




Milvusでハロウィーンのかわいいゴーストを捕まえよう
*この記事の一部はDZoneに掲載されています。
All Things Open](https://2024.allthingsopen.org/schedule)で講演を行ったばかりだが、Retrieval Augmented Generation(RAG)が、今では何年も前から行ってきた手法のように思えて信じられない。
RAGの有用性は無限であるため、この2年間でその深さと幅は爆発的に広がったからだ。大規模言語モデル ](https://zilliz.com/glossary/large-language-models-%28llms%29)から生成された結果を改善する能力は、バリエーション、改善、新しいパラダイムが物事を前進させるため、常に向上しています。
今日はマルチモーダルRAGの実用的なアプリケーション
- フィルターを使った画像検索
- 最高のハロウィンゴーストを見つける
Ollama、LLava 7B、LLM Rerankingを使用する
高度なマルチモーダルRAGをローカルで実行する

このRAGの新しい進歩のいくつかを使って、ハロウィンの問題を解決してみよう。その問題とは、何かがお化けかどうかを見つける問題と、最もかわいい猫のお化けは何かという問題である。
マルチモーダルRAGの実用例
何かが幽霊? フィルターと[clip-vit-base-patch32]による画像検索(https://zilliz.com/ai-models/clip-vit-base-patch32)
私たちは、何かが「ゴースト」であるかどうかの判定を支援することで、世の中に存在するゴースト検出器のためのツールを作りたいと考えています。そのために、私たちがホストしている "ghosts"コレクションを使います。"ghosts"コレクションは、マルチモーダルエンコーディングされたベクトルを検索するだけでなく、フィルタリングできるフィールドをたくさん持っています。Googleフォーム、Streamlitアプリ、S3アップロード、Jupyterノートブックを通じて、誰かが心霊写真を渡すことができる。HuggingFace](https://milvus.io/docs/integrate_with_hugging-face.md)のSentence TransformerとOpenAIのCLIPモデルを利用することで、テキストや画像の組み合わせであるクエリをエンコードします。これにより、疑わしいゴースト画像をエンコードし、それを使ってコレクションを検索し、その類似性を見ることができる。 類似度が十分に高ければ、それを「*幽霊」とみなすことができる。
**コレクション・デザイン
アプリケーションを構築する前に、必要と思われるすべてのフィールドと、ニーズにマッチするタイプとサイズがきちんと定義されていることを確認する必要があります。
ゴースト "のコレクションには、最低限以下のものが必要です:
id**フィールドはINT64型で主キーとして設定され、自動ID生成機能を持つように設定されている。
これは長さ20のVARCHARスカラー文字列で、クラスI、クラスII、フェイク、クラスIVといった幽霊の伝統的な分類を保持する。
これは長さ256のVARCHARスカラー文字列で、Fake、Ghost、Deity、Unstable、Legendといった分類の短い説明を保持します。
長さ1,024の大きなVARCHARスカラー文字列として定義され、オブジェクトの画像へのS3パスを保持するs3pathのフィールドを追加します。
最後に最も重要なのは、vectorで、これは512次元の浮動小数点ベクトルを保持する。
これでデータスキーマができたので、それをビルドしてデータに対する恐ろしい分析に使うことができる。
ステップ1: Milvusスタンドアロンに接続する。
ステップ2: CLIPモデルのロード
ステップ3: ベクトルとスカラーのスキーマでコレクションを定義します。
ステップ4: クエリに使用する画像をエンコードします。
ステップ5: Milvusスタンドアロン・データベースのghostsコレクションに対してクエリーを実行し、Fakeではないcategoryでフィルタリングされたものだけを探します。 結果を1つに限定する。
ステップ6:距離をチェックし、0.8以上であればゴーストと見なします。これは、疑われる実体を実際の幽霊写真の大規模なデータベースと比較することによって行われます。

ステップ7:*結果は、幽霊候補とその最も近い一致が表示されます。

この例でわかるように、Fakeカテゴリにない類似の"ghost "に十分近くマッチしました。
別のハロウィーン・アプリケーションでは、ハロウィーンのお化けを含む別のユースケースのために、別のコレクションと別のエンコーディング・モデルを見ていきます。
ビジュアライズされたBGEモデル](https://milvus.io/docs/multimodal_rag_with_milvus.md)を使って、最もかわいい猫の幽霊を見つける。
私たちは、賞品を獲得したり、ソーシャルメディアの投稿に載せたり、その他の重要な努力のために、最もかわいい猫の幽霊を見つけたい。
**コレクションデザイン
アプリケーションを構築する前に、どのようなフィールドが必要かを確認しておく必要があります。 この単純な使用例では、自動id生成機能を持つ動的スキーマを使用します。 この方法では、フィールドを定義する必要はなく、idとvectorのフィールドでフィールドが作成されます。
私たちの "ghostslocal "コレクションでは、これらが自動的に作成される:
id**フィールドはINT64型で主キーに設定され、自動ID生成に設定されている。
このコレクションでは、ダイナミック・フィールドを有効にするように設定したので、データ挿入時に重要なフィールドを1つ追加します。
最後に最も重要なのは、vector で、これは768次元の浮動小数点ベクトルを保持します。
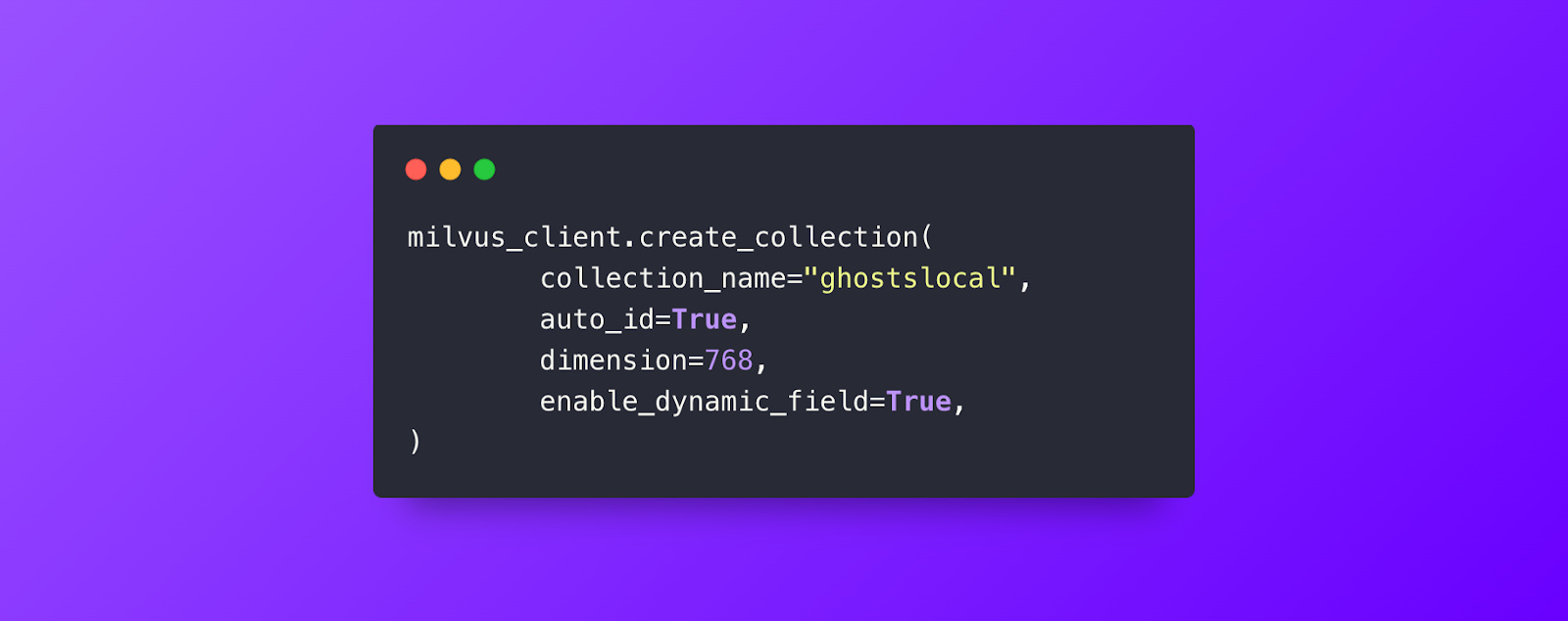
これでデータ・スキーマができたので、次は一番かわいいゴーストを探そう。
ステップ1: Milvus Standaloneに接続する。
ステップ2: BAAI/bge-base-en-v1.5モデルをロードします。
ステップ3: ベクトルとスカラーのスキーマでコレクションを定義します。
ステップ4: 画像のリストを繰り返し、それらをエンコードし、後で挿入するためにdictに追加します。
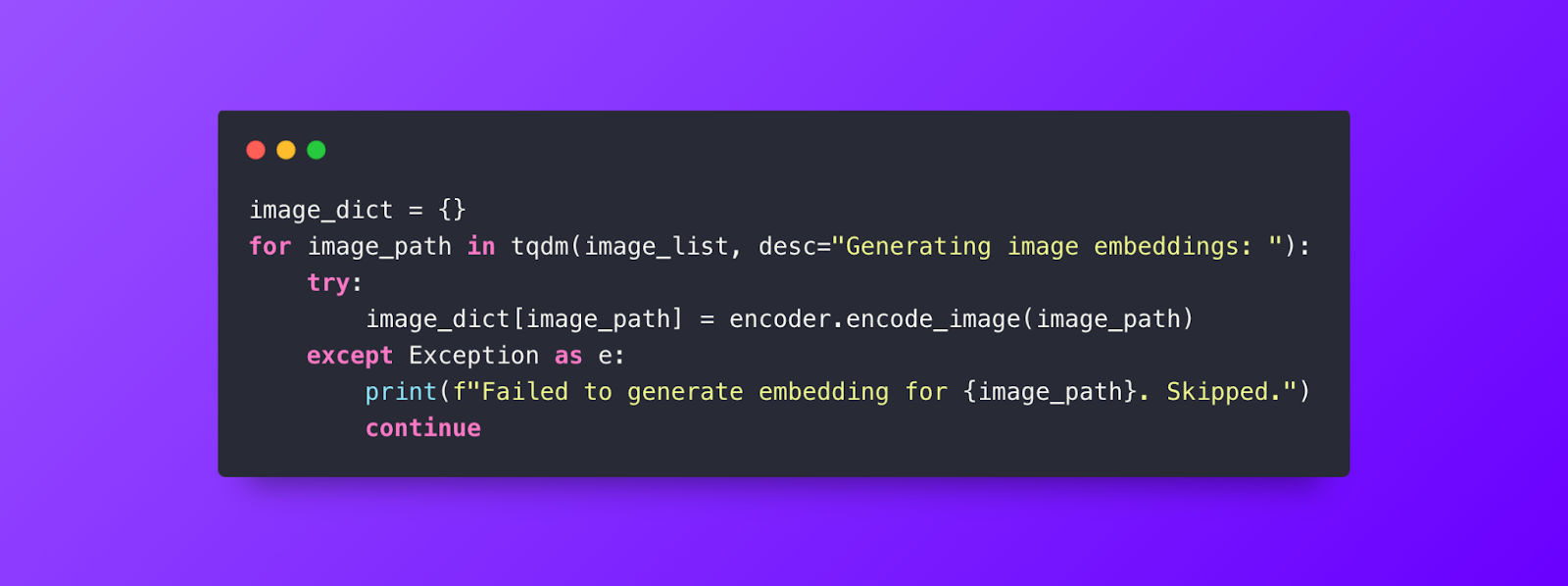
image_pathは、このコレクション用のスキーマの動的フィールドとして作成されます。

ステップ6: "Show me the cutest cat ghost "というテキストクエリをベクター符号化し、クエリに使用する。
ステップ5:類似検索の実行
Step 6: 結果を繰り返し、最もかわいい猫と一致する画像を表示する。
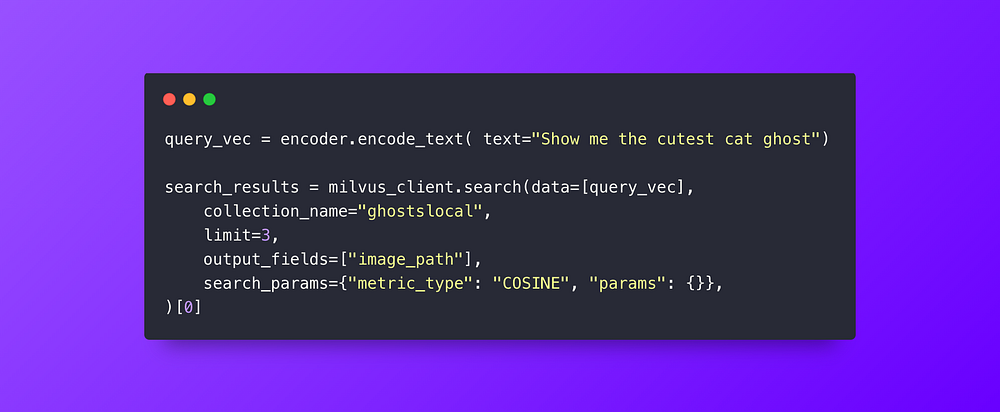
私たちのベクトル検索はとてもシンプルです。私たちはただテキストをエンコードして、一番かわいい猫のお化け(小さなハロウィーンのコスチュームを着ている)を探しているだけです。Milvusは768次元の浮動小数点ベクトルを検索し、最も近いものを見つけてくれます。私たちのデータベースには不気味なお化けや幽霊がたくさんいるので、この結果に異議を唱えるのは難しい。

Ollama、LLava 7B、LLM Rerankingを使用。
高度なRAGをローカルで実行する
さて、これはちょっとしたトリックであり、同時に2つのトピックを実行することができる。Milvus Lite、Ollama、LLava 7B、そしてJupyter Notebookを使って、この高度なRAGテクニック全体をローカルで実行することができます。これはLLMを使って画像をランク付けし、最良の結果を説明する。これまではGPT-4oモデルを使っていました。私はOllamaでローカルにホストされたLLava 7Bで良い結果を得ている。このオープン、ローカル、フリーを実行して見せましょう!
既存のサンプル・コードを再利用して、「幽霊のいるコンピューター・モニター」というテキストで幽霊のいるオフィスの写真をハイブリッド検索して返された画像からパノラマ写真を構築します。そして、その写真をOllamaがホストするLaVA7Bモデルに送り、結果のランク付けを指示します。ランキング、説明、画像が返される。
オラマ](https://assets.zilliz.com/Our_search_image_and_nine_results_d6250744dc.png)
検索画像と9つの結果

LLMはランク順の結果を返しました。

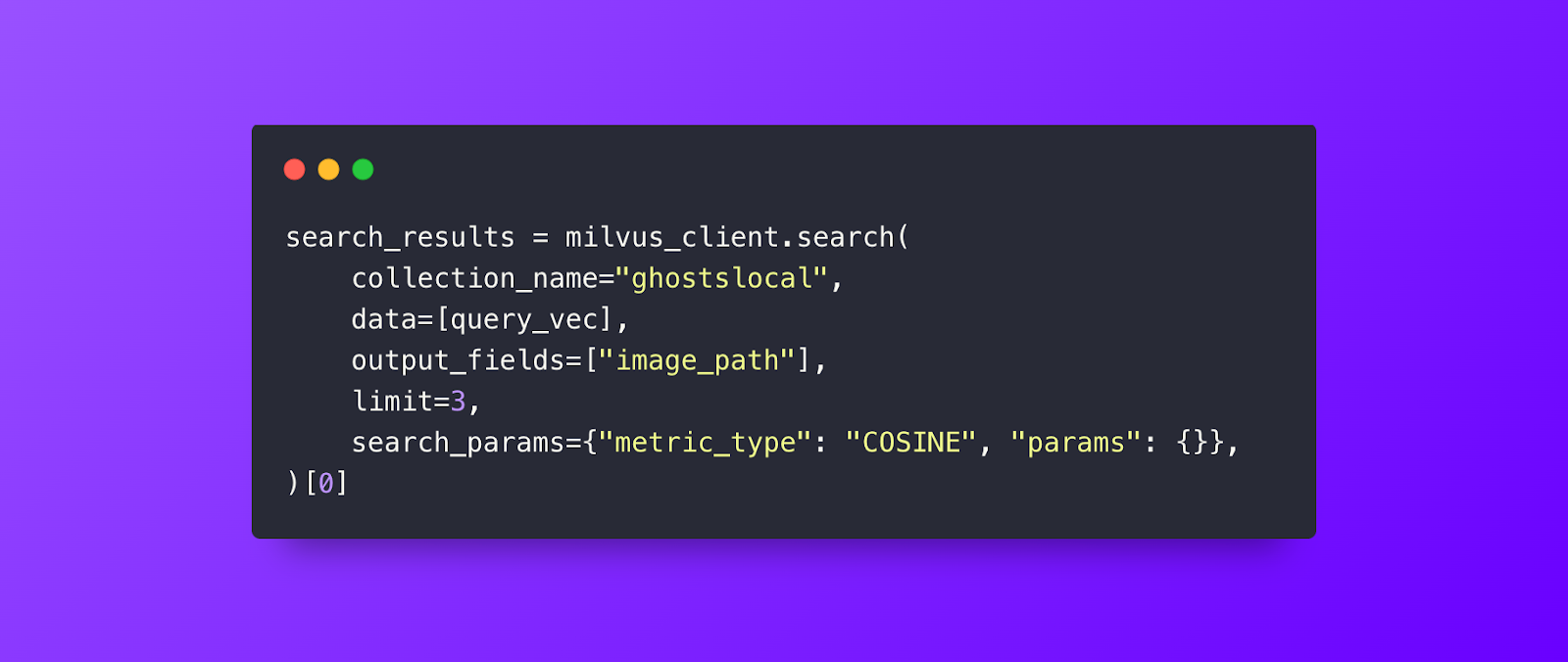
LLMに供給する結果を得るためのシンプルで高速なMilvusクエリー。
完全なコードはexample github にあります。また、StreamLitアプリケーションを含む、いくつかの参考文献やドキュメント化されたコードもありますので、ご自身で試してみてください。
結論
お分かりのように、マルチモーダルRAGは怖くないだけでなく、楽しく、多くの用途に使える。
より高度なAIアプリケーションの構築に興味があるのであれば、MilvusとMultimodal RAGの組み合わせはアプリケーション構築に最適です。テキストだけでなく、画像なども追加できるようになりました。Multimodal RAGは、LLM生成、検索、AIアプリケーション全般に多くの新しい道を開きます。
ご意見をお聞かせください!
もしこの記事を気に入っていただけたら、GitHub に星をつけていただけるととても嬉しいです!また、DiscordのMilvusコミュニティにもぜひご参加ください。ミートアップに参加することで、ローカルなコミュニティやコードを共有することができ、またミートアップのトークやデモ、ディープダイブを録画したYoutubeライブラリにもアクセスすることができます。
もっと学びたい方は、GitHubのBootcampリポジトリ でMilvusを使ったマルチモーダルRAGアプリの構築例をご覧ください。
その他のリソース
ゴーストは非構造化データ](https://medium.com/@tspann/ghosts-are-unstructured-data-i-e31b34c0d9e4)
よりスマートなAIのためにテキストを超えて拡張するマルチモーダルRAG](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai)
マルチモーダルAIモデルベスト10](https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know)
マルチモーダルRAGノート](https://github.com/milvus-io/bootcamp/blob/master/bootcamp/tutorials/quickstart/multimodal_rag_with_milvus.ipynb)
すべてをオープンに - RAGトーク](https://www.slideshare.net/slideshow/2024-10-28-all-things-open-advanced-retrieval-augmented-generation-rag-techniques/272786149)
 Tim Spann
Tim SpannTim Spann is a Principal Developer Advocate at Zilliz.
読み続けて

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.