




チャンクレベルのデータ分割による安全なRAGワークフローの構築
ベクターデータベースは、AI駆動型アプリケーション、特にRAG(検索拡張世代)を強化するための基礎となっており、膨大な高次元データセットを高速かつ効率的に類似検索できる。このようなデータベースが数十億のベクトルを収容する規模になると、効果的なパーティショニングが重要になる。データを論理的なセグメントに整理することで、パーティショニングはクエリのパフォーマンスを向上させ、スケーラビリティをサポートし、マルチユーザー環境におけるテナントごとの分離によって安全なデータ管理を保証する。
Milvus](https://zilliz.com/what-is-milvus)やZilliz Cloud(マネージドMilvus)のような最新のベクトルデータベースは、エンタープライズアプリケーションの需要に対応するために高度なパーティショニング機能を導入しています。しかし、パーティションの数が増えるにつれ、それらを効果的に管理する複雑さも増しています。企業は今、AIワークフローとシームレスに統合しながらパーティショニングを拡張できるプライバシー優先のソリューションを求めている。
先日Zillizが主催したSouth Bay Unstructured Data Meetupで、Caber SystemsのCEO兼共同設立者であるRob Quirosは、ユーザーごと、チャンクごとのアクセスポリシーを使用してベクトルデータベースをパーティショニングする革新的なアプローチを共有した。彼は、パーティションにパーミッションとオーソライゼーションを統合することで、データをチャンクレベルでセキュアにし、プライバシーの問題に対処する方法について詳しく説明した。このブログでは、彼の洞察を振り返り、Caber SystemsがMilvusベクトル・データベースを活用して、堅牢でプライバシーを重視したデータ管理を実現する方法を探ります。詳しくは、YouTubeで講演のリプレイをご覧ください。
ベクターデータベースにおけるアクセス制御の課題Milvus](https://zilliz.com/what-is-milvus)のような最新のベクターデータベースは、マルチテナントを効果的にサポートしており、顧客データセットを個別に保存・管理することができます。この機能により、あるテナントのデータは分離され、他のテナントからはアクセスできないようになり、安全で組織的なデータ管理のための強固な基盤が形成される。しかし、このような分離は包括的なデータの分離には適していますが、これらのデータセット内できめ細かなユーザー固有のアクセス制御を実装することはより困難です。これは、企業が必要とするアクセス・コントロール・モードが多様であるためです。
その中には以下のようなものがある:
役割ベースのアクセス制御(RBAC)** - あらかじめ定義された役割に基づいてアクセス許可を割り当てますが、複雑で動的な要件に苦労します。
属性ベースのアクセス制御(ABAC)** - ユーザーの役割、データの機密性、地理的位置などの属性を使用するが、堅牢なポリシー管理システムが必要。
関係ベースのアクセス制御(ReBAC)** - 部署やチーム間の関係に基づいてアクセスを提供するため、実施メカニズムが複雑になる。
さらに、このようなアクセス・コントロールの提供と管理は、管理者にとって悪夢となる可能性があります。アクセス許可の割り当てからアクセス要求や係争の処理に至るまで、運用上のオーバーヘッドはサポートチームを圧倒することもある。下の図はPermit.ioによるReBAC制御の例である。これは、進行中のセッション中にのみ有効な特定のデータチャンクにアクセスするための複雑なプロセスを示している。
図:ReBAC制御の例](https://assets.zilliz.com/Figure_An_example_of_Re_BAC_control_b26a49a0ed.png)
図:ReBAC制御の例ReBAC制御の例
データアクセスにおけるエージェントの役割
RAGシステムでは、ユーザーの代わりに行動するエージェントがベクトルデータベースに問い合わせ、情報を取得する。エージェントはタスクを自動化することで効率を向上させるが、セキュリティ上の大きな課題をもたらす。エージェントはユーザーのアクションのプロキシとして動作するため、データアクセス中のユーザー権限を継承する。しかし、このメカニズムは攻撃に対して脆弱である:
エージェントのなりすましである:エージェントのなりすまし:悪意のあるアクターはエージェントになりすまし、ユーザーの認証情報を悪用して機密データにアクセスすることができます。
データ漏洩:*** エージェントのセッションが侵害された場合、膨大な量のデータへの不正アクセスを許可する可能性がある。
図:エージェント型RAGのセキュリティ問題 ](https://assets.zilliz.com/Figure_Security_issues_with_Agentic_RAG_f7432846d0.png)
図:エージェント型RAGのセキュリティ問題
これらのリスクを軽減するために、組織は厳格な対策を採用しなければならない:
認証:認証:身元を確認し、なりすましを防ぐための強力なエージェント認証。
セッション管理:*** Rebackが示したように、エージェント・セッションをあらかじめ定義された期間に制限する。
ロギングとモニタリングエージェントの活動を追跡し、異常を検出するための包括的な監査証跡。
これらの対策を講じることは攻撃への対処に役立つが、すべてを実施するのは非常に面倒である。
データの重複 - 企業にとっての重大な課題
データの重複は、企業環境における根強い問題である。ドキュメントはコピー・ペースト、ファイル共有、バージョ ニングによって何度も繰り返され、ベクター・データベースに冗長なチャンクが保存されるこ とがよくあります。この重複はストレージのオーバーヘッドを増大させ、LLMの汎用性を低下させる。Rob氏は、以前Riverbed社でデータ重複排除を行った経験について言及している。そこでは、データの90〜95%が重複しており、これを排除しなければならなかった。
図:データの重複はパーミッション設定における大きな課題である】(https://assets.zilliz.com/Figure_Data_duplication_is_a_big_challenge_in_setting_permissions_3c787d5f84.png)
図:データの重複は権限設定における大きな課題である
パーミッションを含むメタデータがドキュメントからベクターデータベースのチャンクに直接コピーされる場合、大きな複雑さが生じる。パーミッションが異なるドキュメント間でチャンクが重複して存在する場合、メタデータが上書きされ、コンフリクトや不適切なアクセス制御を引き起こす可能性がある。したがって、チャンクレベルでパーミッションを解決することは、データセキュリティとコンプライアンスを確保する上で極めて重要です。
以下はAppleの10-Qステートメントの例ですが、両文書の定型文は共通しており、バージョン間の違いは最小限であることがわかります。従って、ここでのゴールは、正しいアクセス・ルールを一貫して適用できるように、データ・チャンクとそれに関連するパーミッションの起源を特定し、追跡することです。
図:Appleの10Q提出書類の類似文書の例](https://assets.zilliz.com/Figure_Example_of_similar_documents_from_Apple_s_10_Q_filings_82dd61409a.png)
チャンクレベルでのデータ保護
これらの問題に対処するため、Caberはチャンクレベルでデータを保護するソリューションを提案した。これは、ベクターデータベースに取り込まれたドキュメントに注目し、チャンクとそのソース間の関係をマッピングするインデックスをサイドに構築することで実現する。この系統グラフは、各チャンクのソースと関連するパーミッションを可視化し、パーミッションの決定論的な割り当てを可能にする。
図-チャンクレベルでデータを保護するCaberのアプローチ](https://assets.zilliz.com/Figure_Caber_s_approach_to_secure_data_at_the_chunk_level_780f6cef27.png)
図チャンクレベルでデータを保護するCaberのアプローチ (出典)
アップルの10Qファイリングによるリネージグラフの例
アップル社の例を続けると、以下のグラフはアップル社の10-Q提出書類の複数のバージョンからのデータチャンクを含んでいます。グラフの赤いノードは、すべての文書に共通するデータチャンクを表しています。ポリシーを使用して、これらのチャンクのそれぞれのパーミッションが決定されます。これらのパーミッションは、データがベクターデータベースから取得される際に参照され、ユーザーがこれらのチャンクにアクセスするための適切な権限を持っていることを確認します。
図:Caberによるパーミッションのための各チャンクの系統の動的マッピング](https://assets.zilliz.com/Figure_Dynamic_mapping_of_the_lineage_of_each_chunk_for_permissions_with_Caber_dabe5c4212.png)
アップルの10Qファイリングを使ったRAGデモの例
当初、データはパーミッションのメタデータなしでMilvusのようなベクターデータベースに保存される。RAGからデータが出てくるとき、SDKを通してワークフローに統合されたCaberは、LLMにデータを渡す前に、粒度レベルでこのデータのフィルタリングと再編集を可能にする。例えば、この図は2つの異なるユーザーに対するアクセス権限を示しています。一方、別のユーザーであるBobは、同じアクセスに制限されており、一般的な回答を受け取っています。
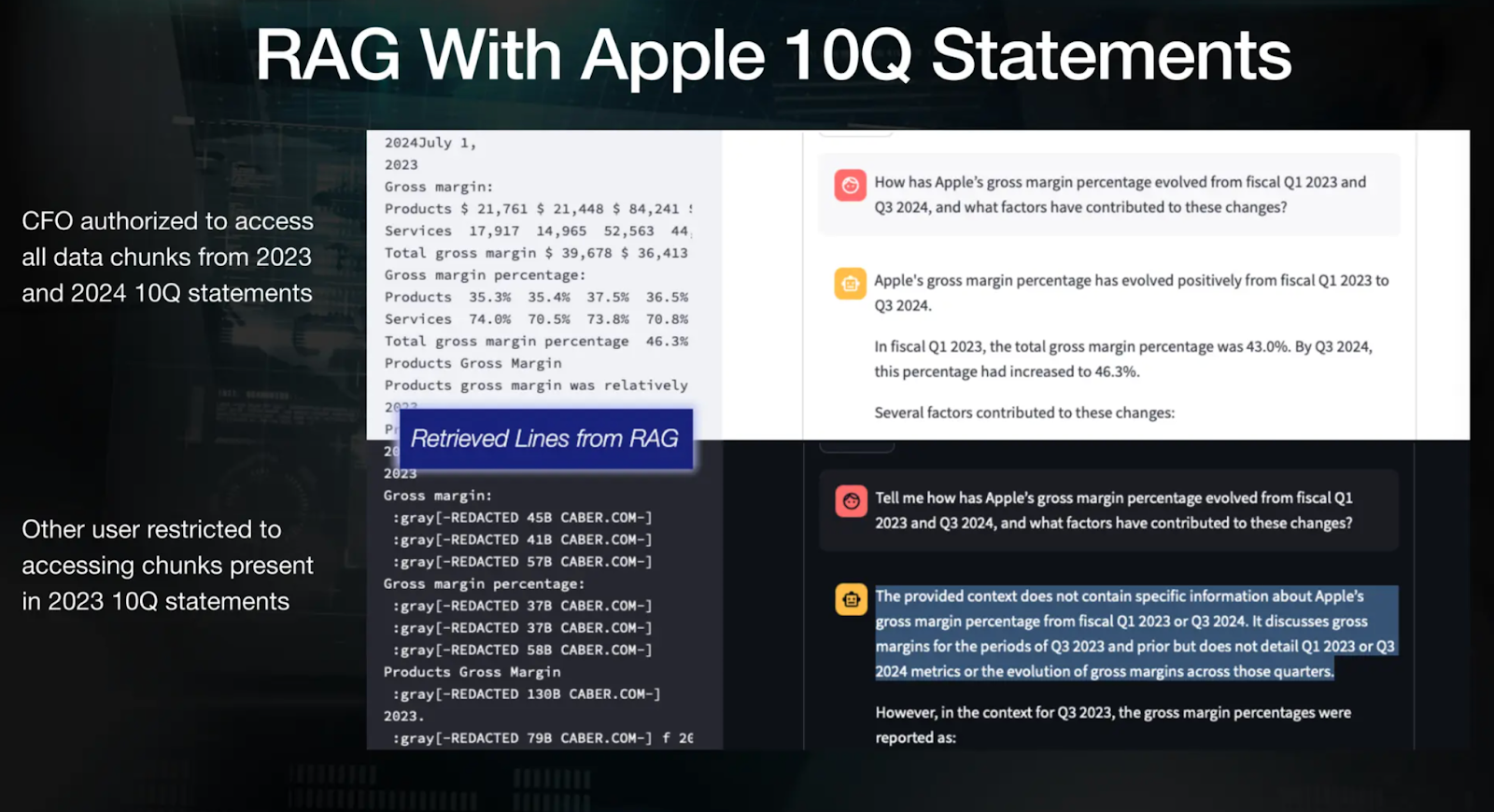 図: 2人のユーザーのアクセス権の違いを示すRAGの例
図: 2人のユーザーのアクセス権の違いを示すRAGの例
LLMワークフローとCaberの統合とその機能
図:CaberとLLMワークフローとの統合 ](https://assets.zilliz.com/Figure_Caber_integrates_with_LLM_workflows_805e582b7e.png)
Caberは、SDKを利用してLLMワークフローと統合することができ、シームレスなアクセス制御管理が可能です。IDコネクターを通じて、システムはユーザー認証情報を取得し、他のコネクターはデータチャンクのインデックスと関連するパーミッションの構築を支援する。例えば、ユーザーがシステムとインタラクトすると、エージェントはプロンプトをベクターデータベースに渡します。RAGレスポンスは、最終的な回答を提供するLLMに送られる。このプロセスの間、データはそのフローに基づいてトレースされ、すべての接続は特定のユーザーに帰属する。
ここで、ベクトルデータベースとしてMilvusを使用することで、動的なパーティショニングとマルチテナンシーをサポートすることができ、チャンクごとのアクセス制御を必要とするプライバシー重視のアプリケーションに最適です。HNSW](https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW)のようなインデックス機能により、何十億ものベクトルに対して高速なクエリを保証します。
説明責任と監査可能性
Caberが提供するトレーサビリティは、重要な説明責任と監査機能を提供する。特に、LLMがユーザーの代わりに自律的に行動するエージェントAIを含む複雑なシナリオでは、行動がかなり予測不可能であるため、何か問題が発生する可能性が高い(例えば、機密データが漏れるなど)。ここで、様々なAPIやオブジェクトの呼び出しを通じてデータがどのように移動したかという知識は、システムがどのステップで失敗したかを正確に知るために不可欠です。
図:説明責任と監査可能性 ](https://assets.zilliz.com/Figure_Accountability_and_Auditability_e14dfee343.png)
アプリケーションフローの詳細な観測可能性
Caberはまた、アプリケーション・フローの詳細な観察可能性によって、アプリケーション・ツールの分析とデバッグを可能にする。ユーザーのデータがいつ、どのサービスによってアクセスされたかを追跡できるため、企業はアプリケーションのデータパイプライン内のボトルネック、非効率性、セキュリティリスクをより的確に特定できる。
図:アプリケーションフローの観測可能性](https://assets.zilliz.com/Figure_Observability_of_Application_Flow_ef9a19f31a.png)
データのコンプライアンス要件とポリシー
以上から得られた洞察は、セキュリティ・ポリシーを改善し、ギャップに積極的に対処するために、LLM にフィードバックすることができる。このフレームワークは、アクセス制御、監査可能性、修復、分析をサポートし、コンプライアンスを確保し、システムの回復力を強化する。
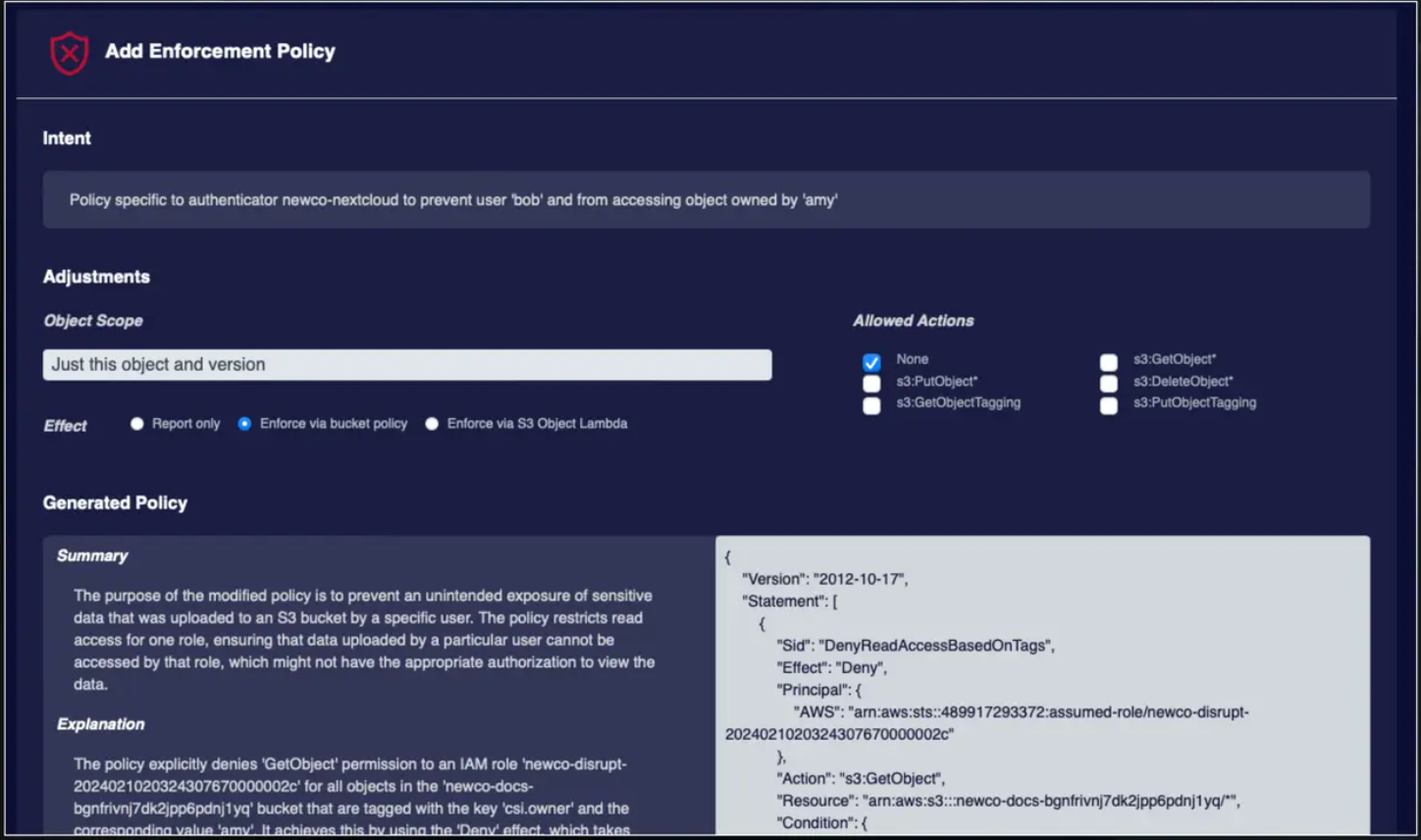 ポリシーへのデータ・コンプライアンス要件.png
ポリシーへのデータ・コンプライアンス要件.png
ポリシーに対するデータコンプライアンスの要件 (ソース)
結論
LLMアプリケーションのユースケースが増えるにつれて、より多くの企業がRAGに依存している。したがって、きめ細かなレベルでのデータアクセスの保護と管理が非常に重要になる。CaberのようなソリューションとMilvusの高度なパーティショニングや検索機能を組み合わせることで、データの重複やデータを安全に利用するためのアクセス制御の設定といった課題に取り組むための理想的なフレームワークを提供することができる。
関連リソース
RAGアプリ構築のベストプラクティス ](https://zilliz.com/blog/best-practice-in-implementing-rag-apps)
この無料計算機でRAGパイプラインの構築コストを素早く見積もる](https://zilliz.com/rag-cost-estimator/)
高度なRAGテクニック:テキストとビジュアルの橋渡し](https://zilliz.com/blog/advanced-rag-techniques-bridging-text-and-visuals-for-accurate-responses)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
RAGを知識グラフで強化するGraphRAGとは](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
RAGアプリケーションの評価方法](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.