




From Extraction to Insights: Understanding ETL

From Extraction to Insights: Understanding ETL
 ETL Pipeline.png
ETL Pipeline.png
How do businesses convert enormous raw datasets into powerful insights? What steps do organizations take to integrate and refine data before analysis? The answer lies in Extract, Transform, and Load (ETL).
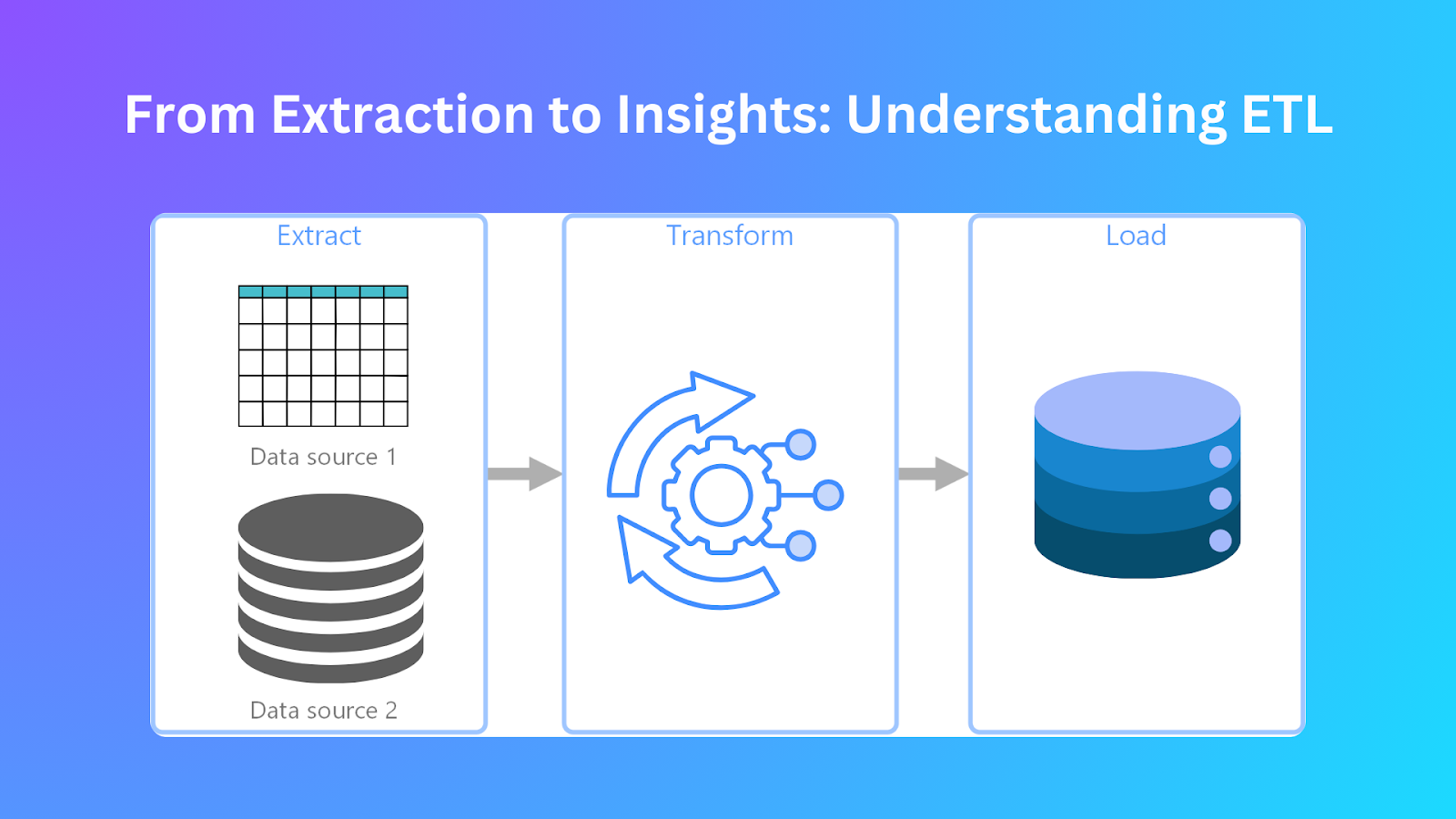
ETL is the key to modern data management. It allows organizations to collect, process, and load data for analysis. ETL extracts information from several resources, modifies it to eliminate errors, and then places it into a centralized database. This process allows for refined, accurate, and organized information, aiding business decision-making.
Data without ETL is challenging to analyze due to its scattered and distorted nature. Inefficient data can lead to errors, impacting various aspects such as customer relations or operational performance. ETL solves poor data quality by automating workflows and maintaining data integrity. This helps the business streamline reporting, enhance analytics, and improve decision-making.
With companies making everything data-driven, understanding ETL becomes crucial. Whether you are working on structured databases, cloud systems, or real-time analytics, ETL guarantees the integration and processing of quality data.
This piece will discuss how ETL functions, its impact, and how an organization can fully use it. We will also uncover the top tools you can use to make your ETL process smoother.
What Is ETL (Extract, Transform, and Load)?
ETL is the core data management and integration process. It begins by extracting data from different sources before transforming it into a suitable format for loading into target destinations such as data warehouses or data lakes. Organizations achieve data consolidation by uniting separate data sources into one repository to support analysis.
ETL is the backbone for maintaining data consistency, quality, and accessibility regardless of system or platform differences. This approach serves multiple industries, including finance, healthcare, and e-commerce.
Businesses use this method to organize their data and remove inconsistencies, which enhances decision-making capabilities. Modern ETL tools can efficiently process both structured and unstructured data.
A well-designed ETL pipeline system enables organizations to analyze trends and uncover insights. The automated workflow enhances operational efficiency through data processing automation. Businesses use ETL to create a unified view that supports accurate reporting and strategic planning activities.
How ETL Works
Data processing through ETL follows a three-step process that ensures accuracy and efficiency during each stage. These stages are:
Extraction
The ETL pipeline starts with data extraction as its initial stage. This stage collects data from different sources before uniting them for processing purposes. Through the extraction process, organizations acquire complete datasets from their diverse systems, which include databases, flat files, cloud storage, and APIs. Here are some of the steps in the data extraction phase:
Data source identification: The first step in the extraction determines where the data resides. Data may come from MySQL and PostgreSQL relational databases, MongoDB and Cassandra NoSQL databases, third-party APIs, CSV or JSON files, and streaming data platforms. Building an effective ETL pipeline requires the proper identification of suitable data sources.
Data retrieval: The data retrieval methods depend on business requirements and the available system functionalities. Data can be retrieved in two ways: either full or incremental. Full extraction collects all data from sources, while incremental extraction only gathers changes since the last extraction. Incremental extraction is preferred because it shortens processing duration and decreases the strain on source systems.
Handling data discrepancies: The extracted data may contain empty fields, inconsistent data types, and structural formats. Organizations should conduct pre-processing checks to identify and manage inconsistencies before starting the transformation phase.
Transformation
After extraction, the data needs to be transformed to ensure compatibility with the target system schema and apply business rules. This transformation process leads to improved data quality, consistent data, and enhanced usability. Here are some of the ways to transform your data:
Data cleaning: It is one of the fundamental transformation procedures. It requires duplicate removal, value imputation for missing data, and standardization of naming conventions. This helps produce reports that are both precise and free from mistakes.
Data integration: The data originates from multiple sources that contain separate data structures. Data integration creates a single coherent data view from various separate datasets. The process involves mapping different column names, reconciling time zone differences, and ensuring referential integrity.
Data aggregation: It helps summarize data for efficient analysis. Businesses often need reports containing regional sales totals, quarterly customer spending averages, and monthly revenue patterns. The aggregation process enables quicker data queries and simplifies data interpretation.
Data conversion: Multiple data types must be converted to be compatible with the required system. Standardizing the data formats is crucial, while normalization of text fields and unit conversion for numerical data completes the process. The data transformation process ensures that all loaded data matches exactly with analytical needs.
Business rules application: Organizations typically create business rules for data transformation processes. A financial institution uses transaction thresholds to develop categories, and e-commerce companies divide their customers into segments based on their purchase activity. The defined rules generate value by organizing unprocessed data into functional categories.
Loading
The transformed data requires loading into a target system, which can be a data warehouse, data lake, or analytical database. The loading process establishes the level at which data can be efficiently queried and analyzed.
Loading into target system: During complete load procedures, the target system receives all data in one operation. This method is used primarily during the first data migration or for handling smaller datasets. Another way is to load only new records and updates from the source system. This method shortens processing duration while making operations more efficient.
Indexing and partitioning: Data indexing methods and partitioning techniques accelerate the system's performance in record searches. Partitioning techniques split data collections into smaller segments, enhancing query performance and making data more manageable.
Organizations establish backup strategies to protect their data from loss during system failures. This method maintains data protection and ensures data availability at all times.
Comparison: ETL vs. ELT
Data integration relies on ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) as its primary methods to transfer data from various sources into data warehouses or lakes. The two methods share the goal of efficient data transfer, but they operate differently when processing and fitting into contemporary data systems. Here is the comparison between them:
| Aspect | ETL | ELT |
| Process Sequence | Extract -> Transform -> Load | Extract -> Load -> Transform |
| Transformation | Transformation occurs before loading into the target system | Transformation occurs after loading into the target system |
| Data Storage | Data is stored in a temporary staging area during the transformation | Data is stored in the target system, and transformation occurs in place |
| Data Processing | Data is processed in batches, and processing is typically done in a linear fashion | Data is processed in real-time or near-real-time, and processing can be done in parallel |
| Scalability | It can be less scalable due to the need for a staging area and batch processing | More scalable due to the ability to process data in real-time and in parallel |
| Cost | It can be more costly due to the need for a staging area and batch processing | It can be less costly due to the ability to process data in real-time and parallel |
| Flexibility | Less flexible due to the rigid process order | More flexible due to the ability to perform transformations at any time |
| Use Cases | Suitable for batch processing, data warehousing, and business intelligence | Suitable for real-time analytics, data integration, and big data processing |
RTL vs ELT | Source
Benefits and Challenges
While ETL supports extracting, transforming, and loading data, it also has benefits and challenges. Let’s have a look at them:
Benefits
Data lineage tracking: ETL processes track data movement from sources to destinations. Their primary functions include identifying errors, upholding integrity, and ensuring accuracy compliance.
Historical data preservation: The ETL process captures data snapshots along its journey, allowing organizations to maintain historical information necessary for trend analysis and reporting. Businesses can track data while conducting comparisons to aid their decision-making process.
Complex data transformation: ETL tools excel at executing complex data transformations, including aggregation processes, data type conversions, and the implementation of business logic. The system's capabilities facilitate data cleaning operations, producing structured and standardized information before the target system receives it.
Data enrichment: The data enrichment process of ETL allows businesses to combine information from various external databases, thereby enhancing dataset quality and completeness. Incorporating contextual information through enrichment increases analytical insight by adding value to data for decision-making purposes.
Batch processing efficiency: ETL workflows achieve maximum efficiency through batch processing, which handles large data volumes during scheduled off-peak cycles. The process minimizes system performance impact during regular business hours while efficiently managing large datasets.
Challenges
Real-time integration limitations: Traditional ETL processes integrate data in scheduled batches, which limits real-time data requirements. Organizations that require instant analytics and decision-making capabilities encounter challenges because of the delays associated with traditional ETL processes.
Resource-intensive operations: The computational requirements for ETL workloads become particularly demanding when data transformation and loading processes occur. The high usage of CPU and memory resources decreases the speed of system operations, thus affecting performance levels.
Error handling complexity: Error management becomes difficult because ETL pipelines need to handle numerous data sources and intricate transformation rules. Robust monitoring tools and debugging systems are needed to identify inconsistencies, handle missing data, and manage quality.
Scalability constraints: The growing volume of data presents scalability challenges that require ETL processes to either secure new infrastructure investments or adopt redesigned architectures. When data optimization is insufficient, increasing data volumes can lead to processing delays and limitations in system performance.
Dependency management: The various stages of ETL workflows rely on one another, so any failure in one step can create a cascading effect throughout the entire pipeline. To avoid operational disruptions, effective management of dependencies necessitates thorough scheduling along with monitoring systems and error recovery mechanisms plans.
Use Cases and Tools
The ETL process is a fundamental operational requirement for multiple industries, helping to achieve efficient data integration and analysis. Here are some of the use cases and tools:
Use Cases
Retail: The ETL process enables retail stores to gather checkout system data, which they normalize against inventory records before storing it in a unified database. The system enables tracking of sales data, stock management, and better customer understanding.
Finance: Financial institutions apply ETL methods to merge transaction data from multiple systems before transforming and loading it into integrated data storage systems. The consolidation process enables organizations to detect fraud effectively, manage risks, and produce compliant reports.
Healthcare: Healthcare organizations apply ETL processes to unite data from electronic medical records (EMRs), clinical databases, and administrative systems. The system's integration allows better patient care management with operational efficiency improvements while supporting informed decision-making processes.
Popular ETL Tools
AWS Glue: A serverless data integration service that facilitates connection to over 70 diverse data sources. It offers a centralized data catalog, a serverless environment, and customizable scripts.
Apache NiFi: It stands as an open-source system that enables automated data flow processing through its ETL functionality. The system delivers easy-to-use web-based access, instant processing capabilities, and extensive customization options that benefit complex data routing operations.
Matillion: A cloud-native ETL tool that operates seamlessly on major cloud-based data platforms. It offers features like generative AI, pre-built connectors, and collaborative workflows.
The tools and their applications demonstrate how essential ETL methods are for converting raw data into practical insights within multiple business domains.
FAQs
- What is the primary purpose of ETL?
ETL functions to merge data from various sources into a single unified repository. The data processing workflow includes three stages: data is extracted from sources and then transformed for operational needs before being loaded into an analytical system.
- How does ETL differ from ELT?
The ETL process begins by extracting data from source systems before transforming it into a staging area to load it into the target system. The data is then loaded into the target system, and transformations are performed directly on that system.
- What are some common challenges in implementing ETL processes?
Implementing ETL procedures faces multiple obstacles because it requires effective data management from different origins, quality control, and efficient handling of substantial data amounts. The challenges create performance issues that demand thorough resource planning to resolve effectively.
- Can ETL processes be automated?
ETL tools provide automation capabilities through scheduling and workflow management features to execute data transfer processes. Automation enables efficient operations through automatic data processing that reduces human involvement while maintaining consistent data quality to keep datasets current for analysis.
- Why is data transformation important in ETL?
Data transformation within ETL operations is critical in cleaning up, standardizing, and formatting data obtained from different sources. The data transformation process ensures that the target system receives accurate and consistent data for analysis and reporting, which supports reliable business decisions.
Related Resources
- What Is ETL (Extract, Transform, and Load)?
- How ETL Works
- Comparison: ETL vs. ELT
- Benefits and Challenges
- Use Cases and Tools
- FAQs
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free