




How Metadata Lakes Empower Next-Gen AI/ML Applications
As AI technologies like large language models (LLMs) and Retrieval Augmented Generation (RAG) continue to evolve, the demand for flexible and efficient data infrastructure is growing. Organizations are seeking data architectures that can support these new tools while minimizing technical debt and enabling seamless scalability.
Metadata lakes are emerging as a key solution in this regard. They are centralized repositories that store metadata from various sources in an organization, offering a unified approach to data management. Metadata provides context and understanding of the stored data, including data source, quality, lineage, ownership, content, structure, and context.
Lisa N. Cao, Product Manager at Datastrato, recently delivered a talk at the Unstructured Data Meetup hosted by Zilliz, where she discussed the critical role of metadata lakes in next-generation AI/ML development. Drawing on her experience as a data engineer, Lisa shared insights into how metadata lakes can streamline data management and integrate with various technologies like vector databases, deep learning models, and LLMs in AI-driven environments.
 Lisa speaking at the June Unstructured Data Meetup in Palo Alto
Lisa speaking at the June Unstructured Data Meetup in Palo Alto
This blog recaps Lisa's key points and explores the challenges of deploying RAG pipelines into production. But first, let’s briefly introduce RAG and the challenges in RAG development and deployment.
Quick Intro to RAG (Retrieval Augmented Generation)
RAG, or Retrieval-Augmented Generation, is an advanced framework that enhances LLM responses by combining retrieval and generative modules. The retrieval module comprises a vector database like Milvus or Zilliz Cloud (the fully managed Milvus) and an embedding model, and the generative module is usually an LLM like ChatGPT.
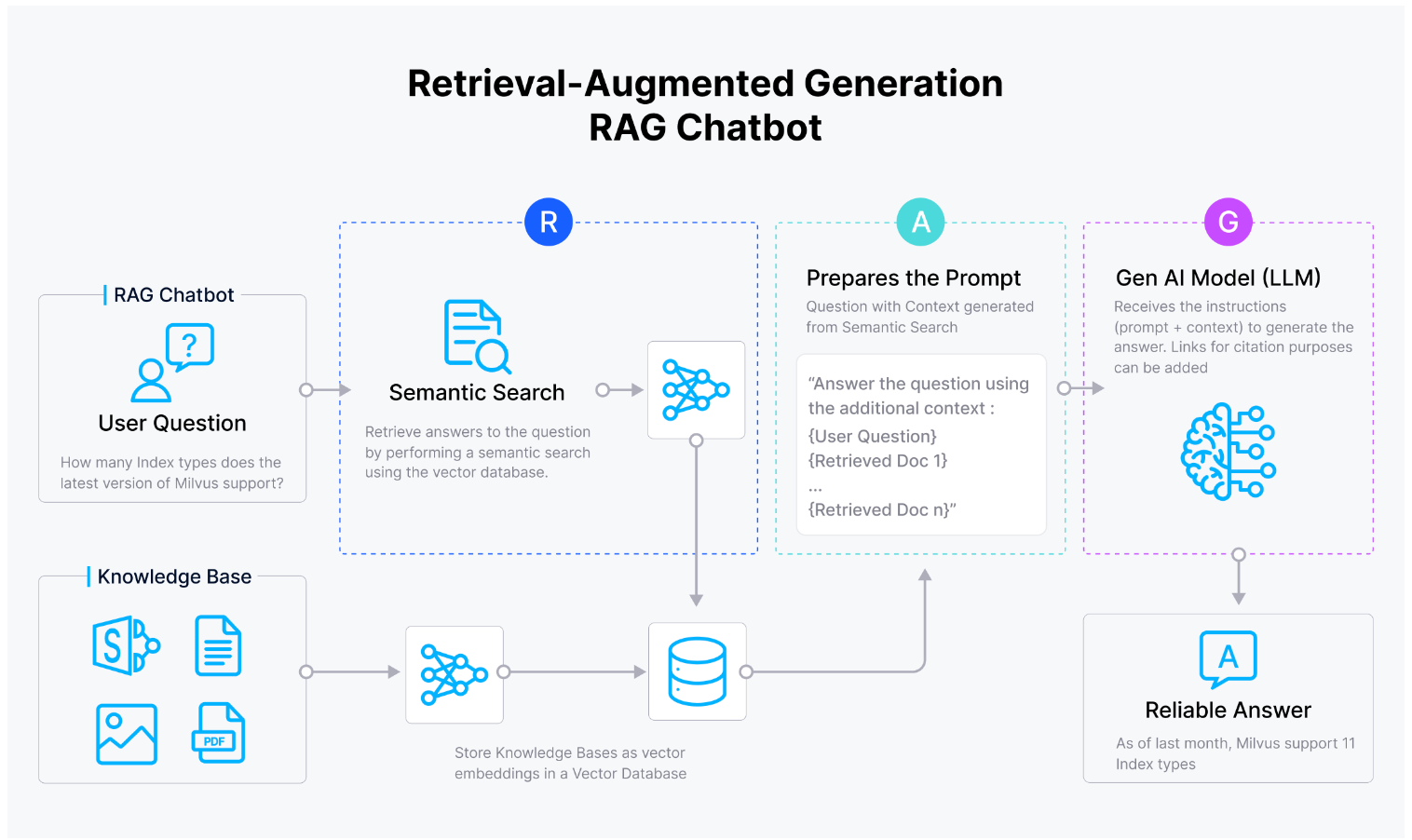 Figure 1 How RAG works
Figure 1 How RAG works
Figure 1: How RAG works
When the user inputs a query to a RAG application, the vector database in the retrieval module extracts the most relevant documents from the large text corpus. These retrieved documents are called “top candidates” and fed to the LLM as the user query context to generate a more accurate response. RAG is particularly useful in applications like question answering, chatbots, and knowledge management systems.
Current Challenges in RAG Development
Recently, many advanced techniques have been introduced to the RAG pipeline for enhanced accuracy and performance, including sophisticated retrieval methods based on re-ranking and recursive retrieval and embedding and LLM-based fine-tuning techniques. Additionally, Agentic frameworks designed for routing and query planning have been introduced to enhance RAG's capabilities.
However, these advancements also introduce new complexities. Lisa discussed several challenges that many AI teams face when developing and deploying RAG into production:
Low Observability: Monitoring document ingestion velocity and data distribution changes within RAG pipelines is challenging. Since the vector database in a RAG application often stores billions of documents, tracking data changes and updates for knowledge management becomes difficult.
Lifecycle Management: Effective version control and lifecycle management are crucial for tracking data changes and updates. Teams need robust tools to trace data lineage transparently and auditably to ensure compliance.
Latency and Optimization: While advanced fine-tuning and recursive retrieval can improve the accuracy of generated outputs, they may also increase response times, leading to higher latency and lower user satisfaction.
Contextual Responses to Queries: Complex user queries can be difficult for LLMs to interpret accurately, resulting in responses lacking context or nuance.
Data Privacy: AI governance is another challenge, particularly when it comes to adding masking or encryption to data used in training.
Continual Learning Mechanism: Lisa emphasized keeping RAG applications updated with fresh data. "There’s a huge difference between models that access continuously updated data and those that rely on stale data," she noted. Implementing a continual learning mechanism, however, can be technically challenging.
Vendor Lock-In: Relying heavily on a single cloud service provider for pipeline needs can lead to vendor lock-in, making it difficult and costly to transition to another ecosystem.
One of the underlying issues that contribute to these challenges is the presence of data silos across organizations.
Data Silos Across Organizations: A Key Contributor to RAG Challenges
Data silos are a common problem in organizations where data is not easily accessible across different teams or departments due to structural or technological barriers. These silos can exist at the operational level, between various teams, or due to the complexity of tools and applications in use.
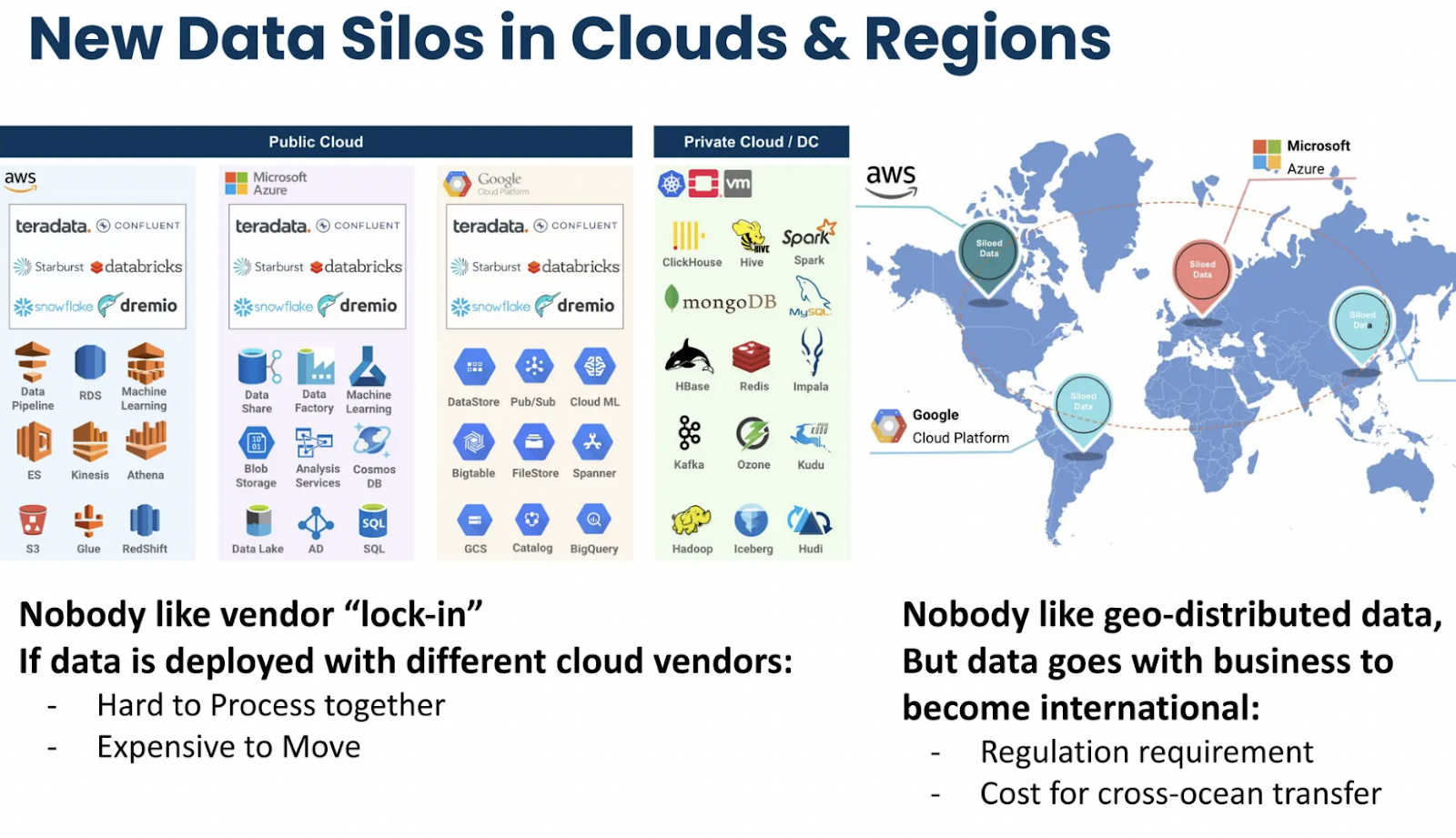 Figure 2- Data Silos Impacting Efficiency in Organizations
Figure 2- Data Silos Impacting Efficiency in Organizations
Figure 2: Data Silos Impacting Efficiency in Organizations
Lisa highlighted the pervasive issue of data silos, noting, "Every company is trying to address this question: ‘How do we create operational consistency in our data across the entire organization?’" This is particularly challenging when teams are distributed globally and work with different data stores.
There are also silos between different teams. For instance, BI analysts and data engineers often use different tools and may lack effective communication. Some teams may not possess the programming knowledge or technical skills to access and process available data. For example, DevOps engineers might struggle to understand the codebase of ML engineers.
Data silos directly impact the ability to build and maintain effective RAG pipelines, as they prevent the seamless flow of data across an organization. This lack of integration can lead to fragmented data sources, inconsistencies in data usage, and, ultimately, challenges in deploying RAG systems that rely on comprehensive and current data.
Metadata Lakes: Bridging the Gap for Unified Data Management
To address the above mentioned RAG challenges, businesses need data architecture solutions to unify, standardize, and operationalize data across the organization. Metadata lakes offer a flexible architecture for storing and managing metadata—information about the source, structure, format, usage, lineage, and more.
What is a metadata lake?
A metadata lake, or data lake metadata management, is a centralized repository that stores metadata from various sources in an organization. Metadata is the descriptive information that provides context and understanding of the data in the data lake. It usually includes details such as data source, quality, lineage, ownership, content, structure, and context.
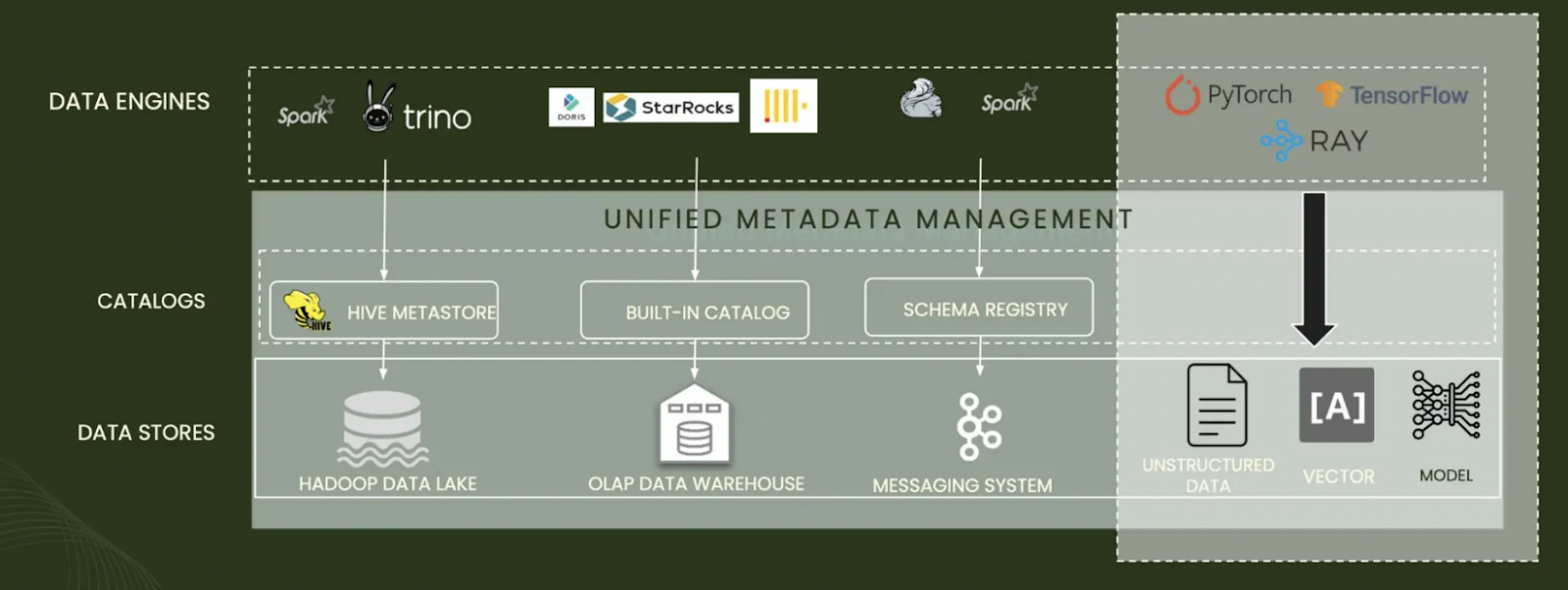 Figure 3- A unified metadata management .png
Figure 3- A unified metadata management .png
Figure 3: A unified metadata management
Unlike a traditional data lake, which stores raw data, a metadata lake focuses on managing, organizing, and making accessible the metadata associated with data assets across different systems, databases, and applications.
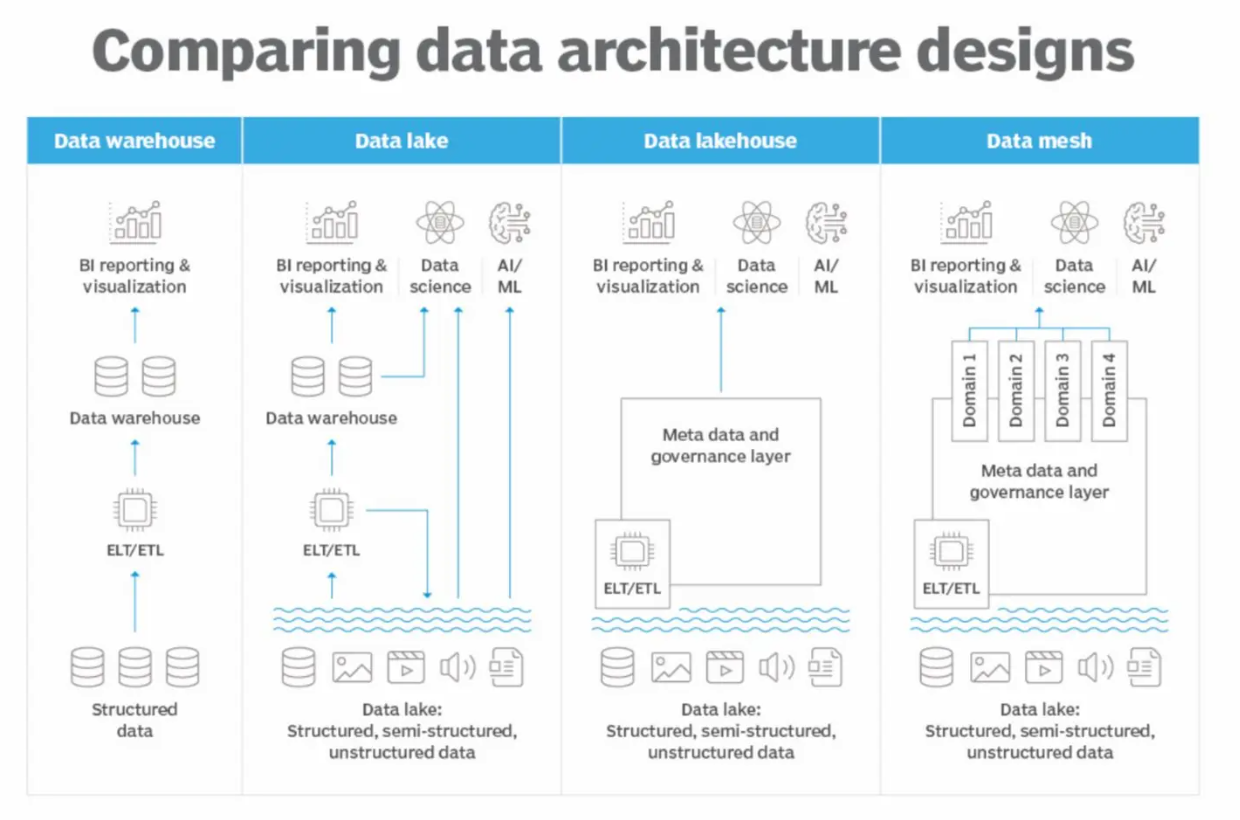 Figure 4- Comparing different data architecture designs
Figure 4- Comparing different data architecture designs
Figure 4: Comparing different data architecture designs
Benefits of Metadata Lakes
Improved Data Discoverability: Metadata lakes serve as centralized catalogs, storing all metadata and making it easier for teams and users to discover data assets across the organization.
Active Metadata: These lakes enable active metadata, which can trigger actions and integrate with orchestrated pipelines, automating tasks and reducing the need for manual intervention.
Embedded Metadata: Metadata can be embedded in different applications, facilitating seamless integration and interaction across the data ecosystem.
Enhanced AI Governance: Centralizing metadata management makes it easier to implement consistent governance policies, ensuring compliance and data quality. Metadata lakes also support detailed data lineage tracking, access controls, and auditing capabilities.
Rich Metadata Utilization: Unified metadata management allows for richer metadata utilization, such as enrichment, data masking, and classification, enhancing data quality, security, and usability.
Overall, metadata lakes simplify and automate data lifecycle management, making collaboration across technical teams easier and helping to eliminate the data silos that hinder RAG development.
Demo: Building Metadata Lakes Using Gravitino
Lisa shared her experience working on an open-source project where a metadata lake was developed using Gravitino. The project aimed to create a data catalog that supports multiple cloud service providers, including AWS, Azure, and GCP. It allows users to register various data sources into the metadata lake, such as S3 buckets, Milvus vector database, HiMetastores, and other data stores. Gravitino also provides access controls and tools for tracking data lineage and facilitating auditing.
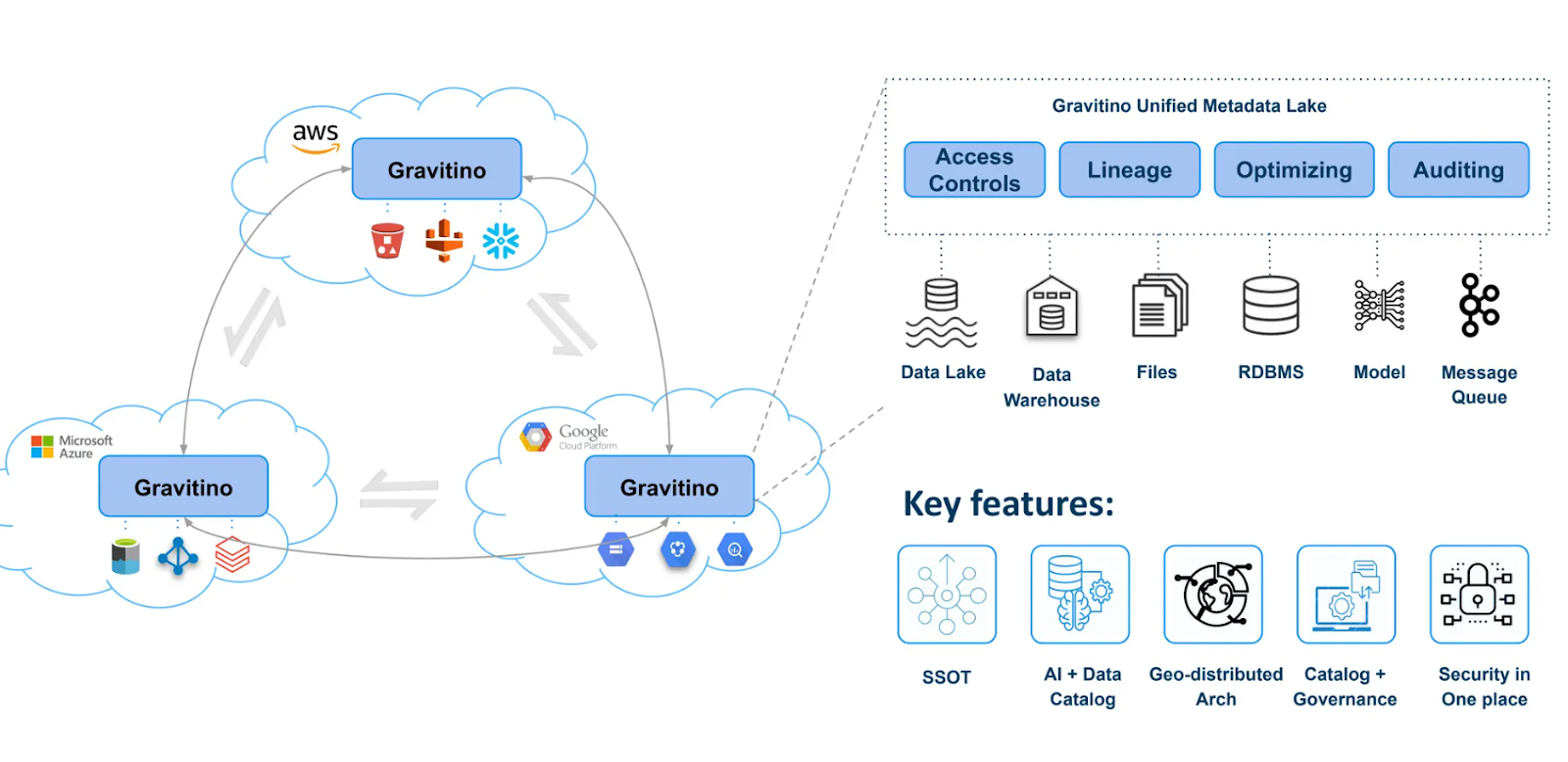 Figure 5- The metadata lake architecture built with Gravitino
Figure 5- The metadata lake architecture built with Gravitino
Figure 5: The metadata lake architecture built with Gravitino
The architecture uses REST APIs to serve metadata to different applications. The connect layers convert all data into a common schema before storing it in the metadata lake. Gravitino supports both tabular and non-tabular data formats and allows for tag-based masking to ensure data security.
AI teams can also integrate knowledge graphs and vector stores within the metadata management framework, creating a unified catalog. Due to the catalog's federated nature, queries can access metadata without moving the source data. Join operations occur either in-memory or at defined locations, optimizing performance and maintaining data integrity across distributed environments.
Conclusion
Metadata lakes are evolving into AI catalogs that manage metadata and integrate with AI and ML workflows. These lakes can assist with RAG development, model registration, AI governance, and implementing advanced analytics. By providing a unified plane for data operations, metadata lakes empower teams to maintain observability in metadata analysis, ensure smooth transitions between different cloud environments and data sources like the Milvus vector database, and uphold governance frameworks seamlessly. As AI technologies advance, metadata lakes will play a key role in supporting next-generation AI/ML applications.
Further Resources
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
Keep Reading

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.