




制約付きサンプリングでLLMから構造化された出力を生成する
大規模言語モデル(LLM)は、構造化されていないデータとの関わり方を変え、創造的なテキストを生成し、洞察を抽出し、タスクを自動化するシステムを可能にした。しかし、これらのモデルは自由形式のコンテンツを生成する一方で、出力がJSON、XML、または事前に定義されたスキーマのような特定のフォーマットに従わなければならない場合、しばしば不足する。この限界は、コーディングアシスタント、意思決定エージェント、構造化情報抽出システムなど、精度が重要な実世界のユースケースにとっては致命的です。
最近サウスベイで開催されたUnstructured Data Meetupで、ZillizのStefan Webbがこの課題に対する実用的な解決策を発表した:制約付きサンプリングである。この記事では、構造化されていないデータの処理における意味検索の役割、有限状態機械がどのように信頼性の高い生成を可能にするか、最新のツールを使った実用的な実装など、彼の講演から重要な洞察を探る。また、これらの技術をベクトル・データベースとどのように統合し、非構造化データ処理と構造化出力生成の両方を扱うロバストなAIアプリケーションを作成するかについても検討する。
セマンティック検索とは何か?
セマンティック検索は、クエリの背後にある意味や文脈に焦点を当てることで、従来のキーワードベースの検索とは異なります。セマンティック検索は、正確な単語をマッチングする代わりに、より関連性の高い結果を提供するために単語間の関係を処理します。この機能は、テキスト、画像、音声、ビデオなど、データの大半が非構造化である世界では不可欠である。ここでは、非構造化データがどのように実用的な洞察に変換されるかを説明します。
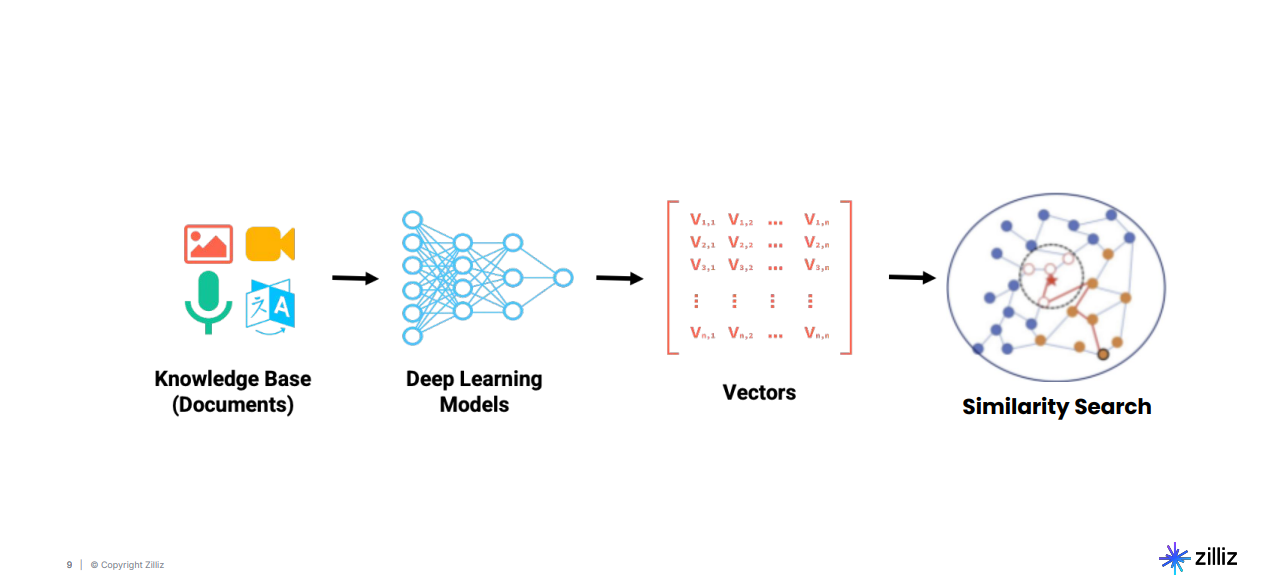
図:非構造化データを実用的な洞察に変えるパイプライン_。
このパイプラインは、文書、画像、音声記録、動画などの生データを取り込むことから始まる。データは、ベクトル埋め込みを生成するディープラーニングモデルに通される。これは、データの意味特性を高次元の数値で表現したものである。これらの埋め込みは、効率的な検索のために、Milvusなどのベクトルデータベースに格納される。最後に、セマンティック検索アルゴリズムは、これらの埋め込みを操作して、関連性に基づいて結果を特定し、ランク付けする。さて、ベクトル空間がどのように見えるか見てみよう。
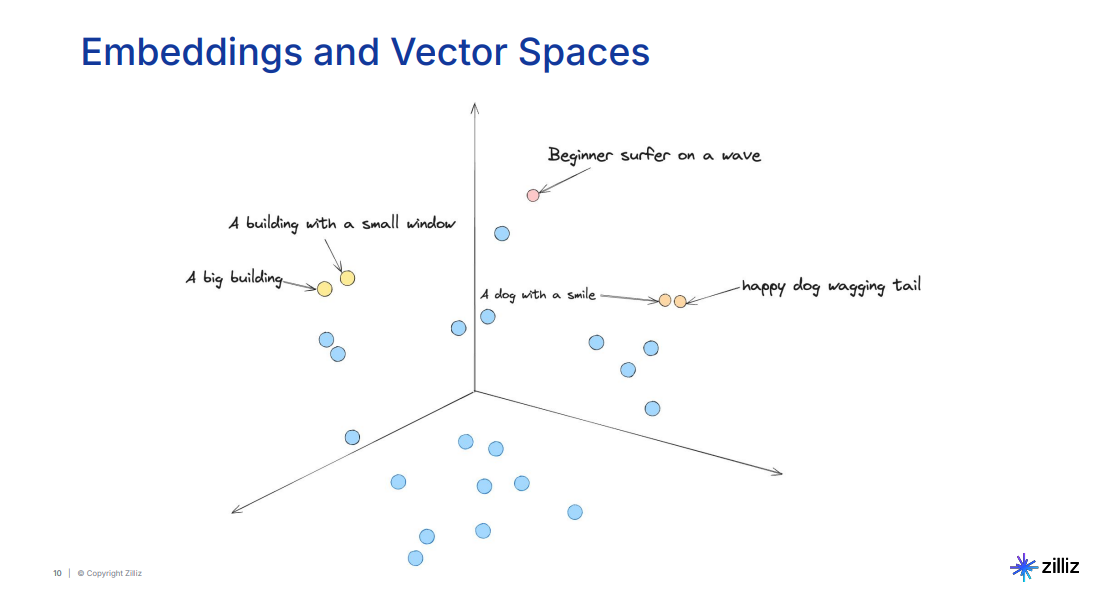
図:類似概念同士をクラスタリングした埋め込み空間の視覚化_」。
埋め込み空間の可視化では、類似した概念をクラスタリングします。例えば、尻尾を振っている幸せな犬と笑顔の犬のようなフレーズは、似たような意味を伝えるため、近くにグループ化される。一方、大きなビル**のような無関係なトピックは、空間内で離れた場所に配置される。このクラスタリングにより、クエリが異なる表現を使用している場合でも、システムは意味的に関連する結果を取り出すことができる。
セマンティック検索は、構造化されていないデータの量が増えるにつれて、ますます不可欠になっている。2025年までには、生成されるデータの90%以上が非構造化データになると推定されており、セマンティックな理解が可能なシステムの必要性が強調されている。
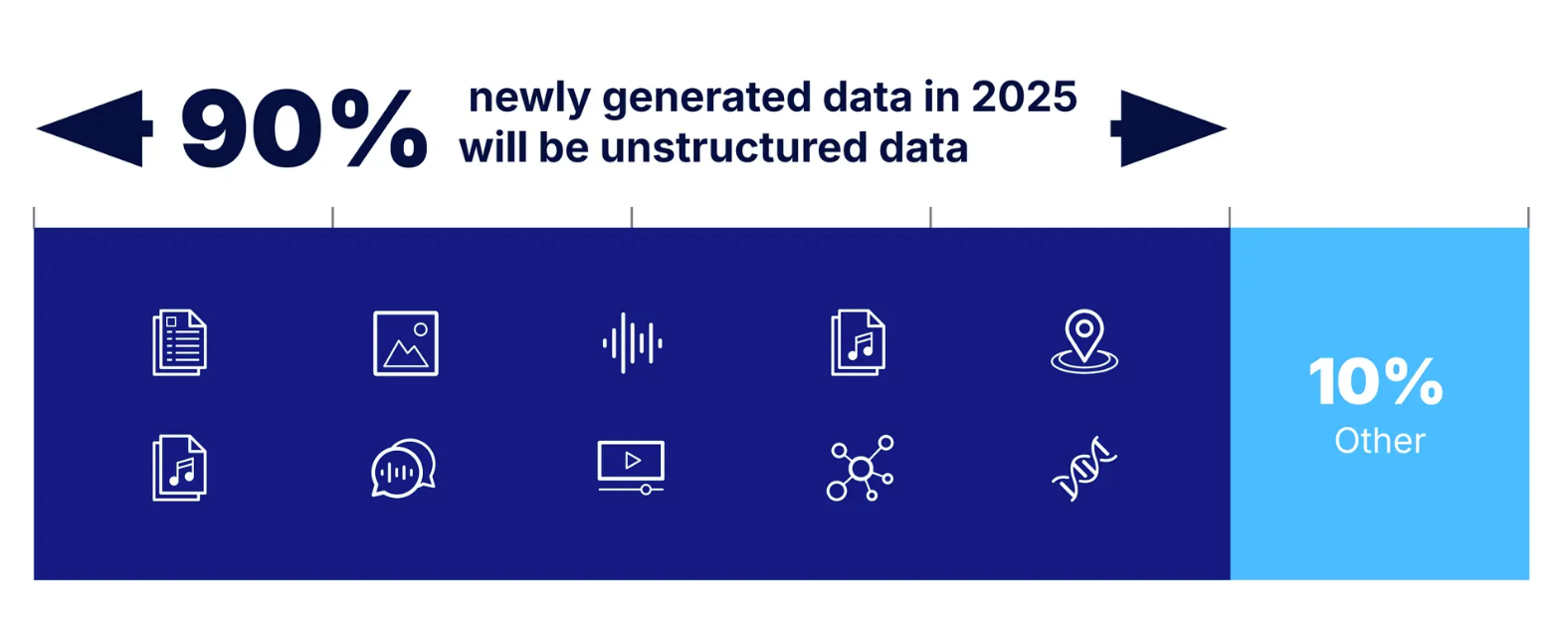
図:2025年に新たに生成されるデータの90%以上が非構造化データになる。
多項式サンプリング:テキスト生成の基礎
LLMのテキスト生成は、学習データから学習された確率に基づいてトークンごとにシーケンスを生成するプロセスである多項式サンプリングによって行われる。各トークンは単語、文字、または単語の一部を表し、モデルは確率分布からサンプリングして次のトークンを選択する。

図:LLMからの基本的な多項式サンプリング_。
アルゴリズムは空のシーケンスから始まり、シーケンスが完了するか停止条件が満たされるまで、繰り返しトークンを追加する。各ステップにおいて、モデルは次のトークンのすべての可能性について確率を計算し、これらの確率に基づいて1つをサンプリングする。この方法は自由形式のテキストを生成することに優れているが、構造的なルールを強制するメカニズムが欠けている。例えば、有効なJSONや整形式のコードを生成するには、構造エラーを修正するための後処理が必要になることが多い。
この限界は、ガイド付きサンプリングの必要性を浮き彫りにする。ガイド付きサンプリングは、生成プロセスに制約を組み込んで、出力が事前に定義された構造に確実に準拠するようにする。
ガイド付きサンプリング:生成中の構造ルールの強制
ガイド付きサンプリングは、生成のガイドとなる制約を適用することで、基本的な多項サンプリングプロセスを強化します。これらの制約はバイナリマスクによって強制され、各ステップで無効なトークンをフィルタリングします。マスクは出力の現在の文脈に基づいて動的に適応し、生成されたシーケンスが有効なままであることを保証する。

図:ガイド付きサンプリングによる構造化出力
例えば、JSONを生成するとき、システムは次のトークンを開始波括弧{の後のフィールド名に制限するかもしれません。同様に、コード生成では、無効な文字や不完全なステートメントをブロックすることによって、制約が適切な構文を強制することができます。このアプローチにより、生成後の大規模な検証や修正が不要になり、情報抽出や意思決定エージェントのようなアプリケーションに特に有用です。
生成プロセスに直接構造を導入することで、ガイド付きサンプリングは、LLMの創造的能力と構造化された出力に要求される精度とのギャップを埋める。この方法は、テキスト生成に有限状態機械(FSM)を実装するための基礎となる。
有限状態マシン:構造的一貫性の強制
有限ステートマシン(FSM)は、制約を強制するための正式なフレームワークを提供することで、ガイド付きサンプリングの概念をさらに発展させたものである。FSMは有限個の状態とその間の遷移を持つ計算モデルである。各状態は出力生成プロセスのポイントを表し、遷移は現在のコンテキストに基づいて有効なパスを定義します。FSMを生成パイプラインに統合することで、厳密な構造ルールを動的に強制することが可能になる。
FSMでは、状態があらかじめ定義されており、それぞれが生成プロセスにおける特定の条件や段階を表す。状態間の遷移は、生成される入力またはトークンに基づいて発生する。許容される遷移を定義することで、FSMは与えられた構造に適合する出力を生成するようにモデルを動的に導く。
例えば、JSONを生成するFSMは、括弧を開き、キーを書き込み、値を書き込み、括弧を閉じる状態を含むかもしれない。FSMは、値を書き込む前にブラケットを閉じないなど、遷移が論理的な順序で起こることを保証する。これにより、後処理を必要とせずに、出力の構造的な完全性が保証される。
FSMは、構造化データ抽出、コード生成、レスポンス・フォーマットなどのアプリケーションで特に有用である。各状態の有効な遷移を事前に計算することで、FSMを効率的に実装し、実行時のオーバーヘッドを最小限に抑えることができる。この効率性とリアルタイムの制約実施とが相まって、FSMは有効で文脈に正確な出力を生成することができる。
例有効数字の生成
FSMガイドによる生成を説明するために、有効な数を生成するタスクの例を見てみよ う。ルールでは、数値には数字と、オプションで小数点が1つだけ含まれていなければならない。
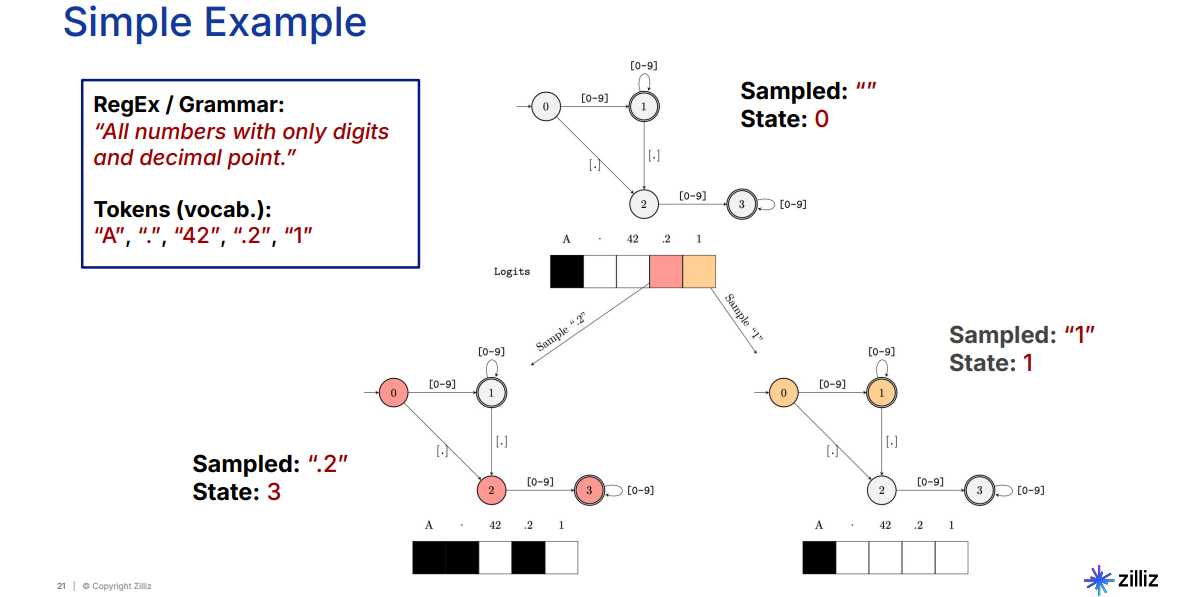
図:有効数字生成のFSM_(英語)
FSMは状態0から始まり、有効なトークンには任意の数字や小数点が含まれる。システムが**1**のような数字を生成すると、「状態1」に遷移する。この状態から、追加の数字が許可されるか、小数点が生成されると、FSMは状態2に遷移する。状態2では、小数点が複数あるとルール違反になるため、数字だけが有効である。FSMは、生成されたシーケンスに基づいて状態と有効なトークンを動的に調整し、出力が指定された形式を守るようにする。
この例は、FSMがリアルタイムで制約を強制する方法を強調しています。与えられたタスクの状態と遷移を定義することで、後処理や手作業による検証を必要とせずに、構造化された出力を生成できるロバストなシステムを作ることができる。
ガイド付きサンプリングとベクトルデータベースの組み合わせ
ガイデッドサンプリングは、ベクトルデータベースと組み合わせることで、その可能性を最大限に発揮する。Milvus](https://zilliz.com/what-is-milvus)のような特殊なデータベースは、高次元のベクトル埋め込みを効率的に保存、管理、検索するように設計されています。ガイド付きサンプリングとベクトルデータベースを組み合わせることで、構造化されていないデータを扱いながら、意味的に関連性があり、構造的に正確な出力を生成するための強力なフレームワークを作ることができます。この2つのコンポーネントがどのように連携してAIアプリケーションを強化するのかを探ってみよう。
意味論的バックボーンとしてのベクトル・データベース
ベクトル・データベースは、セマンティック検索を伴うアプリケーションの基礎層として機能する。ディープラーニングモデルによって生成されたエンベッディングは、ベクトルデータベース内の高次元空間に格納される。
ユーザーがクエリーを行うと、データベースのエンベッディングを生成したのと同じモデルを用いて、エンベッディングに変換される。そして、データベースは、クエリに最も関連する埋め込みを見つけるために類似検索を実行する。この検索プロセスにより、たとえクエリが正確なキーワードを使用していなくても、システムは文脈的に意味のある結果を提供することができる。
ガイド付きサンプリングによる構造の追加
ベクトル・データベースが意味的に関連する情報を検索する一方で、ガイド付きサンプリングは出力が特定のフォーマットや制約に従うことを保証する。関連する埋め込み情報を取得した後、それらは大規模言語モデル(LLM)への入力として渡されます。ガイド付きサンプリングがなければ、LLMは、書式が悪いJSONや無効なXMLなど、要求された構造から逸脱した応答を生成する可能性があります。ガイド付きサンプリングは、トークン選択プロセスで動的にルールを適用することで、この問題に対処します。
この統合の実際のアプリケーション
ベクトルデータベースとガイデッドサンプリングの組み合わせは、様々な業界で幅広く応用されています:
コーディングアシスタント:コーディング・アシスタント:開発者がAIを搭載したコーディング・アシスタントに問い合わせると、システムは関連するコード・スニペットやドキュメントの埋め込みを取得します。ガイド付きサンプリングは、出力されたコードが正しい構文と形式を守っていることを保証し、手作業による修正の必要性を減らします。
情報抽出システム**:これらのシステムは大規模なデータセットを分析し、名前、日付、場所などの構造化された情報を抽出します。ベクター・データベースはデータの関連セグメントを取り出し、ガイド付きサンプリングは出力をJSONのような事前に定義されたスキーマにフォーマットする。
専門領域向けチャットボット**:例えばヘルスケアや法律の領域では、チャットボットは意味的に類似したケーススタディやドキュメントを取得します。ガイド付きサンプリングは、生成された応答が厳格な法律または医療フォーマット標準に準拠していることを保証します。
制約付きサンプリングを実装するためのツール:アウトラインとBAML
制約付きサンプリング技法の実装を簡単にするツールがいくつかあります。例えば、Outlines libraryは、制約を定義して構造化された出力を生成するためのPythonベースのフレームワークを提供する。これは、開発者がテキスト生成中にJSONスキーマや正規表現パターンのようなルールを直接強制することを可能にする。同様に、BAMLは、LLMベースのアプリケーションの記述とテストのためのドメイン固有の言語を提供し、制約の定義と出力の検証のプロセスを効率化します。
Outlinesライブラリを使用して制約付きサンプリングを実施する方法を見てみましょう:
必要なライブラリをインストールすることから始めます:
pip install outlines transformers datasets
outlinesライブラリを使用すると、構造化された出力を生成することができる。transformers ライブラリでは、事前に学習されたモデルを読み込むことができる。datasets ライブラリは outlines ライブラリの依存ライブラリである。
環境が整ったので、コーディングを始めよう。
アウトラインをインポートする
インポートトランスフォーマー
# モデルを読み込む
model = outlines.models.transformers("gpt2-medium")
# テキスト生成用
generator = outlines.generate.text(model)
# 例1: 基本的な継続
prompt = "1+1=2?"
結果 = generator(prompt, max_tokens=30)
print("Unguided output:", result)
# 例2:正規表現による構造化生成
guided_output = outlines.generate.regex(model, r"([Yy]es|[Nn]o|[Nn]ever|[Aa]lways)")(
prompt, max_tokens=30
)
print("Guided output:", guided_output)
# 例3:数値正規表現による制約
prompt = "ノーム・チョムスキーは何年に生まれたか?n"
guided_output_year = outlines.generate.regex(model, r "19[0-9]{2}")(
prompt, max_tokens=30
)
print("Guided output (year):", guided_output_year)
上記のコードでは、まずインストールしたライブラリをインポートし、次にテキストを生成するためのGPT-2媒体モデルをロードします。最初に、プロンプト Is 1+1=2? に対するガイドなしの応答を生成し、基本的なテキスト生成を紹介します。次に、正規表現を使用して、Yes、No、Never、Alwaysのような回答のみを生成するようにモデルをガイドし、出力が特定の回答フォーマットに準拠するようにします。最後に、正規表現制約r "19[0-9]{2}"を実装して、ノーム・チョムスキーの生年をターゲットとする4桁の年を抽出します。以下に出力例を示します:

図:Outlinesライブラリを使った制約付きサンプリングの出力
これは、特定の情報抽出タスクに合わせて、自由形式と構造化テキストの両方を生成するモデルの能力を示しています。
結論
Stefanは、制約付きサンプリングとFSMが、大規模な言語モデルを実世界のアプリケーションでより信頼性の高いものにする上で、いかに重要な進歩であるかを示してくれた。構造的な一貫性を強制し、Outlinesやベクトル・データベースのようなツールを活用することで、柔軟性と精度を兼ね備えたシステムを構築できるようになった。この分野が発展するにつれて、これらの技術は、非構造化データ処理と構造化出力生成のギャップを埋め、AI駆動型アプリケーションの新たな可能性を引き出す上で極めて重要な役割を果たすようになるだろう。
詳しくは、ステファンの講演をYouTubeでご覧ください。
読み続けて

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.