




NVIDIA RAPIDS cuVSによるGPU上のMilvus
#はじめに
**AIアプリケーションの成功において、本番環境でのパフォーマンスは非常に重要な要素です。この緊急性が最適化の必要性を高めています。
実際の例として、Retrieval Augmented Generation (RAG)アプリケーションを考えてみよう。RAGシステムにおいて、ベクトル検索は、ユーザーの体験に力を与えるエンジンであり、ユーザーのクエリに基づいて適切な結果を提供する。しかし、我々はベクトル検索がリソースを大量に消費するタスクであることを十分認識している。保存するデータが多ければ多いほど、計算はより高価で時間のかかるものになる。
このような場合、AIアプリケーションのパフォーマンスを最適化するソリューションを見つける必要がある。Zilliz主催のUnstructured Data Meetupで最近行われた講演で、NVIDIAのプリンシパル・エンジニアであるCorey Noletが、この問題に対処するためのNVIDIAの最新の進歩について語ったので、この記事で紹介する。YouTube](https://youtu.be/pBaq3CcZOFc?t=1548)でも[Coreyの講演]をチェックできる。
具体的には、NVIDIAによって開発されたライブラリであるcuVSに焦点を当てます。このライブラリには、ベクトル探索に関連するいくつかのアルゴリズムが含まれており、GPUの加速能力を活用しています。このライブラリがどのようにベクトル検索操作のパフォーマンスを向上させ、全体的な運用コストを最適化できるかを見ていきます。それでは、早速始めましょう!ベクトル検索とベクトルデータベースの役割
ベクトル検索とは、情報検索の手法の一つで、ユーザーのクエリと検索される文書の両方をベクトルとして表現するものです。ベクトル検索を行うには、クエリと文書(画像やテキストなど)をベクトルに変換する必要がある。
ベクトルには特定の次元があり、その次元は生成に使われた方法によって異なります。例えば、all-MiniLM-L6-v2というHuggingFaceモデルを使用してクエリをベクトルに変換すると、384次元のベクトルが得られます。ベクトルは、それが表すデータやドキュメントの意味的な意味を持ちます。したがって、2つのデータが互いに類似している場合、それらの対応するベクトルはベクトル空間内で互いに近くに配置されます。
ベクトル空間におけるベクトル間の意味的類似性.png](https://assets.zilliz.com/Semantic_similarity_between_vectors_in_a_vector_space_d101dec8f6.png)
ベクトル空間におけるベクトル間の意味的類似性.
各ベクトルがそれが表すデータの意味的な意味を持つという事実は、任意のランダムなペアのベクトル間の類似度を計算することを可能にします。類似していれば類似度のスコアは高くなり、逆もまた然りである。ベクトル検索の主な目的は、クエリのベクトルに最も近いベクトルを見つけることです。
ベクトル検索の実装は、少数の文書を扱う場合には比較的簡単です。しかし、ドキュメントの数が増え、より多くのベクトルを保存する必要があるため、複雑さが増していきます。ベクトルが増えれば増えるほど、ベクトル検索にかかる時間は長くなる。さらに、ローカルメモリに格納するベクトルが増えると、運用コストが大幅に増加する。従って、スケーラブルなソリューションが必要であり、そこでベクトルデータベースの出番となる。
ベクトルデータベースは、膨大なベクトルコレクションを格納するための効率的で高速かつスケーラブルなソリューションを提供します。また、AIアプリケーションの開発プロセスを簡素化するため、一般的なAIフレームワークとの容易な統合も可能です。Milvus](https://milvus.io/)やZilliz Cloud(マネージドMilvus)のようなベクトルデータベースでは、ベクトルのメタデータを保存し、検索操作中に高度なフィルタリング処理を実行することもできます。
 ベクター検索操作の完全なワークフロー.png
ベクター検索操作の完全なワークフロー.png
Milvusのようなベクトルデータベースにベクトルのコレクションを格納するためには、まずデータの種類に応じてデータの前処理を行います。例えば、データがドキュメントのコレクションであれば、各ドキュメントのテキストをチャンクに分割します。次に、各チャンクを任意の埋め込みモデルを使ってベクトルに変換する。そして、すべてのベクトルをベクトル・データベースに取り込み、ベクトル検索をより高速に行うためのインデックスを構築する。
クエリがあり、ベクトル検索を行いたい場合、前回と同じ埋め込みモデルを用いてクエリをベクトルに変換し、データベース内のベクトルとの類似度を計算する。最後に、最も類似したベクトルが返される。
CPUでのベクトル検索処理
ベクトル検索操作には集中的な計算が必要であり、ベクトルデータベース内のベクトル数が増えるほど計算コストは増加します。計算コストには、インデックスの構築、ベクトルの総数、ベクトルの次元数、検索結果の品質など、いくつかの要因が直接影響します。
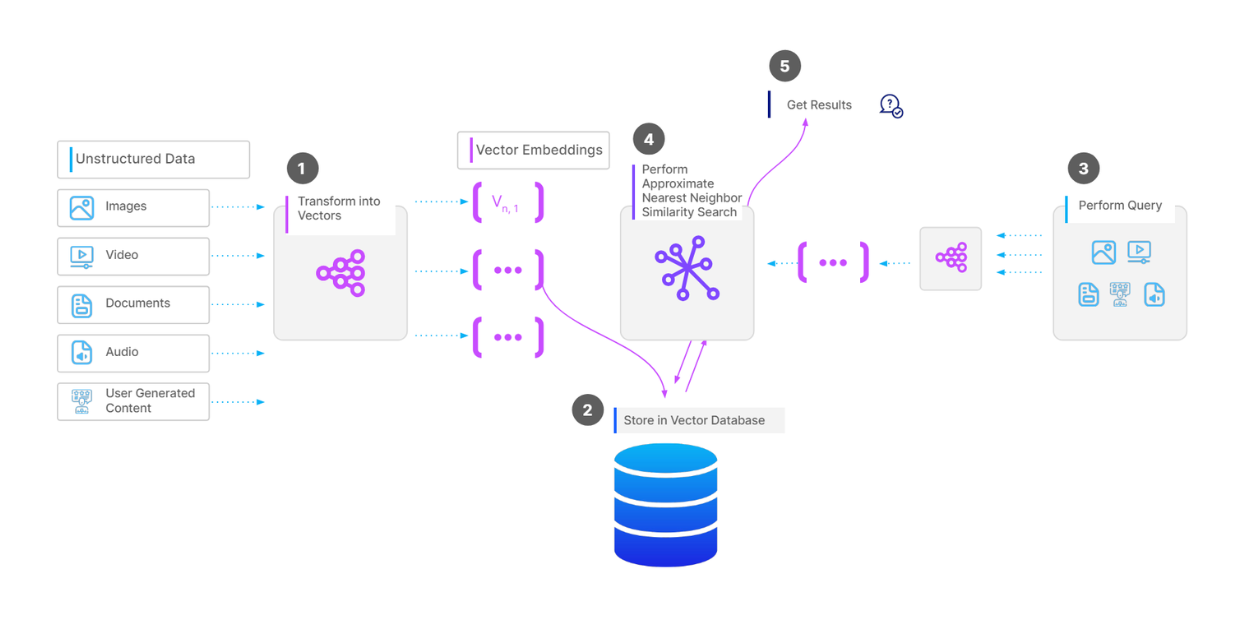
CPUは、費用対効果が高く、AIアプリケーションの他のコンポーネントとの統合が容易であるため、ベクトル検索演算のための一般的な処理ユニットである。多くのベクトル検索アルゴリズムはCPUに完全に最適化されており、Hierarchical Navigable Small World (HNSW)は最もポピュラーなものである。
HNSWは、スキップリストとNavigable Small World (NSW)の概念を組み合わせたものである。NSWアルゴリズムでは、まずデータ点をランダムにシャッフルしてグラフを構築する。次にデータ点を1つずつ挿入し、各点はあらかじめ定義された数のエッジを通して最近傍と接続される。
 HNSWを使ったベクトル探索.png
HNSWを使ったベクトル探索.png
HNSWを使ったベクトル探索.png]()
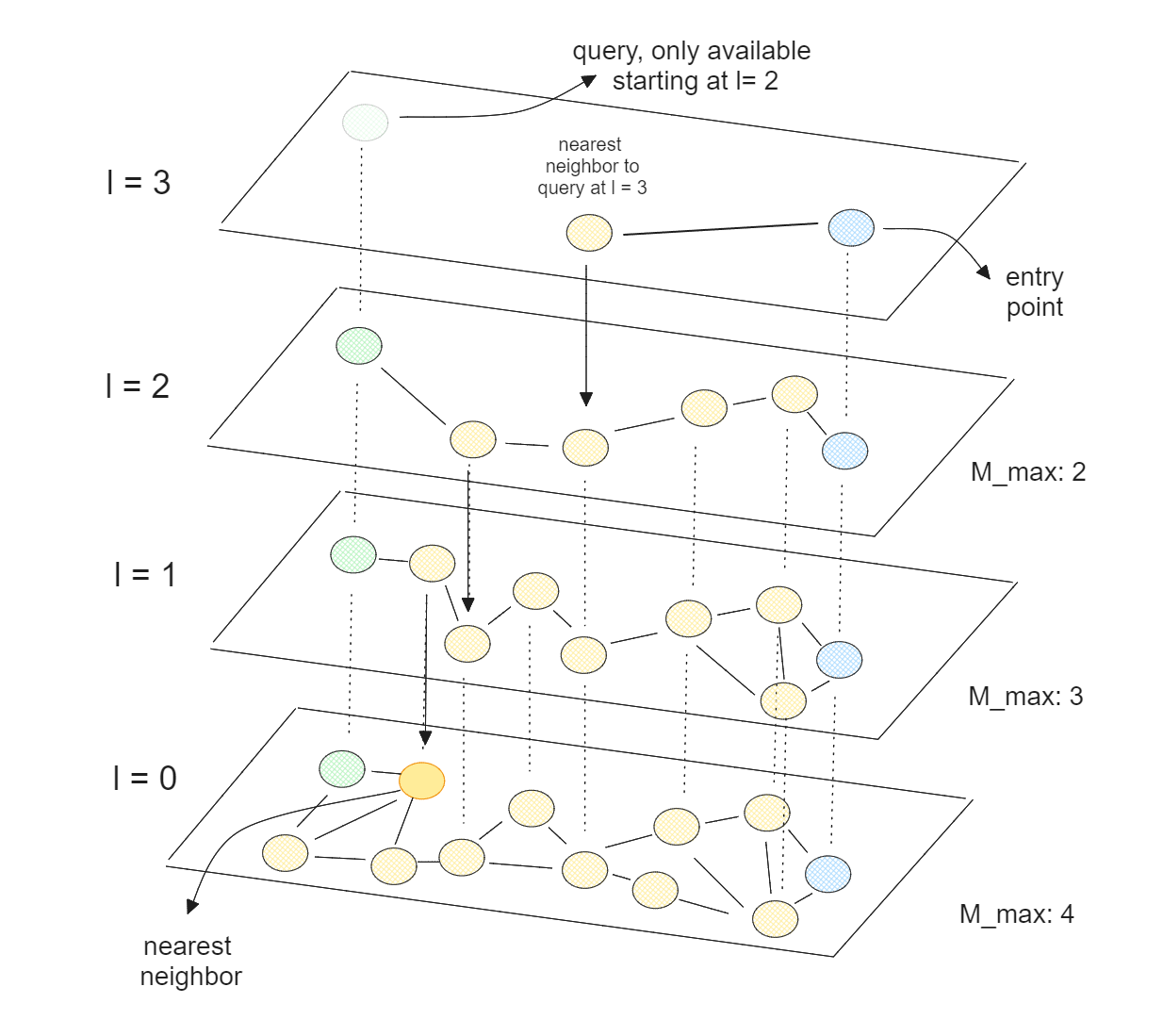
HNSWは多層NSWであり、最下層にはすべてのデータ点が含まれ、最上層にはデータ点のごく一部しか含まれない。HNSWは多層NSWであり、最下層にはすべてのデータ点が含まれ、最上層にはデータ点のごく一部しか含まれない。つまり、高層になるほど、より多くのデータ点をスキップすることになり、これはスキップリストの理論に対応する。
HNSWでは、ほとんどのノードが他のどのノードからも少ない反復回数で到達できるグラフを持つ。この性質により、HNSWはグラフを効率的に素早く移動し、近似最近傍を見つけることができる。HNSWはCPUに最適化されているため、複数のCPUコアにまたがって並列実行することで、ベクトル探索処理をさらに高速化することもできる。
しかし、HNSWの計算時間は、ベクトル・データベース内に格納するデータが多くなるにつれて悪化する。ベクトルの次元数が非常に高い場合は、さらに悪化する可能性があります。したがって、高次元の膨大な数のベクトルがある場合には、別の解決策が必要になります。
GPU上でのベクトル探索操作
膨大な数の高次元ベクトルを扱う場合のベクトル検索のパフォーマンスを向上させる1つの解決策は、GPU上で操作することです。**これを容易にするために、NVIDIAのRAPIDS cuVSを利用することができます。cuVSはGPUに最適化されたベクトル検索の実装をいくつか含むライブラリです。
cuVSは、以下のようないくつかの最近傍アルゴリズムを提供しています:
ブルートフォース:Brute-force:クエリとデータベース内の各ベクトルを比較する網羅的最近傍探索。
IVF-Flat**:近似最近傍(ANN)アルゴリズムで、データベース内のベクトルをいくつかの交差しないパーティションに分割する。クエリは、同じ(そしてオプションで隣接する)パーティション内のベクトルとのみ比較される。
IVF-PQ:IVF-PQ: IVF-Flatの量子化バージョンで、データベースに格納されたベクトルのメモリフットプリントを削減します。
cagra**](https://zilliz.com/blog/Milvus-introduces-GPU-index-CAGRA):HNSWに似たGPUネイティブアルゴリズム。
 CAGRAグラフ構築. .png
CAGRAグラフ構築. .png
CAGRAグラフ構築. ソース._.
これらの最近傍アルゴリズムのうち、ここではCAGRAに注目する。
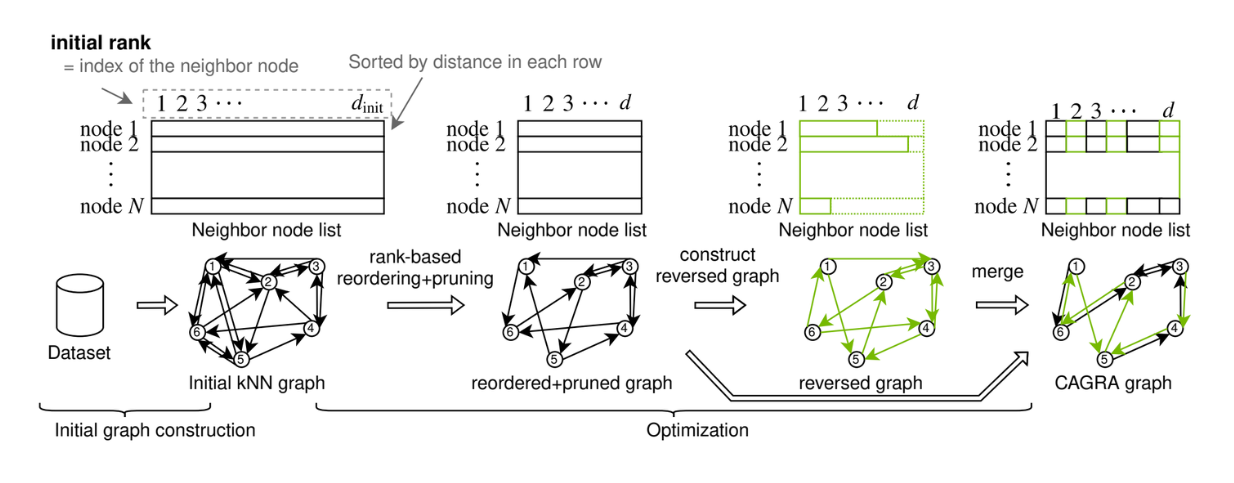
CAGRAは、GPUの並列処理能力を活用し、高速で効率的な近似最近傍探索のためにNVIDIAによって導入されたグラフベースのアルゴリズムです。
CAGRAのグラフは、IVF-PQ法またはNN-DESCENT法を用いて構築することができます:
IVF-PQ法:IVF-PQ法:インデックスを利用し、各点を多数の近傍に接続することで、メモリ効率の高い初期グラフを作成します。
NN-DESCENT法:NN-DESCENT法:点間の接続を拡張し、洗練することによってグラフを構築する反復プロセスを使用する。
HNSWと比較して、CAGRAのグラフ構築メソッドは並列化が容易で、タスク間のデータ相互作用が少ないため、グラフまたはインデックス構築時間が大幅に改善される。CAGRAについてもっと詳しく知りたい方は、 公式論文 または CAGRAの記事 をご覧ください。
CAGRAはベクトル検索操作において最先端の性能を設定した。これを実証するために、次のセクションでHNSWとその性能を比較する。
CAGRA と HNSW の性能比較
ベクトル検索には、インデックス構築と検索という2つの重要な操作がある。この2つの作業におけるCAGRAとHNSWの性能を比較する。
まずインデックス構築から始めよう。
インデックス構築時間の比較 CAGRA vs HNSW..png](https://assets.zilliz.com/Index_building_time_comparison_CAGRA_vs_HNSW_f6fcb14b30.png)
インデックス構築時間の比較 CAGRA vs HNSW.
上の可視化では、CAGRAとHNSWのインデックス構築時間を2つの異なるシナリオで比較しています。1つ目はベクトルデータベースに格納された10M個の128次元ベクトル、2つ目は1M個の768次元ベクトルです。1つ目のシナリオでは、HNSWのCPUにAMD Graviton2、CAGRAのGPUにA10Gを使用し、2つ目のシナリオでは、HNSWのCPUにIntel Xeon Ice Lake、CAGRAのGPUにA10Gを使用した。
80%から99%の範囲で4つの異なるリコール値におけるインデックス構築時間を比較する。すでにご存知かもしれないが、リコールが高いほど、より集中的な計算が必要となる。
これはグラフベースのベクトル探索において、2つの要素を微調整することができるからである:各レイヤーで最近傍を見つけるために考慮する近傍の数と、各レイヤーのエントリーポイントとして考慮する最近傍の数である。リコールが高ければ高いほど、より多くの近傍が考慮され、検索精度は高くなるが、計算コストも高くなる。
上記の可視化から、高い検索結果を得たい場合、GPUを使用する価値があることがわかります。また、ベクトル・データベースに格納される高次元ベクトルの数が増えるにつれて、GPUを使用することによる高速化は増加します。
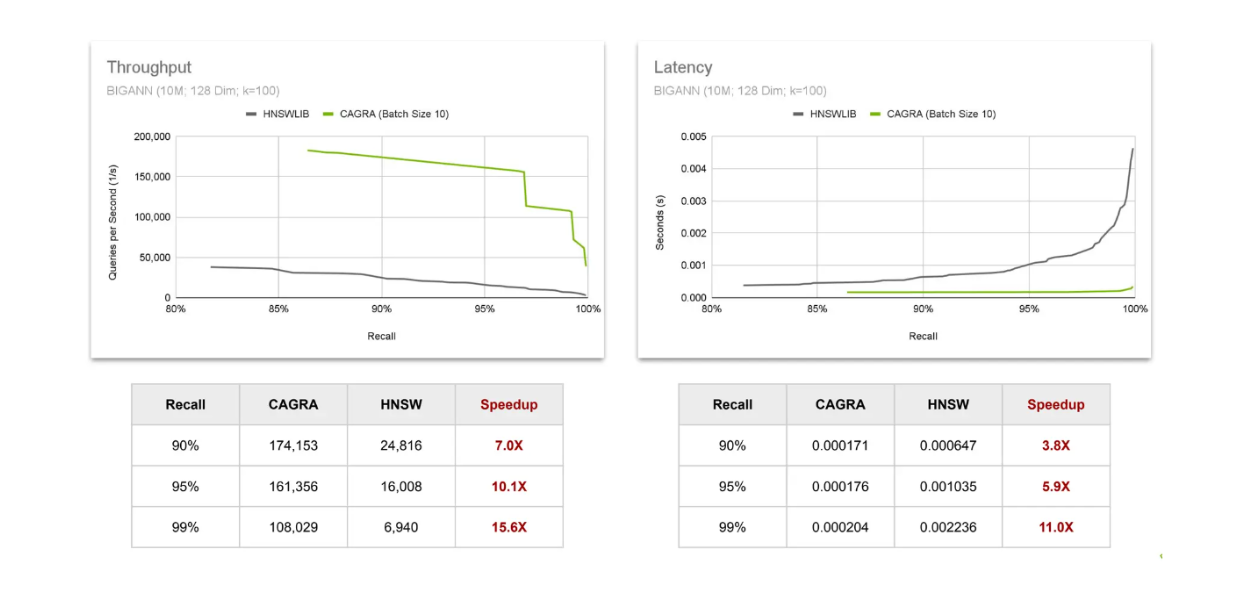
次に、HNSWとCAGRAの性能を、ベクトル検索で一般的な2つのメトリクスを使って比較してみましょう:
スループット**:特定の時間間隔で完了できるクエリの数。
レイテンシ**:アルゴリズムが1つのクエリを完了するのに必要な時間。
 スループットとレイテンシーの比較 CAGRA vs HNSW..png
スループットとレイテンシーの比較 CAGRA vs HNSW..png
スループットとレイテンシーの比較 CAGRA vs HNSW.png]()
スループットを評価するために、1秒間に完了できるクエリの数を観察する。結果は、GPU上でCAGRAを使用することによるスピードアップが、より高い想起値の結果を必要とするほど増加することを示している。レイテンシについても同じ傾向が観察され、リコール値が増加するにつれてスピードアップが増加する。このことは、ベクトル検索からより正確な結果を求めるほど、GPUを使用する価値が高まることを裏付けている。
しかし、AIアプリケーションのシンプルさや他のコンポーネントとの統合のしやすさから、ベクトル探索時にCPUを使用したい場合もあります。この場合、GPUとCPUの両方でベクトル検索を実行できるため、CAGRAで最近傍アルゴリズムを実装することは有用である。
HNSWネイティブとCAGRAグラフのスループット比較.png](https://assets.zilliz.com/Throughput_comparison_between_HNSW_native_vs_CAGRA_graph_used_in_HNSW_search_c44ecbf71d.png)
HNSW検索で使用されるHNSWネイティブとCAGRAグラフのスループット比較.png]()
このアイデアは、インデックス構築時にはCAGRAとGPUの加速能力を使用し、ベクトル検索時にはHNSWに切り替えるというものである。この方法が可能なのは、HNSWアルゴリズムがCAGRAで構築されたグラフを使用して検索を実行でき、ベクトル次元が大きくなるにつれてその性能がHNSWで構築されたグラフよりもさらに向上するからである。
CAGRAはまた、格納されたベクトルのメモリをさらに圧縮するために、CAGRA-Qと呼ばれる量子化手法を提供している。これは特にメモリ割り当てを効率化するのに役立ち、量子化されたベクトルをより小さなデバイスメモリに格納し、より高速な検索を可能にする。
例えば、ホスト・メモリに比べてメモリ・サイズが小さいデバイス・メモリがあるとします。NVIDIAの初期性能ベンチマークによると、ホスト・メモリにグラフを格納した状態でデバイス・メモリに格納された量子化済みベクトルは、デバイス・メモリに格納された量子化されていない元のベクトルとグラフと比較して、高い想起率で同等の性能を発揮することが示されました。
デバイスメモリとCAGRA-Qを利用したベクトル探索ワークフロー.png](https://assets.zilliz.com/Vector_search_workflow_by_utilizing_device_memory_and_CAGRA_Q_f299b007be.png)
デバイスメモリとCAGRA-Q.pngを利用したベクトル検索ワークフロー
CuVS によるGPU上のMilvus
Milvus cuVSライブラリとの統合をサポートしており、MilvusとCAGRAを組み合わせてAIアプリケーションを構築することができます。 Milvusのアーキテクチャは、インデックスノード、クエリノード、データノードなどの複数のノードで構成されています。cuVSは、クエリノードやインデックスノード内の処理を高速化することで、Milvusのパフォーマンスを最適化します。
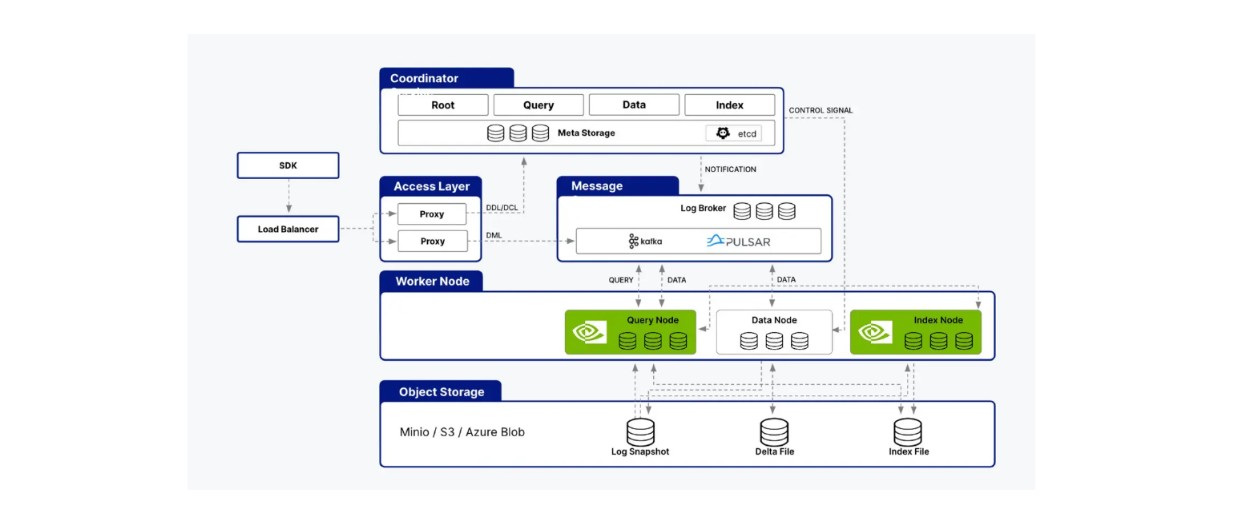 cuVSはMilvusアーキテクチャのクエリノードとインデックスノードの両方をサポートします。.png
cuVSはMilvusアーキテクチャのクエリノードとインデックスノードの両方をサポートします。.png
cuVSはMilvusアーキテクチャのクエリノードとインデックスノードの両方をサポートします。
既にご存知かもしれないが、インデックスノードはインデックス構築を担当し、クエリノードはユーザクエリを処理し、ベクトル検索を実行し、結果をユーザに返す。前のセクションで、CAGRAがHNSWのようなネイティブCPUアルゴリズムと比較して、どのようにこれらの側面を改善するかを見てきた。
次に、cuVSとオンプレミスのMilvusによるインデックス構築のパフォーマンスを検証してみよう。具体的には、CAGRAとIVF-PQを使用したインデックス構築時間を異なるベクトル数で見てみる:1,000万、2,000万、4,000万、8,000万である。
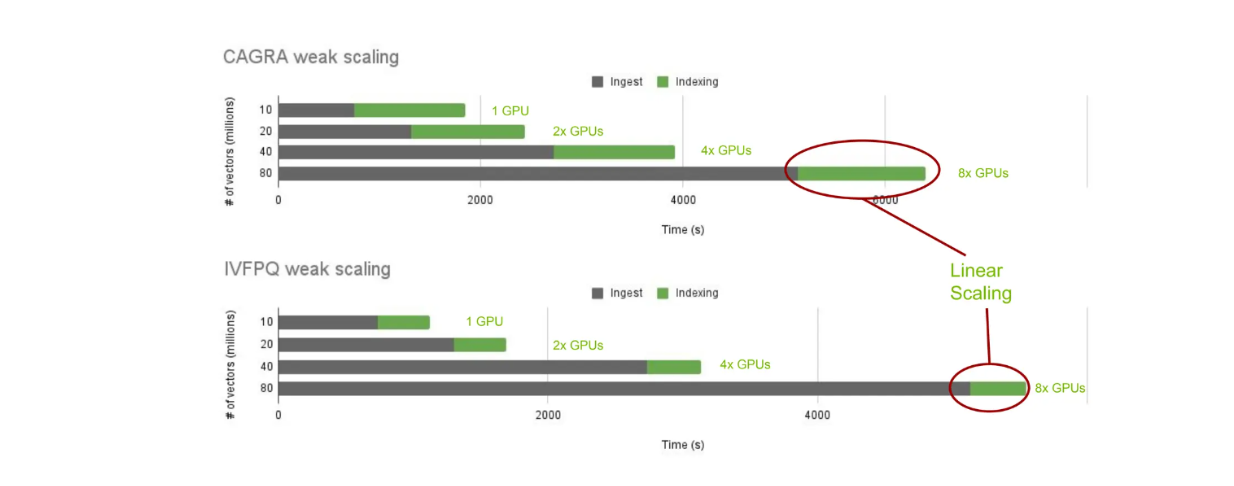 異なる最近傍アルゴリズムにおけるインデックス構築時間のcuVSスケーリング.png
異なる最近傍アルゴリズムにおけるインデックス構築時間のcuVSスケーリング.png
様々な最近傍アルゴリズムにおけるインデックス作成時間のcuVSスケーリング.png](_)
予想通り、インジェスト時間は格納ベクトル数が増加するにつれて増加します。しかし、格納されたベクトル数に応じてGPUを線形に追加すると、インデックス構築時間は一定に保たれます。これにより、cuVSを使用して異なる最近傍アルゴリズム間でインデックス構築時間をスケールして比較することができます。
我々はGPUがCPUに比べて高速な計算処理を提供することを知っています。しかし、GPUを使用する運用コストも高くなります。そのため、GPUとCPUのコストパフォーマンスをMilvusで比較する必要があります。
GPUとCPUのインデックス構築時間比較.png](https://assets.zilliz.com/Milvus_index_building_time_comparison_between_GPU_and_CPU_3bb7e13b41.png)
GPUとCPUのMilvusインデックス構築時間比較.png]()
GPUを使用したインデックス構築時間はCPUよりも大幅に高速です。このユースケースでは、GPUで加速されたMilvusは、CPUと比較して21倍のスピードアップを実現しています。しかし、GPUの運用コストはCPUよりも高い。GPUは1時間当たり16.29ドルかかるのに対し、CPUは1時間当たり9.68ドルだ。
GPUとCPUのコスト・パフォーマンス比を正規化すると、インデックス構築にGPUを使用した方が良い結果が得られます。同じコストで、GPUを使った場合のインデックス構築時間は12.5倍速い。
別のベンチマークテストでは、635M個の1024次元ベクトルのインデックスを構築しました。8台のDGX H100 GPUを使用した場合、IVF-PQ法によるインデックス構築にかかる時間は約56分でした。一方、CPUを使用して同じタスクを実行すると、完了までに約6.22日かかります。
GPUとCPUの大規模Milvusインデックス構築時間比較.png](https://assets.zilliz.com/Large_scale_Milvus_index_building_time_comparison_between_GPU_and_CPU_c987afe852.png)
GPUとCPUの大規模Milvusインデックス構築時間比較.png](_)
結論
NVIDIA の cuVS ライブラリと CAGRA アルゴリズムによる GPU 加速ベクトル探索の進歩は、実運用における AI アプリケー ションのパフォーマンスを最適化する上で非常に有益です。具体的には、GPU は、高い想起値、高いベクトル次元、および多数のベクトルを含む場合に、CPU よりも大幅な改善を提供します。
Milvusの統合機能のおかげで、cuVSをMilvusベクトルデータベースに簡単に組み込むことができるようになりました。GPUはCPUよりも運用コストが高いものの、上記のベンチマークで実証されているように、大規模なアプリケーションでは性能コスト比は依然としてGPUに有利なことが多い。cuVSについてもっと知りたい方は、NVIDIAチームが提供する 包括的なドキュメントを参照してください。
その他のリソース
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ベクターデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
RAGパイプラインのパフォーマンスを向上させる方法](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
RecSysにおけるMilvusとNVIDIA Merlinを用いた効率的なベクトル探索](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)

読み続けて

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.