




🚀 What’s New with Metadata Filtering in Milvus v2.4.3
Milvus v2.4.3 introduced full-string metadata matching! 🎉 Now, you can match strings using prefix, infix, postfix, or even character wildcard searches.
# Prefix example, matches any string starting with “The”.
expression='title like "The%"'
# Infix example, matches any string with the word “the” anywhere in the sentence.
expression='title like "%the%"'
# Postfix example, matches any string ending with “Rye”.
expression='title like "%Rye"'
# Single character wildcard example, matches any one single character at a specific position.
expression='title like "Flip_ed"'
In earlier blogs, we only talked about prefix string matching. However, since Milvus v2.4.3, all the variations are possible as well as using array values, either by exact matches or by checking if any elements in the array match (contains_any()). 🗂️🔍
These updates make metadata filtering more versatile and powerful!
Let’s make all this clearer with an example. I’ll use IMDB movie data for this blog, which I downloaded from Kaggle.
# Import common libraries.
import sys, os, time, pprint
import pandas as pd
# Read CSV data.
df = pd.read_csv("data/original_data.csv")
# Shortcut the data for demo.
df = df.tail(200)
display(df.head())

Each movie has a ‘text’ field with its description and reviews. 📝
Each movie includes metadata like the release year, rating, and lists of genres, actors, and keywords. 🎬⭐️📅
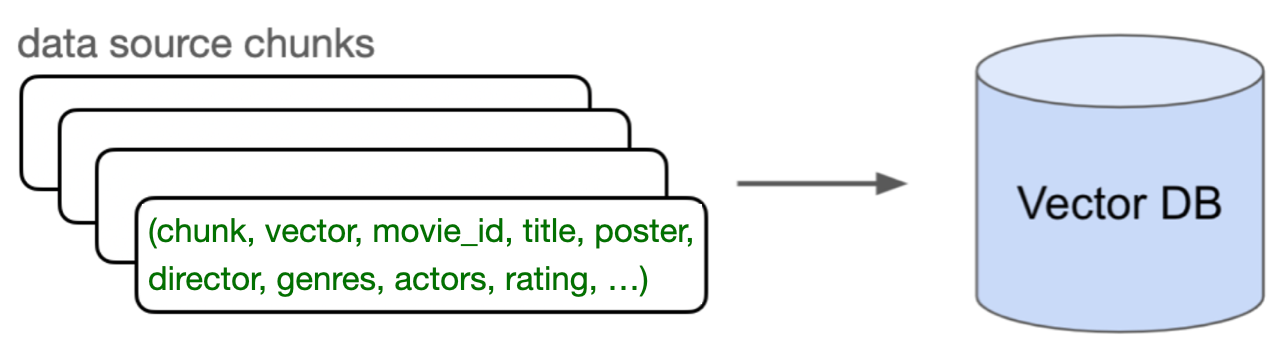
Each “row” represents a movie review chunk of text, its vector representation, and metadata such as movie_id, movie title, poster link, genres, and actors.
Following the usual RAG pattern: 📝🎬
Connect to Milvus: First, connect to Milvus Lite, the local deployment of Milvus. This is our database for storing and managing vectors. 🖥️🔗
Transform Movie Text to Vectors: Take each movie's text field, which includes the description and review, and transform it into a vector. We'll use the HuggingFace model BAAI/bge-large-en-v1.5 for this. 🧠➡️📏
📥📊 Insert Vectors and Metadata into Milvus: Insert this vector, along with the original text (called the “chunk”) and its metadata (like year, rating, genres, etc.) into Milvus. 📥📊
Handle User Queries: Transform the user’s query into a vector using the same embedding model. Then, run an Approximate Nearest Neighbors search to find the closest data vectors to the query vector. 🔍🎬
You can find the full code on my GitHub.
First, connect to Milvus. You’ll need to pip-install Pymilvus. (By specifying just a local file name, it uses Milvus Lite, a local vector database. If you have other Milvus, such as docker or K8s deployed or fully managed Zilliz Cloud, you can specify the URI and Token to connect to them. The rest of the code works the same.)
# !python -m pip install -U pymilvus
import pymilvus
# Connect a client to the Milvus Lite server.
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
Next, chunk and embed the text column containing the movie review into vectors. Many resources give examples of how to do that, so I won’t show the code again here. Below, I show how to assemble the chunked text, vector representation, and metadata, and insert the data into Milvus.
# Create chunk_list and dict_list in a single loop
dict_list = []
for id, title, chunk, vector, poster_url, director,\
genres, actors, keywords, film_year, rating in zip(
df.id, df.Name, chunks, converted_values, df.PosterLink,
df.Director, df.Genres, df.Actors, df.Keywords,
df.MovieYear, df.RatingValue):
# Assemble embedding vector, original text chunk, metadata.
chunk_dict = {
'movie_index': id,
'title': title,
'chunk': chunk.page_content,
'poster_url': poster_url,
'director': director,
'genres': genres,
'actors': actors,
'keywords': keywords,
'film_year': film_year,
'rating': rating,
'vector': vector,
}
dict_list.append(chunk_dict)
# Insert data into the Milvus collection.
print("Start inserting entities")
start_time = time.time()
client.insert(
COLLECTION_NAME,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f"Milvus insert time for {len(dict_list)} vectors: ", end="")
print(f"{np.round(end_time - start_time, 2)} seconds")

Now that the data is in Milvus, we are ready to search!
Search Using String Metadata Filters
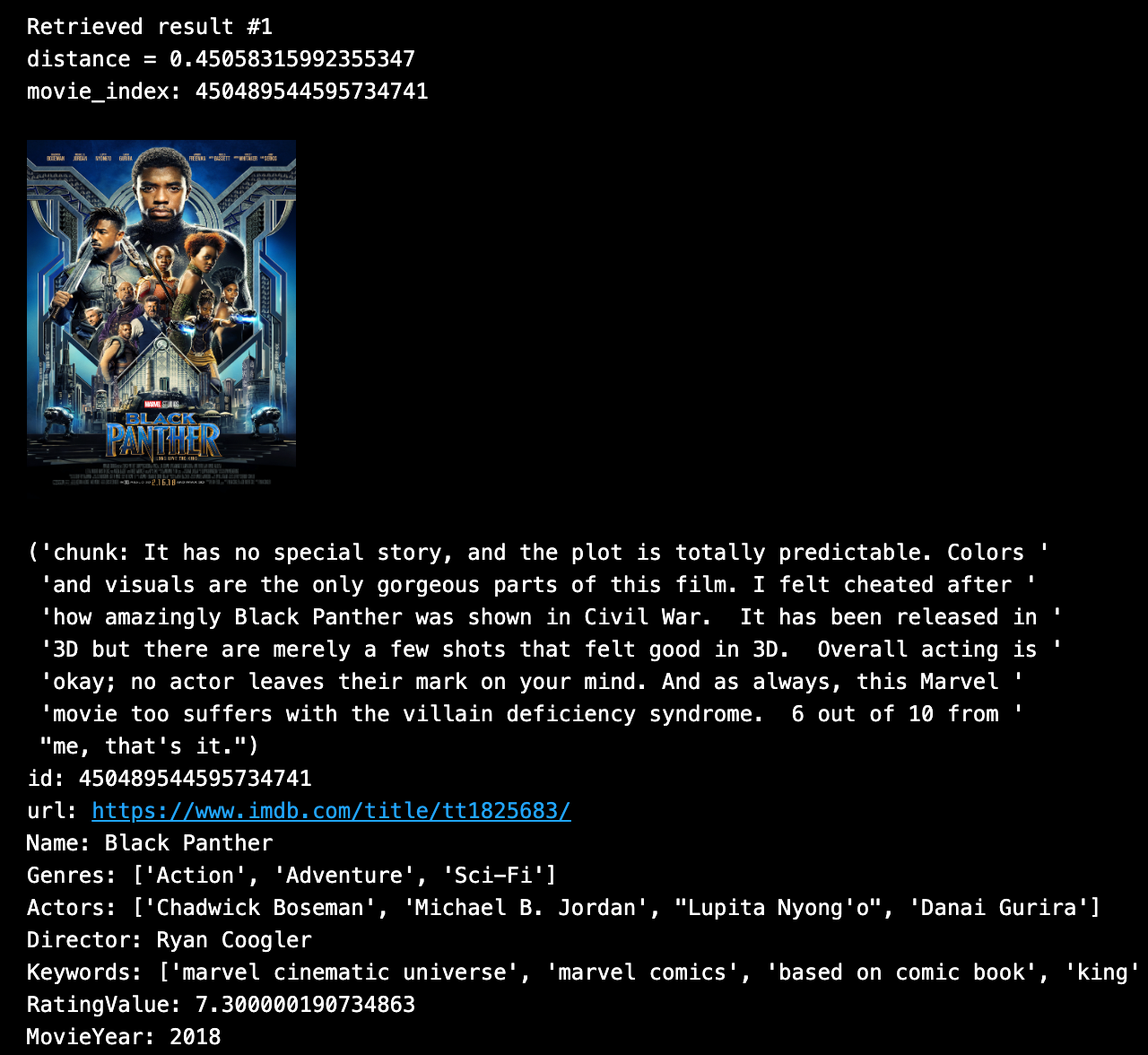
Let’s say we want to find Sci-Fi movies that have a dystopian future with robots and are highly rated. Our example data has metadata we can use for this search.
Here is an example of metadata filtering using fuzzy string matches. Below, I’ve wrapped the vanilla Milvus search API only to display metadata more easily after each search.
SAMPLE_QUESTION = "Dystopia science fiction with a robot."
TOP_K = 1
# Metadata filters.
expression='rating >= 7'
# Infix string match.
expression=expression + ' && title like "%Panther%"'
formatted_results, contexts, context_metadata = \
mc_run_search(SAMPLE_QUESTION, expression, TOP_K)
Resources and Further Reading
Use Array Fields | Milvus Documentation
https://github.com/milvus-io/pymilvus/blob/2.4/examples/fuzzy_match.py
https://milvus.io/docs/boolean.md#Usage
https://milvus.io/docs/single-vector-search.md#Filtered-search

Keep Reading

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.