




What Is A Dynamic Schema?
This post is written jointly by Yujian Tang and Zhenshan Cao.
Every database has a schema, but not all are dynamic. SQL databases have predefined schemas, ones that typically don’t change. When you create it, you tell the database what you want each table to look like and enforce that each entry fits that table’s schema. NoSQL databases typically have a dynamic schema (or can be schemaless). The attributes for each object don’t have to be defined when you create your databases.
For the Milvus vector database, the dynamic schema is one that changes as you add data. For example, dynamic schema support means you can treat data entry like you would with a NoSQL database and add data in a JSON format. Previously, Milvus had a strictly enforced schema. We released a dynamic schema option in Milvus 2.2.9 a few months ago and made it easy to implement.
In this article, we’ll cover:
- What is a Database Schema?
- What is a Vector Database Schema?
- How to Use Dynamic Schema with the Milvus Vector Database
- How Dynamic Schema Feature Is Implemented in Milvus
Pros and cons of Dynamic Schemas
Summary of Dynamic Schemas for Vector Databases
What is a Database Schema?
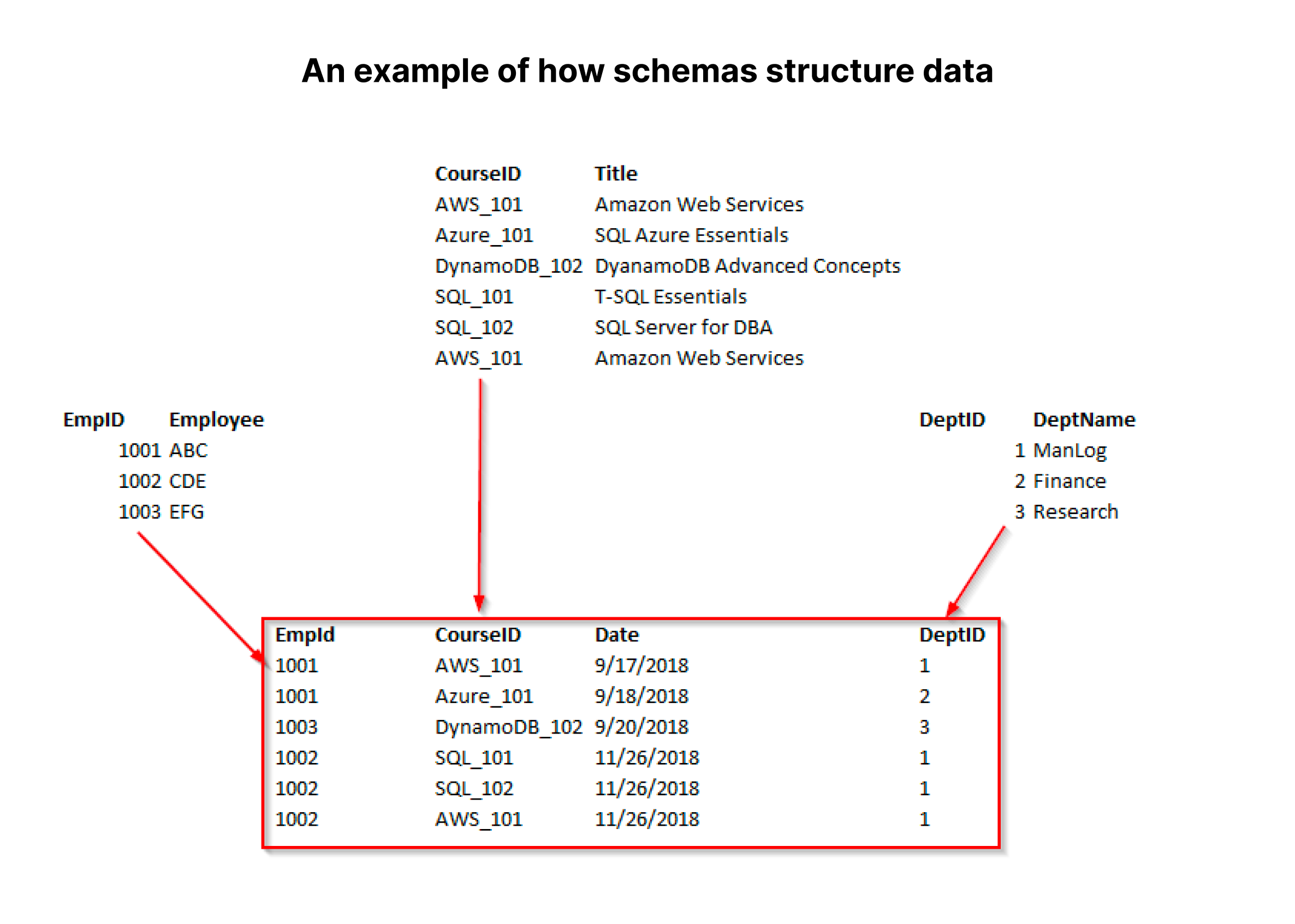
Schemas structure how data is inserted and held in a database. The example above shows how you might create a normalized database schema for a relational database. In the example above, the center table has four columns. This database would have four tables and a schema for each table.
Three tables would have two-column schemas, and the center one would have a four-column schema. The schemas for the columns would also include data definitions. The “Employee”, “Title”, and “DeptName” columns would all be strings, or VARCHARs. Most likely, “CourseID” would be too. “EmpID” and “DeptID” would be integers, and “Date” could be a date type or a VARCHAR type as well.
What is a Vector Database Schema?
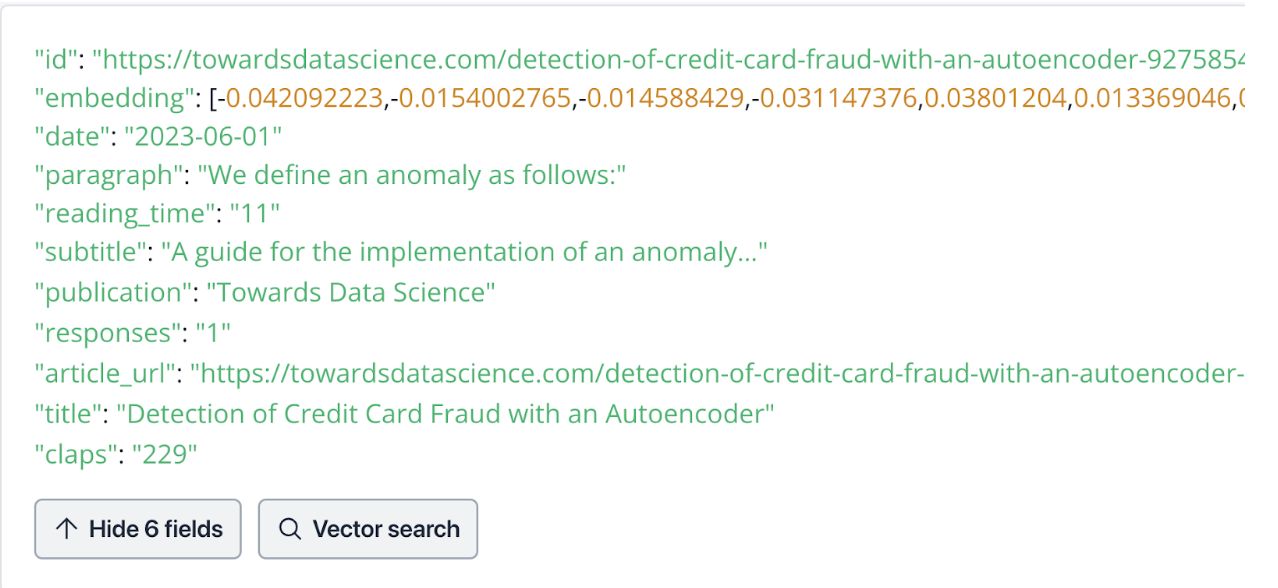
The image below shows an entry into an instance of Zilliz, the fully managed vector database service of Milvus, that I use for my Chat Towards Data Science project. If we were to define it like a relational database schema, we’d have 11 columns. There would be six string or VARCHAR columns - “id”, “paragraph”, “subtitle”, “publication”, “article_url”, and “title”. Three of the other five columns would be some sort of INT data type - “reading_time”, “responses”, and “claps”. The two remaining columns would be a DATE type, “date”, and what we call a “FLOAT_VECTOR”, the embedding vector.
How to use Dynamic Schema with the Milvus vector database?
Milvus is a popular open-source vector database built for performance, scalability, and reliability. We released a dynamic schema option in Milvus 2.2.9 a few months ago and made it easy to implement.
The following code snippet demonstrates how to enable and utilize the dynamic schema feature in Milvus and how to insert data into dynamic fields and perform filtered searches.
from pymilvus import (
connections,
FieldSchema, CollectionSchema, DataType,
Collection,
)
DIMENSION = 8
COLLECTION_NAME = "books"
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True),
FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='embeddings', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, schema=schema)
data_rows = [
{"id": 1, "title": "Lord of the Flies",
"embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],
"isbn": "978-0399501487"},
{"id": 2, "title": "The Great Gatsby",
"embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],
"author": "F. Scott Fitzgerald"},
{"id": 3, "title": "The Catcher in the Rye",
"embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],
"claps": 100},
]
collection.insert(data_rows)
collection.create_index("embeddings", {"index_type": "FLAT", "metric_type": "L2"})
collection.load()
vector_to_search = [0.57, 0.94, 0.19, 0.38, 0.32, 0.28, 0.61, 0.07]
result = collection.search(
data=[vector_to_search],
anns_field="embeddings",
param={},
limit=3,
expr="claps > 30 || title =='The Great Gatsby'",
output_fields=["title", "author", "claps", "isbn"],
consistency_level="Strong")
for hits in result:
for hit in hits:
print(hit.to_dict())
In the created collection "books," we define a schema with three fields: id, title, and embeddings. The id is the primary key, a unique identifier of each row, and in the format of INT64. The title represents the book's name with the type VARCHAR, and the embedding is an 8-dimensional vector column. In this post, vector data is randomly set in the code for demonstration purposes.
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, schema=schema)
We enable dynamic schema by passing a field to the CollectionSchema object on the definition. All we do is add the enable_dynamic_field schema and set it to True.
data_rows = [
{"id": 1, "title": "Lord of the Flies",
"embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],
"isbn": "978-0399501487"},
{"id": 2, "title": "The Great Gatsby",
"embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],
"author": "F. Scott Fitzgerald"},
{"id": 3, "title": "The Catcher in the Rye",
"embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],
"claps": 100},
]
In the above code, we insert three rows of data. The data for id=1 includes the dynamic field isbn, id=2 includes author, and id=3 includes claps. These dynamic fields have different types, including string types (isbn and author) and integer types (claps).
result = collection.search(
data=[vector_to_search],
anns_field="embeddings",
param={},
limit=3,
expr="claps > 30 || title =='The Great Gatsby'",
output_fields=["title", "author", "claps", "isbn"],
consistency_level="Strong")
In the code above, we perform a hybrid search combining ANNS (Approximate Nearest Neighbors) search with filtering based on dynamic fields. The query aims to retrieve data from rows that satisfy the conditions specified in the expr parameter. The output includes title, author, claps, and isbn fields if present. The expr parameter allows filtering based on schema fields (title) and dynamic fields (claps).
After running the code, the output results are as follows:
{'id': 2, 'distance': 0.40939998626708984, 'entity': {'title': 'The Great Gatsby', 'author': 'F. Scott Fitzgerald'}}
{'id': 3, 'distance': 1.8463000059127808, 'entity': {'title': 'The Catcher in the Rye', 'claps': 100}}
How is the Dynamic Schema feature implemented in Milvus?
Milvus kernel allows users to add dynamic fields with different names and data types to each row of data using a hidden meta column. When users create a table and enable dynamic fields, a hidden column named $meta is created alongside the table. The hidden column uses JSON as the data type because it is a language-independent data format widely supported by modern programming languages for generating and parsing JSON-format data.
Milvus organizes data in a columnar structure. During insertion, the data for dynamic fields in each row is packaged into one piece of JSON data, and all rows of JSON data together form the hidden column $meta.
What are the pros and cons of Dynamic Schema?
Dynamic schemas offer advantages and drawbacks, catering to different needs in data modeling.
Pros
- Dynamic schemas are easy to set up, making them accessible to a broad user base without requiring intricate configurations.
- Dynamic schemas accommodate changes in data models over time, allowing developers to adjust without significant restructuring.
Cons:
- Filtered search with dynamic schemas is much slower than fixed schemas.
- Bulk insert on dynamic schema is complicated.
To address these challenges, Milvus has integrated a vectorized execution model to boost filtered search efficiency. In contrast to the conventional volcano model, which processes one row of data at a time through invoked operators, the vectorized execution model handles entire batches of data concurrently. This computing paradigm optimizes data locality during computation, resulting in a significant enhancement in overall system performance.
Looking ahead, we’ll continue to enhance the scalar indexing capabilities in Milvus 2.4. This enhancement aims to accelerate filtered search through inverted indexing for static and dynamic fields, promising improved performance and efficiency in managing and querying dynamic schemas.
Summary of Dynamic Schemas for Vector Databases
In this article, we took a look at database schemas. We used an example schema of a relational database to better understand schemas. Relational databases have strict schemas that need to be defined. Schemas have to have defined fields, and fields have to have defined data types. That’s how Milvus’ schema used to be enforced.
However, Milvus actually only needs to know how two fields are defined. One, the ID of the entry, and two, the embedding field. The rest of the fields do not need to be defined, but they can be. With the introduction of dynamic schema, passed using the enable_dynamic_field parameter, Milvus no longer needs to have the other fields defined.
Dynamic schemas present a double-edged sword, offering ease of setup, flexibility, and efficiency, but not without trade-offs. For example, filtered search with dynamic schemas is slower than fixed schemas, and bulk inserting on dynamic schemas is more complicated. Milvus utilized a vectorized execution model to address the challenges that come with dynamic schemas, optimizing the overall system performance. We’ll also enhance the scalar indexing capabilities in Milvus 2.4 to improve performance and efficiency in managing and querying dynamic schemas.

Keep Reading

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.