




AIに備える非構造化データのための適切なETLツールの選択
あなたの組織のデータは、実際にどれくらい利用されているだろうか?多くの企業と同じなら、答えは「あまりない」だろう。というのも、企業が生成するデータの90%以上は非構造化であり、文書、電子メール、ビデオなどに分散しているからだ。行や列に収まる構造化データとは異なり、非構造化データには決まったスキーマがないため、処理が難しくなる。
非構造化データの管理は、一貫性のないフォーマットや多様なソースのために困難である。 非構造化データは、ビジネス・インテリジェンス(BI)、人工知能(AI)、意思決定において大きな可能性を秘めている。非構造化データを効果的に処理する組織は、より深い洞察を得て、自動化を改善し、顧客体験を向上させる。
抽出、変換、ロード(ETL)は、様々なソースからデータを移動させ、使用可能な形式に変換し、ターゲットシステムにロードするプロセスである。ETLプロセスは、あらかじめ定義されたスキーマと厳格な変換を使用して、構造化データ用に構築された。その結果、非構造化データの複雑さと可変性に苦戦していた。最新のETLツールは、自然言語処理(NLP)(https://zilliz.com/ai-faq/what-are-the-main-applications-of-nlp)や機械学習(ML)のような高度な技術を使用している。これらの機能により、非構造化データを処理し、標準化し、ベクトルデータベースに効率的に格納することができる。これにより、データの検索、分析が容易になり、予測分析、チャットボット、ナレッジグラフなどのAI駆動型アプリケーションに利用できるようになる。
このブログでは、非構造化データ用のETLツール、主な課題、ユースケースに適したツールの選択方法について説明します。また、さまざまなETLソリューションの比較も掲載しています。
ETLとは?
ETLとは、**Extract(抽出)、Transform(変換)、Load(ロード)の頭文字をとったもので、データを抽出し、一貫性のある使用可能な形式に変換し、データウェアハウスやベクトルデータベースのようなターゲットシステムにロードする中核的なデータ統合プロセスです。
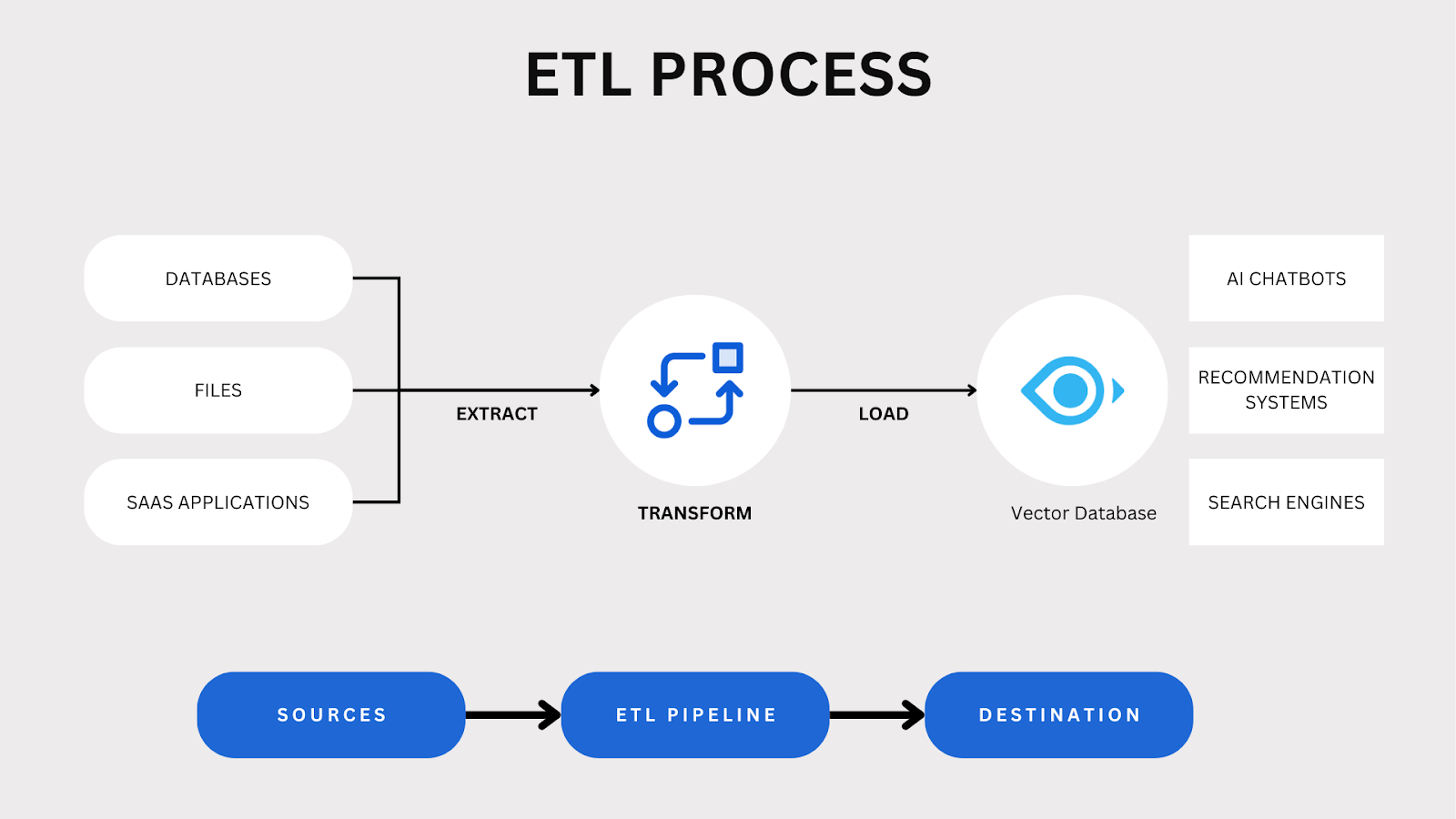
ETLプロセスの概要
ETLプロセスにはいくつかの段階がある:
1.**データは、PDF、電子メール、ビデオ、画像、ソーシャルメディアフィードなど、多様なソースから収集される。非構造化コンテンツには、スキャン文書の光学式文字認識(OCR)、音声ファイルの音声テキスト変換、画像や動画からのメタデータ抽出などの専門技術が必要です。その目的は、構造に関係なく、関連するすべての情報を取り出すことである。
2.変換:* 抽出されたデータは、ビジネス要件または技術要件を満たすように処理される。これには、クリーニング、正規化、集計、ビジネスルールの適用などが含まれ、正確性と使いやすさを保証します。
3.**処理されたデータは、ベクトルデータベースのような非構造化コンテンツ用に最適化されたシ ステムに格納される。これらのシステムにより、高次元データの効率的な索引付け、検索、分析が可能になり、意思決定のサポートが容易になる。
ETLは、組織が複数のソースからデータを統合し、アクセス可能で分析に適した状態にするのに役立ちます。効果的なETL戦略により、企業は洞察力を高め、効率を改善し、データ主導の世界で競争力を維持することができます。
人気の非構造化データETLツール
AIモデルの構築であれ、検索支援世代(RAG)パイプラインの設定であれ、ユースケースに適したETLツールの選択は不可欠です。いくつかのETLツールは、ベクトルデータベースとの非構造化データ統合を管理するのに役立ちます。以下は、注目すべきツールの概要、主な機能、使用例です。
1.エアバイト
Airbyteは、Extract and Load (EL)データパイプラインを構築するためのオープンソースのデータ移動基盤である。データソースコネクタを介した非構造化データおよび半構造化データの移動を容易にします。
主な特徴と機能
豊富なコネクターカタログ:** 550以上の構築済みコネクターを提供し、構造化および非構造化データソースの両方をサポートします。
AI統合: **数百の一般的なソースからベクトルデータベースにデータを移動することにより、ジェネレーティブAI(GenAI)ワークフローをサポートします。
カスタマイズと拡張性: **ローコード/ノーコードツールでカスタムコネクタを数分で構築するためのオープンソースプラットフォームを提供します。
使用例
検索機能付き生成](https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation) (RAG) パイプラインの構築。
非構造化データをAIや機械学習モデルに統合する。
複数のソースからのデータを統合して包括的な分析を行う。
2.ファイブトラ
Fivetranは、様々なソースからデータウェアハウスやベクターデータベースへのデータ移動を自動化するマネージドデータ統合サービスである。
主な特徴と機能
SaaSアプリケーション、データベース、ERPを含む650以上のノーコードコネクタを提供します。
自動データ同期: **手動操作なしで、ソースから宛先まで継続的にデータを更新します。
変換サポート: ** Fivetranのデータモデルは、お客様の生データを即座に生産可能なテーブルに変換し、洞察を促進します。
スキーママイグレーション:** シームレスなデータレプリケーションのためのスキーママイグレーションをサポートします。
使用例
SalesforceやZendeskのような複数のデータベースやSaaS(Software-as-a-Service)ツールのデータを一元管理。
最小限の労力で最新の分析データベースを維持。
構造化および非構造化データソースのETLプロセスを簡素化します。
3.非構造化.io
Unstructuredは、RAGやモデルの微調整などのAIアプリケーションのために、非構造化ドキュメントを取り込み、処理し、変換するように設計されたプラットフォームである。
主な特徴と機能
多様なデータソース:** テキスト文書、画像、PDF、プレゼンテーションを含む様々なファイルタイプをサポートし、複数のフォーマットからのシームレスな取り込みを可能にします。
LLM-Ready:**データがどこにあっても、それを取り込み、AIに適したJSONファイルに変換するコネクタを提供します。
互換性:*** 主要なベクターデータベースやLLMフレームワークとシームレスに統合します。
使用例
AIや機械学習アプリケーションのための非構造化データの準備。
エンタープライズアナリティクスのためのデータ品質の向上
非構造化データを生成AIアーキテクチャに統合する
4.非構造化AI
非構造化AIは、RAGアーキテクチャと下流のGenAIアプリケーションのために、複雑な非構造化ドキュメントフォーマットを処理します。
主な特徴と機能
データ変換: **生の非構造化データをRAGやGenAIアプリケーションに適した構造化フォーマットに変換します。
統合サポート:** RAGやベクトルデータベースのような下流のAIワークフローと連携します。
使用例
非構造化データの入力を必要とするRAGパイプラインやAIアプリケーションの開発。
クリーニングされたデータによる自然言語処理タスクの強化。
マルチメディアコンテンツの分析前処理の自動化
5.ベクターETL
VectorETLは、AIエンジニアのAIアプリケーションのためのデータ処理を支援するために設計されたモジュラーフレームワークである。多様なデータソースをベクトル埋め込みに変換し、様々なベクトルデータベースに格納するプロセスを効率化します。
主な特徴と機能
構造化されていないデータをベクトル埋め込みに変換することで、ベクトル検索システムの作成と管理を簡素化します。
データ統合:**様々なベクトルデータベースへのシームレスなデータフローをサポートします。
性能最適化:**大規模な非構造化データセットの効率的な処理を保証します。
使用例
ベクトル化されたデータ入力に依存するAIアプリケーションの構築。
ベクトルベースの検索システムによる検索機能の強化。
マルチメディアデータのAIワークフローへの統合
6.概要
Unstractは、あらゆる規模の文書処理ワークフローを自動化するノーコード・プラットフォームです。最先端のAIを活用し、現在のインテリジェント・ドキュメント・プロセッシング(IDP)やロボティック・プロセス・オートメーション(RPA)の能力を凌駕します。
主な特徴と機能
自動データ構造化:** 大規模言語モデル(LLMs)を活用し、大規模な手作業なしに非構造化データを構造化フォーマットに変換します。
テキスト、画像、マルチメディアなど、さまざまな非構造化データをサポートします。
ユニークな抽出アプローチ:** デュアル LLM システムを採用し、一方のモデルが抽出側、もう一方がチャレンジャーとして機能します。
使用例
ビジネスインテリジェンスプラットフォームのための非構造化データの準備の合理化。
非構造化ドキュメントからAIに最適化されたアウトプットを生成する。
抽出された文書データのLLM理解の向上
非構造化データのETLにおける課題
非構造化データのETLには、データの多様で予測不可能な性質に起因する独自の課題が伴います。多様な形式を扱い、データ品質を確保し、一貫性を維持することは複雑です。以下に主な課題を挙げます。
データの多様性:** 非構造化データには、テキスト、画像、動画、音声などの形式があります。複数のタイプを扱うには、高度なツールが必要です。 ;
構造化データとは異なり、非構造化データには事前に定義されたスキーマがないため、意味のある情報を直接抽出することが困難です;
変換の複雑さ:** 非構造化データを構造化フォーマットに変換するには、多くの場合 NLP や機械学習を使用した複雑な変換が必要です;
データの品質と一貫性:** 非構造化データには、エラーや不整合が含まれています。様々なフォーマットや固定スキーマがないため、正確性を確保することは困難です。
構造化されていないデータを複数のソースから統合することは複雑です。シームレスな統合にはフォーマットの標準化が不可欠。
専門的なETLツールやフレームワークがこれらの課題を解決し、非構造化データをより管理しやすく、AIに対応できるようにします。
比較と提言
非構造化データ用の適切なETLツールを選択することは、効率的なデータ統合と分析のために非常に重要です。以下では、非構造化データ用の一般的な ETL ツールを比較し、主な機能、ユースケース、および潜在的な制限について説明します:
| ツール | コアストレングス | 主要な非構造化データ処理 | AI/MLフォーカス | オートメーションレベル | オープンソース/マネージド | エアバイト | **幅広いデータ接続性 | **多様なソースコネクター | **オープンソース/マネージド |
| エアバイト**|幅広いデータ接続性|多様なソースコネクタ|RAG/GenAIデータ移動|カスタマイズ可能なコネクタ|オープンソース | |||||||||
| Fivetran**|自動化されたデータパイプライン|自動化されたスキーマハンドリング|基本的なデータウェアハウス|高度な自動化|マネージドサービス | |||||||||
| Unstructured.io|AI向けドキュメント前処理|複雑なドキュメントフォーマットの解析|LLM対応出力|継続的な前処理|エンタープライズソリューション|Unstructured.io|AI向けドキュメント前処理|複雑なドキュメントフォーマットの解析|LLM対応出力|継続的な前処理|エンタープライズソリューション | |||||||||
| Unstructured AI | 高度なデータ変換 | チャートや階層的なテキスト処理 | RAG最適化 | カスタマイズ可能なパイプライン | オープンソース | ||||
| VectorETL | ベクトル埋め込み作成 | ベクトルデータベース統合 | ネイティブベクトル化 | スケーラブルベクトル処理 | モジュラーフレームワーク | ||||
| Unstract|正確な文書抽出|マルチメディア抽出、デュアルLLMチェック|トークン使用量削減、高精度抽出。 | デュアルLLM検証 | オープンソース |
おすすめ
選択するETLツールは、目標と技術要件によって異なります。複数のソースからデータを一元化する必要があるのか、AIと統合する必要があるのか、オープンソースのソリューションを優先するのか。以下は、さまざまなユースケースに基づく推奨事項です:
AIと機械学習の統合のために: Unstructured.io、VectorETL、およびUnstractは、AIアプリケーションに焦点を当てたプロジェクトに適しており、非構造化データをAIと互換性のある形式に変換するための強力なサポートを提供しています。
包括的なデータの一元化のために: AirbyteとFivetranは、広範なコネクタを提供し、構造化および非構造化の両方の複数のソースからのデータを統合するのに理想的です。
Airbyteは幅広いコネクタとカスタマイズ可能な機能を提供しており、ETLプロセスをカスタマイズしたいチームに最適です。
複雑な文書処理のニーズに:** Unstractは、そのデュアルLLMアプローチで際立っており、異なる文書タイプからのデータ抽出において高い精度を保証します。
インプリメンテーションインサイト
特定の非構造化データソースを選択し、選択したツールを使用して小規模な ETL プロジェクトを実行します。これにより、本格的な導入に着手する前に、互換性、効率性、ツールの機能を評価することができます。
クロスファンクショナルコラボレーション: **データエンジニア、アナリスト、ドメインエキスパート間のコラボレーションを促進する。これにより、ETLプロセスがビジネス目標に合致し、より良いデータ処理と意思決定のために専門的な知識を活用できるようになります。
ETLプロセスの拡張:*** データ量と複雑さが増すにつれて、選択したETLツールが効率的に拡張できることを確認する。処理速度、コネクタのサポート、さまざまな非構造化データ形式との互換性などの要素を考慮する。
ニーズに基づいてETLツールを慎重に評価することで、よりスムーズで効率的なワークフローを実現できます。パイロットプロジェクトを実施することで、適切なツールを検証し、統合の課題を最小限に抑え、非構造化データの価値を最大限に高めることができます。ユースケースがRAGの場合、チャンキング、エンベッディング、ベクターストレージを強力にサポートするツールを選択することで、実装が簡単になります。
ベクトル検索でAIのための非構造化データのパワーを解き放つ
テキスト、画像、動画などの非構造化データは、その複雑さゆえにしばしば未開拓のままになっている貴重な洞察を秘めている。ベクトル検索をAIワークフローに組み込むことで、その可能性を最大限に引き出すことができる。ベクトル検索は、非構造化データをベクトル埋め込みに変換することで処理と分析を可能にし、AIモデルが隠れたパターンを検出できるようにする。
なぜベクトル検索でAIのための非構造化データをマスターするのか?
非構造化データには複雑な情報が含まれています。ベクトル検索は、従来の方法では見落としがちなパターンや傾向を明らかにします。これにより、企業はデータ駆動型の意思決定を行い、競争上の優位性を得ることができます。
非構造化データは複数のプラットフォームにまたがって保存され、サイロ化しています。ベクター・サーチは多様なソースをシームレスに統合し、包括的な分析を可能にします。これにより、徹底的な分析が可能になり、より優れた洞察力とデータ主導の戦略が育まれます。
非構造化データをベクトル埋め込みデータに変換することで、より正確でコンテキストを考慮した検索が可能になります。これにより、AIアプリケーションが改善され、ユーザーエクスペリエンスと関連性の高いアウトプットが向上します。
Milvus/ZillizクラウドとETLツールの統合
オープンソースのベクトルデータベースであるMilvusと、そのマネージドサービスであるZillizCloudは、AIアプリケーションのための大規模なベクトルデータを扱います。Zillizは複数のベクトルデータベースとの統合を提供し、非構造化データの可能性を最大限に引き出す。1,000以上のコネクター](https://zilliz.com/data-connectors)をサポートし、AIを活用した検索と分析のために様々な非構造化データソースのシームレスな統合を可能にします。
Airbyteインテグレーション:** MilvusはAirbyte用のコネクタを提供し、様々なソースからの非構造化データをベクターデータベースにシームレスに取り込むことができます。これにより、ETLワークフローが簡素化され、AIへの対応が強化されます。
Fivetranとの統合: **Fivetran用のMilvusコネクタを使用することで、組織は構造化データおよび非構造化データのベクターデータベースへの転送を自動化できます。このセットアップにより、AIを活用した検索と分析が最適化されます。
Unstructured.ioとの統合: MilvusはUnstructured.ioと統合し、変換された非構造化データをベクトルデータベースに直接取り込むことができます。これにより、AIモデルがインサイトを効率的に処理し、取得できるようになります。
ベクター検索を始める
1.適切なETLツールの選択:データソースとビジネス要件に合ったETLツールを選択する。拡張性、統合の容易さ、非構造化データのサポートなどの要素を考慮する。
2.Milvus/Zilliz Cloudとの統合:選択したETLツールのMilvusコネクタを活用する。この統合により、非構造化データに由来するベクトル埋め込みデータのシームレスな取り込みと保存が可能になる。
3.**AIアプリケーションの開発Milvus/Zilliz Cloudに保存されたベクトルデータを活用して、チャットボット、レコメンデーションエンジン、インテリジェント検索システムなどのAIアプリケーションを構築することができます。これらのソリューションは、高度な検索と分析を可能にし、非構造化データから貴重な洞察を抽出して、イノベーションと情報に基づいた意思決定を促進します。
非構造化データソースからMilvusコネクターへ|出典
結論
非構造化データを効果的に管理することは、AIや機械学習の可能性を最大化することを目指す組織にとって極めて重要である。Airbyte、Fivetran、Unstructured.io、Unstructured AI、VectorETL、UnstractなどのETLツールは、非構造化データの処理と統合のための堅牢なソリューションを提供している。
これらのETLツールとMilvusのようなベクトルデータベースを統合することで、AI主導の検索と高度な分析機能が強化される。Zillizは、シームレスなETL統合を可能にすることで、このプロセスを簡素化し、企業が1,000以上の非構造化ソースからMilvusに直接データを取り込むことを可能にします。
適切なETLツールと統合を選択することで、企業は貴重なインサイトを発見し、イノベーションを推進し、AI主導の世界で競争力を維持することができます。
関連リソース
ETL | Zilliz](https://zilliz.com/jp/glossary/etl)
非構造化データ|Zilliz](https://zilliz.com/glossary/unstructured-data)
ベクトル探索で非構造化データをAIに対応させる|Zilliz](https://zilliz.com/data-connectors)
ベクターデータベース統合ハブ|Zilliz](https://zilliz.com/product/integrations)

読み続けて

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.