




データサイエンスの成果に向けたチャットの根拠
今回はシリーズの3回目です。最初の2回は、Milvusを使った基本的なベクトルデータベースのみのチャットボットの実装と、LlamaIndexを使ったチャットボットの実装を紹介しました。今回も引き続きLlamaIndexを使用しますが、結果を "根拠づける "ものを追加します。TruEraは、彼らのRAG評価ブログの1つに、素晴らしい根拠付けに関する解説と短い説明を載せている。
この記事では、LlamaIndexを介したTowards Data ScienceのRAGの結果をどのように根拠づけるかを3つのセクションに分けて説明します:
RAG結果の根拠付けのセットアップ
Towards Data Scienceチャットボットのパラメータの定義
引用による結果の根拠付け
RAGの結果を根拠づけるためのセットアップ
どんなアプリでもそうだが、最初のステップは前提条件を設定することだ。この例では、まず4つの異なるライブラリをインストールする。llama-index、python-dotenv、pymilvus、openai`が必要である。これらの4つのライブラリはそれぞれ、LLMの検索、環境変数の管理、vector databaseの操作、OpenAIの操作をサポートしてくれる。
pip install llama-index python-dotenv openai pymilvus
次のコードブロックでは、OpenAIとZilliz (管理されたMilvusベクトルデータベース)をセットアップします。load_dotenv関数を使って環境変数を取り出します。環境変数は通常'.env'ファイルに格納されています。それから、os`を使って必要な変数名を渡して値を取得する。OpenAIはLLMで、Zillizはベクターデータベースです。この例では、Zillizとクラウドに保存されたコレクションを使用して、複数のアプリのバージョンにまたがってデータを永続化します。
import os
from dotenv import load_dotenv
インポート openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
データサイエンスチャットボットのパラメータを定義する
次に、RAGチャットボットのパラメータを定義します。エンベッディングモデル、Milvusベクトルデータベース、LlamaIndexデータパッシング抽象化の3つをセットアップする必要があります。まず、埋め込みモデルを設定します。この例では、前回のブログで使用した埋め込みモデル、HuggingFace MiniLM L12モデルを使用して、データをスクレイピングして埋め込みます。HuggingFaceEmbedding`モジュールを使って、LlamaIndex経由でこのデータをロードすることができる。
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L12-v2")
次に、ベクトルデータベースをセットアップする。Zilliz CloudはMilvusのフルマネージドで最適化されたバージョンなので、MilvusVectorStoreモジュールを使って接続することができる。Zilliz CloudでホストされているMilvusインスタンスに接続するために、URI、トークン、コレクション名、類似度メトリック、テキストキーを指定します。
ZillizのURIとトークンは先ほど環境変数から取得した。コレクション名、類似度メトリック、テキストキーはこのブログシリーズの最初の部分から継承されています。
from llama_index.vector_stores import MilvusVectorStore
vdb = MilvusVectorStore(
uri = zilliz_uri、
token = zilliz_token、
collection_name = "tds_articles"、
similarity_metric = "L2"、
text_key="paragraph"
)
最後に、LlamaIndexのデータを抽象化する。必要なのは、定義済みのサービスを渡すservice contextと、ベクターストアからLlamaIndexの "インデックス "を作成するvector store indexです。今回は、埋め込みモデルを渡すためにサービスコンテキストを使います。そして、既存のMilvusベクトルデータベースと作成されたサービスコンテキストを渡して、ベクトルインデックスを作成します。
from llama_index import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(embed_model=embed_model)
vector_index = VectorStoreIndex.from_vector_store(vector_store=vdb, service_context=service_context)
LlamaIndexの引用による結果の根拠付け
引用と帰属はRAGに加える重要なものです。これによって、文書コーパスのどこから答えが来ているのかを知ることができ、RAGの結果がどの程度根拠のあるものかを評価することができます。
LlamaIndex は CitationQueryEngine モジュールを使って引用を実装する簡単な方法を提供しています。このモジュールで始めるのはとても簡単だ。from_args`を使用してベクトルインデックスを渡すと、引用クエリーエンジンをインスタンス化することができます。先ほどベクターインデックスでテキストフィールドを定義したので、何も追加する必要はありません。
from llama_index.query_engine import CitationQueryEngine
query_engine = CitationQueryEngine.from_args(
vector_index
)
クエリー・エンジンができたら、あとはクエリーを送るだけだ。この例では、"大規模言語モデルとは何ですか?"と尋ねている。これはTowards Data Scienceから得られるであろう答えだ。また、出力をきれいに表示するために pprint を追加した。
res = query_engine.query("What is a large language model?")
from pprint import pprint
pprint(res)
下の画像は、回答がどのように見えるかの例です。本文中に答えと出典が記載されています。これによって、答えが根拠のあるものであり、それがどこから来たものなのかを知ることができます。
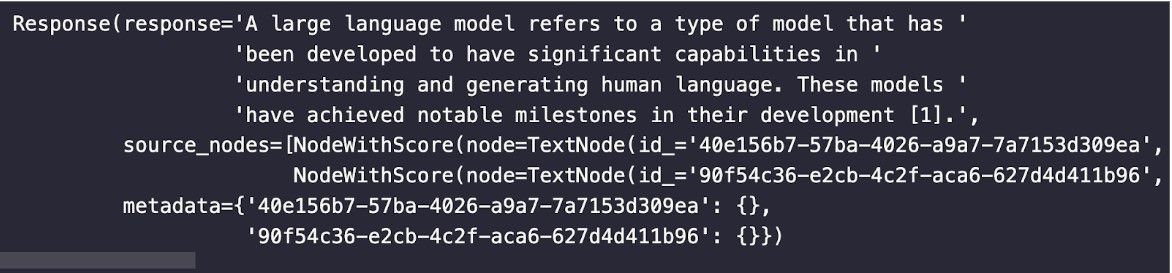
引用と帰属によるRAG結果の根拠まとめ
このチュートリアルは、RAGを介してチャットボットを作成することを中心としたシリーズの3回目です。Towards Data Scienceの同じデータを全てのチュートリアルで使用しています。このチュートリアルでは、引用と帰属を使って、結果が根拠あるものであることを確認します。
引用と帰属は、RAGが従来抱えていた2つの問題を解決します。1つは、どこからデータを取得しているかを知ることができる。2つ目は、データに基づいて、どの程度「真実」なのか、あるいはどの程度の回答なのかを確認することができる。この概念は "groundedness "とも呼ばれる。
我々は、このRAGチュートリアルを構築するために、LlamaIndexとZilliz Cloudを使用した。LlamaIndexは、引用がベクターストアに存在する限り、引用を引き出すエンジンを簡単にスピンアップすることができます。Zilliz Cloudは、複数のプロジェクトにまたがってデータを簡単に永続化することができます。
Chat Towards Data Scienceシリーズをもう一度読むには、以下のリンクをクリックしてください:

読み続けて

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

Knowledge Injection in LLMs: Fine-Tuning and RAG
Explore knowledge injection techniques like fine-tuning and RAG. Compare their effectiveness in improving accuracy, knowledge retention, and task performance.