




RAGアプリケーションを構築する開発者のための実践的なヒントとコツ
ベクトル検索は楽ではない
ベクトル検索は、ベクトル類似検索または最近傍検索としても知られ、RAGアプリケーションや情報検索システムのデータ検索において、与えられたクエリベクトルと類似または密接に関連するアイテムまたはデータポイントを見つけるために使用されるテクニックである。大規模なデータセットを扱う場合、この手法は簡単であるとして販売されることが多い。一般的な認識では、データを埋め込みモデルに入力してベクトル埋め込みを生成し、これらのベクトルをベクトルデータベースに転送するだけで、目的の結果を取り出すことができる。
ベクトル検索の方法](https://assets.zilliz.com/how_to_perform_a_vector_search_5a16e223d0.png)
多くのベクトルデータベースプロバイダーは、"簡単"、"ユーザーフレンドリー"、"シンプル "といった表現で、その機能を宣伝しています。彼らは、機械学習、AI、ETLプロセス、詳細なシステムチューニングなどの複雑さを回避し、わずか数行のコードで重要な成果を達成できると主張している。
そして彼らは正しい。ベクトル検索は、NumPyのような基本的な数値計算ライブラリを使うのと同じくらい簡単なのだ。このコンセプトを実証するために、私はk-nearest neighborsアルゴリズム(KNN)を使って、わずか10行のPythonコードで短いデモを書いた。この単純なアプローチは、1000または10000ベクトルまでのデータセットによる小規模なアプリケーションに効果的で正確である。
npとしてnumpyをインポートする。
# ユークリッド距離を計算する関数
def euclidean_distance(a, b):
return np.linalg.norm(a - b)
# KNN を実行する関数
def knn(data, target, k):
# ターゲットとデータ内のすべての点間の距離を計算する
distances = [euclidean_distance(d, target) for d in data] # 距離をデータのインデックスと結合する。
# 距離とデータインデックスを結合
distances = np.array(list(zip(distances, range(len(data)))) # 距離でソートする。)
# 距離でソート
sorted_distances = distances[distances[:, 0].argsort()] # 距離でソートする。
# 最も近い上位k個のインデックスを取得
close_k_indices = sorted_distances[:k, 1].astype(int)
# 上位k個の最も近いベクトルを返す
return data[closest_k_indices].
しかし、データセットが100万、1000万ベクトルを超えるようなささやかなレベルまで大きくなると、このアプローチは機能しません。なぜなら、実世界のアプリケーションはユーザーとのインターフェイスが必要であり、利用可能でなければならず、常に複雑だからです。スケーラブルな実世界のアプリケーションを構築するには、検索品質、スケーラビリティ、可用性、マルチテナンシー、コスト、セキュリティなど、コーディング以外のさまざまな要素を徹底的に考慮する必要がある!
だから、正直になろう。"私のマシンでは動く "という格言を覚えているだろうか?ベクター検索も同じで、プロトタイプは常に動作します。本番でのベクター検索は複雑なことが多いので、本番でベクター検索を搭載したアプリケーションを構築するためのベストプラクティスは何でしょうか?
このような課題を解決するために、Milvusを使ってRAGアプリケーションの本番環境にベクターデータベースを効果的に導入するための3つの重要なヒントをご紹介します:
効果的なスキーマの設計:効果的なスキーマを設計する:パフォーマンスとスケーラビリティを最適化するスキーマを作成するために、データ構造とそれがどのようにクエリされるかを慎重に検討してください。
スケーラビリティのための計画**:将来の成長を予測し、データ量とユーザー・トラフィックの増加に対応できるようにアーキテクチャを設計する。
最適なインデックスを選択し、パフォーマンスを微調整する:ユースケースに最適なインデックス作成方法を選択し、パフォーマンス設定を継続的に監視・調整します。
これらのベスト・プラクティスに従うことで、堅牢で効率的なベクトル検索搭載アプリケーションを構築する道が開けます。以下のコメント欄で、あなたの経験や役に立ったその他のヒントを共有してください!
効果的なスキーマ戦略の設計
スキーマは、テーブル、フィールド、リレーションシップ、データタイプを含むデータベースの構造を定義します。この体系化されたフレームワークにより、データが一貫性を持って予測可能に保存され、管理、クエリ、メンテナンスが簡素化されます。適切なスキーマを選択することは、Milvusのようなベクトルデータベースにとって特に重要です。Milvusはベクトルや、メタデータやスカラーデータを含む様々な構造化データ型を扱います。このデータはフィルタリング検索を強化し、全体的な検索結果を向上させることができる。このセクションでは、最も効果的なスキーマ戦略を選択する際に考慮すべき重要な要素を探ります。
動的スキーマと固定スキーマの比較
データベースシステムにおいて、動的スキーマと固定スキーマはデータを構造化するための2つの主要なアプローチを表しています。動的スキーマは柔軟性を提供し、大規模なデータ整列やETLプロセスを必要とせずにデータの挿入や検索を簡素化します。このアプローチは、迅速なデータ構造の変更を必要とするアプリケーションに最適です。一方、開発者は、そのコンパクトな記憶形式のおかげで、パフォーマンス効率とメモリ節約のために固定スキーマを高く評価しています。
ハイブリッドスキーマアプローチは、効率的なベクトルデータベースアプリケーションを開発する開発者にとって有益です。この方法は、重要なデータ経路に対する固定スキーマの堅牢性と、多様なユースケースに対応する動的スキーマの柔軟性を兼ね備えている。例えば、レコメンダーシステムでは、商品名や商品IDのような要素はコンテキストによって重要度が変わる可能性がある。ハイブリッドスキーマを採用することで、開発者は変化するデータ要件に適応する能力を維持しながら、必要なところで最適なパフォーマンスを確保することができます。
主キーとパーティションキーの設定
プライマリ・キーとパーティション・キーはベクトル・データベースにおける2つの重要な概念です。Milvus](https://zilliz.com/what-is-milvus)のベクターデータベースを例にして、これらのキーがベクターデータベース内でどのように機能するのかを掘り下げてみましょう。
Milvusのアーキテクチャはデータをいくつかの要素に分割しています。固定フィールドと動的フィールド(ペイロードと総称されます)、強制ベクトルフィールド、そしてタイムスタンプやUUID(universally unique identifiers)のようなシステムフィールドがあり、これらは従来のリレーショナルデータベースに見られるものと似ています。
プライマリキー:** Milvusではプライマリキーは一意な識別子として機能することが多く、RAGのユースケースではチャンクIDに適用されることがある。このキーは頻繁にアクセスされ、自動生成するように設定することができます。このキーはデータベース内の特定のデータエントリを素早く検索する役割を果たします。
パーティションキー:** Milvusでコレクションを作成する際、パーティションキーを指定することができます。このキーにより、Milvusはデータエンティティをそのキー値に基づいて異なるパーティションに格納し、データを管理可能なセグメントに効果的に整理することができます。パーティション・キーについて簡単に考えるには、フィルタリングしたいデータセットがある場合にパーティション・キーの使用を検討することです。例えば、マルチテナントの状況ではデータの分離と効率的な配布が必要であるため、別々のパーティションに格納することでこれを実現できる。パーティション・キーはスケーラビリティにも有効で、ハッシングによってデータをシャードに分割することで、データベースは大規模なユーザー・ベースやマルチテナントをより効率的に管理できるようになる。
プライマリー・キーもパーティション・キーも、ベクター・データベースの構造的完全性と運用効率を維持するための基本であり、膨大なデータセットを扱い、迅速なデータ・アクセスと検索を実現するために不可欠なものである。
ベクター埋め込みタイプの選択
RAGアプリケーションのためにベクトル埋め込みを選択する場合、ベクトル作成に適したMLモデルを選択すること、そして**利用可能な様々な埋め込みタイプ(密埋め込み、疎埋め込み、バイナリ埋め込み)を理解することが必須です。
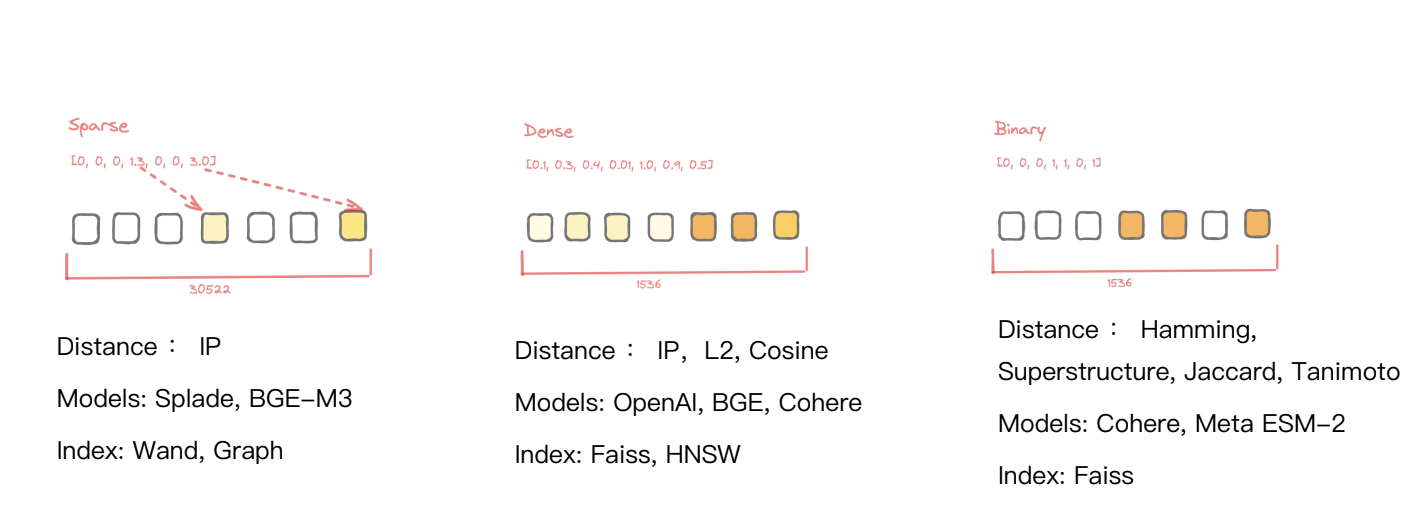 ベクトル埋込みの3つの一般的なカテゴリ
ベクトル埋込みの3つの一般的なカテゴリ
Dense Embeddings**](https://zilliz.com/learn/sparse-and-dense-embeddings) は、意味的類似性検索のためのベクトルデータベースアプリケーションで最もよく使われるタイプです。これらは、その頑健性と様々なデータ型への汎用性で知られています。一般的な密埋め込みモデルには、OpenAI、BGE、Cohereなどがあります。
疎埋め込み**](https://zilliz.com/learn/enhancing-information-retrieval-learned-sparse-embeddings)は、領域外のデータを効率的に検索できることで人気を集めている。最近のSpladeやBGE M3のようなモデルの進歩は、異種検索における有用性を高めており、多様なアプリケーションのための汎用的な選択肢となっている。
バイナリ埋め込み**は、バイナリ形式(0と1)であることが特徴で、メモリ効率が良いように設計されており、タンパク質配列決定のような特殊なユースケースに最適です。Meta ESM-2のようなモデルは、一般的にこれらのエンベッディングを生成するために使用され、特定の検索ニーズに的を絞ったソリューションを提供します。
RAGアプリケーションの検索結果の精度を保証するためには、密な埋め込み以上のものを使用する必要があります。したがって、異なるベクトル埋め込みタイプを効率的かつ効果的に検索するために、異なるインデックス作成アルゴリズムをサポートするソリューションを見つける必要があります。Milvusは、密、疎、バイナリ、さらには疎と密のハイブリッド埋め込みを管理するための様々なインデックスをサポートしており、様々なデータ次元にわたる効率的な検索を可能にし、ベクトルデータベースアプリケーションにおける最適なパフォーマンスを保証します。
スキーマの設計:実践例
検索結果の精度を高めるスキーマ・アーキテクチャを効果的に設計するために、先ほど確認したこれらの要素をまとめてみよう:
フィールド名|タイプ|説明|値の例 --- | --- | --- | --- chunkID|Int64|プライマリキー、ドキュメントの異なる部分を一意に識別|123456789 userID|Int64|パーティションキー、単一のuserID内で検索が行われるようにuserIDに基づいてデータ分割が行われる|987654321 docID|Int64| 文書のユニークな識別子、同じ文書の異なるチャンクを関連付けるために使用される|555666777 chunkData|varchar| 数百バイトのテキストを含む文書の一部。 dynamicParams|JSON| 名前やソースURLなど、ドキュメントの動的パラメータを格納する。| {"name":"Example Document", "source":"example.com"}など。 sparseVector|Specific format|スパースベクトルを表すデータ。特定のフォーマットでは、スパース性を表すために特定の位置にのみ非ゼロ値を持つ。| [0.1, 0, 0, 0.8, 0.4] 密なベクトルを表すデータ。特定のフォーマットは、それぞれに値を持つ固定の次元数を持つ。| [0.2, 0.3, 0.4, 0.1]
典型的な検索拡張世代(RAG)アプリケーションのスキーマデモ
このスキーマを調べると、主キーとベクトル・フィールドを超える追加フィールドの存在に気づくだろう。これらの追加フィールドは、ベクターデータベースを構築し、活用する上で役割を果たします。詳しく見ていきましょう:
**基本中の基本です:主キー(chunkID)と埋め込みフィールド(denseVector)です。
マルチテナンシーサポート:userID`の追加により、ソリューションのテナントごとにデータを分割するフィールドを追加しました。この追加により、ユーザーごとのデータアクセスの分離と管理が可能になり、セキュリティとパーソナライゼーションが強化されます。
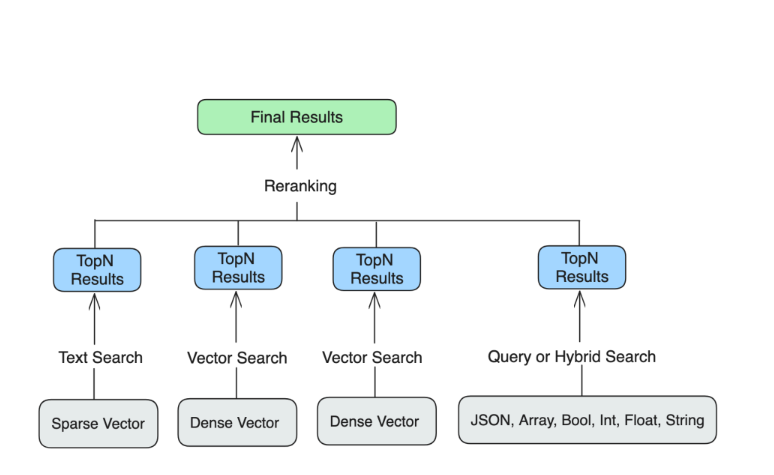
検索結果の絞り込み:この絞り込みのために、他にもいくつかのフィールドを追加しました:
- docID
:このフィールドはチャンクのオリジンを示し、Milvusのグルーピング検索機能を活用するために使用することができます。この例では、ドキュメントをチャンクに分割し、代表ベクトルの埋め込みをdenseVectorフィールドに格納し、このフィールド(docID)に関連するドキュメント情報を格納している。search()操作にgroup_by_field` 引数を含めることで、ドキュメントIDによって結果をグループ化し、類似した文章やチャンクではなく、関連するドキュメントを検索することができる。これにより、同じドキュメントから別々のチャンクを検索するのではなく、関連するドキュメントを検索することができる。 - dynamicParams`:このフィールドはフィルタリングすることができ、ニーズに合ったデータを管理・取得することができる。ドキュメント名やソースURLなど、メタデータの宝庫である。複数のキーと値のペアを1つのフィールドに格納するために、フィールドjsonを設定します。
- sparseVector`:このフィールドはチャンクのスパース埋め込みを保持する。ANN検索を実行し、スパースベクトルに関連付けられたスカラー値に基づいて結果を取り出すことができる。
この図は、別々のクエリから結果を集め、検索結果を絞り込むために再ランク付けできることを示している。
これらの追加フィールドを含むスキーマを設計することで、RAGアプリケーションの要件に対応した、より堅牢で柔軟なベクトルデータベースを作成することができます。従来のデータ管理と検索技術を取り入れながら、ベクトル検索の強みを活用することができます。
スケーラビリティの計画
MVP RAGアプリケーションで成功を収めたら、本番展開の準備を始めましょう。これには、将来の成長を予測し、データ量やユーザートラフィックの増加に対応できるようにアーキテクチャを設計することが含まれます。
アプリケーションを効果的に拡張できるようにするためには、ベクトルデータベースにおけるスケーラビリティが、従来のリレーショナルデータベースと比較してユニークな課題をもたらすことを認識する必要があります。この設定は、主に2つの問題を引き起こします。インデックス速度の低下と、頻繁な更新によるインデックス品質の低下です。
Milvusのシャーディング戦略](https://assets.zilliz.com/The_sharding_strategy_of_Milvus_0cb60d125e.png)
Milvusは、データセット全体を管理可能なセグメントに分割することで、このような課題に対処することができる。これにより、遅延更新を実行したり、不安定になったセグメントをコンパクトにしたりすることができ、一貫した検索品質を維持することができる。このセグメンテーションは効果的な負荷分散を促進し、クエリをすべての処理コアに均等に分散させることができる。
パーティションをマルチテナンシーに使用することで、検索がパーティションに関連するデータに限定されるため、スケーラビリティとパフォーマンスも向上する。このアプローチはデータを効果的に整理し、適切なユーザーに可視性を制限することでセキュリティとプライバシーを強化する。さらに、Milvusは1つのコレクションで最大100億のデータポイントを効率的に管理できる。すごい量だ!
テナント数が10,000以下のマルチテナント・アプリケーションでは、コレクションごとにデータを管理することで、より大きなデータ管理が可能になります。しかし、パーティション・キーは、数百万人のユーザーを持つサービスのデータを動的にセグメント化することで、無制限のテナントを効果的にサポートすることができます。
Milvusは、大量のクエリを簡単に処理できるように設計された分散システムです。そして最大の特徴はノードを追加するだけで、パフォーマンスが大幅に向上し、アプリケーションの可能性が広がります。当初は大規模なリソースを必要としない小規模なデータセットの場合、メモリーのリザーブ(通常、現在の割り当て量の2~3倍)をスケールアップすることで、1秒あたりのクエリー数(QPS)を実質的に倍増させることができます。このスケーラブルなフレームワークにより、データの増加に伴ってデータベース機能も成長し、全体として効率的で信頼性の高いパフォーマンスが保証されます。
インデックスの選択、評価、チューニング
プロトタイプの段階では、すべてのデータをメモリにロードすることが、より高速な処理と容易な開発のために一般的です。しかし、本番稼動に移行し、データが大きくなってくると、すべてをメモリに格納することは不可能になってきます。これは以下の理由からです:
メモリーには限りがあり、ディスク・ストレージに比べて高価である。
大きなデータセットは、利用可能なメモリー容量を超える可能性がある。
すべてのデータをメモリにロードすると、起動時間とリソース消費量が大幅に増加する可能性があります。
大規模なデータセットを本番環境で効率的に扱うには、適切なインデックス戦略を選択する必要があります。適切なインデックスを使用することで、RAGアプリケーションのクエリー速度、ストレージ要件、レイテンシなどのパフォーマンスを最適化することができます。
Milvusがサポートするインデックス](https://assets.zilliz.com/Indices_Milvus_supports_90b336ba26.png)
この図は、3つの主要な指標に基づく様々なインデックスの違いを視覚化するのに役立ちます:
1秒あたりのクエリー数(QPS):これはインデックスが1秒間に処理できる検索クエリの数を測定し、そのスループットと効率を反映します。
ストレージ:インデックスを保存するのに必要なディスク容量を表し、インフラコストやスケーラビリティに影響する。
レイテンシ:1つのクエリを処理して結果を返すのにかかる時間を指し、アプリケーションの応答性に影響します。
異なるインデックス間でこれらの指標を比較することで、特定のユースケースとパフォーマンス要件に最も適したインデックスを決定することができます。
Milvusでは、様々なストレージとパフォーマンスのニーズに合わせた柔軟なインデックス選択フレームワークを提供しています:
GPUインデックス**](https://zilliz.com/blog/Milvus-introduces-GPU-index-CAGRA)は、迅速なデータ処理と検索をサポートするハイパフォーマンス環境向けの最高のオプションです。
メモリー・インデックス**は、パフォーマンスと容量のバランスが取れた中間層のオプションで、確実なクエリーパーセカンド(QPS)レートを提供し、平均レイテンシー約10ミリ秒でテラバイトのストレージまで拡張することができます。
Disk Index**は、数十テラバイトを約100ミリ秒のレイテンシで管理することができ、より大規模で時間的制約の少ないデータセットに適している。Milvusはディスクインデックスをサポートする唯一のオープンソース・ベクターデータベースである。
スワップインデックス**は、S3や他のオブジェクトストレージソリューションとメモリ間のデータスワップを容易にします。このアプローチは、レイテンシを効果的に管理しながら、コストを約10分の1に大幅に削減します。典型的なアクセス時間は100ミリ秒程度ですが、アクセス頻度の低い("コールド")データでは数秒に延びることもあり、オフラインのユースケースやコスト重視のアプリケーションに有効です。
インデックスを選択した後は、その構築時間、精度、パフォーマンス、リソース消費量に基づいて、そのパフォーマンスを評価することができます。例えば、最適化されていないインデックスでは、構築の必要なく毎秒 20 クエリしかサポートできないかもしれません。インデックスを最適化することで QPS は大幅に向上し、チューニングを繰り返すごとに 10 倍になる可能性があります。
インデックスを効果的に選択し、微調整するためには、以下のことを行う必要があります:
1.特定のニーズに基づいて適切なインデックス・タイプを選択する。
2.パフォーマンスを最適化するためにインデックス・パラメータを調整する。
3.使用例をベンチマークし、インデックスが期待通りに動作することを確認する。
4.検索パラメータを調整し、パフォーマンスをさらに向上させる。
最適化プロセスに不安がある場合は、VectorDBBenchのようなベンチマークツールの力を活用しましょう。このツールは、Zillizによって開発され、オープンソース化されたもので、すべての主流のベクトルデータベースを評価することができます。包括的な実験を行い、最適なパフォーマンスを得るためにシステムを微調整することができます。
クイックリファレンスとして、GPUインデックスカタログの各インデックスの性能を概説した便利なチートシートを用意しました。このリソースは、アプリケーションのニーズに最適なインデックスを導き出すことで、性能とコスト効率を最適化するのに役立ちます。
インデックス・チートシート ](https://assets.zilliz.com/An_index_cheat_sheet_a56b4654f2.png)
まとめ
この包括的なガイドでは、ベクターデータベースの多面的な世界と、その効率性とスケーラビリティを最大化するために必要な実践的なアプローチについて解説しています。スキーマ設計の基本から大規模データセットの複雑な管理まで、ベクターデータベースを扱う上で開発者が知っておくべき重要な戦略とベストプラクティスを網羅した。
ベクターデータベースが進化するにつれ、これらの側面について情報を得ることは、開発者がより堅牢で、効率的で、スケーラブルなアプリケーションを構築するための力となります。ベテランのデータベース専門家であれ、この分野の新参者であれ、ここで提供される洞察は、ベクターデータベースの複雑さを、より大きな自信と能力でナビゲートするのに役立つことでしょう。

読み続けて

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.