




Metadata Filtering with Zilliz Cloud Pipelines
A common question I hear is, “Do I need a regular SQL database in addition to my vector database?” This question may be necessary if you include additional information with the unstructured data. Additionally, you can filter the data for business purposes before performing a semantic similarity search. For example:
In a legal context, you may need to search for chunks of text only from your contract database or a specific contract.
In retail, you may want to narrow your search to a particular size of men's shoes.
In image search, you may wish to find posters for films released during 2010-2016, with IMDB scores higher than 7.0.
Back to the question above, my answer is “No, you don’t have to worry about it when you use Milvus vector database or Zilliz Cloud, the fully managed Milvus.” With Milvus, you can perform hybrid vector and scalar search to achieve better precision.
In the following sections, we will discuss scalar or metadata filtering and how you can perform metadata filtering in Zilliz Cloud. This blog continues my previous blog on getting started with RAG in just 5 minutes. You can find its code in this notebook and scroll down to Cell #27.
How to understand Metadata Filtering in Milvus?
Milvus vector database allows you to perform vector searches by applying boolean expressions and limiting them with conditions on the attributes of your data. The attributes can be any field except for the unstructured data embedding vector. In addition, metadata filtering coexists with vector search in Milvus. You can use any field other than the embedding vector field in the filter expression and use vector index to search the embedding vector field. Milvus automatically handles both operations when you specify a filter expression in your search command.
How to perform Metadata Filtering in Zilliz Cloud?
To start iterating quickly, I’ll use Zilliz Cloud (Free Tier), the fully managed Milvus, in this guide. It hosts your database on a serverless cloud server, but you can still interact with it locally by making PyMilvus API calls. I’ll also use Zilliz Cloud Pipelines, a built-in feature, to encode unstructured data into vector embeddings for streamlined operations.
The data below is from our Milvus Documentation documentation pages.
Step 1: Create a collection (database table) and pipelines
Upload your data to S3 or GCS.
Open another browser window to https://cloud.zilliz.com/ and create a “Starter” Cluster.
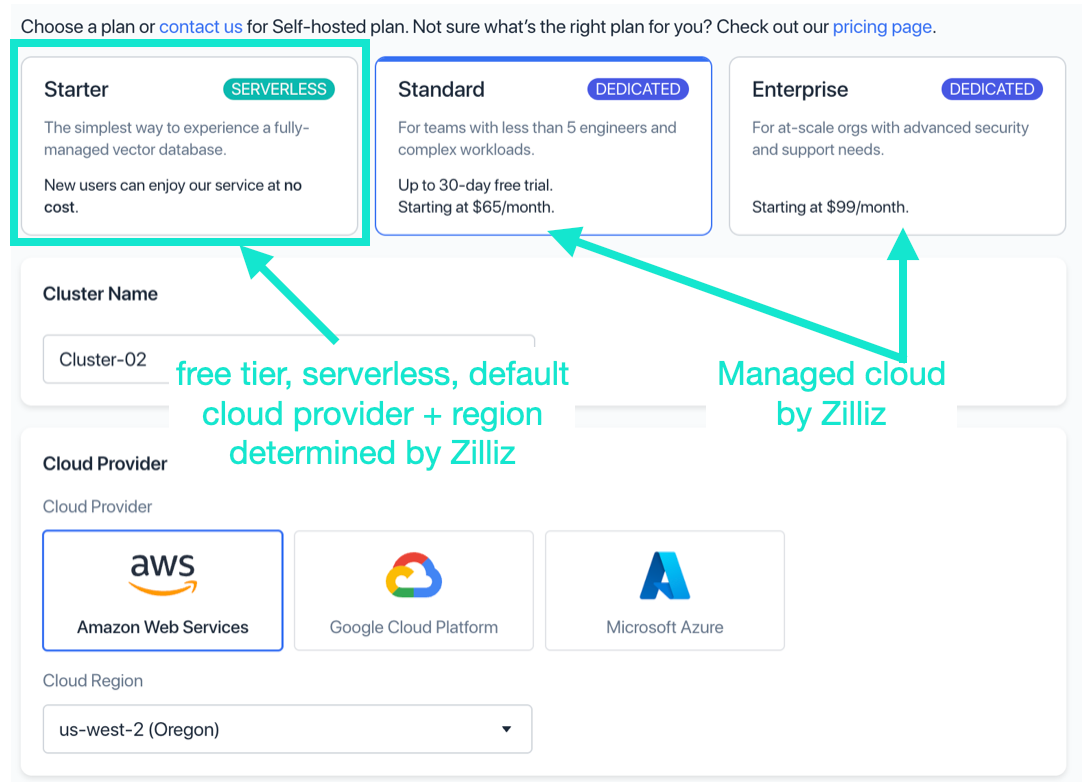
- Add the collection name and click “Create Collection and Cluster”.

Note: When you create your first Zilliz Cloud cluster, you create a new collection as well by default. When you use Zilliz Cloud Pipelines, you’ll create another new collection.
- Navigate through the left-side menu to Pipelines and follow the guided steps to upload your data.
a. Start with “Ingestion Pipeline.”
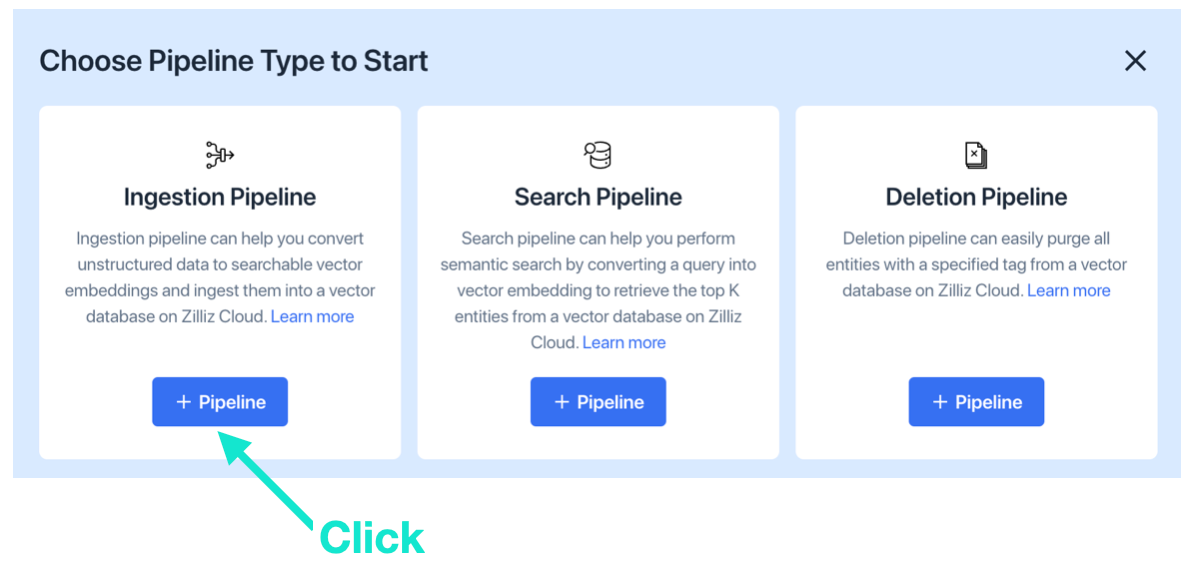
b. Select the name of your cluster, add collection and pipeline names, and click “Add a Function.”
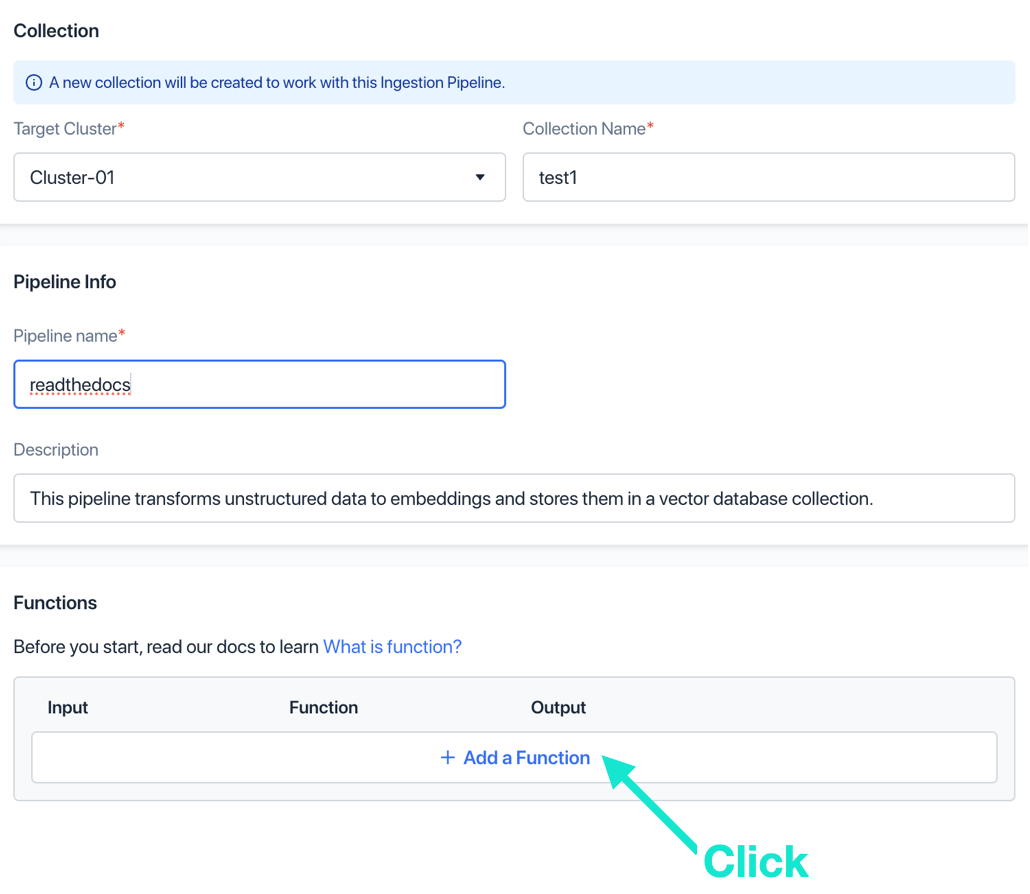
c. Add a name, and click “Add”. At this step of the pipeline, you cannot modify anything.
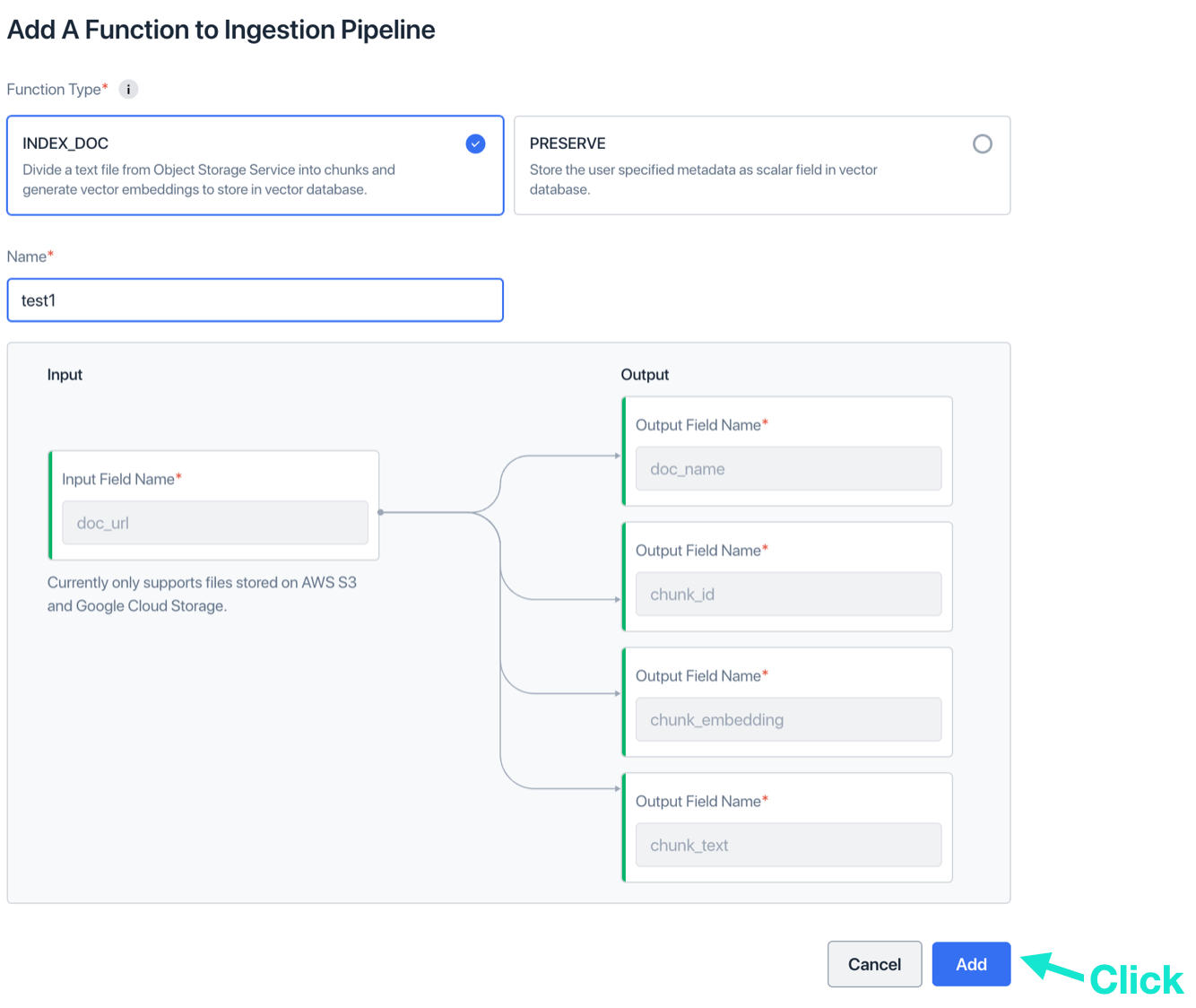
d. Optional: Click “Add a Function” again
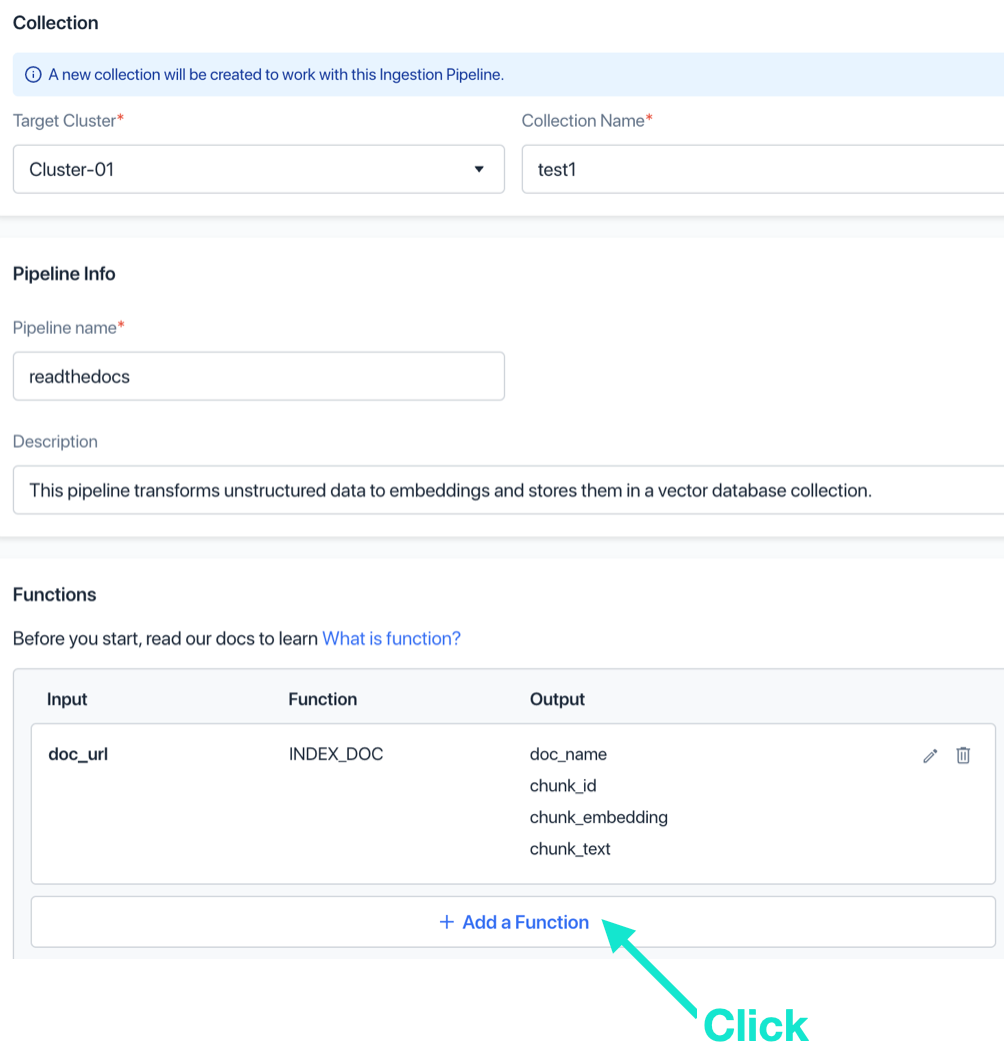
e. Optional: Name the metadata field step, the metadata field, and the type. Click “Add”.
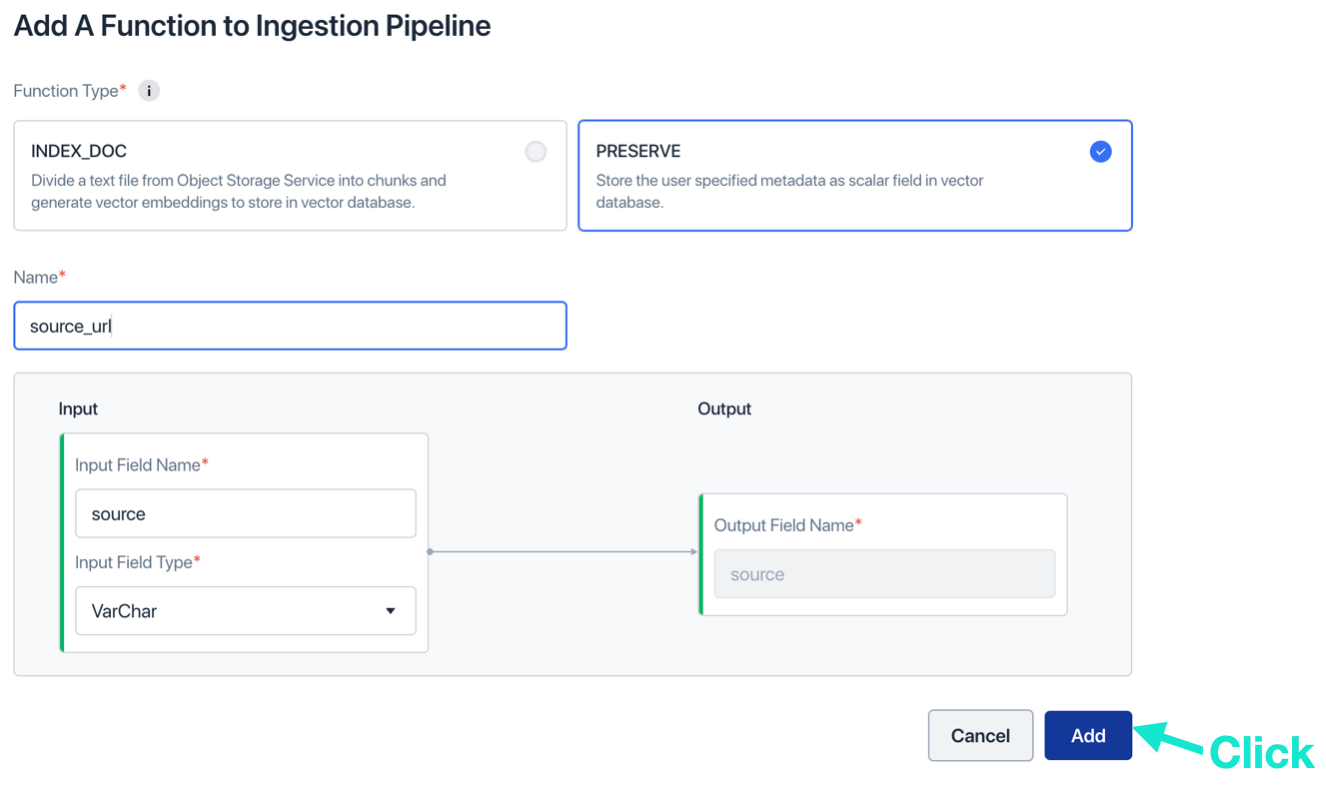
- Click “Create Ingestion Pipeline”. Now, you’ve created a new Ingestion Pipeline and a new Collection.

Click “Create Deletion and Search Pipelines” to create deletion and search pipelines.
To find the pipeline “Ingestion,” click the Run icon > under “Actions.”

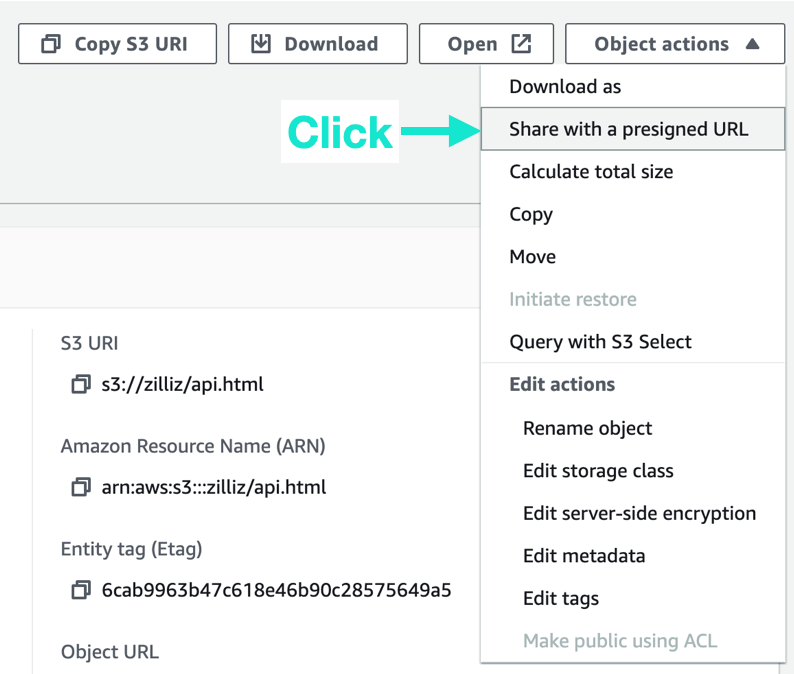
- Point to your data. In AWS, the easiest way is a temporary pre-signed URL. Select when you want to share it, then Copy the pre-signed URL.
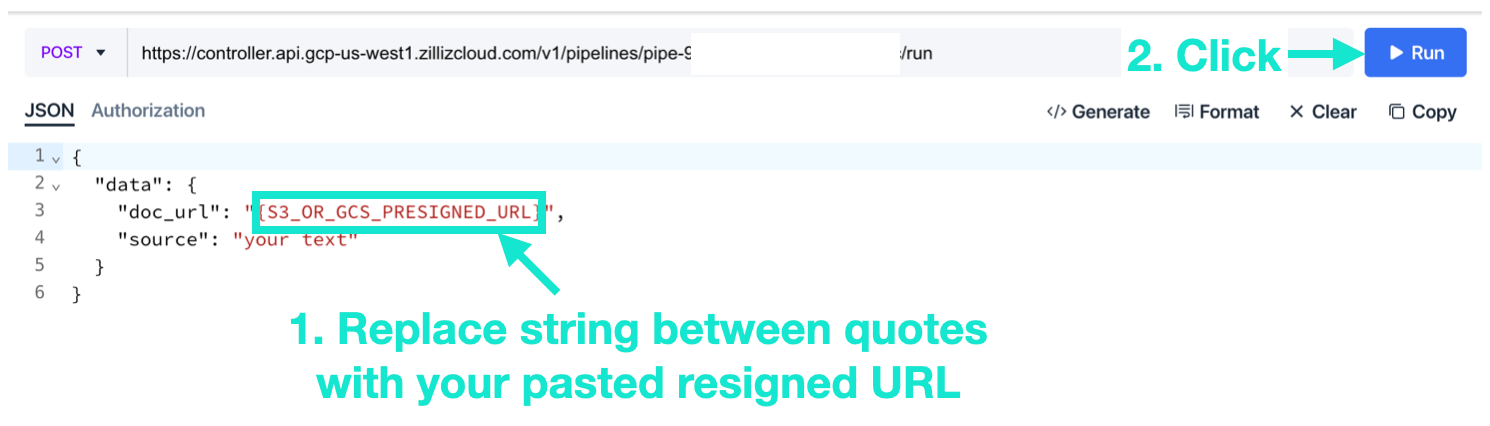
- Paste the pre-signed URL and click “Run.”
- Refresh your browser and check if the new collection and schema are correct.
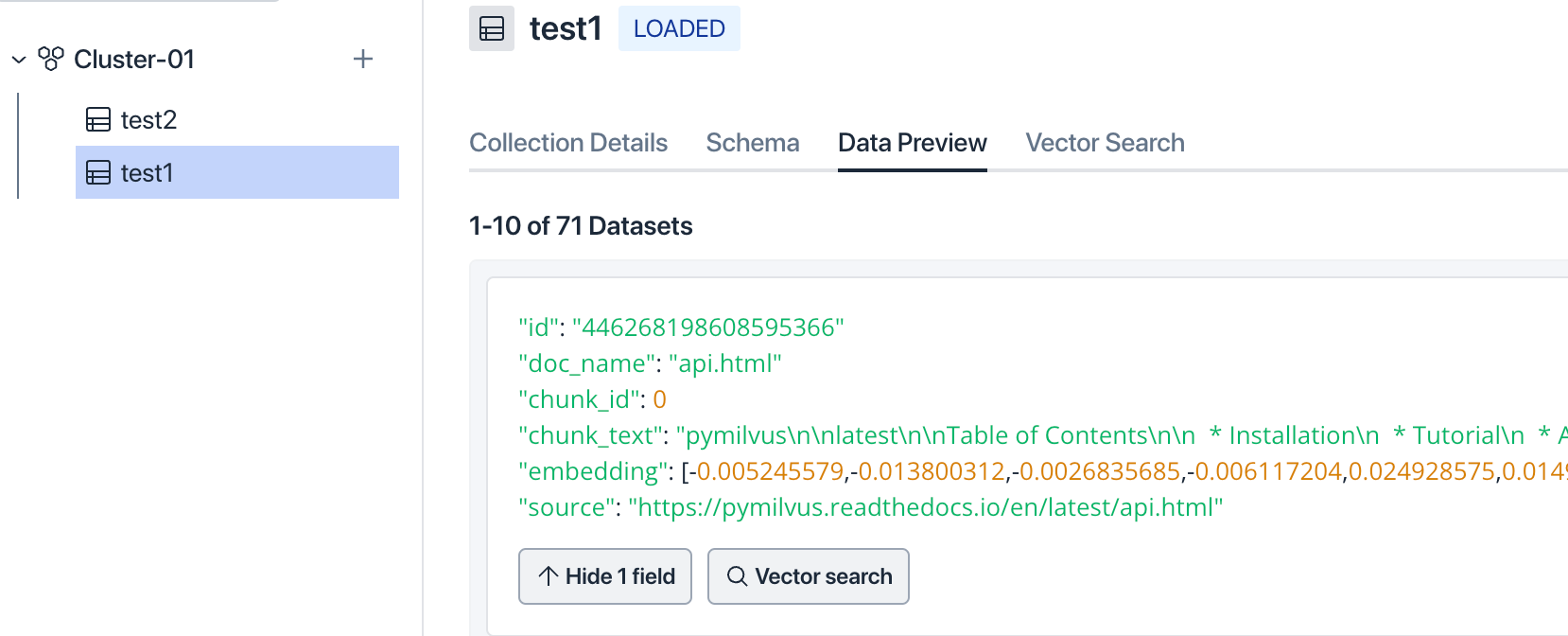
Query in the web console or using API calls.
Step 2. Search in the web console
Find the Pipeline “Search” under Actions > click the Run icon.
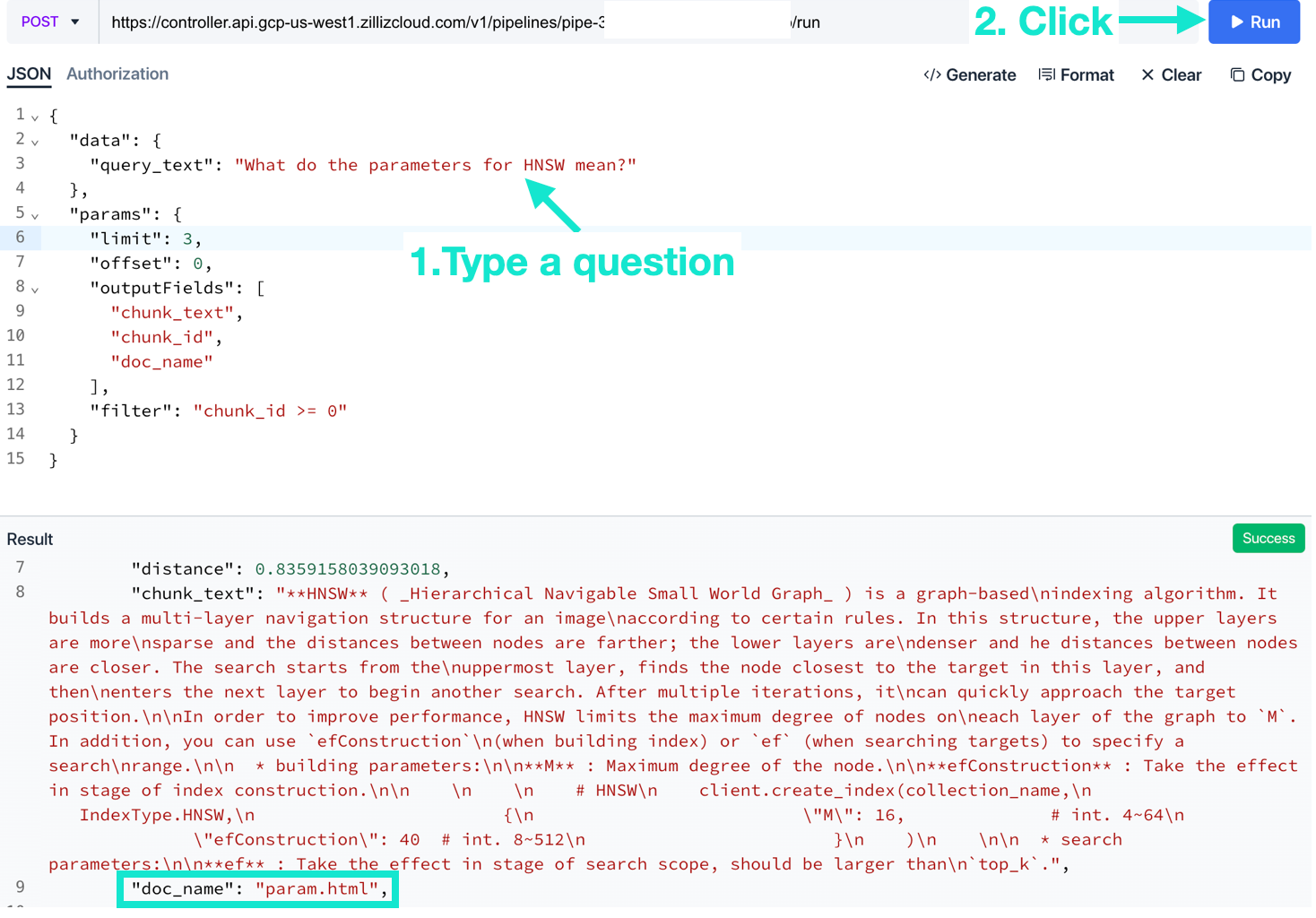
In the UI, type your question and click “Run.”
Edit the “filter” using a boolean expression. You should see that the filter was applied to the search results.
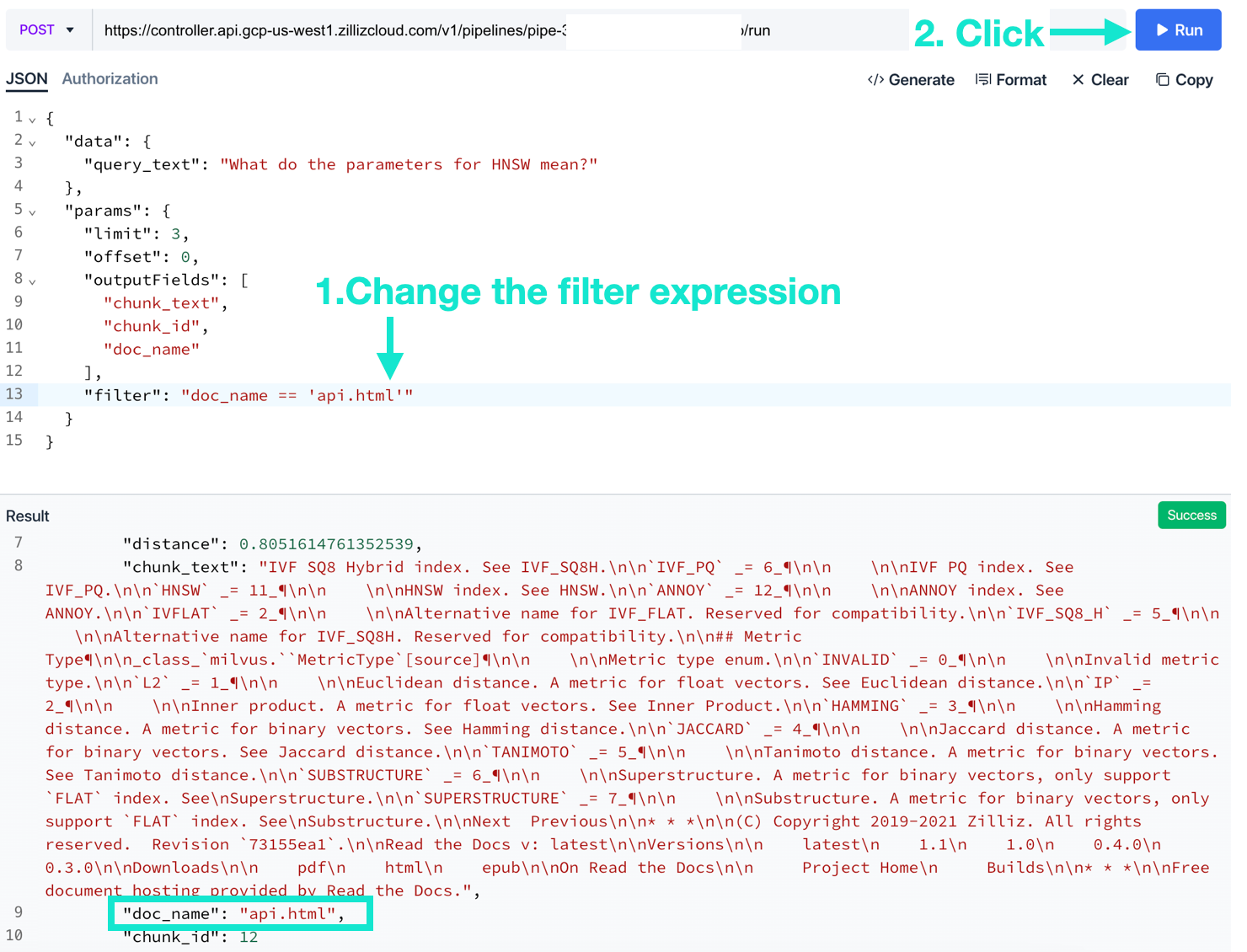
That’s it! You can use boolean expressions to filter search using any field other than the unstructured data embedding vector. The embedding vector field is searched using the vector index AUTOINDEX in Pipelines.
Also, in Pipelines, embeddings are normalized so that IP and cosine distance metrics work equivalently. The default embedding model used in Pipelines, at the moment, is bge-large-en-v1.5.
Step 3. Search via API
You could also search using API calls (Python code is in this notebook; scroll down to Cell#27. )
You’ll need two things.
Zilliz API Token
Pipeline-ID
You can get the API Token from the Cluster main screen.
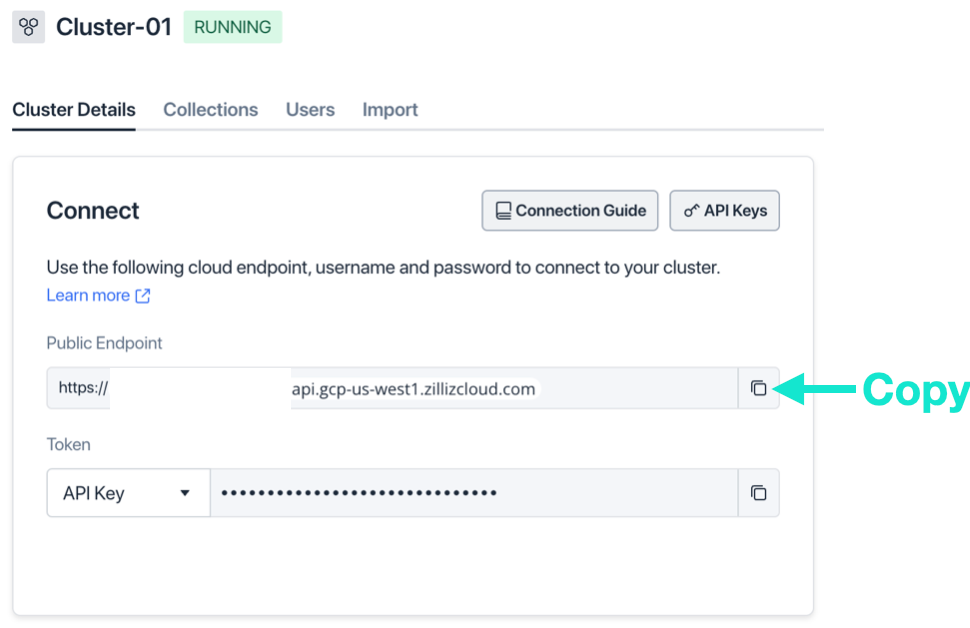
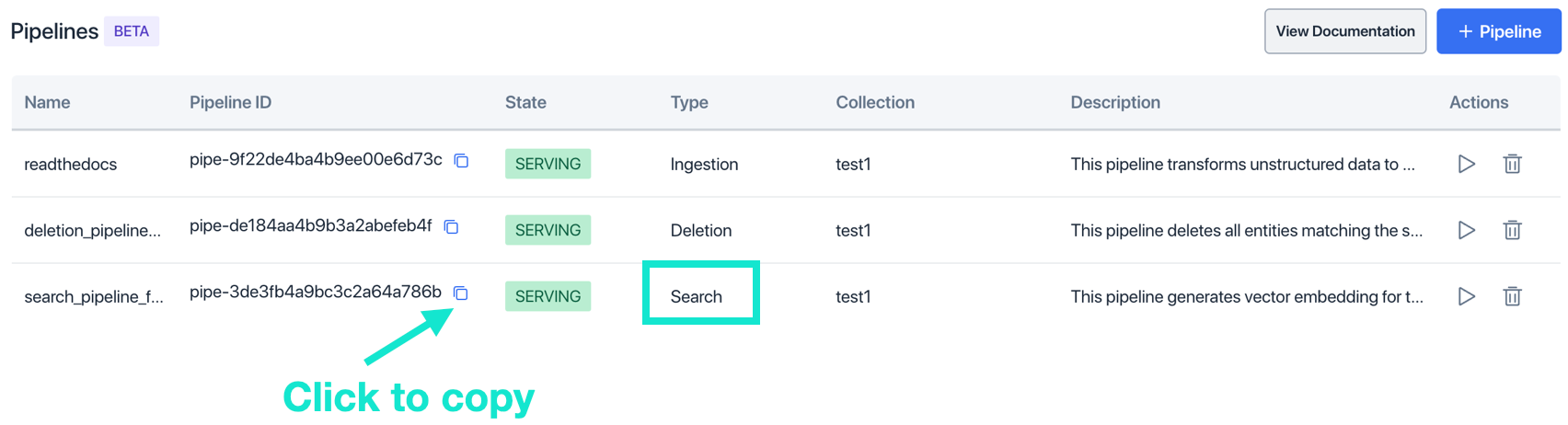
To get the Pipeline-ID, find the Pipeline “Search,” look in the “Pipeline-ID” column, and click the copy icon. Paste the Pipeline ID in the URL of your API call.
import requests, json
url = "https://controller.api.gcp-us-west1.zillizcloud.com/v1/pipelines/pipe-xxxx/run"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {TOKEN}",
}
data = {
"data": {
"query_text": SAMPLE_QUESTION
},
"params": {
"limit": TOP_K,
"offset": 0,
# Any of these fields can be used in filter expression.
"outputFields": ["chunk_text", "chunk_id", "doc_name", "source"],
"filter": "doc_name == 'param.html'"
}
}
# Send the POST request
response = requests.post(url, headers=headers, json=data)
That’s it! Now, you’ve learned how to perform filter search in Zilliz Cloud via API.
Summary
Like joining data in an SQL database to enable you to perform SQL queries, metadata filtering allows you to perform hybrid vector and scalar searches in Milvus or Zilliz Cloud for more precise results that cater to your specific needs. You can limit your search with certain conditions by specifying boolean expressions that filter the scalar fields or the primary key field. You can use any field, except the embedding vector, in the filter expression and search the embedding vector field using the vector index. Milvus or Zilliz Cloud automatically handles both operations when you specify a filter expression in your search command.
The full code for this demo is in this notebook; scroll down to Cell#27. Give it a try.

Keep Reading

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.