




Chat Towards Data Science: Building a Chatbot with Zilliz Cloud
This article is the first part of the Chat Towards Data Science blog series.
In the era of Generative AI, developers harness large language models (LLMs) for more intelligent applications. However, LLMs are prone to hallucination due to their limited knowledge. Retrieval Augmented Generation (RAG) effectively addresses this problem by supplementing LLMs with external knowledge. In my Chat Towards Data Science blog series, I’ll walk you through building a RAG-based chatbot using your dataset as the knowledge backbone.
In the first part of my blog series, we’ll guide you through creating a chatbot for website Towards Data Science, utilizing web scraping to create a knowledge base stored in Zilliz Cloud, a fully managed vector database service built on Milvus.
Scraping web data with BeautifulSoup4
The first step in any machine learning (ML) project is to gather the required data. For this project, we employ web scraping techniques to collect data for our knowledge base. We utilize the requests library to fetch web pages and then use BeautifulSoup4 (a library that scrapes information from web pages) to parse the HTML information and extract the paragraphs.
Preparing BeautifulSoup4 and Requests for Web Scraping
To get started, install BeautifulSoup by running pip install beautifulsoup4 sentence-transformers. We only need two imports for this section: requests and BeautifulSoup. Next, we create a dictionary of URLs that we want to scrape. In this example, we only scrape content from Towards Data Science, but you can also scrape other websites. We retrieve data from each archive page using the format shown in the code below.
import requests
from bs4 import BeautifulSoup
urls = {
'Towards Data Science': 'https://towardsdatascience.com/archive/{0}/{1:02d}/{2:02d}',
}
We also need two helper functions for our web scraping. The first function converts the number of days of the year to a month and day format. The second retrieves the number of claps (claps show support for a Medium article) from an article.
The day conversion function is relatively simple. We hard code the number of days each month and use that list to perform the conversion. Since this web scraping project targets explicitly the year 2023, we don't need to account for leap years. Feel free to modify it for different years if you prefer.
The clap counting function represents the claps for a Medium article. Some articles can receive thousands of claps, which Medium denotes with the letter "K." Therefore, we need to consider this representation in our function.
# takes the number day of the year and returns month, day
def convert_day(day):
month_days = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
m = 0
d = 0
while day > 0:
d = day
day -= month_days[m]
m += 1
return (m, d)
# converts the claps string
def get_claps(claps_str):
if (claps_str is None) or (claps_str == '') or (claps_str.split is None):
return 0
split = claps_str.split('K')
claps = float(split[0])
claps = int(claps*1000) if len(split) == 2 else int(claps)
return claps
Parsing the BeautifulSoup4 web scraping response
Now that we have set up the necessary components, we can proceed with web scraping. In this section, we import an additional library called "time.” I added this library because I encountered 429 errors (too many requests) during the process. Using the time library, we can introduce a delay between sending requests. Additionally, we utilize the sentence transformers library to obtain our embedding model, specifically a MiniLM model, from Hugging Face.
As mentioned earlier, we are only scraping data for 2023, so we set the year to 2023. Furthermore, we only need data from day 1 (January 1) to day 243 (August 30). At the time of scraping, it was early September. In retrospect, it would have been better to scrape until day 244, but we will proceed with what I have already done for now. In the first part of our function, up until the first time.sleep() call, we set up the necessary components. We convert the iterator into a month and day, convert that into a date string, and then retrieve the HTML response from the archive URL.
After obtaining the HTML, we parse it using BeautifulSoup and search for div elements with a specific class name (indicated in the code), which indicates that it is an article. From there, we parse the title, subtitle, article URL, number of claps, reading time, and number of responses. Subsequently, we use requests again to retrieve the article from the article URL.
We call time.sleep() for a second time to conclude the second section of this for loop. At this point, we have obtained most of the metadata required for each article. We extract each paragraph and its corresponding embedding using our Hugging Face model. We then create a dictionary that contains all the metadata for that specific paragraph and article.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
import time
# data_batch = []
year = 2023
for i in range(1, 243):
month, day = convert_day(i)
date = '{0}-{1:02d}-{2:02d}'.format(year, month, day)
for publication, url in urls.items():
response = requests.get(url.format(year, month, day), allow_redirects=True)
if not response.url.startswith(url.format(year, month, day)):
continue
time.sleep(8)
page = response.content
soup = BeautifulSoup(page, 'html.parser')
articles = soup.find_all(
"div",
class_="postArticle postArticle--short js-postArticle js-trackPostPresentation js-trackPostScrolls")
for article in articles:
title = article.find("h3", class_="graf--title")
# print(title.contents)
if title is None:
continue
title = str(title.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ')
# title = title.contents[0]
subtitle = article.find("h4", class_="graf--subtitle")
subtitle = str(subtitle.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ') if subtitle is not None else ''
article_url = article.find_all("a")[3]['href'].split('?')[0]
try:
claps = get_claps(article.find_all("button")[1].contents[0])
except:
claps = 0
reading_time = article.find("span", class_="readingTime")
reading_time = 0 if reading_time is None else int(reading_time['title'].split(' ')[0])
responses = article.find_all("a")
if len(responses) == 7:
responses = responses[6].contents[0].split(' ')
if len(responses) == 0:
responses = 0
else:
responses = responses[0]
else:
responses = 0
article_res = requests.get(article_url)
time.sleep(8)
soup = bs4.BeautifulSoup(article_res.text)
paragraphs = soup.select('[class*="pw-post-body-paragraph"]')
for i, paragraph in enumerate(paragraphs):
embedding = model.encode(paragraph.text)
data_batch.append({
"_id": f"{article_url}+{i}",
"article_url": article_url,
"title": title,
"subtitle": subtitle,
"claps": claps,
"responses": responses,
"reading_time": reading_time,
"publication": publication,
"date": date,
"paragraph": paragraph.text,
"embedding": embedding
})
The last step is to pickle our file.
import pickle
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'wb') as f:
pickle.dump(data_batch, f)
What does our data look like?
It is always helpful to visualize the data. Below is what the data looks like in Zilliz Cloud. Pay attention to the embeddings, which represent the vector. We generate these vector embeddings from the text in the following section.
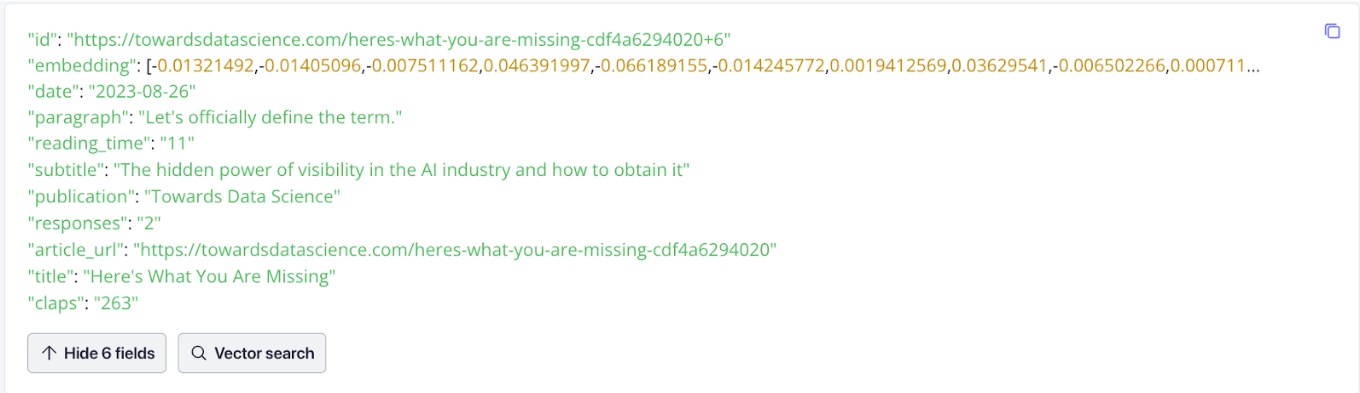
Ingest data from TDS into your vector database
Once we have the data, the next step is to pipe it to a vector database. In this project, I utilized a separate notebook for ingesting the data into Zilliz Cloud, a fully managed vector database service built on Milvus, rather than scraping it from Towards Data Science.
To insert our data into Zilliz Cloud, we follow these steps:
Connect to Zilliz Cloud.
Define the parameters for our collection.
Insert the data into Zilliz Cloud.
Setting up the Jupyter Notebook
Run the command pip install pymilvus python-dotenv to set up our Jupyter Notebook and start the data ingestion process. I use the dotenv library to manage my environment variables as usual. For the pymilvus package, we need to import the following modules:
utility- for checking the status of your collectionsconnections- to connect to your Milvus instanceFieldSchema- to define the schema of a fieldCollectionSchema- to define the schema of a collectionDataType- data types stored in a fieldCollection- the way we access a collection
Then, we open up the data we previously pickled, retrieve our environment variables, and connect to Zilliz Cloud.
import pickle
import os
from dotenv import load_dotenv
from pymilvus import utility, connections, FieldSchema, CollectionSchema, DataType, Collection
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'rb') as f:
data_batch = pickle.load(f)
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
connections.connect(
uri= zilliz_uri,
token= zilliz_token
)
Setting up your Zilliz vector database and data ingestion
Now, we need to set up Zilliz Cloud. We must create a collection to store and organize the data we scrape from the TDS website. Two constants are required: dimension and collection name. The dimension refers to the number of dimensions our vector has. In this case, we use the MiniLM model with 384 dimensions. The collection name is self-explanatory.
With Milvus' new dynamic schema feature, we can simply define the id and embedding field for a collection without worrying about the number of other fields stored or their required data type. However, it is vital to remember the specific names of the fields we held to retrieve them correctly.
For this project example, we use the dynamic schema feature to define only the ID and embedding fields. We then assign these fields to a schema and the schema to a collection. Next, we specify the parameters for the index. In this case, we use an inverted file index (IVF) without quantization (FLAT), an Euclidean distance (L2), and 128 centroids for the index.
IVF without quantization is the most intuitive indexing method. Essentially, we’re clustering the vectors into 128 sections to query. 128 is an arbitrary number in this case. It’s a hyperparameter that we can tune depending on what our results look like. Heuristically, it’s a good starting point because it can provide a good diversity of clusters as well as reduce the initial complexity of the query. Once we have defined these parameters, we create the index on the embedding field and load the collection into memory.
DIMENSION=384
COLLECTION_NAME="tds_articles"
fields = [
FieldSchema(name='id', dtype=DataType.VARCHAR, max_length=200, is_primary=True),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
Once we have defined the collection and loaded it into memory, we have two options for inserting the data:
Looping through the data batch and inserting each piece individually
Inserting the data in batches
After we insert all the data, it is important to flush the collection to index it and ensure consistency. Ingesting large amounts of data may take some time.
for data in data_batch:
collection.insert([data])
collection.flush()
Query TDS article segments
Now, everything is set up and ready for querying. In this post, we will keep this part simple by vectorizing our query and searching for the closest match in Zilliz Cloud. In my following posts, we will also use LlamaIndex and LangChain.
Get your HuggingFace model and set up to query Zilliz
You must obtain the embedding model and set up the vector database to query our Towards Data Science knowledge base. This step requires running a separate notebook. I will use the dotenv library to manage environment variables. Additionally, we need to use the MiniLM model from Sentence Transformers. For this step, you can reuse the code provided in the Web Scraping section.
import os
from dotenv import load_dotenv
from pymilvus import connections, Collection
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
Running a vector search query
Now, you need to connect to your vector database and perform a search. In this project, we will connect to a Zilliz Cloud instance and retrieve the collection we created earlier, tds_articles. To obtain our query, we prompt the user to input their question about TDS up until September 2023.
Next, we use the embedding model from Hugging Face to encode the query. This process converts the user's question into a 384-dimensional vector representation. We then use this encoded query to search the vector database. During the search, we need to specify the approximate nearest neighbor field (anns_field), index parameters, the desired limit for the number of search results, and the output fields we want.
Previously, we utilized Milvus' dynamic schema feature to streamline the field schema definition. Now, as we search the vector database, including the desired dynamic fields in the search results is essential. This specific scenario entails requesting the paragraph field, which contains the text from each paragraph in the articles.
connections.connect(uri=zilliz_uri, token=zilliz_token)
collection = Collection(name="tds_articles")
query = input("What would you like to ask Towards Data Science's 2023 publications up to September? ")
embedding = model.encode(query)
closest = collection.search([embedding],
anns_field='embedding',
param={"metric_type": "L2",
"params": {"nprobe": 16}},
limit=2,
output_fields=["paragraph"])
print(closest[0][0])
print(closest[0][1])
I asked the app to provide information about large language models, and it returned the following two responses. Although these responses mention "language models" and include some related information, they do not provide a detailed explanation of large language models. The second response is semantically similar but needs to be sufficiently close to what we requested.

Adding onto a vector database knowledge base
So far, we have created a knowledge base on TDS articles using Zilliz as our vector database. While we have been able to retrieve semantically similar search results easily, they are only sometimes what we need. The next step is to enhance our results by incorporating new frameworks and technologies.
In the upcoming section, we will explore the addition of LlamaIndex to route our results, similar to the routing we performed in my previous blog about Query Multiple Documents using LlamaIndex, LangChain, and Milvus.
Summary
This tutorial covers building a chatbot for the Towards Data Science publication. We illustrate the web scraping process to create and store a knowledge base in a vector database (specifically, Zilliz Cloud). We then demonstrate how to prompt the user for a query, vectorize the query, and query the vector database.
However, we discovered that while the results are semantically similar, they are not exactly what we desire. In the next part of this blog series, we will explore using LlamaIndex to route queries and see if we can achieve better results. Apart from the steps discussed here, you can also experiment with Zilliz Cloud by replacing the model, combining texts, or using a different dataset!
To read the entire Chat Towards Data Science series again, here are the links:

Keep Reading

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.