




DeepSeek V3がAIの世界を席巻する理由:開発者の視点
現在、私たちが使用している大規模言語モデル(LLM)の最終目標のひとつは、人間ができるあらゆる知的タスクを理解し、実行できるようになることです。この概念は一般的に人工知能(AGI)と呼ばれている。AGIに向けた競争は、OpenAI、Meta、Google、Anthropic、Qwenなど、世界をリードするAI開発者による多くのLLMの急速な発展に火をつけた。
最近では、DeepSeekが開発した新しいLLMが、その性能と運用コストの組み合わせにより、AIコミュニティ内で大々的な宣伝を巻き起こしています。例えば、DeepSeek R1モデルは、OpenAIのこれまでで最も先進的な推論モデルであるo1モデルと同様の性能を、わずか数分の一の学習コストで実現できると主張されています。一方、DeepSeek V3モデルの性能はGPT-4oに匹敵し、トレーニングコストはわずかです。OpenAIとは異なり、DeepSeekはモデルを完全にオープンソース化することを決定し、AIコミュニティ全体がDeepSeekのモデルの重みにアクセスできるようにしました。これにより、AGIに向けたプロセスがさらに加速されるだろう。
この記事では、DeepSeekモデル、特にDeepSeek V3のいくつかの革新的な特徴について説明します。それでは早速、最初の重要な革新的機能を探っていきましょう。
特徴1:マルチヘッド潜在的注意
DeepSeek V3は、その中核において、古典的なTransformersアーキテクチャを採用している。膨大な数のTransformerブロックから構成され、各ブロックには、以下の視覚化でわかるように、正規化、注意、フィードフォワード層といういくつかの重要な層が含まれている:
![]()
単一のTransformerブロックの視覚化。
このセクションでは、DeepSeek V3 モデルの Multi-head Latent Attention(MLA)が存在する場所であるため、注意層にのみ焦点を当てます。
一言で言えば、注意層は、特定の位置にあるトークンの 埋め込み 表現を入力として期待します。注意層の最初のステップは、学習された3つの重み行列を使用して、この入力埋め込みをクエリ、キー、および値のベクトルに投影することです。次に、この層はこれらの値を用いて、前のトークンに対するこの特定のトークンの文脈を推定する。
しかし、アテンション・メカニズムの計算方法には大きな欠点がある。すでにご存知かもしれないが、LLMは一度に1つのトークンを連続して生成し、新しいトークンは常に前に生成されたトークンに依存する。したがって、新しいトークンの文脈を推定するには、前のトークンの注目度を再計算する必要がある。例えば、トークン番号50を生成するには、トークン1から49までの注目度を毎回再計算する必要があります。その結果、推論中のトークン生成処理に非常に時間がかかる。
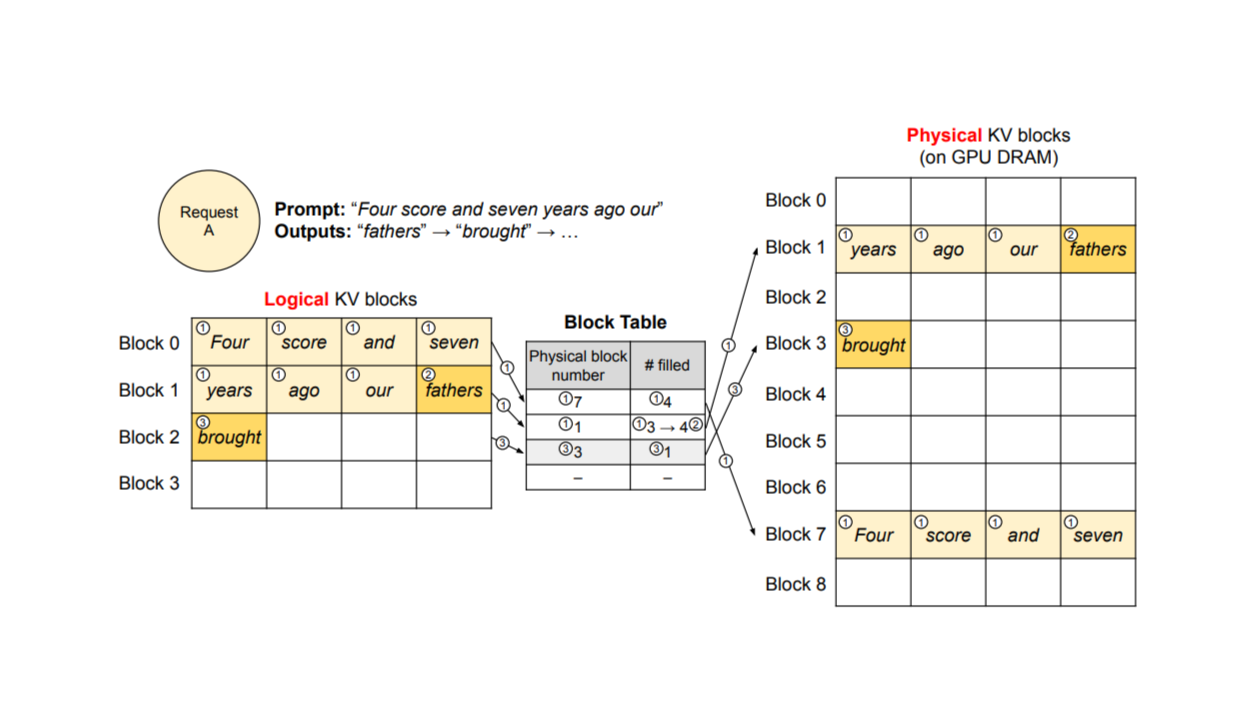
vLLMにおけるKVキャッシュ管理 ソース._.
この問題を解決するために、トークン生成プロセスを高速化するKVキャッシュと呼ばれるアプローチが通常LLMに実装されている。KVキャッシュでは、その名の通り、新しいトークンのキーと値は、各生成プロセス中にキャッシュに保存されます。したがって、新しいトークンの注目度計算では、すべてをゼロから再計算する代わりに、キャッシュされた以前のトークンのキーと値を使用します。これにより、トークン生成プロセスが効果的に高速化されます。
DeepSeek V3 は、アテンション層でも KV キャッシュを利用しています。実際、MLAの導入により、このアプローチはさらに進化した。要するに、MLAは冗長な要素を取り除くことで、入力埋め込み次元を低ランク表現に圧縮する。この圧縮の結果、キー、値、クエリーベクトルのサイズはさらに小さくなり、KVキャッシュ用のメモリを最適化し、トークン生成処理を高速化する。
![]()
単一のTransformerブロックにおけるDeepSeek V3のアーキテクチャ Source._.
上の図からわかるように、このアプローチでは、キーと値を一緒に低ランク表現に圧縮します。この圧縮されたバージョンのキーと値のベクトルは、通常のKVキャッシュと同様にキャッシュすることができる。
一方、クエリは独立して圧縮される。1つはレイヤーを直接投影して高次元表現に戻すもので、もう1つはRotary Positional Embedding (RoPE)と呼ばれる手法で処理される。RoPE法は、シーケンス中の新しいトークンの位置情報を導入するために重要である。これら2つのパイプラインの出力は、マルチヘッドアテンションレイヤーのための1つの最終入力に連結される。
結合圧縮されたキーバリューベクトルも、クエリーベクトルと同様の処理を受ける。ただし、キーベクトルのRoPEの入力は、圧縮されたキーバリューベクトルではなく、元の入力埋め込みから得られる。
特徴2:DeepSeek MoE
DeepSeek V3に実装されているもう一つの魅力的なアプローチは、Mixture of Experts (MoE)アプローチです。上の画像からわかるように、この手法は、DeepSeek V3 では、Transformers ブロックの元のフィード・ フォワード・ネットワークの代わりとして実装されています。
MoE が何をするのかを簡単に理解するために、例を使いましょう。私たちが大学で学んでいて、それぞれ異なる科目(数学、物理学、文学)の専門家である教授が大勢いるとします。微積分について何か聞きたいときは、数学の教授に案内される。同様に、量子物理学について質問したいときは、物理学の教授に案内される。
MoEも同じように機能する。MoEは多くのモデルで構成されており、それぞれが特定の問題を解決するための専門知識を持っている。
訓練段階では、各モデルが特定のドメインからさまざまなデータを取得し、そのドメインのタスクを解決するエキスパートになる。その後、推論中に、問題のすべてのドメインを処理する単一の巨大なモデルに依存する代わりに、MoEは最も有能な専門家モデルにクエリを割り当てる。このアプローチでは、タスクに応じて予測時に少数のエキスパートモデルのみが起動されるため、推論がより高速かつ効率的になる。
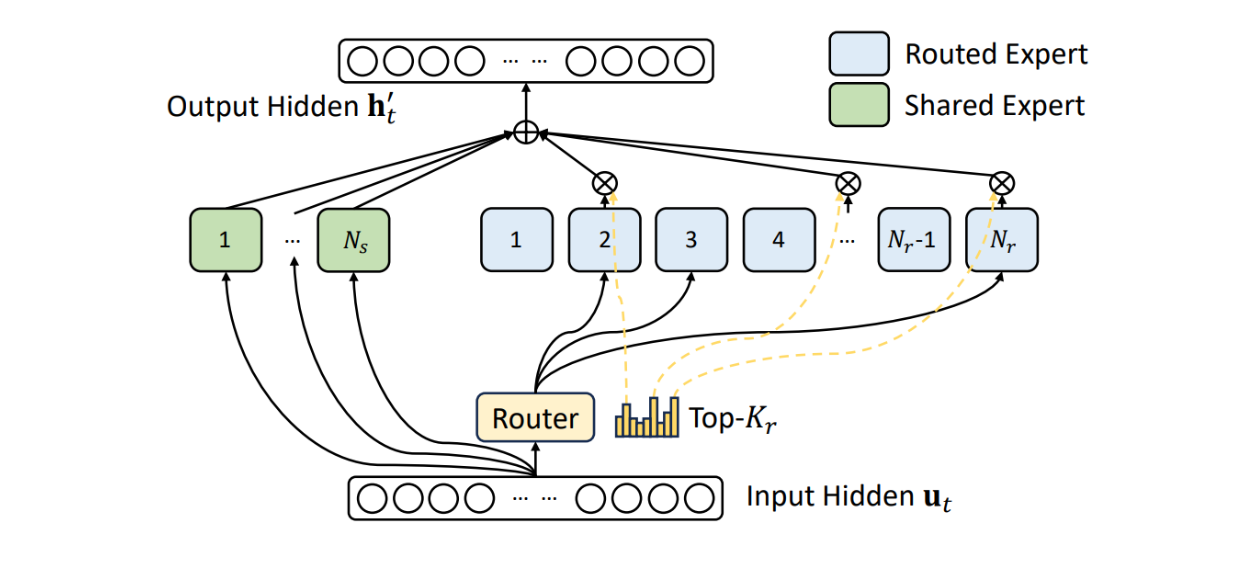
DeepSeek V3におけるMoE_ ソース..
MoEアプローチの重要な要素は、ゲーティング・ネットワークです。このネットワークには、入力クエリを分析し、それを最も適切なエキスパート・モデルにルーティングするという2つの主な役割があります。しかし、MoEのトレーニングに関する一般的な問題は、負荷分散の問題であり、ゲーティングネットワークは、すべてのトレーニングデータを他のモデルに分配する代わりに、1つの特定のモデルにルーティングし続けます。
補助損失を実装することで、ゲーティング・ネットワークに訓練データを異なるモデルに分配するよう学習させることができます。問題は、補助損失に頼るだけでは、トレーニング後のモデルのパフォーマンスが低下することが示されていることだ。
負荷分散とモデル性能のトレードオフを導入するために、DeepSeek V3 は補助ロスを使用しない負荷分散戦略を実装しました。この戦略は、対応するエキスパートのルーティング負荷に応じて動的に調整されるバイアス項を各エキスパートモデルに導入する。これにより、エキスパート・モデルの過負荷や過少利用が発生しないようになります。
また、上の可視化でわかるように、DeepSeek V3 は特定のエキスパートを「共有エキスパート」として設計しており、これらのエキスパートはさまざまなタスクに対して常にアクティブです。この実装は、タスクの異なるドメイン間でモデルを汎化する能力を向上させるのに役立ちます。
この MoE 機能が、DeepSeek V3 の汎用性を支える秘密のレシピです。次のセクションで説明するように、DeepSeek V3 は、数学、コーディング、言語など、ドメインの異なるさまざまなタスクで高い性能を発揮します。実際、このモデルは現在、いくつかのドメインで最も強力なオープンソースのベースモデルとなっています。
特徴 3:マルチトークンの予測
一般的な LLM は、各デコーディング・ステップで 1 つのトークンを予測しますが、DeepSeek V3 は、 特にトレーニング段階で異なる動作をします。DeepSeek V3 は、学習中にいわゆるマルチトークン予測(MTP)を実装し、各デコーディングス テップで複数の将来のトークンを予測できるようにします。
複雑なレイヤーが追加されますが、MTP アプローチは、さまざまなタスクにわたってモデルのパフォーマンスを向上させるために重要です。ご想像の通り、1つのデコードステップで数ステップ先の可能性のある未来のトークンを見ることで、モデルは任意のタスクに対して可能な限り最良のソリューションを学習することができます。
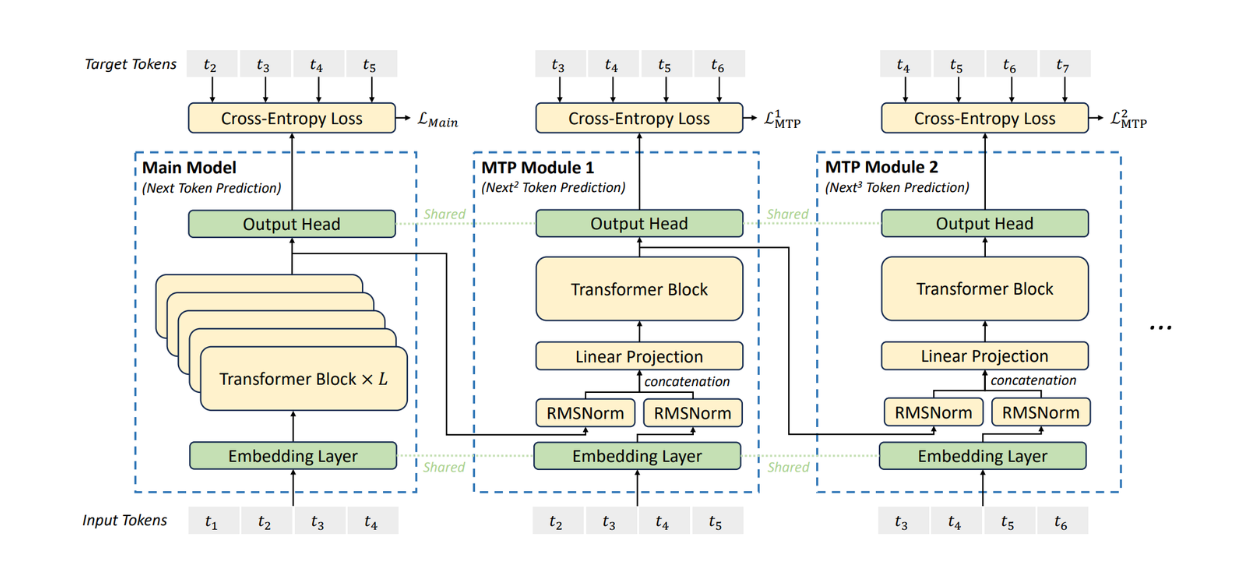
DeepSeek V3におけるMTPアプローチの視覚化 Source._.
MTPを実装するために、DeepSeek V3は複数のモデルを採用し、それぞれがTransformerレイヤーの束で構成されています。1 つのモデルがメイン・モデルとして機能し、他のモデルは MTP モジュールとして機能します。明確に定義されているわけではありませんが、MTPモデルのサイズはメインモデルに比べて一般的に小さくなります(HuggingFace上のDeepSeek V3モデルの合計サイズは685Bで、メインモデルが671B、MTPモジュールが14Bです)。
学習フェーズでは、メインモデルと MTP モジュールの両方が同じ埋め込みレイヤから入力を受ける。つまり、まずメインモデルが1つ先のトークンを予測し、その後、最初のMTPモジュールが2つ先のトークンを予測する。このプロセスは MTP モジュールの数に応じて継続する。トークンを予測した後、メインモデルと MTP モジュールは同じ出力ヘッドを使用する。
推論フェーズでは、MTP モジュールを柔軟に変更することができる。例えば、一般的なLLMのように、推論時にMTPモジュールを完全に破棄し、 メインモデルのみを使用することができる。また、MTPモジュールを使って投機的なデコーディングアプローチを実装し、生成プロセ スをさらに高速化することもできる。
他のモデルと比較した DeepSeek V3 のコストとパフォーマンス
上記のすべての革新的な機能により、DeepSeek V3 モデルは、クローズドソースの競合モデルよりもはるかに安価にトレーニングすることができました。
DeepSeek V3 は、2,048 個の NVIDIA H800 GPU を搭載したクラスタで学習されました。DeepSeek V3モデルの事前訓練フェーズには約532万8000ドル、微調整と強化学習を含む事後訓練フェーズには0.01万ドルかかり、DeepSeek V3モデルの最初から最後までの訓練には合計557万6000ドルが費やされた。これは、OpenAIのGPT-4のトレーニングにかかった費用(約1億ドル)よりもかなり安い(https://www.wired.com/story/openai-ceo-sam-altman-the-age-of-giant-ai-models-is-already-over/)。
また、DeepSeek V3は、下図にあるように、Qwen2.5 72B、Llama3.1 405B、Claude3.5 Sonnet、ChatGPT 4oなどの他のオープンソースやクローズドソースのLLMと比較して、異なるベンチマークで優れたパフォーマンスを示しました:
https://assets.zilliz.com/Comparison_between_Deep_Seek_V3_and_other_state_of_the_art_chat_models_cd9b7c18c0.png
DeepSeek-V3と他の最先端チャットモデルの比較 Source._.
DeepSeek V3の性能は、コーディング、数学、中国語などの様々なタスクにおいて、他の最先端モデルと比較して優れていることが証明されています。英語タスクでの性能は、いくつかのベンチマークでクロード3.5ソネットと同等の結果を示しました。
さらに、GPT-4-Turbo-1106を判定に用い、長さを制御した勝率を指標として、オープンエンド生成タスクにおけるDeepSeek V3の性能を他のLLMと比較しました。その結果、DeepSeek V3は、Arena-HardおよびAlpacaEval 2.0ベンチマークにおいて、他と比較して最高の性能を示しました。
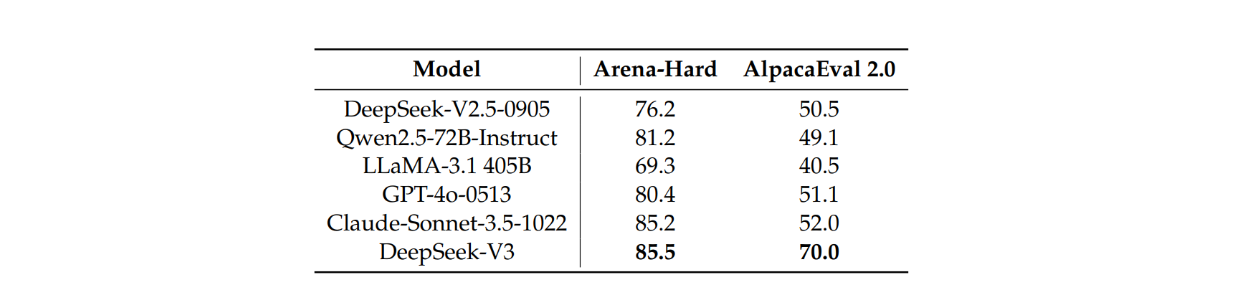
AlpacaEval2.0およびArena-HardベンチマークにおけるDeepSeek-V3と他の最先端チャットモデルの比較 Source._.
Arena-HardおよびAlpacaEval 2.0の両ベンチマークにおけるDeepSeek V3の優れた性能は、長くて複雑なプロンプトだけでなく、書き込みタスクや簡単な質問と回答のシナリオを処理する能力と堅牢性を示しています。
開発者が DeepSeek V3 を活用する方法
性能以外に、DeepSeek V3 モデルのもう 1 つの主な魅力は、オープンソースであることです。DeepSeekは、V3モデルをMITライセンスの下でオープンソース化することを決定しました。これは、開発者がその重みに自由にアクセスし、商用利用であっても独自の目的に使用できることを意味します。
パーソナライズされたレコメンデーションやコンテンツ生成から、バーチャルアシスタント、社内チャットボット、文書要約など、様々なGenAIのユースケースに利用することができます。また、これらのユースケースを利用することで、DeepSeek V3のパワーをオープンソースのベクトルデータベースであるMilvusと組み合わせることができ、何十億ものコンテキスト埋め込みを保存することができます。
この記事を書いている時点では、DeepSeek V3はまだHugging Faceに統合されていない。しかし、ローカルで簡単にモデルを使用・実行できるように、すぐに統合されることを期待している。Hugging Faceの正式な統合を待つ間、いくつかの方法でDeepSeek V3を実行することができます。
DeepSeek V3を試す最も簡単な方法は、DeepSeekの公式チャットプラットフォームを利用することです。サインアップして、モデルとのチャットを開始するだけです。
自分のマシンでローカルに実行したい場合は、まず、以下のコマンドで DeepSeek V3 の公式リポジトリをクローンする必要があります:
git clone <https://github.com/deepseek-ai/DeepSeek-V3.git>
次に、inference フォルダに移動し、以下のコマンドを実行して必要な依存関係をすべてインストールする:
cd DeepSeek-V3/inference
pip install -r requirements.txt
次に、モデルの重みをダウンロードする必要があります。HuggingFaceには2つのモデルの重みがあります: 基本バージョン (事前学習フェーズの後のみ)と チャットバージョン (事後学習フェーズの後)。好きなモデルのバージョンをダウンロードし、/path/to/DeepSeek-V3フォルダの中に重みを入れてください。
次のコマンドで、HuggingFaceモデルの重みを特定のフォーマットに変換することができます:
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
最後に、このコマンドを実行して、DeepSeek V3 とのチャットを開始できます:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
DeepSeek V3 を起動して実行する別の方法として、 vLLM, SGLang, LMDeploy, TensorRT-LLM などの LLM に最適化されたサービングフレームワークを使用する方法があります。
DeepSeek V3 以降の将来の展望
DeepSeek V3 の導入は、さまざまな面で大きなブレークスルーといえる。MLA、MoE、MTP、FP8量子化による混合精度トレーニングなど、DeepSeek V3のトレーニングフェーズで実装された多くのイノベーションにより、性能と効率が高いだけでなく、トレーニングコストも大幅に安いLLMを開発する道が開かれました。
MLA、MoE、MTPの実装は、推論中のトークン生成プロセスを様々な方法で高速化することに貢献する:
MLAはKVキャッシュメモリを節約し、入力表現の次元を低ランク表現に圧縮することでトークン生成を高速化する。
MoEは、タスクに応じて推論中に特定のエキスパートだけをアクティブにすることで、トークン生成プロセスを高速化し、モデルのスケーラビリティを向上させる。推論中に671Bのパラメータをすべてアクティブにする代わりに、モデルはそのごく一部(約37B)だけをアクティブにする。
推論中に MTP を再利用することで、投機的なデコーディングアプローチを容易にする ことができる。このアプローチでは、次のトークン予測は、ゼロから予測するのではなく、MTPモジュー ルによって予測された将来の可能性のあるトークンから開始することができる。
DeepSeek が DeepSeek V3 を MIT ライセンスの下でオープンソース化したことは、私たちグローバルな AI コミュニティがその技術に貢献し、実験し、構築することを奨励しています。これにより、私たち全員が、私たち全員に利益をもたらすAGIを達成するという目標に向けて、より迅速な技術革新の輪に入ることができるのです。
DeepSeek V3の性能は、他の最先端のLLMと比較してすでに優れていますが、将来的にはさらに向上する可能性があることが研究により示唆されています。
以前、DeepSeekチームは、最も強力なモデルであるDeepSeek R1の推論能力をDeepSeek V2.5モデルに抽出する研究を行いました。あまり聞き慣れないかもしれませんが、蒸留とは、より大きく高性能なモデルの知識をより小さなモデルに移すプロセスを指します。
DeepSeek V2.5は、R1モデルからの追加蒸留データを提示した場合、LiveCodeBenchおよびMATH-500ベンチマークで大幅な改善を示しましたが、平均応答長の増加という明らかな欠点もありました。

DeepSeek V2.5におけるDeepSeek-R1からの蒸留の寄与 Source._.
それにもかかわらず、この研究は、同じ知識蒸留技術を将来的にDeepSeek V3にも適用して、さまざまなデータ領域にわたって性能をさらに最適化できることを示しています。
結論
DeepSeek V3 は、オープンソースの AI 分野における大きな一歩である。DeepSeek V3は、主要なクローズドソースモデルに匹敵するパフォーマンスを、わずかなトレーニングコストで提供する。Multi-Head Latent Attention (MLA)、Mixture of Experts (MoE)、Multi-Token Predictions (MTP)などの革新的な機能は、学習および推論フェーズの効率性と精度の向上に貢献しています。また、MITライセンスに基づくオープンソースであるため、AIコミュニティはその進歩の上に構築することができ、AGIへの進歩を加速させる。
今後、DeepSeek V3のインパクトはさらに強力になる可能性がある。DeepSeek R1 と DeepSeek V2.5 によって以前に探求されたように、知識蒸留技術の応用の可能性は、さらなる最適化と効率向上の余地を示唆している。DeepSeek V3は、費用対効果が高く高性能なAI研究の新たなベンチマークを設定したと言える。
読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.