




カスタムAIモデルでRAGを拡張する際のインフラの課題
Retrieval Augmented Generation(RAG)システムは、より正確で文脈に関連した応答を提供することで、AIアプリケーションを大幅に強化してきた。しかし、これらのシステムがより洗練され、カスタムAIモデルが組み込まれるにつれて、本番環境でのスケーリングとデプロイメントにはかなりの困難が伴うようになった。
先日Zillizが主催したUnstructured Data Meetupで、BentoMLの創設者兼CEOであるChaoyu Yangは、カスタムAIモデルを持つRAGシステムをスケーリングする際のインフラのハードルに関する彼の洞察を共有し、BentoMLのようなツールがこれらのコンポーネントのデプロイと管理をいかに簡素化できるかを強調した。この投稿では、Chaoyu Yang氏の重要なポイントをまとめ、高度な推論パターンと最適化テクニックを探ります。これらの戦略は、パワフルなだけでなく、効率的で費用対効果の高いRAGシステムを構築するのに役立ちます。
RAGはどのようにAIアプリケーションを強化するか
GenAIアプリケーションにおける幻覚の問題に取り組むために、RAG(Retrieval Augmented Generation)システムが登場した。Milvus](https://zilliz.com/what-is-milvus)やZilliz Cloudのようなベクトルデータベースのベクトル類似性検索能力と大規模言語モデル(LLMs)の生成能力を統合することによって、RAGシステムはAIモデルが以下のような応答を生成することを可能にする:
より正確
文脈的に適切
非常に有益
幻覚がない
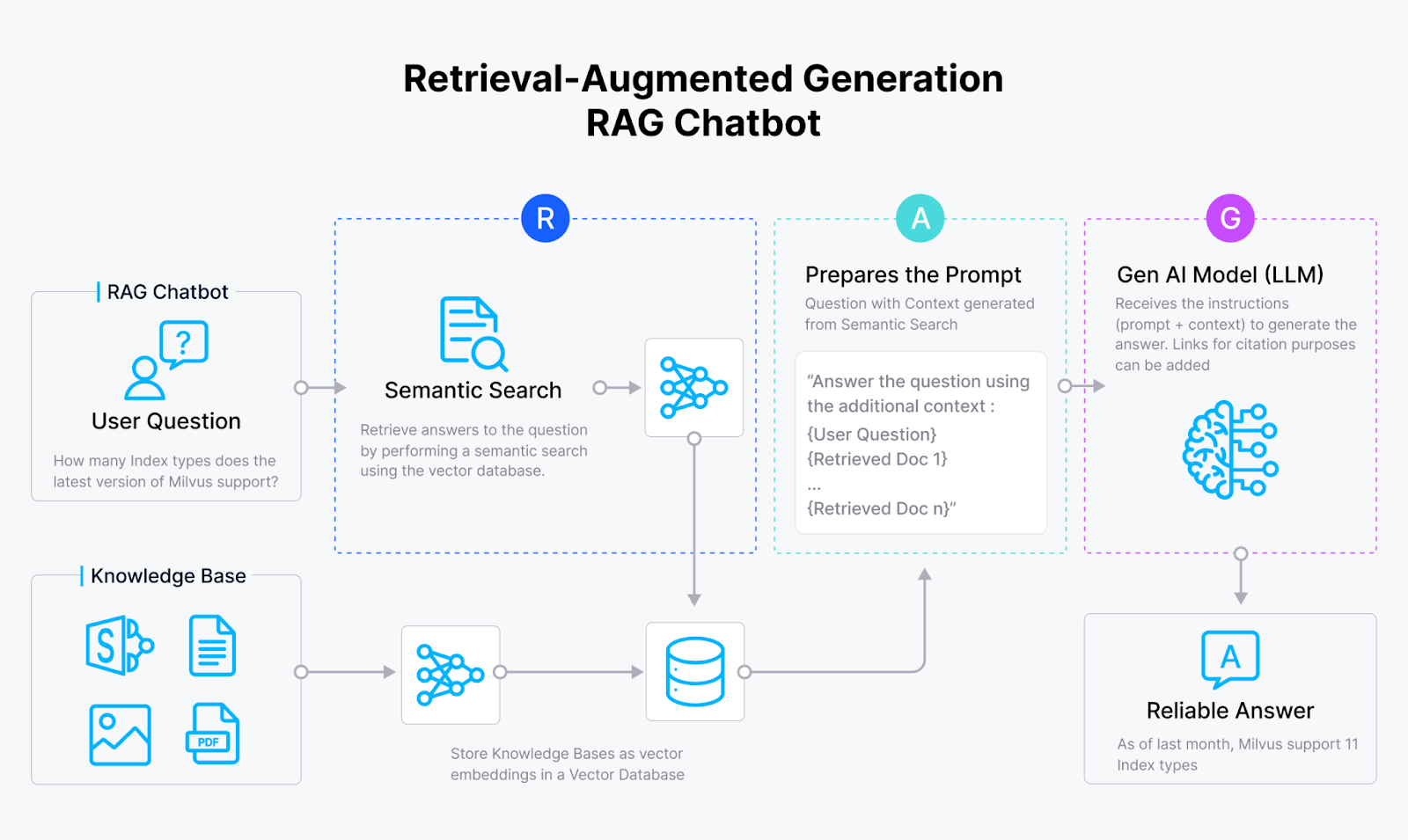
RAGチャットボットの仕組み
これらのシステムは、以下のような幅広い領域を変革する可能性を秘めている:
質問応答
文書要約
パーソナライズされたコンテンツ生成
その他
RAGシステムは、まるでAIライブラリアンのように、外部ソースに隠された膨大な知識を活用することで、この目標を達成する!
RAGシステムの本番導入における課題
RAGシステムには、本番環境で活躍するまでに克服すべき課題がある。最大のハードルの一つは、最高の検索パフォーマンスを確保することである:
リコールの最適化:**すべての関連情報が検索されていることを確認すること
精度の最適化:**無関係な情報を最小限に抑えること
さらに興味深いことに、RAGシステムは多くの場合、複雑で構造化されていないデータ・ソースを扱わなければならない。漫画本よりも多くのレイアウト、表、画像があるPDFを理解することを想像してみてください!この問題は、高度な文書処理と理解技術を必要とする。
RAGシステムが直面するもう一つの課題は、正確で、文脈的に適切で、ユーザーの意図に沿った応答を生成することである。それは、異なる本からの断片だけを使って首尾一貫した物語を書くようなものだ!
さらに、生成されたコンテンツの安全性と信頼性を確保することも、特に利害関係が大きい場合には極めて重要だ。AIシステムが暴走し、誤った情報を広めるようなことは避けたい!
カスタムAIモデルは、この物語における頼もしい相棒だ。特定のドメインやデータセットに合わせてAIモデルを微調整し適応させることで、開発者はRAGシステムに、これらの課題に正面から取り組むために必要なスーパーパワーを与えることができる。
カスタムAIモデルを活用してRAGのパフォーマンスを向上させる
RAGシステムの潜在能力を最大限に引き出すには、特定のユースケースに合わせたカスタムAIモデルを活用することが重要です。これらのモデルを微調整し最適化することで、パフォーマンスを大幅に向上させることができます。カスタムAIモデルが大きな効果を発揮する主な分野をいくつか探ってみよう。
テキスト埋め込みモデル:RAG成功の基盤
text-embedding-ada-002 "のようなデフォルトのテキスト埋め込みモデルは、しばしば私たちの特定のドメインのニュアンスを捕らえるのに不十分です。このモデルはMTEB leaderboardで57位にランクされており、改善の余地が大きいことを示しています。
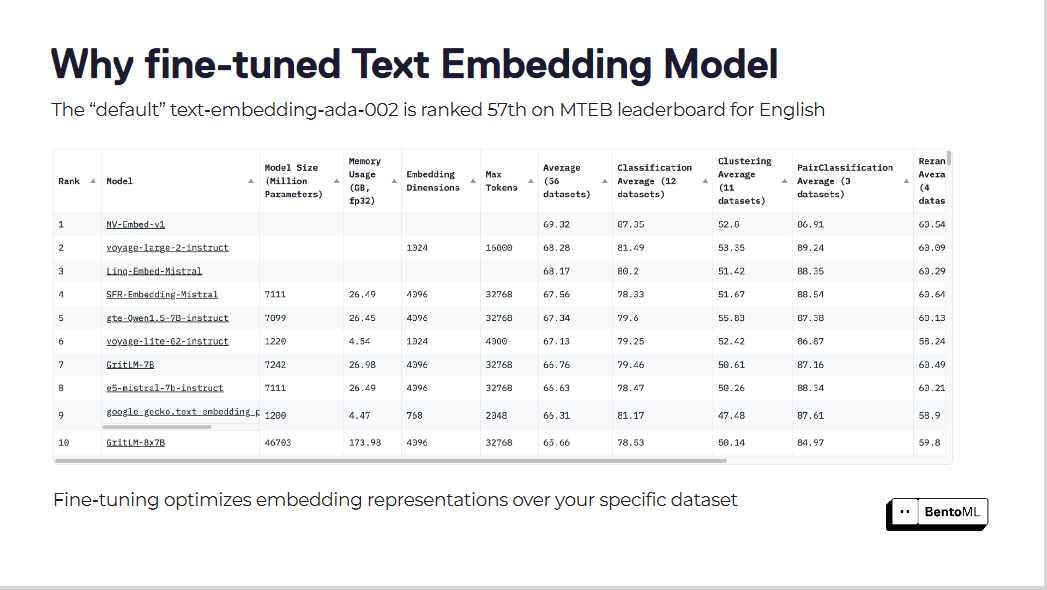
ファインチューニングにより、特定のデータセットに対する埋め込み表現を最適化する
これらの埋め込みモデルを微調整することで、検索スコアは著しく向上します。特定のデータセットに対して埋め込みモデルを最適化することで、RAGシステムは大幅な性能向上を実現しています。
LLMのホスティングコントロールする
プロプライエタリなLLMは便利ですが、必ずしも私たちのニーズや制約を満たしてくれるとは限りません。オープンソースのLLMは、我々の要求に合わせてモデルをカスタマイズし、適応させることができる。LLMをホスティングする際には、以下の重要な要素を考慮する必要があります:
セキュリティとデータプライバシー
レイテンシーとパフォーマンス
必要とされる特定の機能
コストと拡張性
メンテナンスとサポート
ドキュメントの処理と理解:非構造化データからの洞察の抽出
RAGシステムは、多くの場合、PDFや画像などの複雑で構造化されていないドキュメントを処理し、理解する必要があります。様々なモデルやテクニックを統合することで、価値ある洞察を引き出すことができます。例えば、以下のようなことが可能です:
LayoutLMによるレイアウト分析
テーブル・トランスフォーマーTATRによるテーブル検出
EasyOCRまたはTesseractによるOCR
LayoutLM v3またはDonutによるビジュアル文書QA
特定のドキュメントタイプに合わせてこれらのモデルを微調整することで、パフォーマンスを大幅に向上させることができます。
検索精度向上のための高度なテクニック
検索精度をさらに向上させるために、以下のようなテクニックの実装を検討することができる:
コンテキストを意識したチャンキングと大域的な概念を意識したチャンキング:** これらの手法は、文書内のコンテキストと包括的な概念を考慮することで、検索に最も関連性の高い情報を特定するのに役立つ。
メタデータの抽出:***文書からメタデータを抽出することで、検索と応答合成を強化するための追加コンテキストを提供することができる。
リランカーモデル:***カスタムデータセットでリランカーモデルを微調整することで、汎用モデルよりも10~30%パフォーマンスが向上する可能性がある。
これらの重要な領域でカスタムAIモデルを活用することで、RAGシステムのパフォーマンスを大幅に向上させることができます。
しかし、これらのモデルを効率的に展開し、提供することは、独自の課題をもたらします。次のセクションでは、カスタム・モデルを使用してRAGを拡張する際のインフラの課題について説明します。
カスタムモデルによるRAGのスケーリングにおけるインフラの課題
RAGシステムがより複雑になり、複数のカスタムモデルを組み込むようになると、計算リソースへの要求と効率的な展開と管理の必要性が著しく高まります。カスタムAIモデルによるRAG(Retrieval Augmented Generation)システムの拡張は緊急の要件となりますが、独自のインフラ課題が伴います。
カスタムモデル推論APIの効率的な提供
主な課題の1つは、カスタムモデル推論APIの効率的な提供です。RAG システムでは多くの場合、以下のような複数のモデルの統合が必要となる:
テキスト埋め込みモデル
大規模言語モデル(LLM)
文書処理モデル
それぞれのモデルは、異なる計算要件とパフォーマンス特性を持つ可能性がある。これらのモデルを、リアルタイムの要求に対応し、需要に応じて拡張できる推論APIとして展開することは複雑である。
この課題に対処するためには、モデルの推論APIを提供するための堅牢でスケーラブルなインフラを持つことが不可欠である。このインフラは、GPUの割り当て、メモリ管理、レイテンシの制約など、各モデル固有の要件を処理できなければなりません。Dockerのようなコンテナ化技術は、モデルの依存関係をカプセル化し、異なるシステム間で一貫した実行環境を提供するのに役立ちます。
効率的なスケーリングメカニズム
しかし、単にモデルをコンテナ化するだけでは十分ではありません。インフラストラクチャーは、さまざまなワークロードを処理するための効率的なスケーリングメカニズムもサポートしなければなりません。この要件には、入ってくるリクエストトラフィックに基づいてモデルインスタンス数を自動的にスケーリングすること、最適なリソース利用を確保すること、レスポンスタイムを最小化することなどが含まれます。
モデルサービングの最適化
もう一つの重要な課題は、パフォーマンスとコスト効率のためにモデルサービングを最適化することです。カスタムAIモデル、特に大規模な言語モデルは、計算コストが高くつきます。素朴なデプロイ戦略は、リソースの利用を最適化できず、コスト増につながる可能性があります。複数のリクエストをグループ化してGPUの並列性を活用するダイナミックバッチングのような技術は、スループットを大幅に改善し、応答時間を短縮することができます。
ダイナミックバッチングの他にも、量子化、プルーニング、モデル蒸留などの最適化テクニックを適用することで、カスタムモデルのメモリフットプリントと計算要件を削減することができます。しかし、これらの最適化を実行するには、モデルの性能とリソース効率のトレードオフを慎重に検討する必要があります。
効率的なリソース割り当てとオートスケーリング
効率的なリソース割り当てと自動スケーリングも、カスタムモデルを持つ RAG システムをスケーリングする上で重要な側面です。インフラストラクチャは、各モデルのワークロード要件に基づいて動的にリソースを割り当てることができなければなりません。このアプローチでは、GPU使用率、メモリ使用量、リクエスト・レイテンシなどの主要メトリクスを監視し、情報に基づいたスケーリング決定を行います。自動スケーリングメカニズムは、トラフィックの突然の急増に対応し、最適なパフォーマンスを維持するためにリソースを適宜スケーリングできなければなりません。
複数のモデルの構成とオーケストレーション
さらに、インフラストラクチャーはRAGシステム内の複数のモデルのコンポジションとオーケストレーションをサポートしなければならない。RAGシステムは、あるモデルの出力が別のモデルの入力となるような複雑なパイプラインを含むことが多い。インフラストラクチャーは、このようなパイプラインを定義・管理するためのツールやフレームワークを提供し、シームレスなデータフローと効率的な実行を保証しなければならない。
モニタリングと観測可能性
モニタリングと観測可能性は、カスタムモデルを持つ RAG システムの健全性とパフォーマンスを維持するために極めて重要である。インフラストラクチャは、すべてのシステム・コンポーネントにわたって主要なメトリクス、ログ、トレースを追跡する包括的なモニタリング機能を提供する必要があります。これにより、問題の迅速な検出と診断が可能になり、実世界のパフォーマンスデータに基づいてシステムを最適化し、微調整することができます。
継続的インテグレーションとデプロイメント(CI/CD)
最後に、インフラストラクチャーはカスタムモデルの継続的インテグレーションとデプロイメント(CI/CD)をサポートする必要があります。モデルが更新され、改良されるにつれて、システム全体を混乱させることなく、新バージョンをデプロイするための合理的なプロセスが確立されるべきである。これには、RAGシステムの安定性と信頼性を確保するための、堅牢なバージョニング、テスト、ロールバックのメカニズムが必要である。
このようなインフラの課題に対処するには、ツール、フレームワーク、ベストプラクティスを組み合わせる必要がある。次のセクションでは、機械学習モデルの提供およびデプロイのためのプラットフォームである BentoML が、どのようにこれらの課題に取り組み、カスタム AI モデルによる RAG システムのスケーリングを簡素化できるかを探ります。
BentoML によるカスタムモデルの推論 API の構築
BentoML は、RAG システムのカスタムモデル用の推論 API の構築とデプロイのプロセスを簡素化します。BentoMLは、モデル開発から本番環境に対応したAPIへのシームレスな移行を提供し、より迅速な反復と既存システムとの容易な統合を可能にします。RAGをスケールさせるためのインフラストラクチャの課題を克服するのに役立つ方法を見てみましょう。
推論スクリプトからサービングエンドポイントへ
わずか数行のコードで、推論スクリプトを BentoML を使って簡単にサービングエンドポイントに変換することができます。微調整されたテキスト埋め込みモデルのBentoMLサービスを作成する例を見てみましょう:
インポート torch
from sentence_transformers import SentenceTransformer, models
クラス SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model"、
device="cuda"
)
defエンコード(
self、
sentences: t.List[str]、
)-> np.ndarray:
return self.model.encode(sentences)
このコードスニペットでは、埋め込みモデルとそれに関連するメソッドをカプセル化するために SentenceTransformers クラスを定義している。_init__`メソッドの中で、SentenceTransformer`モデルが微調整されたモデルで初期化され、"cuda "デバイス上で実行されるように設定される。encode` ``メソッドは入力として文のリストを受け取り、それらの埋め込みをNumPyの配列として返します。
これをBentoMLサービスにするには、 @bentoml.service`` `` と @bentoml.api`` デコレータを追加する:
import bentoml
@bentoml.service
クラス SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model"、
device="cuda"
)
@bentoml.api
def encode(
self、
sentences: t.List[str]、
)-> np.ndarray:
return self.model.encode(sentences)
モデルを提供するには、BentoML CLIを使います:
bentoml serve .
このコマンドはBentoMLサーバーを起動し、カレントディレクトリに定義されたモデルにサービスを提供します。CLI の出力は、サービスが [http://localhost:3000](http://localhost:3000) で待ち受けていることを示しています。
BentoML クライアントを使用して、提供されたモデルに対してリクエストを行うことができます:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result: np.NDArray = client.encode(
sentences=["サンプル入力文"]、
)
サービングの最適化
BentoML はすぐに使えるサービスの最適化をいくつか提供しています。最も強力な最適化のひとつは動的バッチ処理です。API 定義に batchable=True` パラメータを追加することで、BentoML は受信したリクエストを自動的にバッチ処理し、GPU の使用率を最適化し、モデルサービングのスループットを向上させます。
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
ダイナミックバッチングは、入ってくるリクエストをグループ化し、大きなバッチを分解し、バッチサイズを自動調整することで、小さなバッチをインテリジェントに形成します。この最適化により、エンベッディングサービングのレスポンスタイムが最大3倍、スループットが最大200%向上する。
デプロイメントとサービング・インフラストラクチャ
BentoML は、柔軟でスケーラブルなデプロイメントとサービングのためのインフラを提供します。Docker によるコンテナ化や、Kubernetes によるオーケストレーションなど、さまざまなデプロイオプションをサポートしています。GPU の数や種類など必要なリソースを簡単に指定でき、同時実行や外部キューなどのトラフィック設定も可能です。
import bentoml
@bentoml.service(
resources={
"gpu":1,
"gpu_type":"nvidia-tesla-t4"、
},
traffic={
「concurrency":512,
"external_queue":真
}
)
クラス SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
BentoML のアダプティブ・マイクロバッチングとエラスティック・スケーリング機能は、最適なリソース利用を保証し、入力トラフィックに基づいて自動的にスケーリングします。また、ユーザーフレンドリーなデプロイメント・ダッシュボードを提供し、リクエスト・レート、レスポンス・タイム、リソースの利用状況を把握することができます。次に、BentoML を使って LLM 推論をスケーリングする方法を見てみましょう。
BentoML による LLM 推論サービスのスケーリング
BentoML は、LLM推論サービスを効率的にスケールするための包括的な機能と最適化を提供します。
自動スケール戦略
オートスケーリングは、LLM推論サービスがさまざまなワークロードに対応し、最適なパフォーマンスを維持できるようにします。しかし、GPU使用率や1秒あたりのクエリー数(QPS)といった従来のオートスケーリング・メトリクスは、LLMサービスに必要なレプリカ数を正確に反映していない場合があります。
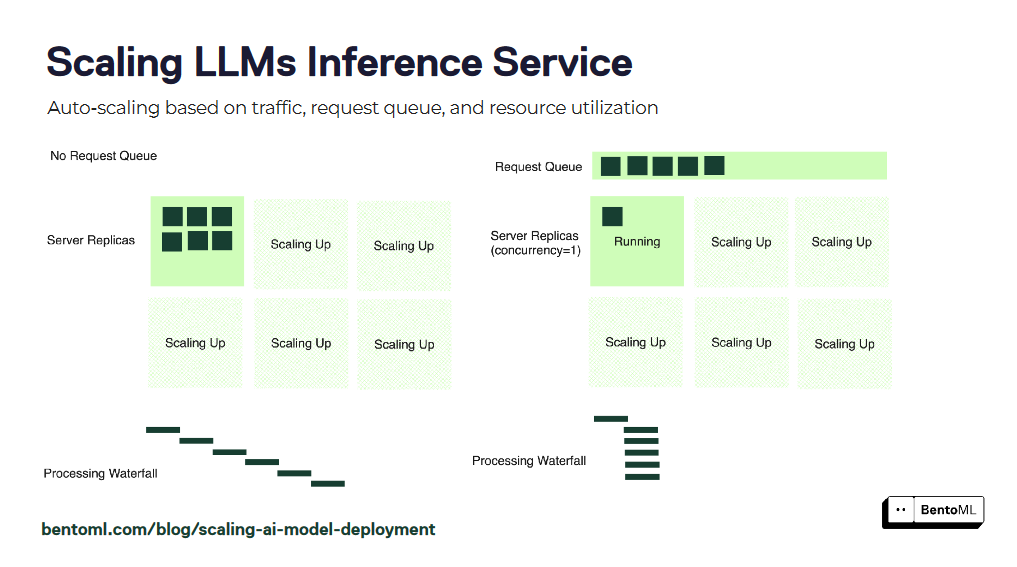
BentoMLは、LLM推論サービスをスケーリングするためのより効果的なアプローチとして、同時実行ベースのオートスケーリングを導入します。同時実行ベースのオートスケーリングは、各モデルのレプリカが処理できる同時リクエスト数を考慮し、サービスのキャパシティをより正確に表現します。
コールドスタートの最適化
コールドスタートは、LLM 推論サービスをスケーリングする際、特に大きなコンテナ・イメージやモデル・ファイルを扱う際に、大きな課題となる可能性があります。BentoML では、コールドスタートのレイテンシーを軽減するための最適化テクニックをいくつか提供しています。
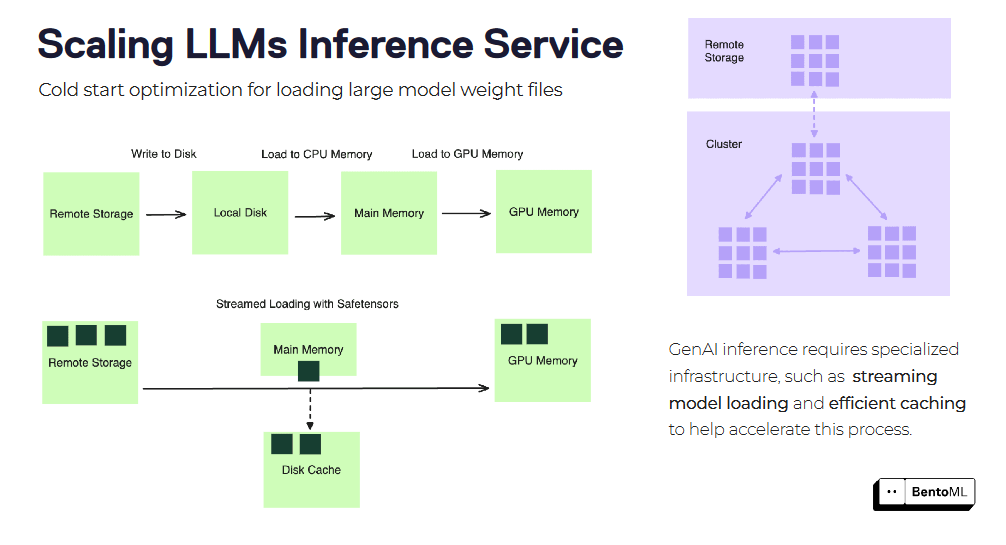
そのひとつが、コンテナ・イメージのストリーム・ロードです。サービスを開始する前にコンテナイメージ全体をダウンロードする代わりに、BentoML はイメージをストリームロードし、必要なファイルだけをオンデマンドで取得します。これにより、新しいレプリカの起動時間を大幅に短縮することができます。
もうひとつの最適化は、効率的なモデルウェイトファイルのロードとキャッシュです。BentoML は、ロードされたモデルのウェイトをレプリカ間でキャッシュできるため、新しいリクエストごとにモデルをロードする時間を短縮できます。これは特に、膨大なウェイトファイルを持つ大規模な言語モデルにとって有益です。
BentoML のオートスケーリング戦略とコールドスタート最適化を活用することで、LLM 推論サービスを効果的に拡張し、RAG システムの需要に対応することができます。BentoML は複雑なインフラストラクチャ管理を抽象化するため、最適なパフォーマンスとスケーラビリティを確保しながら、モデルの開発と反復に集中することができます。
RAG システムのための高度な推論パターン
RAG システムでは、複雑なワークフローを処理し、パフォーマンスを最適化するために、高度な推論パターンが必要になることがよくあります。BentoML は、このようなパターンをサポートする柔軟で拡張可能なフレームワークを提供し、高度な RAG システムを簡単に構築できます。
レイアウト解析、表抽出、OCRなど、複数のモデルや処理ステップを組み合わせることで、文書処理パイプラインを構築できます。
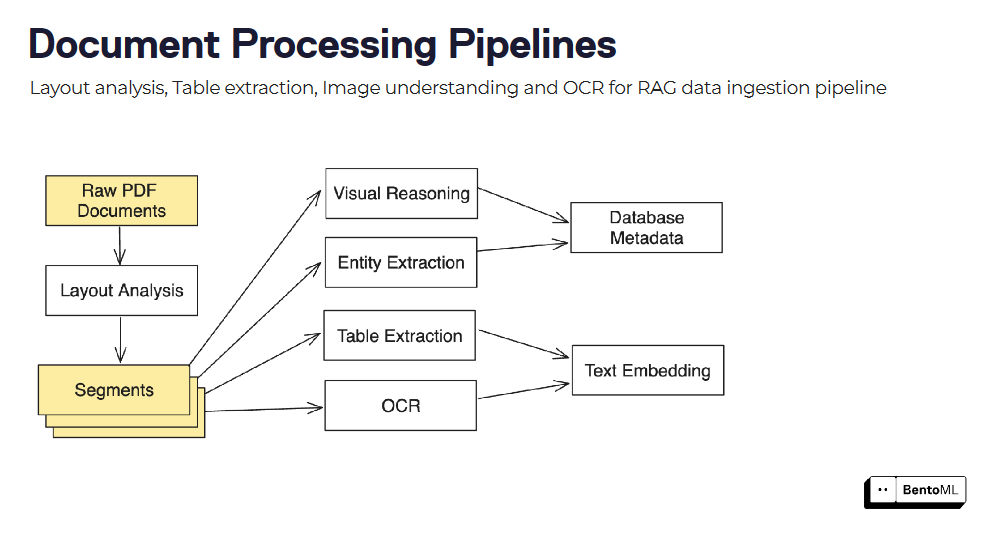
BentoML の非同期推論インターフェースは、長時間実行するタスクを効率的に処理します。また、バッチ推論をサポートすることで、並列性と最適化を活用した大規模データセットの処理が可能になります。
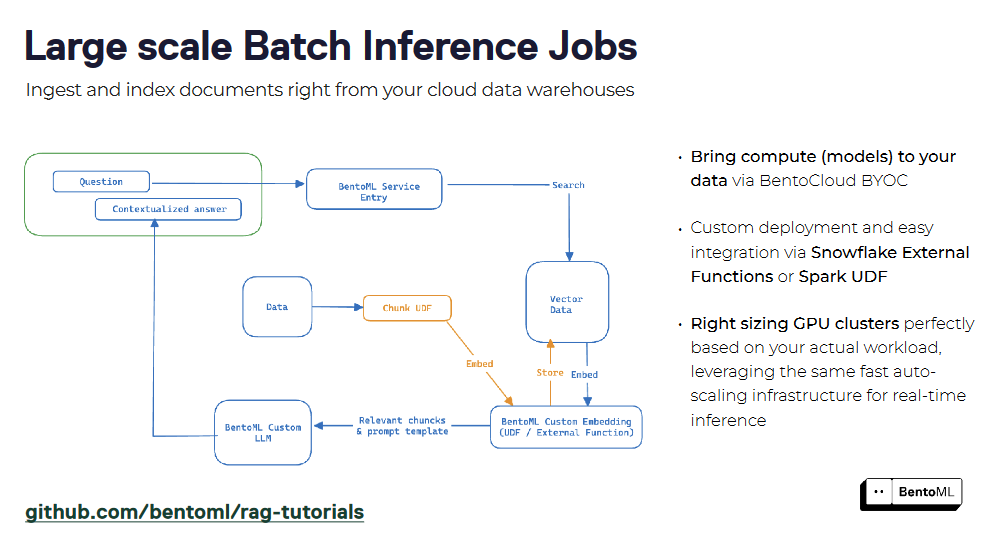
RAGシステムは、BentoMLを使用してサービスとしてパッケージ化することができ、クエリとインタラクションのための統一されたインターフェイスを作成することができる。リトリーバとジェネレータのコンポーネントをカプセル化することで、RAGサービスを簡単にデプロイし、他のアプリケーションと統合することができます。BentoML のコンテナ化とオーケストレーションのサポートは、本番環境での RAG サービスのスケーリングと管理を簡素化します。
これらの高度な推論パターンは、さまざまなタスクやワークロードを処理するパワフルで効率的なRAGサービスを構築する上でのBentoMLの柔軟性と拡張性を示しています。
LLMを提供するインフラストラクチャとは別に、ベクトル埋め込みを保存し、類似性検索を実行するための堅牢なベクトルデータベースも必要です。そこでMilvusベクトルデータベースが役立ちます。 次のセクションでは、BentoMLとMilvusを使った簡単なRAGアプリの構築について見ていきます。
BentoMLとMilvusベクトルデータベースの統合
Milvusは、高性能な類似検索用に設計されたオープンソースのベクトルデータベースで、Retrieval Augmented Generation (RAG)を構築するための極めて重要なインフラコンポーネントです。
MilvusはBentoMLと統合され、スケーラブルなRAGアプリケーションの構築が容易になりました。このセクションでは、BentoMLとMilvusベクトルデータベースを使ったRAGアプリケーションの構築について説明します。この例では、Milvusの軽量版であるMilvus Liteを使い、素早くプロトタイピングを行います。
使用するデータセットはこちら:City data.
ステップ1: 環境の設定.
まず、以下のように必要なライブラリをインストールする:
# 必要なライブラリのインストール
pip install -U pymilvus bentoml
**ステップ2:データの準備
都市データ](https://github.com/ytang07/bento_octo_milvus_RAG/tree/main/data)をダウンロードして加工してみよう。
インポート os
インポートリクエスト
インポート urllib.request
# データソースをセットアップする
repo = "ytang07/bento_octo_milvus_RAG"
ディレクトリ = "data"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# GitHubからファイルをダウンロードする
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# ダウンロードしたデータを処理する
def chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
sentences = text.split("\n")
return [s for s in sentences if len(s) > 7].
cities = os.listdir("city_data")
city_chunks = [].
for city in cities:
chunked = chunk_text(f "city_data/{city}")
city_chunks.append({
"city_name": city.split(".")[0]、
「チャンク
})
ステップ 3: BentoML クライアントのセットアップ** ステップ 3: BentoML クライアントのセットアップ **ステップ 3: BentoML クライアントのセットアップ
次に、エンベッディングモデルとLLMのBentoMLクライアントを設定します。
import bentoml
# エンドポイントとAPIトークンを設定する
embedding_endpoint = "あなたの_embedding_model_endpoint"
llm_endpoint = "your_llm_endpoint"
api_token = "あなたのAPI_token"
# BentoMLクライアントの初期化
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
プレースホルダのエンドポイントとトークンを、実際の BentoML デプロイのエンドポイントと API トークンに置き換えてください。これらのクライアントにより、埋め込みを生成し、テキスト生成に言語モデルを使用することができます。
**ステップ4: エンベッディングを生成する。
エンベッディングを生成する前に、以下のようにエンベッディング関数を作成します:
埋め込み関数を作成する。
def get_embeddings(texts):
# 大量のテキストを処理する
if len(texts) > 25:
splits = [text[x : x + 25] for x in range(0, len(texts), 25)] # 大きなテキストバッチを処理する。
埋め込み = [].
for split in splits:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
return embeddings
# 小さなバッチを直接扱う
return embedding_client.encode(sentences=texts)
この関数は、埋め込みモデルには入力サイズの制限があるかもしれないので、大きなテキスト集合のバッチ処理を行います。
**すべてのチャンクの埋め込みを生成します。
entries = [].
for city_dict in city_chunks:
# 各都市のテキストチャンクの埋め込みを得る
embedding_list = get_embeddings(city_dict["chunks"])
# エンベッディングとメタデータを含むエントリを作成
for i, embedding in enumerate(embedding_list):
エントリ = {
"embedding": embedding、
"sentence": city_dict["chunks"][i]、
"city": city_dict["city_name"]、
}
entries.append(entry)
ここでは、埋め込み、元の文、都市名を含むエントリーのリストを作成している。この構造はMilvusにデータを挿入する際に便利である。
ステップ5: Milvusのセットアップ.
埋め込みデータを追加するために、Milvusを使ってベクトルデータベースを初期化します。
Milvusクライアントの初期化とスキーマの作成。
from pymilvus import MilvusClient, DataType
コレクション名 = "Bento_Milvus_RAG"
DIMENSION = 384 # 埋め込みモデルの出力ディメンションと一致する必要がある。
# Milvus クライアントの初期化
milvus_client = MilvusClient("milvus_demo.db")
# スキーマの作成
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
ここではアプリケーションに埋め込まれたMilvus liteを使っています。スキーマは自動生成されたIDと埋め込みベクトルを含むMilvusのデータ構造を定義しています。
**インデックスパラメータを準備し、コレクションを作成する。
# インデックスパラメータの準備
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="embedding"、
index_type="AUTOINDEX"、
metric_type="COSINE"、
)
# コレクションを作成または再作成する
if milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
コレクション名=COLLECTION_NAME, スキーマ=スキーマ, インデックスパラメータ=インデックスパラメータ
)
データに基づいて最適なインデックスタイプを自動的に選択するAUTOINDEXを使用しています。コサイン類似度 がベクトル比較の距離指標として使用されています。
Milvusにデータを挿入する。
それでは、以下のようにMilvusにデータを挿入します。
# 前処理したデータをMilvusに挿入する
milvus_client.insert(collection_name=COLLECTION_NAME, data=entries)
このステップでは、すべての前処理済みデータ(エンベッディングとメタデータ)をMilvusコレクションに挿入します。
ステップ6: RAGを実装する。
RAGを効率的に実装するために、以下に示すように、RAGレスポンスを生成し、コレクションから関連するコンテキストを取得し、回答を生成する3つの関数を作成する:
**回答を生成するLLMの関数を作成する。
def generate_rag_response(question, context):
# LLM用のプロンプトを用意する
prompt = (
f "あなたは親切なアシスタントです。コンテキストのみに基づいてユーザーの質問に答えてください:{コンテキスト}に基づいてユーザーの質問に答えてください。\n"
f "ユーザーの質問は{question}です。
)
# LLMを使って回答を生成する
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
この関数は、取得したコンテキストとユーザーの質問を使ってプロンプトを作成し、LLMを使ってレスポンスを生成します。
**関連するコンテキストを取得する関数を作成する。
def retrieve_context(question):
# 質問の埋め込みを生成する
embeddings = get_embeddings([question])
# Milvusで類似ベクトルを検索する
res = milvus_client.search(
collection_name=COLLECTION_NAME、
data=embeddings、
anns_field="embedding"、
limit=5、
output_fields=["sentence"]、
)
# 関連する文を抽出して結合する
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits].
return ".".join(sentences)
この関数はユーザーの質問を埋め込み、Milvusで類似のベクトルを検索し、コンテキストのために対応するテキストチャンクを取得します。
**上記の関数を組み合わせてRAGパイプラインを作成します。
def ask_question(question):
# 関連するコンテキストを取得する
context = retrieve_context(question)
# コンテキストと質問に基づいて回答を生成する
return generate_rag_response(question, context)
この関数はすべてを結びつけ、RAGパイプラインを作成します。
**ステップ7: RAGシステムの使用
さて、以下に示すように、質問に答えるためにRAGシステムを使用することができます:
# 使用例
question = "ケンブリッジはどんな状態ですか?"
answer = ask_question(question)
print(f "質問: {question}")
print(f "答え: {答え}")
この例では、ある都市に関する特定の質問に答えるためにRAGシステムを使用する方法を示します。
重要な注意事項
1.このコードを実行する前に、エンベッディングと大規模言語モデルがBentoMLに正しくデプロイされていることを確認してください。
2.エンベッディングの次元(この例では384)は、エンベッディング・モデルの出力と一致している必要があります。
3.このセットアップでは、小規模なデータセットに適したMilvus Liteを使用しています。より大規模なアプリケーションには、DockerやK8s上でのMilvusのフルデプロイメントをご検討ください。
4.RAGシステムの有効性は、最初の都市データの品質とカバレッジに依存します。最良の結果を得るためには、データセットが包括的で正確であることを確認してください。
BentoMLとMilvusの統合により、提供された都市情報に基づいて質問に答えることができる強力なRAGシステムが構築されます。さらにデータを追加したり、特定のユースケースに合わせて微調整することで、このシステムを拡張することができます。
結論
カスタムAIモデルによるRetrieval Augmented Generation(RAG)システムの構築とスケーリングには、ユニークな課題がある。開発者は、カスタムモデルのパワーを活用し、デプロイとサービングインフラストラクチャを最適化し、高度な推論パターンを採用することで、高性能でスケーラブルなRAGシステムを構築することができる。
BentoML は、この旅における貴重なツールです。推論 API の構築とデプロイのプロセスを簡素化し、サービングのパフォーマンスを最適化し、シームレスなスケーリングを可能にします。
BentoML を Milvus ベクターデータベースと統合することで、組織はより強力でスケーラブルな RAG システムを構築することができます。この組み合わせにより、関連情報の効率的な検索とコンテキストを考慮した応答の生成が可能になり、さまざまなドメインや業界にわたる高度なAIアプリケーションの可能性が広がります。
BentoMLとRAGに関する詳しい情報は、以下のリソースをご覧ください。
OpenAIなしのRAG:BentoML、OctoAI、Milvus - Zillizブログ](https://zilliz.com/blog/rag-without-open-ai-bentoml-octoai-milvus)
RAGパイプラインのパフォーマンスを向上させる方法 - Zillizブログ](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Mastering LLM Challenges: An Exploration of RAG - Zilliz blog
カオスを取り込む:非構造化データをRAGのスケールで確実に扱うためのMLOps (milvus.io)](https://milvus.io/blog/Ingesting-Chaos-MLOps-Behind-Handling-Unstructured-Data-Reliably-at-Scale-for-RAG.md)
なぜMilvusはRAGの構築をより簡単に、より速く、よりコスト効率的にするのか - Zillizブログ](https://zilliz.com/blog/why-milvus-makes-building-rag-easier-faster-cost-efficient)
読み続けて

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.