通常、1つの連続値を予測する場合はよりシンプル。 |
表分類 vs 回帰
分類タスクでMilvusはどのように役立つか?
データの量と複雑さが増すにつれて、大規模なデータセットを管理し照会する従来の方法は、時間がかかり非効率的になる可能性があります。そこで、高性能でオープンソースのベクトルデータベースMilvusを持つZillizが重要な役割を果たします。
画像認識](https://zilliz.com/vector-database-use-cases/image-similarity-search)、物体検出、動画類似検索、スパム検出、推薦システムなどの分類タスクは、テキスト埋め込み、画像特徴、音声ベクトルのような非構造化データの高次元表現を扱う必要があることが多い。Milvusは、このような大量のベクトルデータを効率的に管理・検索するために特別に設計されています。
分類におけるMilvusの利点
1.高次元データの処理:分類では、モデルはしばしばベクトル化されたデータ(例えば、単語の埋め込みや画像の特徴ベクトル)に依存して予測を行います。Milvusはこれらのベクトルを保存・管理するために最適化されており、モデルの学習や推論時に大規模なデータセットに素早くアクセスすることができます。
2.高速類似度検索:分類モデルは、データセット内の最も近いデータ点を見つける必要が頻繁にあります。Milvusは、ベクトルデータに対して高速な類似性検索を実行することで、このプロセスを高速化し、最も近い近傍データに基づいて新しい入力を簡単に分類できるようにします。
3.大規模データセットに対するスケーラビリティ:Milvusは、分類データセットが大きくなっても、高速で効率的なパフォーマンスを維持します。Milvusは、数百万の製品ベクトル、画像埋め込み、数千の画像埋め込みなど、膨大な量のデータであっても、分類タスクをスムーズに実行できるようにシームレスに拡張します。
結論
分類は、不正行為の検出から画像の認識まで、様々な実世界のアプリケーションにおいて、データのラベルやカテゴリを予測するための機械学習技術である。分類モデルの構築と展開を成功させるには、大量のデータ(多くの場合、高次元ベクトル)を扱う必要があります。Milvusはベクトルデータに対して効率的なストレージ、高速検索、スケーラビリティを提供します。Milvusは、迅速な類似性検索により分類タスクのパフォーマンスを向上させ、データセットが増大してもスムーズに拡張することができます。Milvusを使用することで、開発者は大規模な分類タスクの課題に容易に対処することができ、機械学習における強力なツールとなります。
##分類に関するFAQ
- 機械学習における分類とは何ですか?
機械学習における分類とは、与えられた入力に対して、その特徴に基づいてカテゴリやラベルを予測するプロセスのことです。モデルはラベル付けされたデータを使って学習され、パターンを学習し、新しい未見のデータを "スパム "や "スパムではない "といった事前に定義されたクラスに分類します。
- 分類アルゴリズムは回帰とどう違うのか?
回帰アルゴリズムが連続的な数値を予測するのに対して、分類アルゴリズムはカテゴリー的な出力(クラスやラベルなど)を予測します。例えば、分類は電子メールがスパムかどうかを決定することができ、一方、回帰は家の価格を予測するかもしれない。
- なぜ分類タスクではデータの準備が重要なのか?
データ準備では、入力データがきれいで構造化されており、モデルが処理する準備が整っていることを確認します。欠損値を処理し、データを正規化し、最も関連性の高い特徴を選択します。適切な準備により、モデルの精度と性能が向上します。
- Milvusは分類タスクをどのように支援しますか?
Milvus**はオープンソースのベクトルデータベースであり、画像やテキストの埋め込みなどの高次元データを効率的に格納・検索します。効率的な類似性検索によって分類を高速化し、画像認識や推薦システムのようなタスクにおける大規模なデータセットの取り扱いを容易にします。
- 分類における一般的な課題とその対処法とは?
よくある課題には、オーバーフィット、データの不均衡、データのノイズなどがあります。これらは、正則化、リサンプリング手法(例:SMOTE)、ノイズ除去戦略、大規模データセットを効率的に管理するためのMilvusのようなスケーラブルなインフラストラクチャのような技術を用いて対処することができます。
関連リソース
物体検出とは何か? 総合ガイド](https://zilliz.com/learn/what-is-object-detection)
機械学習におけるK-最近傍(KNN)アルゴリズムとは](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
近似最近傍探索(Annoy)](https://zilliz.com/learn/approximate-nearest-neighbor-oh-yeah-ANNOY)
ベクトル・データベースとは何か、その仕組みとは](https://zilliz.com/learn/what-is-vector-database)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
コンピュータビジョンを理解する ](https://zilliz.com/learn/what-is-computer-vision)