




RAGアプリケーションを構築する際のメタデータフィルタリング、ハイブリッド検索、エージェント
RAGとは?
Retrieval Augmented Generation(RAG)とは、追加データソースを統合することでLLMを強化する技術である。典型的なRAGアプリケーションには以下が含まれる:
インデックス作成** - データソースからデータを取り込み、インデックスを作成するパイプライン。
検索と生成** - 実行時に、RAGはユーザーのクエリを処理し、Milvusに格納されたインデックスから関連データをフェッチし、LLMはこのエンリッチされたコンテキストに基づいてレスポンスを生成する。
RAGアプリケーションを改善する方法は様々です。本ブログでは、MilvusベクトルデータベースのMetadata Filtering、Hybrid Search、Agent機能により、RAGアプリケーションのパフォーマンスをどのように向上させることができるかについて説明します。
メタデータフィルタリング
Milvusにデータを挿入する際、データに関するメタデータを含めると便利です。例えば、PDFを扱う場合、ベクターが属するページ、PDFファイル名、作者などを挿入することができます。
Milvusにメタデータを保存することで、無関係なデータをフィルタリングし、検索をより迅速かつ効率的に行うことができます。このアプローチはRAGアプリケーションで特に有用で、ユーザクエリに関連するコンテンツのみをLLMに返すことができます。
Milvusは完全な文字列メタデータマッチングをサポートしており、prefix、infix、postfix、さらには文字ワイルドカード*検索を使用して文字列をマッチングすることが可能です。
# プレフィックスの例。"The "で始まる文字列にマッチします。
expression='title like "The%"'.
# 接尾辞の例: 文中の "the "を含む文字列にマッチします。
expression='「%the%」のようなタイトル'
# Postfixの例: "Rye "で終わる文字列にマッチします。
expression='「%Rye」のようなタイトル'
# 1文字のワイルドカードの例.
expression='title like "Flip_ed"'.
また、配列の値を使用することも可能です。 完全にマッチさせることもできますし、contains_any()で配列の要素がマッチするかどうかをチェックすることもできます。
ハイブリッド検索
Milvusでは1つのデータセットコレクションで最大10個のベクトルフィールドを使用することができます。このサポートによりハイブリッド検索が可能になり、ユーザーは複数のベクトル列を同時に検索することができます。この機能により、マルチモーダル検索、ハイブリッドスパース&デンス検索、ハイブリッド・デンス・フルテキスト検索が容易になり、多用途で柔軟な検索機能を提供します。
異なる列のベクトルは、異なる処理方法を持つ異なる埋め込みモデルによって生成されたデータの様々な側面を表す。ハイブリッド検索結果は、様々な再順位付け戦略を用いて結合され、再順位付けされる。
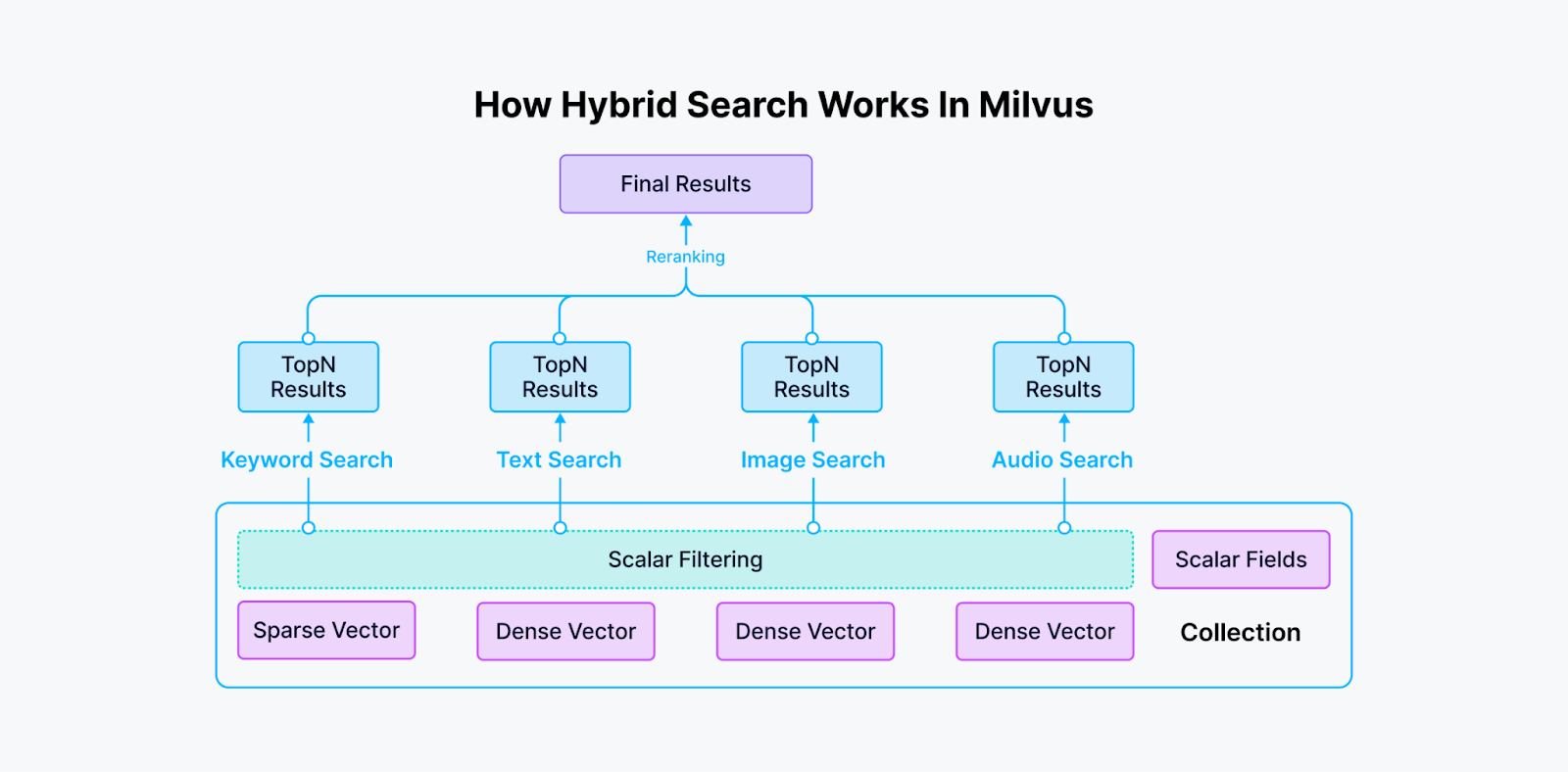
Milvusにおけるハイブリッド検索の仕組み
情報の複数の視点を表現する。例えば、eコマースでは、商品画像には正面、側面、上面が含まれます。異なるビューは、異なるタイプまたは次元のベクトルで表現することができます。
様々なタイプのベクトル埋め込みを利用する。これには、BERTやTransformersのようなモデルによる密な埋め込みや、BM25、BGE-M3、SPLADEのようなアルゴリズムによる疎な埋め込みが含まれる。
画像、動画、音声、テキストファイルなど、様々な非構造化データからのマルチモーダルベクトルの融合をサポートする。例えば、犯罪捜査では、指紋、声紋、顔認識などのバイオメトリック・モダリティを通じて容疑者を表現することができ、異なるモダリティにまたがる個人の識別を支援する。
ベクトル検索と全文検索の融合をサポート。
RAGアプリケーションにおけるエージェント
大規模な言語モデルは、それ自身がアクションを起こすことはできない。エージェントは、LLMを推論エンジンとして使用し、どのアクションを取るか、どの入力を渡すかを決定するシステムである。アクションを実行した後、その結果をLLMに送信し、さらにアクションが必要か、あるいは終了しても問題ないかを判断することができる。
LLMは、ウェブ検索、電子メールの閲覧、RAGの修正、検索された文書に対する自己反省や自己採点の追加など、さまざまなアクションを実行するために使用できます。
一度セットアップすれば、エージェントが新しいデータをMilvusに追加することができます。これにより、RAGシステムは常に最新の状態に保つことができる。また、Milvusでは upsert() 関数を使用することで、必要に応じて簡単にデータを更新することができます。
必要な情報のみをupsertすることができるので、コレクションにメタデータを持つことが重要なのはこのためです。
LangGraph、Llama 3、Milvusを使ったLocal Agentic RAGシステムの構築方法を紹介したブログをご覧ください。
結論
結論として、Milvusに統合されているメタデータフィルタリング、ハイブリッド検索、エージェントを使用することで、RAGアプリケーションを強化することができます。
メタデータフィルタリングにより、付加的な属性でデータを充実させることができ、正確で効率的な検索が可能になります。ハイブリッド検索は、複数のベクトルカラムにまたがるクエリーを可能にすることで、検索機能を拡張します。エージェントは、LLMの出力に基づいてアクションを自動化することで、機能をさらに一歩進めます。
これらのストラテジーを使用して、より堅牢で効率的なRAGアプリケーションを構築することができます。
このブログ記事を楽しんでいただけたなら、Githubで私たちに星を与え、Discordに参加してあなたの経験をコミュニティと共有することをご検討ください。

読み続けて

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.