




リレーショナル・データベースとベクトル・データベース
データベースは長い間、アプリケーションのパフォーマンスに課題をもたらし、多くの場合、大規模な微調整が必要でした。これに対して、スケーラビリティ、パフォーマンス、開発者の生産性を向上させ、特定のタイプのアプリケーションの作成を簡素化する新しいデータベース設計が登場してきました。
しかし、これらの新しいデータベース・ソリューションにはトレードオフがつきものです。各設計には妥協が伴い、特定の利点が他の利点を犠牲にして得られます。これらのオプションとトレードオフを理解することは、ニーズに最適なツールを選択するために不可欠です。この記事では、ベクター・データベースについて調べ、従来のリレーショナル・データベースと比較することで、十分な情報を得た上で意思決定を行うことができるようにします。
なぜアプリケーションに特化したデータベースを選ぶのか?
近年、特定のユースケースに特化したデータベースが急増しています:
グラフ・データベース:グラフデータベース:高度に接続されたデータを効率的に保存・分析するために設計されたグラフデータベースは、データポイント間の関係(ナレッジグラフ)を管理することに優れている。
検索データベース**:非構造化または半構造化データを扱い、高速で効率的な検索とクエリに最適化されている。
時系列データベース**:高い書き込みスループットと時間ベースのクエリに最適化された時系列データベースは、頻繁かつ大規模なタイムスタンプ付きデータエントリーを扱うワークロードを処理します。
キー・バリュー・データベース**:高いパフォーマンスとスケーラビリティで知られるキー・バリュー・データベースは、メタデータを追加することなくシンプルなキー・バリュー・ペアとしてデータを保存するため、高速な読み取りと書き込み操作に最適です。
イン・メモリー・データベース**:これらのデータベースはデータをディスク上ではなくRAM上に保存するため、ディスクアクセスの遅延がなくなり、パフォーマンスが大幅に向上します。
ベクター・データベース**:これらのデータベースはベクトル埋め込みを保存するために構築され、計算量の多いセマンティック検索を処理するために最適化されています。
リレーショナル・データベース(RDBMS)の市場シェアは依然として圧倒的であるが、目的別に構築されたデータベースは急速に普及しており、ベクトル、時系列、キーバリュー、グラフ・データベースが過去2年間で最も大きな伸びを示している。
特化型データベースへのシフトは、パフォーマンスと高度な機能に対する要求の高まりによって推進されており、ユーザーはソフトウェアが大手ハイテク企業が設定した高い基準を満たすことを期待している。さらに、マイクロサービス・アーキテクチャの台頭が、特化型データベースの採用を促進している。独立してデプロイ可能で、互いに抽象化されたマイクロサービスにより、チームは他のサービスのテクノロジーに関する広範な知識がなくても、特定のアプリケーション機能に最適なツールを選択できる。
しかし、別のデータベースをアーキテクチャに統合すると、複雑さが増す。特化したデータベースの利点が、コストや複雑さを上回るかどうかを評価することが極めて重要です。アプリケーションに長期的な影響を与える決定を下す前に、長所と短所を徹底的に評価することが不可欠です。
実際には、様々なワークロードやアプリケーションをサポートする統一されたデータ管理システムを実現することは困難です。自動車業界に例えると、SUV、トラック、セダン、スクールバスなど、特定の機能を念頭に設計された、あらゆる用途に対応する1台の自動車を想定することはできません。同じように、データベースの世界でも、システムはさまざまなニーズに応じて最適化されており、万能のソリューションはありえない。将来は、特定の要件に合わせたより専門的なデータベースを開発することになるだろう。多様なデータベースシステムとやりとりするための統一インターフェースやSDKが登場するかもしれませんが、ますます特化したソリューションに向かう傾向は続くでしょう。"Charles Xie, Zilliz.**の創設者兼CEO。
リレーショナルデータベースの概要
リレーショナル・データベースは、伝統的なデータベースとしても知られ、データを表形式で管理する汎用性の高いツールである。行と列で構成されるこの構造は、効率的なデータの保存と検索を可能にし、通常はディスク上で管理される。SQLを使用することで、リレーショナル・データベースの汎用性はさらに高まり、さまざまなクエリをサポートする。この適応性により、リレーショナル・データベースは様々なアプリケーションに適している。リレーショナル・データベースは、データセット間の構造化された関係を強制し、事前に定義されたスキーマによってデータの一貫性と整合性を保証する能力が特に評価されている。
データの格納:行と列
リレーショナル・データベースは、行と列の体系的な配置を利用してデータを格納する。各行は1つのレコードを表し、各列はデータフィールドまたは属性を表す。この体系的な形式により、データへのアクセスや管理が容易になり、ユーザーはデータストアをナビゲートしたり、データベース内の情報を効率的に更新したりすることができる。
クエリー機能
構造化クエリ言語(Structured Query Language:SQL)はリレーショナル・データベースの主な機能で、複雑なデータを抽出・操作するための正確なクエリを作成することができます。SQLは、データをフィルタリング、ソート、検索するための堅牢なフレームワークを提供し、大規模なデータセットに対して複雑な検索や操作を簡単に実行できる。SQLを使用することで、ユーザーは関連情報を素早く特定し、特定の条件に基づいて詳細なレポートを作成することができます。
ACID プロパティ
リレーショナル・データベースのトランザクションは、ACIDとして知られる4つの重要な特性、すなわち原子性、一貫性、分離、および耐久性によって管理されます。原子性は、トランザクションのすべての側面が全体として完了し、部分的な更新が残らないことを保証します。一貫性はデータの完全性を維持し、トランザクションが有効な状態を導くことを保証する。分離は、トランザクションが完全にコミットされるまで互いに影響を及ぼさないようにし、競合を回避する。最後に耐久性は、トランザクションが一度コミットされると、システム障害が発生した場合でも変更が永続的であることを保証する。
ベクターデータベースの概要
では、ベクターデータベースとは一体何なのか?ベクトルデータベースは、ベクトル表現と埋め込みを活用することで、非構造化データを扱うように設計された特殊なシステムである。このアプローチにより、意味情報の迅速な検索と効率的な類似検索が可能になる。
ベクトルデータベースは、現代のAIエコシステム、特にRAG(Retrieval Augmented Generation)において極めて重要である。RAGは、外部の知識を統合することによって、大規模言語モデル(LLM)の性能を向上させ、AIの幻覚を緩和し、生成された応答の精度を向上させる。これらのデータベースは、LLMがより信頼性の高い回答を生成するために使用する文脈情報を管理し、取得する。
LLMは、チャットボット、推薦システム、画像・動画・音声検索などのマルチメディア検索など、さまざまな分野で広く応用されている。
ベクターデータベースとリレーショナルデータベースの比較
従来のリレーショナルデータベースは、構造化されたデータを管理し、あらかじめ定義されたスキーマを使用し、表形式のデータフォーマット内で正確な検索を行うことに優れています。これに対してベクトルデータベースは、画像、音声、動画、テキストなどの非構造化データを高次元ベクトルとして表現することで、そのユニークな処理能力を発揮し、可能性の世界を広げる。行と列を使用するリレーショナル・データベースとは異なり、ベクトル・データベースはデータを多次元のベクトルとして保存し、類似性に基づいてクラスタリングします。
MySQLやPostgreSQLのようなリレーショナル・データベースは、長い間多くの開発者に選ばれてきたが、業界ではベクトル検索機能をこれらのシステムに組み込む方向に顕著にシフトしている。例えば、PostgreSQLのユーザは、ベクトルデータベースの必要性からPgvectorを利用することが多くなっており、データベースを取り巻く環境におけるトレンドの広がりを示しています。
ベクトルベースの操作をサポートするために、リレーショナルデータベースは一般的にHNSW(Hierarchical Navigable Small World) のようなインデックス技術を追加し、ベクトル空間で近似最近傍検索を行います。これは、AI主導のアプリケーションで類似アイテムを見つけるために不可欠である。さらに、これらのデータベースは、従来のデータと一緒にベクトルストレージを提供し、SQLの互換性を維持しているため、ユーザーはベクトルデータの管理とクエリに使い慣れたSQLコマンドを活用できる。
しかし、完全なベクトル検索エンジンではなく、PostgreSQLデータベースのプラグインであるPgvectorとは異なり、MilvusやZilliz Cloudのような専用のベクトルデータベースは、ほぼリアルタイムのパフォーマンスで何十億もの高次元ベクトルを管理し、クエリするために一から構築されています。これらの特化型データベースは、高度なインデックス技術を活用して類似検索を効率的に処理し、類似性に基づく操作に優れたパフォーマンスを提供し、大規模なベクトルデータ管理をサポートします。また、AIや機械学習アプリケーション向けに調整された堅牢なAPIを提供し、複雑で大規模なベクトルデータのニーズに適しています。
ベクターインデックスが重要な理由
プロトタイピングの段階では、すべてのデータをメモリにロードすることが、より高速な処理とより簡単な開発のために一般的です。しかし、本番環境でデータがスケールアップするにつれ、このアプローチは以下の理由により現実的ではなくなります:
メモリの限界:メモリーの制限:メモリーはディスク・ストレージよりも制限され、高価である。
容量の問題**:大きなデータセットは利用可能なメモリーを超える可能性がある。
パフォーマンスへの影響**:すべてのデータをメモリに保存すると、起動時間とリソース消費量が増加する可能性があります。
大規模なデータセットを実運用で効率的に扱うには、適切なインデックス戦略を選択することが非常に重要です。適切なベクターインデックスは、クエリー速度、ストレージの必要性、レイテンシのバランスをとることで、RAG(Retrieval Augmented Generation)アプリケーションのパフォーマンスを最適化します。下図は、3つの主要な指標に基づいて異なるインデックスがどのように機能するかを視覚化するのに役立ち、プロセスにおけるあなたの役割の重要性を強調しています。
Milvusがサポートするインデックス](https://assets.zilliz.com/Indices_Milvus_supports_90b336ba26.png)
1秒あたりのクエリー数(QPS)**:インデックスの1秒あたりのクエリ処理能力を測定し、スループットと効率を示します。
ストレージインデックスに必要なディスク容量を反映し、インフラコストとスケーラビリティに影響します。
レイテンシーアプリケーションの応答性に影響を与えます。
これらの指標を比較することで、ユースケースやパフォーマンスニーズに最も適したインデックスを選択することができます。
Milvusは、様々なストレージ要件やパフォーマンス要件に合わせた柔軟なインデックス選択フレームワークを提供します:
GPUインデックス:GPUインデックス:ハイパフォーマンス環境に最適で、迅速なデータ処理と検索をサポートします。
メモリインデックス**:パフォーマンスとキャパシティのバランスを提供し、1秒あたりのクエリ(QPS)レートに適し、平均レイテンシ約10ミリ秒でテラバイトのストレージまで拡張可能。
ディスク・インデックス**:数十テラバイトのデータを約100ミリ秒のレイテンシで処理し、より大規模で時間的制約の少ないデータセットに適しています。Milvusは、ディスクインデックスをサポートする唯一のオープンソースベクタデータベースとしてユニークである。
スワップ・インデックス**:S3や他のオブジェクトストレージとメモリ間のデータスワップを容易にし、レイテンシを管理しながらコストを約10分の1に削減する。典型的なアクセス時間は約100ミリ秒だが、アクセス頻度の低いデータでは数秒に及ぶこともあり、オフラインでの使用やコスト重視のアプリケーションに適している。
インデックスを選択したら、構築時間、精度、パフォーマンス、リソース使用量に基 づいてそのパフォーマンスを評価する。例えば、最適化されていないインデックスでは、毎秒 20 クエリしかサポートできないかもしれない。一方、最適化されたインデックスでは、チューニングを繰り返すごとに QPS を 10 倍にすることができるが、その分、構築時間が長くなる可能性がある。
インデックスを効果的に選択し、微調整するには
ニーズに基づいてインデックス・タイプを選択する。
パフォーマンスを最適化するためにインデックス・パラメータを調整する。
使用例のベンチマークを行い、期待されるパフォーマンスを確保する。
検索パラメータを調整し、検索結果をさらに向上させます。
最適化プロセスのガイダンスとして、VectorDBBenchのようなベンチマークツールをご利用ください。Zillizによって開発され、オープンソース化されたVectorDBBenchは、様々なベクターデータベースを評価し、最適なパフォーマンスを得るための包括的な実験とシステムの微調整を可能にします。
当社のGPUインデックスカタログの各インデックスの性能を概説したチートシートがクイックリファレンス用に用意されており、アプリケーションに最適なインデックスを導き出すことで、性能とコスト効率の最適化を支援します。
インデックス・チートシート ](https://assets.zilliz.com/An_index_cheat_sheet_a56b4654f2.png)
ベクトル検索のためのリレーショナルデータベースのパフォーマンスベンチマーク
前述のように、伝統的なリレーショナルデータベースは1-2ベクトルインデックスを使用することが多く、大規模なベクトルデータを扱う際に性能の問題につながることがあります。この課題を明らかにするために、VectorDBBench はベクトルデータベースのベンチマーク用に設計されたオープンソースツールです。様々な主流、ベクトルインデックス、データベース、クラウドサービスを評価し、unbiased metricsとしてqueries per second (QPS)、queries per dollar (QP$)、P99 latencyを提供している。
例えば、VectorDBBenchはPgvectorとMilvusやZillizを比較することができます。ベンチマーク結果は一貫して、MilvusとZillizがPgvectorと比較してQPS、スピード、レイテンシにおいて優れたパフォーマンスを提供することを示しています。
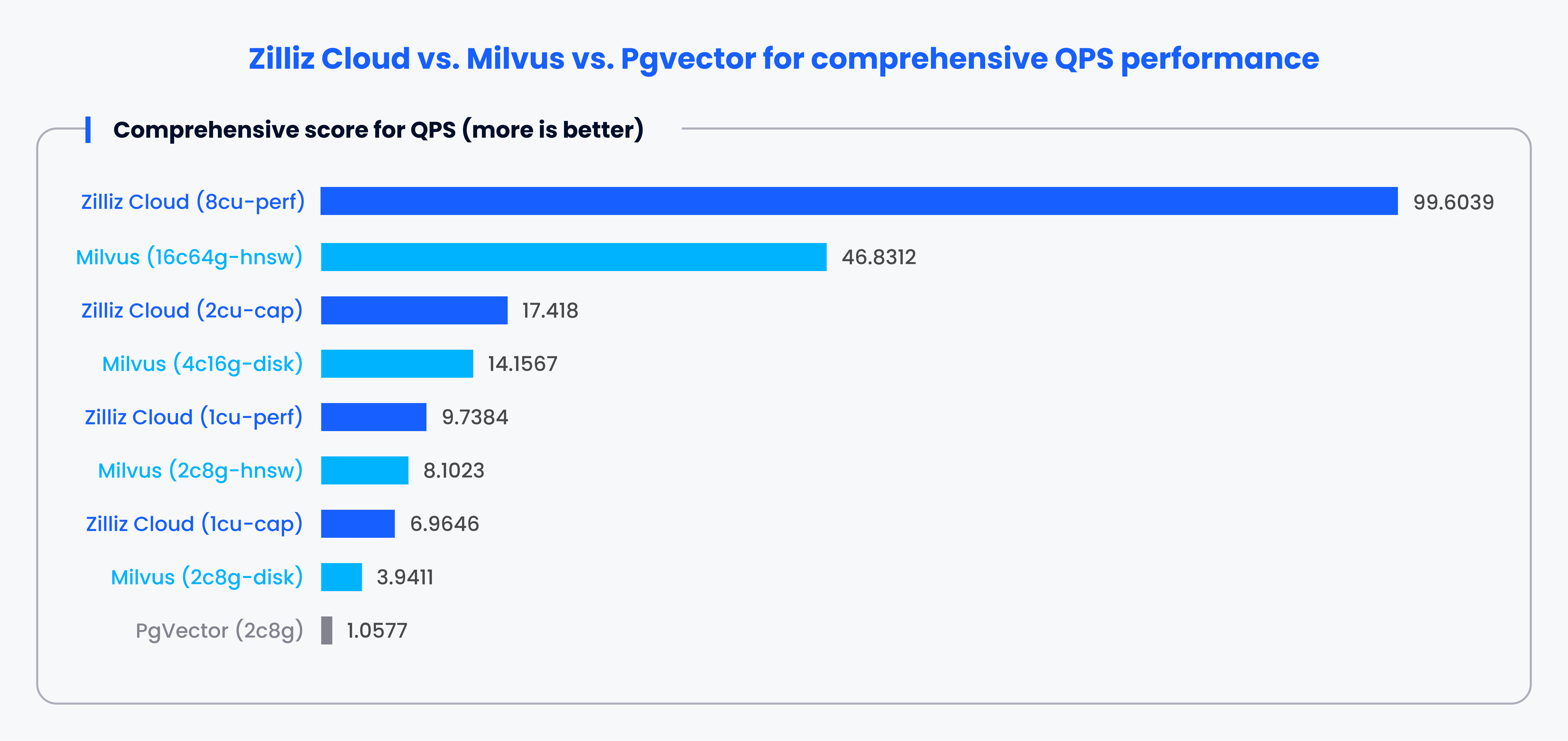
注: これは、特定のルールに従ったさまざまなケースにおける各システムの性能に基づく1~100のスコアです。スコアが高いほどパフォーマンスが高いことを示す。
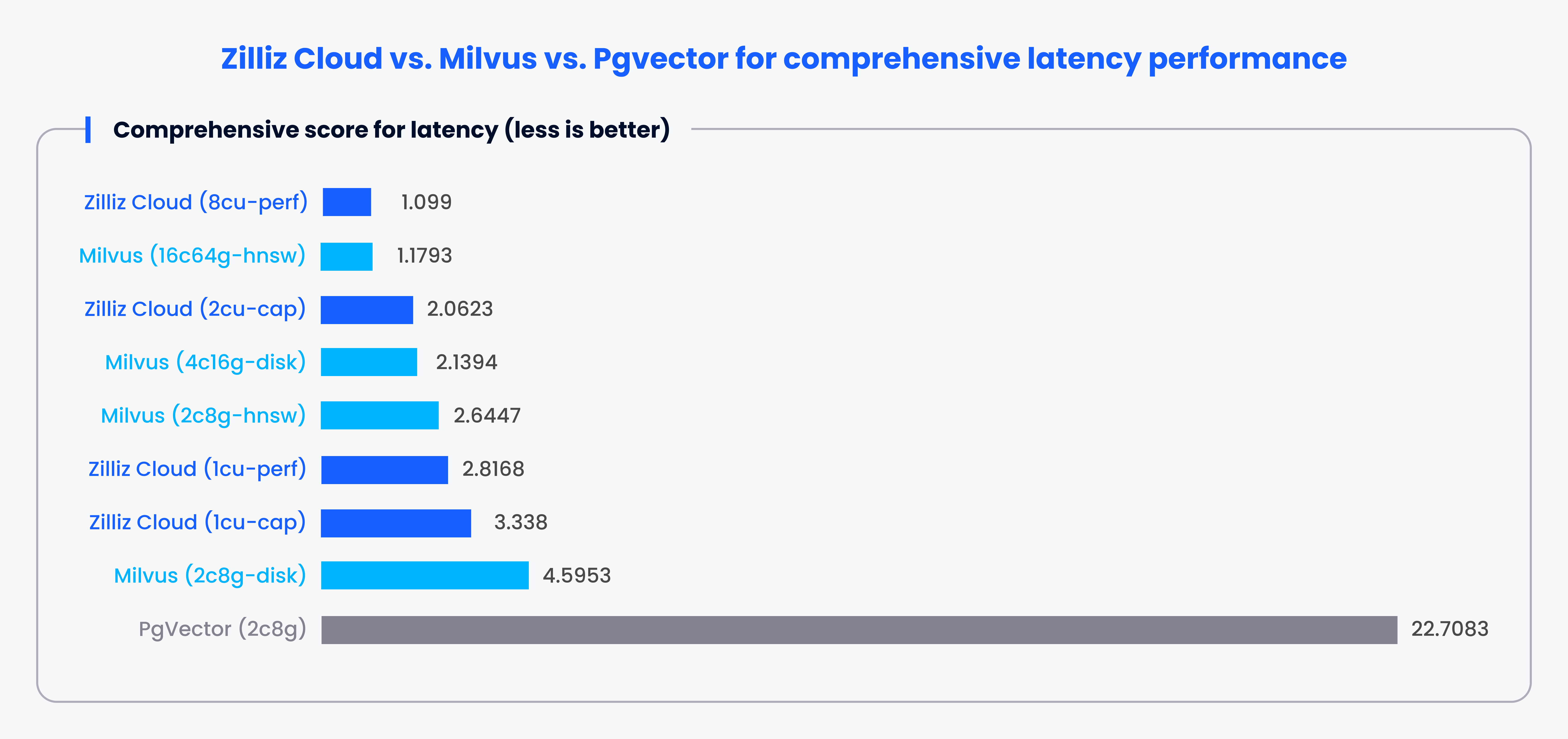
注: これは、特定のルール に従った さまざまなケース における各システムのパフォーマンスに基づく >1 スコアです。スコアが低いほどパフォーマンスが高いことを示す。
VectorDBBenchを使用すると、様々なメトリクスの観点から、どのデータベースがより良いパフォーマンスを発揮するかを素早く理解することができます。また、どのデータベースがあなたの特定のニーズに最も適しているかを判断することもできます。
ベクターデータベースの使用例
従来のデータベースは主にトランザクションの処理、在庫の追跡、または給与管理に使用されますが、ベクターデータベースはAIを活用した素晴らしいユースケースの開発をサポートすることに優れています。
検索拡張世代(RAG)**。
外部データ・ソースをLLMやAIアプリケーションに組み込むことで、LLMの知識を拡張します。
レコメンダーシステム
ユーザーの過去の行動や嗜好に基づいて、情報や商品を推薦する。
マルチモーダル類似検索
テキスト、ビデオ、オーディオ、画像など、異なるモダリティを横断してクエリを実行します。
分子類似度検索
指定した分子の類似した部分構造、上部構造、その他の構造を検索します。
結論ベクターデータベースとリレーショナルデータベースの比較
アプリケーションに適したデータベースを選択することは、重要であるばかりでなく、不可欠である。リレーショナル・データベースは、構造化されたデータの管理やSQLによる複雑なクエリの実行に強い。対照的に、ベクトル・データベースは非構造化データや高次元の検索を扱うように設計されており、AIや機械学習のタスクにより優れたパフォーマンスを提供する。この決断の重みは、いくら強調してもしすぎることはない。
高度な索引付けと検索機能を持つベクターデータベースは、大規模な高次元データの処理において、しばしば従来のリレーショナルデータベースを凌駕する。しかし、特殊なベクターデータベースを追加すると、セットアップが複雑になる可能性があります。
適切なインデックス戦略を選択し、VectorDBBenchのようなベンチマークツールを使用することで、パフォーマンスを最適化し、ニーズに最適な選択をすることができます。
データベース・ソリューションとパフォーマンスの詳細については、Zilliz Cloudをご覧ください。

読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.